DevOps per l'Apprendimento Automatico
DevOps e MLOps
DevOps è descritto come l'unione di persone, processi e prodotti per consentire la distribuzione continua di valore agli utenti finali, di Donovan Brown in Che cos'è DevOps?.
Per comprendere come viene usato quando si usano i modelli di Machine Learning, si esaminerà ulteriormente alcuni principi fondamentali di DevOps.
DevOps è una combinazione di strumenti e procedure che guidano gli sviluppatori nella creazione di applicazioni affidabili e riproducibili. L'obiettivo dell'uso dei principi DevOps è fornire rapidamente valore all'utente finale.
Se si vuole offrire più facilmente valore integrando modelli di Machine Learning nelle pipeline di trasformazione dei dati o nelle applicazioni in tempo reale, è possibile trarre vantaggio dall'implementazione dei principi DevOps. Informazioni su DevOps consentono di organizzare e automatizzare il lavoro.
La creazione, la distribuzione e il monitoraggio di modelli affidabili e riproducibili per offrire valore all'utente finale sono l'obiettivo di operazioni di Machine Learning (MLOps).
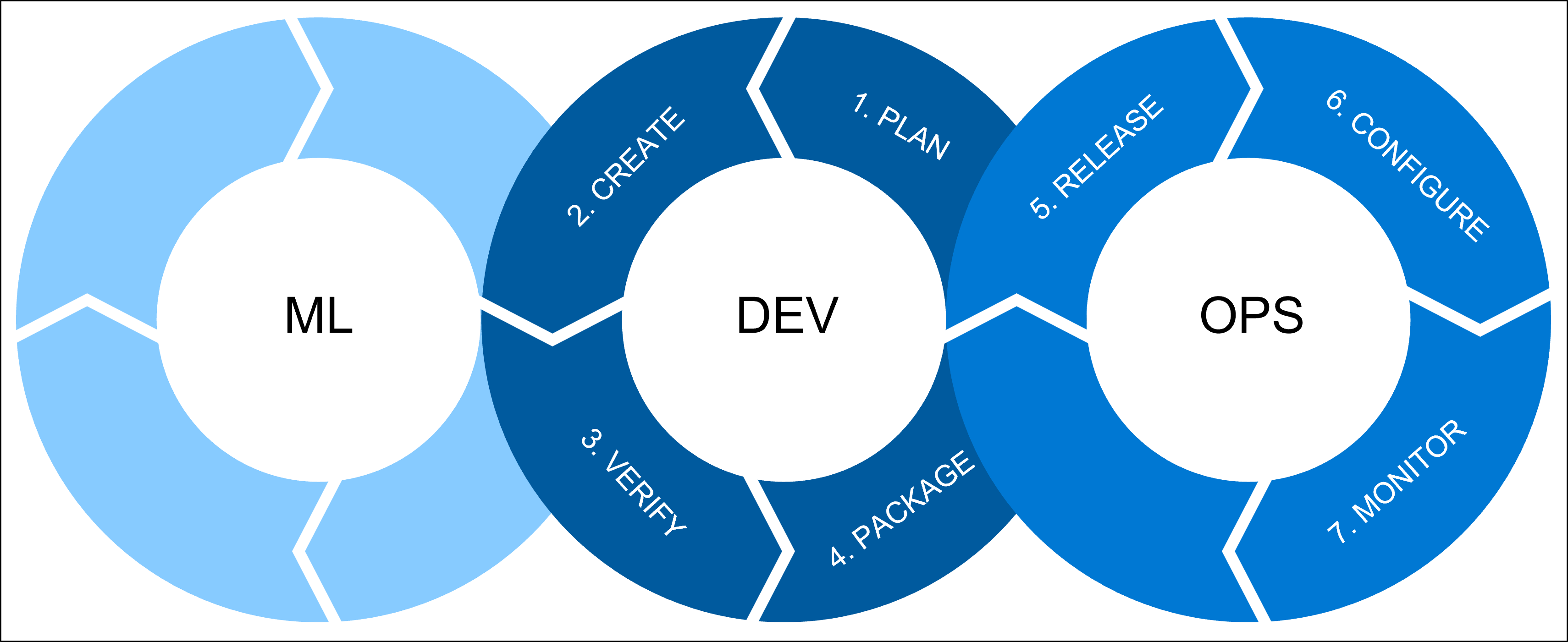
Sono disponibili tre processi da combinare ogni volta che si parla di operazioni di Machine Learning (MLOps):
ML include tutti i carichi di lavoro di Machine Learning per i quali un data scientist è responsabile. Un data scientist eseguirà le operazioni seguenti:
- Analisi esplorativa dei dati (EDA)
- Progettazione di funzionalità
- Training e ottimizzazione del modello
dev fa riferimento allo sviluppo software, che include:
- Plan: definire i requisiti e le metriche delle prestazioni del modello.
- Creazione: creare gli script di training e assegnazione di punteggi del modello.
- Verify: verificare la qualità del codice e del modello.
- Creazione del pacchetto: preparare la soluzione per la distribuzione tramite il processo di gestione temporanea.
OPS fa riferimento alle operazioni e include:
- Rilascio: distribuire il modello nell'ambiente di produzione.
- Configurazione: standardizzare le configurazioni dell'infrastruttura con Infrastructure as Code (IaC).
- Monitorare: tenere traccia delle metriche e assicurarsi che il modello e l'infrastruttura funzionino come previsto.
Verranno ora illustrati alcuni principi DevOps essenziali per MLOps.
Principi devOps
Uno dei principi fondamentali di DevOps è l'automazione. Automatizzando le attività, si aspira a distribuire più rapidamente nuovi modelli nell'ambiente di produzione. Grazie all'automazione, si creeranno anche modelli riproducibili affidabili e coerenti in ambienti diversi.
Soprattutto quando si vuole migliorare regolarmente il modello nel tempo, l'automazione consente di eseguire rapidamente tutte le attività necessarie per garantire che il modello nell'ambiente di produzione sia sempre il modello con prestazioni migliori.
Un concetto chiave per ottenere l'automazione è CI/CD, che è l'acronimo di integrazione continua e consegna continua.
Integrazione continua
L'integrazione continua riguarda le attività di creazione e verifica. L'obiettivo è creare il codice e verificare la qualità del codice e del modello tramite test automatizzati.
Con MLOps, l'integrazione continua può includere:
- Refactoring in script Python o R del codice esplorativo nei notebook di Jupyter.
- Linting per verificare la presenza di eventuali errori stilistici o programmatici negli script Python o R. Ad esempio, controllare se una riga nello script contiene meno di 80 caratteri.
- Unit test per verificare le prestazioni del contenuto degli script. Ad esempio, controllare se il modello genera stime accurate in un set di dati di test.
Suggerimento
Informazioni su come convertire gli esperimenti di Machine Learning nel codice Python di produzione
Per eseguire l'esecuzione di linting e unit test, è possibile usare strumenti di automazione come azure Pipelines in Azure DevOpso GitHub Actions.
Distribuzione continua
Dopo aver verificato la qualità del codice degli script Python o R usati per eseguire il training del modello, è necessario portare il modello nell'ambiente di produzione. Continuous delivery comporta i passaggi da eseguire per distribuire un modello nell'ambiente di produzione, preferibilmente automatizzando il più possibile.
Per distribuire un modello nell'ambiente di produzione, è prima necessario crearne il pacchetto e distribuirlo in un ambiente di pre-produzione . Eseguendo lo staging del modello in un ambiente di pre-produzione, è possibile verificare se tutto funziona come previsto.
Dopo che la distribuzione del modello nella fase di staging è stata completata con successo e senza errori, è possibile approvare la distribuzione del modello nell'ambiente di produzione .
Per collaborare alla creazione di script Python o R per eseguire il training del modello e di qualsiasi codice necessario per distribuire il modello in ogni ambiente, si userà il controllo del codice sorgente.
Controllo del codice sorgente
controllo del codice sorgente (o controllo della versione) viene ottenuto più comunemente usando un repository basato su Git. Un repository fa riferimento al percorso in cui è possibile archiviare tutti i file rilevanti per un progetto software.
Con i progetti di Machine Learning, è probabile che si abbia un repository per ogni progetto disponibile. Il repository includerà notebook di Jupyter, script di training, script di assegnazione dei punteggi e definizioni di pipeline, tra le altre cose.
Nota
È preferibile non archiviare i dati di training nel repository. In alternativa, i dati di training vengono archiviati in un database o in un data lake e vengono recuperati da Azure Machine Learning direttamente dall'origine dati usando archivi dati.
I repository basati su Git sono disponibili tramite Azure Repos in Azure DevOps o un repository GitHub.
Ospitando tutto il codice pertinente in un repository, è possibile collaborare facilmente al codice e tenere traccia delle modifiche apportate da un membro del team. Ogni membro può lavorare sulla propria versione del codice. Sarà possibile visualizzare tutte le modifiche passate ed esaminare le modifiche prima di eseguirne il commit nel repository principale.
Per decidere chi lavora in quale parte del progetto, è consigliabile usare pianificazione agile.
Pianificazione Agile
Poiché si vuole distribuire rapidamente un modello nell'ambiente di produzione, la pianificazione agile è ideale per i progetti di Machine Learning.
La pianificazione Agile consiste nell'isolare il lavoro in sprint. sprint sono brevi periodi di tempo durante i quali si vuole raggiungere parte degli obiettivi del progetto.
L'obiettivo è pianificare gli sprint per migliorare rapidamente qualsiasi codice. Che si tratti di codice usato per l'esplorazione di dati e modelli o per distribuire un modello nell'ambiente di produzione.
Il training di un modello di Machine Learning può essere un processo senza fine. Ad esempio, in qualità di data scientist potrebbe essere necessario migliorare le prestazioni del modello a causa della deriva dei dati. In alternativa, è necessario modificare il modello per allinearlo meglio ai nuovi requisiti aziendali.
Per evitare di dedicare troppo tempo al training del modello, la pianificazione agile può aiutare a definire l'ambito del progetto e aiutare tutti a allinearsi accettando risultati a breve termine.
Per pianificare il lavoro, è possibile usare uno strumento come Azure Boards in Azure DevOps o problemi di GitHub.
Infrastruttura come codice (IaC)
L'applicazione di principi DevOps ai progetti di Machine Learning significa creare soluzioni riproducibili affidabili. In altre parole, tutto ciò che si fa o si crea, si dovrebbe essere in grado di ripetere e automatizzare.
Per ripetere e automatizzare l'infrastruttura necessaria per eseguire il training e la distribuzione del modello, il team userà Infrastructure as Code (IaC). Quando si esegue il training e si distribuiscono modelli in Azure, IaC significa che tutte le risorse di Azure necessarie nel processo sono definite nel codice e il codice viene archiviato in un repository.
Suggerimento
Acquisire familiarità con DevOps esplorando i moduli di Microsoft Learn nel percorso di trasformazione DevOps