Identificare i componenti chiave delle applicazioni LLM
I modelli di linguaggio di grandi dimensioni sono come sistemi sofisticati di elaborazione del linguaggio progettati per comprendere e generare linguaggio umano. Pensa a loro come avere quattro parti essenziali che funzionano insieme, in modo simile a come un'auto necessita di un motore, un sistema di carburante, una trasmissione e un volante per funzionare correttamente.
- Prompt: istruzioni per il modello. Il prompt è il modo in cui si comunica con l'LLM. È la tua domanda, richiesta o istruzione.
- Tokenizer: suddivide il testo in unità linguistiche. Il tokenizer è un traduttore linguistico che converte il testo umano in un formato che il computer può comprendere.
- Modello: "cervello" dell'operazione. Il modello è il "cervello" effettivo che elabora le informazioni e genera risposte. In genere si basa sull'architettura del trasformatore, utilizza meccanismi di auto-attenzione per elaborare il testo e genera risposte contestualmente pertinenti.
- Attività: operazioni che possono essere eseguite da LLMs. Le attività sono i diversi processi correlati alla lingua che possono essere eseguiti da LLMs, ad esempio la classificazione del testo, la traduzione e la generazione di dialoghi.
Questi componenti creano un potente sistema di elaborazione del linguaggio:
- Tu fornisci un prompt (istruzione)
- Il tokenizer lo suddivide (lo rende comprensibile al computer)
- Il modello lo elabora (usando l'architettura Transformer e la self-attention)
- Il modello esegue l'attività (genera la risposta necessaria)
Questo sistema coordinato è ciò che consente alle llms di eseguire attività linguistiche complesse con notevole precisione e fluenza, rendendoli utili per tutto ciò che va dalla scrittura dell'assistenza al servizio clienti alla generazione di contenuti creativi.
Comprendere le attività eseguite dai modelli LLM
I moduli LLM sono progettati per eseguire un'ampia gamma di attività correlate al linguaggio. I modelli LLM sono ideali per le attività di elaborazione del linguaggio naturale o NLP (1), per via della comprensione approfondita che riescono ad avere del testo e del contesto. L'elaborazione del linguaggio naturale (NLP) è il campo dell'intelligenza artificiale incentrato sull'abilitazione dei computer a comprendere, interpretare e generare il linguaggio umano in modo significativo e utile. Nel contesto delle attività LLM, NLP rappresenta la categoria di funzioni correlate al linguaggio che i modelli LLMS eccelleno a causa della comprensione approfondita del testo e del contesto.
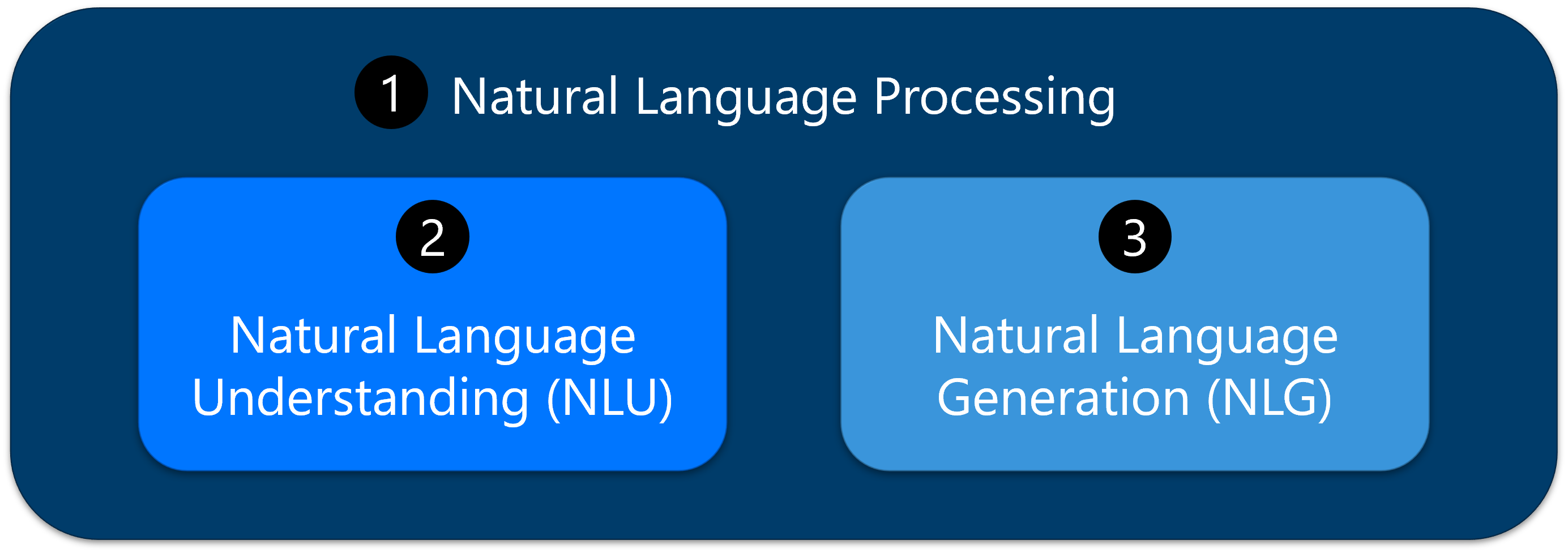
Una categoria di attività NLP include la comprensione del linguaggio naturale, o NLU (2), attività come l'analisi del sentiment, il riconoscimento entità denominata (NER) e la classificazione del testo, che implica l'estrazione del significato e l'identificazione di elementi specifici all'interno del testo.
Un altro set di attività NLP rientra nella generazione del linguaggio naturale, o NLG (3), tra cui completamento del testo, riepilogo, traduzione e creazione di contenuti, in cui il modello genera testo coerente e contestualmente appropriato in base agli input specificati.
I modelli LLM vengono usati anche nei sistemi di dialogo e negli agenti di conversazione, in cui possono partecipare a conversazioni simili a quella umana, fornendo risposte pertinenti e accurate alle query degli utenti.
Comprendere l'importanza del tokenizer
La tokenizzazione è un passaggio fondamentale per la pre-elaborazione in LLMs. Converte il testo umano in un formato che un computer può comprendere. Il testo è suddiviso in unità gestibili denominate token. Questi token possono essere parole, parole secondarie o persino singoli caratteri, a seconda della strategia di tokenizzazione usata.
Il processo di tokenizzazione può essere riepilogato nel modo seguente:
- Suddividere il testo in token: "Hello world" potrebbe diventare ["Hello", "world"] o anche ["Hel", "lo", "wor", "ld"]
- Gestire lingue diverse: Elabora inglese, spagnolo, cinese e così via.
- Rendere efficiente l'elaborazione: I pezzi più piccoli sono più facili da usare per il modello
- Converti in numeri: I computer funzionano con numeri, non lettere, quindi "Hello" diventa qualcosa come [7592, 1917]
I tokenizzatori moderni, ad esempio Byte Pair Encoding (BPE) e WordPiece, sudddividono le parole rare o sconosciute in unità di sottoparole, consentendo al modello di gestire in modo più efficace i termini non presenti nel vocabolario.
Si consideri, ad esempio, la frase seguente:
I heard a dog bark loudly at a cat
Per tokenizzare questo testo, è possibile identificare ogni parola discreta e assegnarle un ID token. Ad esempio:
- I (1)
- heard (2)
- a (3)
- dog (4)
- bark (5)
- loudly (6)
- at (7)
- a (3)
- cat (8)
La frase può ora essere rappresentata con i token:
{1 2 3 4 5 6 7 3 8}
La tokenizzazione consente al modello di mantenere un equilibrio tra le dimensioni del vocabolario e l'efficienza della rappresentazione, assicurandosi che possa elaborare input di testo diversi in modo accurato.
La tokenizzazione consente inoltre al modello di convertire il testo in formati numerici che possono essere elaborati in modo efficiente durante il training e l'inferenza.
Comprendere l'architettura del modello sottostante
Si pensi all'architettura di un LLM come il progetto di una casa: mostra come tutte le parti sono organizzate e interagiscono per creare qualcosa di funzionale.
Gli LLMs vengono costruiti usando qualcosa chiamato architettura del trasformatore. Immagina di leggere un libro e di dover capire come le diverse frasi si relazionano tra loro. L'approccio tradizionale consiste nel leggere parola per parola, da sinistra a destra, come si legge normalmente. Nell'approccio al trasformatore, è possibile guardare l'intera pagina contemporaneamente e vedere immediatamente come tutte le parole si connettono tra loro.
L'auto-attenzione è un'innovazione chiave usata nell'architettura del trasformatore. È come avere un evidenziatore super intelligente che contrassegna automaticamente le parole più importanti per comprendere ogni frase.
Ad esempio: nella frase "Il cane inseguiva la palla perché era eccitato", l'auto-attenzione aiuta il modello a sapere che "it" si riferisce al "cane" (non la palla), anche se "cane" appare in precedenza nella frase.
I trasformatori sono costituiti da livelli di codificatori e decodificatori che interagiscono per analizzare il testo di input e generare gli output. Il meccanismo di auto-attenzione consente al modello di valutare l'importanza di parole diverse all'interno di una frase, consentendogli di acquisire le dipendenze a lungo raggio e il contesto in modo efficace.
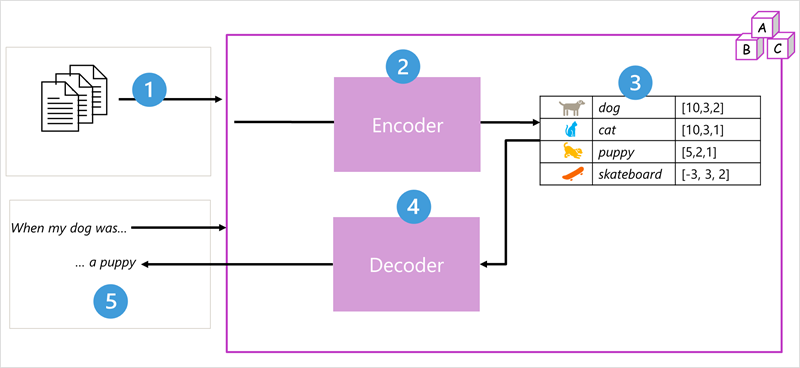
Si userà questo diagramma come esempio del funzionamento dell'elaborazione LLM.
Il LLM è addestrato su un volume elevato di testo in linguaggio naturale.
Passaggio 1: Input - Documenti di addestramento e una richiesta "Quando il mio cane era..." entrano nel sistema.
Passaggio 2: Codificatore (Analizzatore): suddivide il testo in token e ne analizza il significato. Il blocco del codificatore elabora le sequenze di token usando l'auto-attenzione per determinare le relazioni tra token o parole.
Passaggio 3: Vengono creati gli incorporamenti: l'output del codificatore è una raccolta di vettori (matrici numeriche multivalore) in cui ogni elemento del vettore rappresenta un attributo semantico dei token. Questi vettori sono detti incorporamenti. Sono rappresentazioni numeriche che acquisiscono significato:
- cane [10,3,2] - animale, animale domestico, soggetto
- gatto [10,3,1] - animale, animale domestico, specie diverse
- cucciolo [5,2,1] - giovane animale, correlato al cane
- skateboard [-3,3,2] - oggetto, non correlato agli animali
Passaggio 4: decodificatore (lo scrittore) - Il blocco decodificatore funziona su una nuova sequenza di token di testo e usa gli embedding generati dal codificatore per generare un output del linguaggio naturale appropriato. Confronta le opzioni e sceglie la risposta più appropriata.
Passaggio 5: Output generato - Data una sequenza input come
When my dog was, il modello può usare il meccanismo di auto-attenzione per analizzare i token di input e gli attributi semantici codificati negli incorporamenti al fine di prevedere un completamento appropriato della frase, ad esempioa puppy.
Questa architettura è altamente parallelizzabile, rendendola efficiente per il training su set di dati di grandi dimensioni. Le dimensioni dell'LLM, spesso definite dal numero di parametri, determinano la capacità di archiviare le conoscenze linguistiche ed eseguire attività complesse. Si pensi ai parametri come milioni o miliardi di celle di memoria minuscole che archivia regole e modelli del linguaggio. Più celle di memoria indicano che il modello può ricordare di più sul linguaggio e gestire le attività più difficili. I modelli di grandi dimensioni, ad esempio GPT-3 e GPT-4, contengono miliardi di parametri, consentendo loro di archiviare una vasta conoscenza del linguaggio.
Comprendere l'importanza del prompt
I prompt sono gli input iniziali forniti ai moduli LLM per guidarne le risposte. Sono il direttore d'orchestra che fa in modo che tutti e quattro i componenti LLM (prompt, tokenizer, modello, output) interagiscano in modo efficace. La qualità e la chiarezza del prompt influenzano significativamente le prestazioni del modello e un prompt ben strutturato può portare a risposte più accurate e pertinenti.
La creazione di richieste efficaci è fondamentale per ottenere l'output desiderato dal modello. I prompt possono variare da semplici istruzioni a query complesse, e il modello genera testo in base al contesto e alle informazioni fornite nel prompt.
Ad esempio, un prompt può essere:
Translate the following English text to French: "Hello, how are you?"
Oltre alle richieste standard, tecniche come la prompt engineering (ingegneria dei prompt) comportano l'affinamento e l'ottimizzazione delle richieste per migliorare l'output del modello per attività o applicazioni specifiche.
Esempio di prompt engineering, in cui vengono fornite istruzioni più dettagliate:
Generate a creative story about a time-traveling scientist who discovers a new planet. Include elements of adventure and mystery.
L'interazione tra attività, tokenizzazione, modello e richieste è ciò che rende i modelli LLM così potenti e versatili. La capacità del modello di eseguire varie attività migliora quando si dispone di una tokenizzazione efficace, che garantisce che gli input di testo vengano elaborati in modo accurato. L'architettura basata su trasformatore consente al modello di comprendere e generare testo in base ai token e al contesto fornito dalle richieste.