Usare gli LLM per le attività di elaborazione del linguaggio naturale (NLP)
Le attività comuni di elaborazione del linguaggio naturale (NLP) sfruttano le funzionalità di modelli di linguaggio di grandi dimensioni (LLMs) per affrontare un'ampia gamma di problemi correlati al linguaggio.
Queste attività includono:
- Riepilogo: Condensare testi lunghi in riepiloghi concisi.
- Analisi valutazione: Identifica il tono emotivo del testo.
- Traduzione: Convertire il testo tra le lingue.
- Classificazione zero-shot: Classificare il testo in etichette predefinite senza esempi precedenti.
- Attività di apprendimento few-shot: Adattarsi alle nuove attività con dati di training minimi.
Queste applicazioni illustrano il potenziale trasformativo di LLMS nell'elaborazione e nella comprensione del linguaggio umano.
Verranno ora esaminate in modo più dettagliato ognuna di queste attività.
Riassumere testo
Il riepilogo è un'attività NLP comune in cui un modello linguistico condensa una lunga parte di testo in una versione più breve mantenendo al tempo stesso le informazioni chiave e le idee principali.
Esistono due tipi di riepilogo:
- Il riepilogo estrattivo implica la selezione di frasi o enunciati importanti direttamente dal testo di origine.
- Il riepilogo astrattivo genera nuove frasi che acquisiscono l'essenza del testo originale.
Gli LLM, con la loro conoscenza avanzata del contesto e del linguaggio, eccellono nel riepilogo astrattivo, producendo riepiloghi coerenti e contestualmente accurati.
È possibile usare il riepilogo in varie applicazioni, ad esempio la generazione di brevi notizie, il riepilogo dei documenti di ricerca e la creazione di report concisi.

Eseguire l'analisi del sentiment
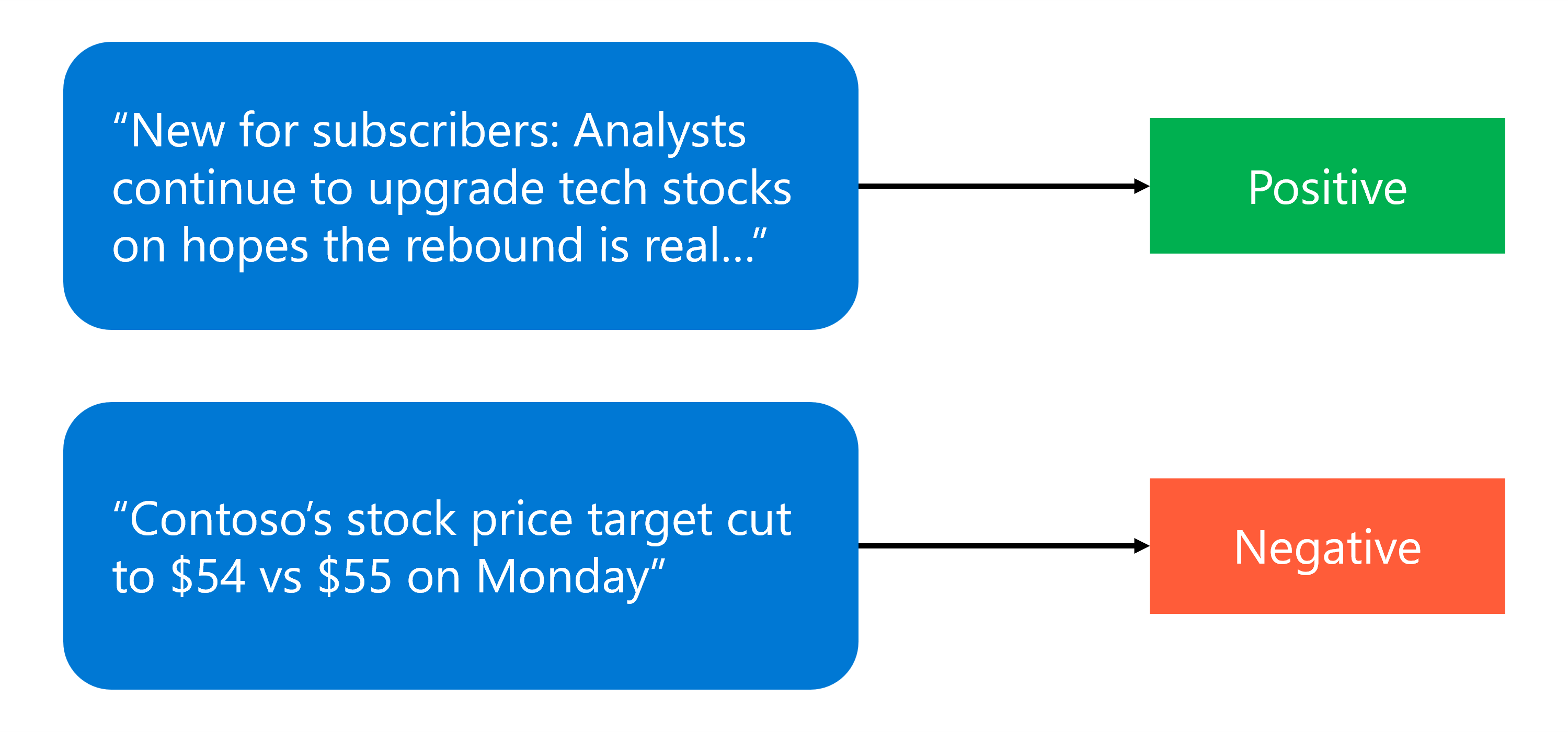
L'analisi del sentiment, nota anche come opinion mining, è il processo di determinazione del tono emotivo dietro un corpo di testo.
L'analisi del sentiment prevede la classificazione del testo in categorie come sentiment positivo, negativo o neutro.
Gli LLM sono molto efficaci in questo compito grazie alla loro capacità di comprendere le sfumature del linguaggio e del contesto. Analizzando la scelta delle parole, la struttura delle frasi e il contesto, questi modelli possono misurare accuratamente il sentiment espresso in recensioni, post di social media, feedback dei clienti e altro ancora.
L'analisi del sentiment è ampiamente usata nelle aziende per monitorare la reputazione del marchio, misurare la soddisfazione dei clienti e comprendere l'opinione pubblica su vari argomenti.
Tradurre testo
La traduzione è l'attività di conversione del testo da una lingua a un'altra, e gli LLM hanno rivoluzionato questo campo con la loro capacità di eseguire traduzioni automatiche di alta qualità.
Questi modelli linguistici usano grandi set di dati multilingue e architetture di rete neurale sofisticate per comprendere e generare testo in più lingue. Gli LLM possono acquisire le sfumature e le espressioni idiomatiche di lingue diverse e produrre traduzioni non solo accurate, ma anche contestualmente appropriate.
Rispetto alle tecniche precedenti per la traduzione, gli LLM sono spesso più accurati in quanto possono comprendere il significato semantico di un testo prima di tradurlo, il che comporta traduzioni meno letterali.
La traduzione automatica basata su LLM è essenziale per la comunicazione globale, consentendo alle aziende, ai governi e agli individui di interagire attraverso barriere linguistiche con maggiore facilità e precisione.
Usare la classificazione zero-shot
La classificazione zero-shot è una tecnica in cui un LLM può classificare il testo in etichette predefinite senza visualizzare esempi etichettati durante il training.
La classificazione zero-shot viene ottenuta usando l'ampia conoscenza generale e la comprensione del linguaggio del modello.
Si fornisce una descrizione in linguaggio naturale delle etichette e il modello classifica il testo in base a questo input.
La classificazione zero-shot è estremamente versatile ed efficiente, in quanto elimina la necessità di set di dati di training di grandi dimensioni etichettati specifici per ogni nuova attività. Questa funzionalità è utile nei campi in cui emergono spesso nuove categorie, consentendo l'adattamento immediato e l'applicazione.
Usare l'attività di apprendimento few-shot
Quando si usa l'apprendimento few-shot, si fornisce un LLM con alcuni esempi prima di eseguire un'attività specifica.
Fornire un modello con alcuni esempi, consente al modello di adattarsi rapidamente alle nuove attività con dati minimi, usando la conoscenza del linguaggio stabilita.
L'apprendimento few-shot è vantaggioso negli scenari in cui i dati etichettati sono scarsi o costosi da ottenere. Fornendo alcuni esempi, è possibile guidare il modello per eseguire attività specializzate, ad esempio la classificazione del testo specifica del dominio, l'analisi del sentiment personalizzata o il riconoscimento di entità.
La flessibilità e l'efficienza rendono l'apprendimento few-shot uno strumento potente per la distribuzione di VM in diverse applicazioni reali.
Ad esempio, esplorare il prompt seguente che include l'apprendimento few-shot:
## Instructions
For each tweet, describe its sentiment.
## Examples
Tweet: I hate it when my phone battery dies
Sentiment: Negative
Tweet: My day has been great
Sentiment: Positive
Tweet: This is the ink to the article
Sentiment: Neutral
Tweet: This new music video is incredible
Sentiment: Positive
Il LLM usa gli esempi per comprendere cosa deve fare e completa il prompt restituendo il sentiment dell'ultimo tweet.
Ora che sono state esaminate varie attività per i moduli APM, è possibile usare Azure Databricks per sperimentare gli LLM open source e testarne le funzionalità con le richieste.