Modelli linguistici semantici
Annotazioni
Per altri dettagli, vedi la scheda Testo e immagini .
Poiché lo stato dell'arte per l'elaborazione del linguaggio naturale è avanzato, la possibilità di addestrare modelli che incapsulano la relazione semantica tra token ha portato all'emergere di potenti modelli linguistici di apprendimento profondo. Al centro di questi modelli è la codifica dei token di lingua come vettori (matrici multivalore di numeri) note come incorporamenti .
Questo approccio basato su vettori per la modellazione del testo è diventato comune con tecniche come Word2Vec e GloVe, in cui i token di testo sono rappresentati come vettori densi con più dimensioni. Durante il training del modello, i valori delle dimensioni vengono assegnati per riflettere le caratteristiche semantiche di ogni token in base all'utilizzo nel testo di training. Le relazioni matematiche tra i vettori possono quindi essere sfruttate per eseguire attività comuni di analisi del testo in modo più efficiente rispetto alle tecniche puramente statistiche precedenti. Un avanzamento più recente di questo approccio consiste nell'usare una tecnica chiamata attenzione per considerare ogni token nel contesto e calcolare l'influenza dei token intorno. Gli incorporamenti contestualizzati risultanti, ad esempio quelli presenti nella famiglia di modelli GPT, forniscono la base dell'intelligenza artificiale generativa moderna.
Rappresentazione di testo come vettori
I vettori rappresentano punti nello spazio multidimensionale, definiti dalle coordinate lungo più assi. Ogni vettore descrive una direzione e una distanza dall'origine. I token semanticamente simili dovrebbero comportare vettori con un orientamento simile, in altre parole puntano in direzioni simili.
Si considerino ad esempio gli incorporamenti tridimensionali seguenti per alcune parole comuni:
| Parola | Vector |
|---|---|
dog |
[0.8, 0.6, 0.1] |
puppy |
[0.9, 0.7, 0.4] |
cat |
[0.7, 0.5, 0.2] |
kitten |
[0.8, 0.6, 0.5] |
young |
[0.1, 0.1, 0.3] |
ball |
[0.3, 0.9, 0.1] |
tree |
[0.2, 0.1, 0.9] |
È possibile visualizzare questi vettori nello spazio tridimensionale, come illustrato di seguito:

I vettori per "dog" e "cat" sono simili (entrambi gli animali domestici), come sono "puppy" e "kitten" (entrambi i giovani animali). Le parole "tree", "young"e ball" hanno orientamenti di vettore distinti, riflettendo i loro diversi significati semantici.
La caratteristica semantica codificata nei vettori consente di usare operazioni basate su vettori che confrontano parole e abilitano confronti analitici.
Ricerca di termini correlati
Poiché l'orientamento dei vettori è determinato dai valori delle dimensioni, le parole con significati semantici simili tendono ad avere orientamenti simili. Ciò significa che è possibile usare calcoli come la somiglianza del coseno tra vettori per eseguire confronti significativi.
Ad esempio, per determinare l'"elemento dispari" tra "dog", "cat" e "tree", è possibile calcolare la somiglianza del coseno tra coppie di vettori. La somiglianza coseno viene calcolata come:
cosine_similarity(A, B) = (A · B) / (||A|| * ||B||)
Dove A · B è il prodotto punto e ||A|| è la grandezza del vettore A.
Calcolo delle analogie tra le tre parole:
dog[0.8, 0.6, 0.1] ecat[0.7, 0.5, 0.2]:- Prodotto punto: (0,8 × 0,7) + (0,6 × 0,5) + (0,1 × 0,2) = 0,56 + 0,30 + 0,02 = 0,88
- Grandezza di
dog: √(0,8² + 0,6² + 0,1²) = √(0,64 + 0,36 + 0,01) = √1,01 ≈ 1,005 - Grandezza di
cat: √(0,7² + 0,5² + 0,2²) = √(0,49 + 0,25 + 0,04) = √0,78 ≈ 0,883 - Somiglianza del coseno: 0,88 / (1,005 × 0,883) ≈ 0,992 (somiglianza elevata)
dog[0.8, 0.6, 0.1] etree[0.2, 0.1, 0.9]:- Prodotto scalare: (0,8 · 0,2) + (0,6 · 0,1) + (0,1 · 0,9) = 0,16 + 0,06 + 0,09 = 0,31
- Grandezza di
tree: √(0,2² + 0,1² + 0,9²) = √(0,04 + 0,01 + 0,81) = √0,86 ≈ 0,927 - Somiglianza del coseno: 0,31 / (1,005 × 0,927) ≈ 0,333 (somiglianza bassa)
cat[0.7, 0.5, 0.2] etree[0.2, 0.1, 0.9]:- Prodotto punto: (0,7 × 0,2) + (0,5 × 0,1) + (0,2 × 0,9) = 0,14 + 0,05 + 0,18 = 0,37
- Somiglianza del coseno: 0,37 / (0,883 × 0,927) ≈ 0,452 (somiglianza bassa)
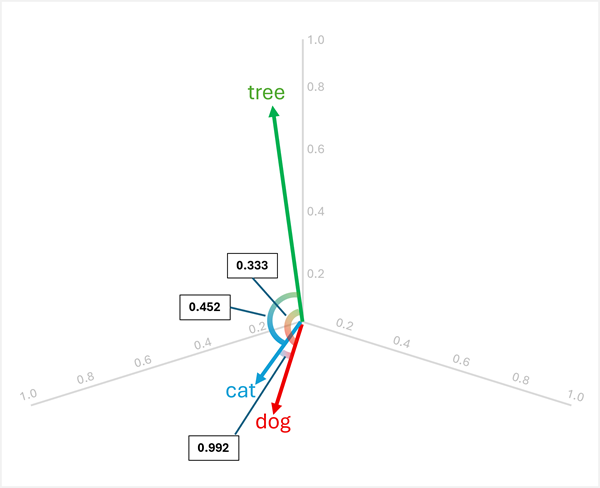
I risultati mostrano che "dog" e "cat" sono molto simili (0,992), mentre "tree" ha una somiglianza inferiore a "dog" (0,333) e "cat" (0,452). Pertanto, tree è chiaramente l'elemento che non c'entra.
Conversione vettoriale tramite addizione e sottrazione
È possibile aggiungere o sottrarre vettori per produrre nuovi risultati basati su vettori; che può quindi essere usato per trovare i token con vettori corrispondenti. Questa tecnica consente alla logica aritmetica intuitiva di determinare i termini appropriati in base alle relazioni linguistiche.
Ad esempio, usando i vettori precedenti:
-
dog+young= [0.8, 0.6, 0.1] + [0.1, 0.1, 0.3] = [0.9, 0.7, 0.4] =puppy -
cat+young= [0.7, 0.5, 0.2] + [0.1, 0.1, 0.3] = [0.8, 0.6, 0,5] =kitten
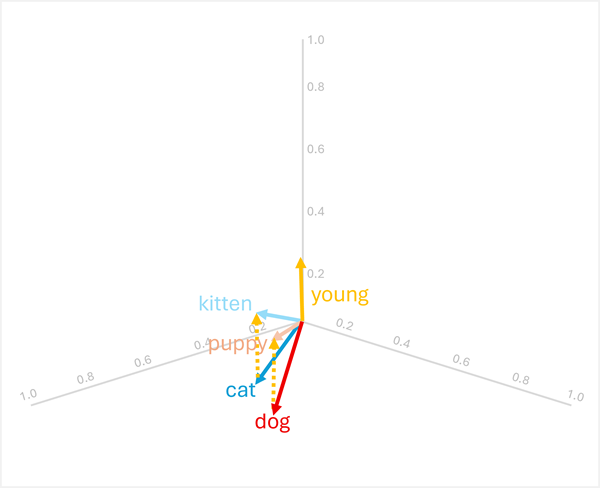
Queste operazioni funzionano perché il vettore per "young" codifica la trasformazione semantica da un animale adulto alla sua controparte giovane.
Annotazioni
In pratica, l'aritmetica vettoriale produce raramente corrispondenze esatte; È invece necessario cercare la parola il cui vettore è più vicino (più simile) al risultato.
L'aritmetica funziona anche inversamente:
-
puppy-young= [0.9, 0.7, 0.4] - [0.1, 0.1, 0.3] = [0.8, 0.6, 0.1] =dog -
kitten-young= [0.8, 0.6, 0.5] - [0.1, 0.1, 0.3] = [0.7, 0.5, 0.2] =cat
Ragionamento analogico
L'aritmetica vettoriale può anche rispondere a domande analogiche come "puppy è a dog come kitten è a ?"
Per risolvere questo problema, calcolare: kitten - puppy + dog
- [0.8, 0.6, 0.5] - [0.9, 0.7, 0.4] + [0.8, 0.6, 0.1]
- = [-0.1, -0.1, 0.1] + [0.8, 0.6, 0.1]
- = [0.7, 0.5, 0.2]
- =
cat
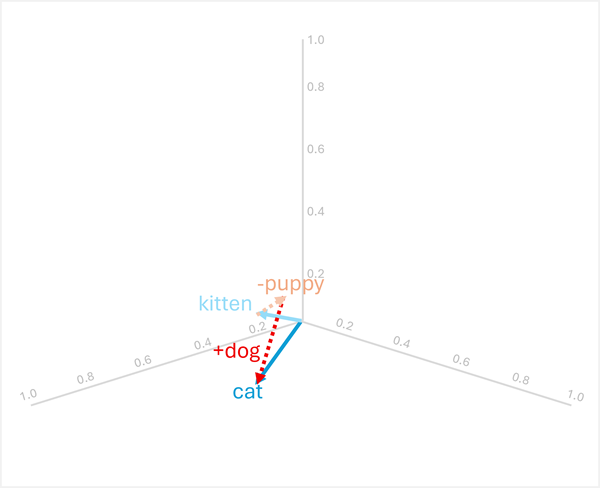
Questi esempi illustrano in che modo le operazioni vettoriali possono acquisire relazioni linguistiche e abilitare il ragionamento sui modelli semantici.
Uso di modelli semantici per l'analisi del testo
I modelli semantici basati su vettori offrono potenti funzionalità per molte attività comuni di analisi del testo.
Esecuzione del riepilogo del testo
Gli incorporamenti semantici consentono il riepilogo estrativo identificando le frasi con vettori più rappresentativi del documento complessivo. Codificando ogni frase come vettore (spesso mediando o raggruppando le incorporazioni delle parole costitutive), è possibile calcolare quali frasi sono più centrali per il significato del documento. Queste frasi centrali possono essere estratte per formare un riepilogo che acquisisce i temi chiave.
Estrazione di parole chiave
La somiglianza vettoriale può identificare i termini più importanti in un documento confrontando l'incorporamento di ogni parola con la rappresentazione semantica complessiva del documento. Le parole i cui vettori sono quelli più simili al vettore del documento, o più centrali quando si considerano tutti i vettori di parola nel documento, sono probabilmente termini chiave che rappresentano gli argomenti principali.
Riconoscimento di entità denominate
I modelli semantici possono essere ottimizzati per riconoscere le entità denominate (persone, organizzazioni, posizioni e così via) imparando rappresentazioni vettoriali che raggruppano tipi di entità simili. Durante l'inferenza, il modello esamina l'incorporamento di ogni token e il relativo contesto per determinare se rappresenta un'entità denominata e, in tal caso, quale tipo.
Classificazione del testo
Per attività come l'analisi del sentiment o la categorizzazione degli argomenti, i documenti possono essere rappresentati come vettori di aggregazione ,ad esempio la media di tutti gli incorporamenti di parole nel documento. Questi vettori di documento possono quindi essere usati come funzionalità per i classificatori di Machine Learning o confrontati direttamente con i vettori prototipo di classe per assegnare categorie. Poiché i documenti semanticamente simili hanno orientamenti vettoriali simili, questo approccio raggruppa efficacemente il contenuto correlato e distingue categorie diverse.