Modelli LLM (Large Language Model) di GitHub Copilot
GitHub Copilot è basato su modelli linguistici di grandi dimensioni (LLM) per fornire assistenza per la scrittura di codice. In questa unità viene illustrato come comprendere l'integrazione e l'impatto dei modelli linguistici di grandi dimensioni (LLM) in GitHub Copilot. Verranno esaminati gli argomenti seguenti:
- Che cosa sono i modelli linguistici di grandi dimensioni (LLM)?
- Ruolo dei modelli linguistici di grandi dimensioni (LLM) in GitHub Copilot e nella creazione di richieste
- Ottimizzazione dei modelli linguistici di grandi dimensioni (LLM)
- Ottimizzazione LoRA
Che cosa sono i modelli linguistici di grandi dimensioni (LLM)?
I modelli linguistici di grandi dimensioni (LLM) sono modelli di intelligenza artificiale progettati e sottoposti a training per comprendere, generare e manipolare il linguaggio umano. Questi modelli includono la capacità di gestire un'ampia gamma di attività che coinvolgono il testo, grazie alla grande quantità di dati di testo su cui viene eseguito il training. Di seguito sono riportati alcuni aspetti principali da comprendere sui modelli linguistici di grandi dimensioni (LLM)i:
Volume dei dati di training
I modelli linguistici di grandi dimensioni (LLM) vengono esposti a grandi quantità di testo da origini diverse. Questa esposizione consente di ottenere una vasta comprensione del linguaggio, del contesto e delle complessità coinvolte in varie forme di comunicazione.
Comprensione contestuale
Questi modelli risultano eccellenti nella generazione di testo contestualmente pertinente e coerente. La loro capacità di comprendere il contesto consente loro di fornire contributi significativi, indipendentemente dal fatto che si tratti di completare frasi, paragrafi o persino di generare interi documenti contestualmente appropriati.
Integrazione di apprendimento automatico e intelligenza artificiale
I modelli linguistici di grandi dimensioni (LLM) sono basati sui principi dell'apprendimento automatico e dell'intelligenza artificiale. Si tratta di reti neurali con milioni, o anche miliardi, di parametri ottimizzati durante il processo di training per comprendere e prevedere il testo in modo efficace.
Versatilità
Questi modelli non sono limitati a un tipo specifico di testo o linguaggio. Possono essere personalizzati e ottimizzati per eseguire attività specializzate e risultano quindi estremamente versatili e applicabili in vari domini e linguaggi.
Ruolo dei modelli linguistici di grandi dimensioni (LLM) in GitHub Copilot e nella creazione di richieste
GitHub Copilot usa i modelli linguistici di grandi dimensioni (LLM) per fornire suggerimenti sul codice in grado di riconoscere il contesto. Il modello linguistico di grandi dimensioni (LLM) esamina non solo il file corrente, ma anche altri file aperti e schede nell'IDE per generare completamenti del codice accurati e pertinenti. Questo approccio dinamico garantisce suggerimenti personalizzati, migliorando quindi la produttività.
Ottimizzazione dei modelli linguistici di grandi dimensioni (LLM)
L'ottimizzazione è un processo critico che consente di personalizzare i modelli linguistici di grandi dimensioni (LLM) con training preliminare per attività o domini specifici. Implica il training del modello su un set di dati specifico dell'attività più piccolo, noto come set di dati di destinazione, usando al tempo stesso le informazioni e i parametri ottenuti da un set di dati con training preliminare di grandi dimensioni, detto modello di origine.
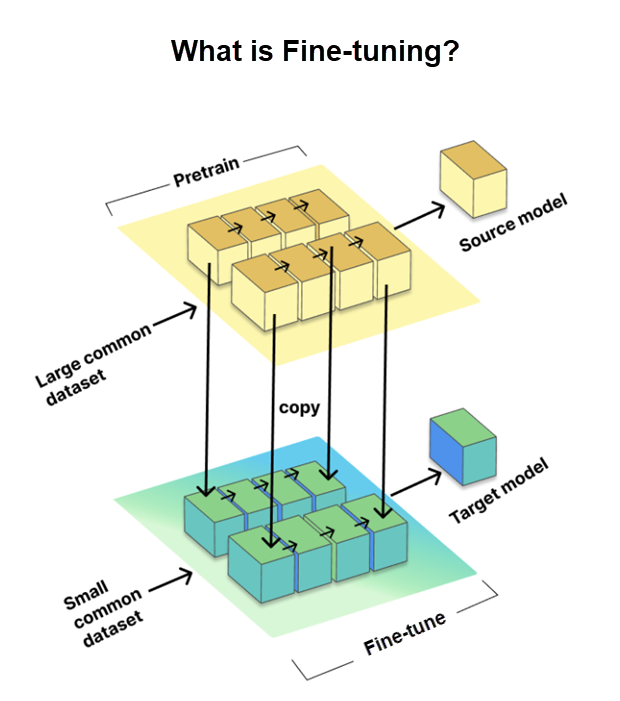
L'ottimizzazione è essenziale per adattare i modelli linguistici di grandi dimensioni (LLM) per attività specifiche, migliorandone quindi le prestazioni. GitHub ha fatto tuttavia un ulteriore passo avanti usando il metodo di ottimizzazione LoRA, che viene illustrato di seguito.
Ottimizzazione LoRA
L'ottimizzazione completa tradizionale comporta l'esecuzione del training di tutte le parti di una rete neurale, che può essere un'operazione lenta e fortemente dipendente dalle risorse. Ma l'ottimizzazione LoRA (Low-Rank Adaptation) è un'alternativa intelligente. Viene usato per migliorare il funzionamento di modelli linguistici di grandi dimensioni (LLM) con training preliminare per attività specifiche senza ripetere tutto il training.
Ecco come funziona LoRA:
- LoRA aggiunge parti sottoponibili a training più piccole a ogni livello del modello con training preliminare invece di modificare tutto.
- Il modello originale rimane invariato, consentendo quindi di risparmiare tempo e risorse.
Vantaggi di LoRA:
- Offre prestazioni migliori rispetto ad altri metodi di adattamento, ad esempio adattatori e ottimizzazione del prefisso.
- Consente di ottenere ottimi risultati con meno parti in movimento.
In breve, l'ottimizzazione LoRA consiste nel lavorare in modo più intelligente, non più difficile, per migliorare i modelli linguistici di grandi dimensioni (LLM) per i requisiti di codifica specifici quando si usa Copilot.