Preparare il modello con la generazione aumentata di recupero
L'ingegneria del prompt aiuta a guidare la risposta di un modello, ma non può fornire conoscenze che non possiede già. I modelli linguistici vengono sottoposti a training su set di dati di grandi dimensioni, ma i dati di training hanno una data di scadenza e non includono le informazioni private dell'organizzazione. Quando un modello non dispone di contesto rilevante, potrebbe generare risposte che suonano plausibili ma sono effettivamente errate.
Per affrontare questa sfida, è possibile basare il modello fornendogli dati rilevanti e concreti su cui basare le risposte. Il recupero della generazione aumentata (RAG) è la tecnica più comune per basare un modello linguistico.
Comprendere le nozioni di base
Quando si usa un modello linguistico senza fondamento, le uniche informazioni provengono dai suoi dati di addestramento. Il risultato potrebbe essere grammaticalmente corretto e strutturato logicamente, ma potrebbe essere impreciso o includere dettagli fabbricati. Ad esempio, chiedere "Quali hotel offrono a Parigi?" senza dati di base potrebbero restituire nomi fittizi di hotel.
Quando si verifica un prompt, si forniscono dati pertinenti da un'origine attendibile insieme alla domanda dell'utente. Il modello genera quindi una risposta basata su tali dati, producendo risposte più accurate e contestualmente pertinenti.
Considerare la differenza:
- Non fondato: il modello si basa solo sui dati di training e potrebbe inventare nomi di hotel o dettagli.
- Basato su dati reali: il modello riceve come contesto i dati effettivi del catalogo degli hotel e risponde con nomi, prezzi e disponibilità reali degli hotel.
Il grounding migliora l'accuratezza effettiva delle risposte collegando il modello a informazioni specifiche, correnti e pertinenti alle esigenze dell'utente.
Funzionamento di RAG
Rag è un modello che recupera informazioni rilevanti da un'origine dati e lo include nella richiesta prima che il modello generi una risposta. Il processo segue tre passaggi:
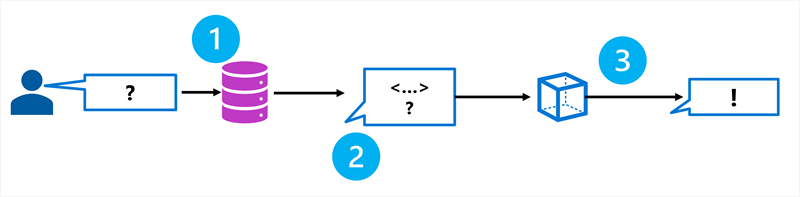
- Retrieve: cercare informazioni rilevanti per la domanda dell'utente in un'origine dati.
- Aumenta: aggiungere le informazioni recuperate al prompt come contesto.
- Genera: inviare il prompt arricchito al modello linguistico per generare una risposta fondata.
Recuperando il contesto da una fonte di dati specificata, si assicura che il modello utilizzi informazioni rilevanti e aggiornate anziché basarsi esclusivamente sui dati di formazione.
Creare incorporamenti per la ricerca
Un componente critico di RAG è la possibilità di trovare in modo efficiente le informazioni più rilevanti nell'origine dati. Questo è il percorso in cui sono disponibili incorporamenti e ricerca vettoriale .
Un incorporamento è una rappresentazione matematica del testo come vettore, ovvero un elenco di numeri a virgola mobile che acquisisce il significato di parole, frasi o documenti. È possibile creare incorporamenti inviando il contenuto a un modello di incorporamento, ad esempio un modello di incorporamento di Azure OpenAI disponibile in Microsoft Foundry.
Si supponga, ad esempio, di creare due documenti:
- "I bambini giocavano allegramente nel parco".
- "I bambini correvano felicemente nel parco giochi".
Queste frasi usano parole diverse, ma hanno significati simili. Quando si creano incorporamenti per ognuno di essi, i relativi vettori vengono vicini nello spazio multidimensionale, riflettendone la somiglianza semantica.
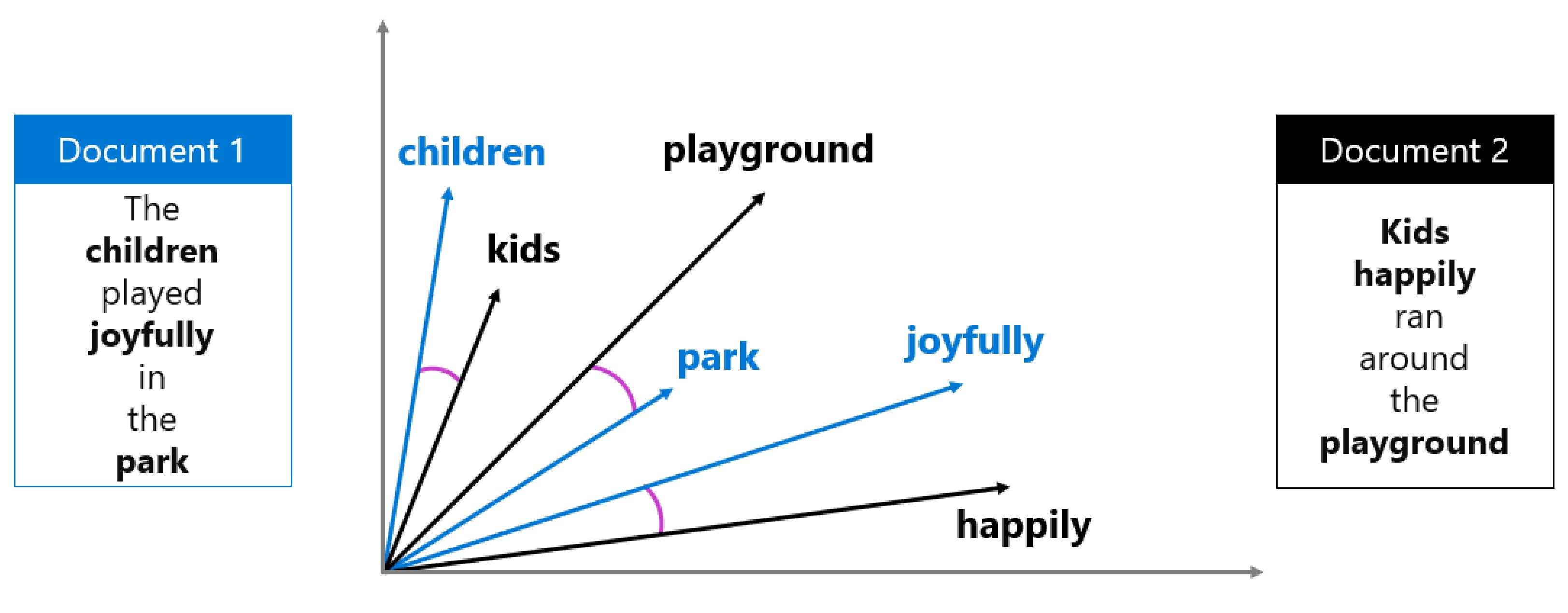
La somiglianza del coseno misura il modo in cui due vettori sono vicini calcolando l'angolo tra di essi. Un valore vicino a 1 indica che i vettori sono molto simili. Questo approccio matematico consente di trovare documenti pertinenti anche quando le parole esatte non corrispondono.
Usare Azure AI Search per il recupero
Azure AI Search fornisce il componente di recupero per le soluzioni RAG in Microsoft Foundry. Consente di portare dati personalizzati, creare un indice ricercabile ed eseguirne una query per recuperare le informazioni pertinenti.
Per usare Azure AI Search con RAG, è possibile:
- Aggiungi i dati a Microsoft Foundry da origini come Azure Blob Storage, Azure Data Lake Storage Gen2 o Microsoft OneLake. È anche possibile caricare direttamente i file.
- Creare un indice usando un modello di incorporamento per generare rappresentazioni vettoriali del contenuto. L'indice viene archiviato in Azure AI Search.
- Interrogare l'indice quando un utente pone una domanda. Il sistema converte la domanda in un incorporamento, cerca il contenuto più simile e restituisce i risultati pertinenti.
Azure AI Search supporta diverse tecniche di ricerca:
- Ricerca di parole chiave: corrisponde a termini esatti nella query al testo nell'indice.
- Ricerca semantica: usa modelli semantici per trovare la corrispondenza con il significato della query anziché con parole chiave esatte.
- Ricerca vettoriale: usa incorporamenti per trovare contenuto semanticamente simile.
- Ricerca ibrida: combina parole chiave, semantica e ricerca vettoriale per i risultati più accurati. La ricerca ibrida è consigliata per le applicazioni di intelligenza artificiale generative.
Implementare RAG con il Azure AI Foundry SDK
Dopo aver creato un indice Azure AI Search, è possibile connetterlo a un modello tramite microsoft Foundry project. Il SDK azure-ai-projects consente di ottenere un client OpenAI autenticato e di usare l'API delle Risposte per generare risposte fondate.
Il codice Python seguente illustra un'implementazione di base:
from azure.ai.projects import AIProjectClient
from azure.identity import DefaultAzureCredential
project = AIProjectClient(
endpoint=os.environ["PROJECT_ENDPOINT"],
credential=DefaultAzureCredential(),
)
client = project.get_openai_client()
response = client.responses.create(
model="gpt-4o",
input=[
{"role": "system", "content": "You are a helpful travel advisor. "
"Use the following hotel data to answer: " + retrieved_context},
{"role": "user", "content": "Which hotels do you offer in Paris?"},
],
)
print(response.output_text)
In questo esempio retrieved_context rappresenta i documenti restituiti dall'indice Azure AI Search. Inserendo tali risultati nel messaggio del sistema, la risposta del modello è basata sui tuoi dati effettivi anziché sulle sue conoscenze generali derivate dal training.
Quando usare RAG
Rag è più efficace quando:
- Il modello necessita di conoscenze specifiche del dominio: l'organizzazione dispone di dati privati su cui il modello non è stato sottoposto a training, ad esempio un catalogo di prodotti, documenti di criteri o knowledge base interni.
- Modifiche frequenti delle informazioni: i dati vengono aggiornati regolarmente, ad esempio inventario, prezzi o notizie. RAG recupera i dati attuali al momento della query senza dover ripetere il training.
- L'accuratezza effettiva è fondamentale: sono necessarie risposte basate su dati reali anziché sulle conoscenze generali del modello.
- I dati di training del modello di base hanno un limite: gli eventi o le informazioni che si sono verificati dopo la data di scadenza del training del modello devono essere accessibili.
Per lo scenario dell'agenzia di viaggi, RAG consente ai clienti di porre domande su hotel, destinazioni e criteri di prenotazione specifici, tutti contenuti nei dati effettivi del catalogo dell'agenzia.
Suggerimento
Se si creano agenti che necessitano di conoscenze radicate senza dover gestire la propria infrastruttura di ricerca, prendere in considerazione Foundry IQ, un archivio di conoscenze gestito che semplifica l'ancoraggio per gli agenti di intelligenza artificiale. Per ulteriori informazioni, consultare Costruisci agenti AI potenziati dalla conoscenza con Foundry IQ.