Esercizio - Eseguire lo streaming dei dati Kafka in un notebook di Jupyter e definire finestre temporali per i dati
Il cluster Kafka sta scrivendo i dati nel log per una successiva elaborazione tramite Spark Structured Streaming.
Nell'esempio clonato è incluso un notebook di Spark, che deve essere caricato nel cluster Spark per l'uso.
Caricare il notebook Python nel cluster Spark
Nel portale di Azure fare clic su Home > Cluster HDInsight e quindi selezionare il cluster Spark appena creato (non il cluster Kafka).
Nel riquadro Dashboard cluster fare clic su Notebook di Jupyter.

Quando vengono richieste le credenziali, immettere un nome utente di amministratore e la password definita durante la creazione dei cluster. Verrà visualizzato il sito Web di Jupyter.
Fare clic su PySpark e nella pagina PySpark fare clic su Carica.
Passare al percorso in cui l'esempio è stato scaricato da GitHub, selezionare il file RealTimeStocks.ipynb, fare clic su Apri, quindi su Carica e infine fare clic su Aggiorna nel browser Internet.
Dopo il caricamento del notebook nella cartella PySpark, fare clic su RealTimeStocks.ipynb per aprire il notebook nel browser.
Eseguire la prima cella nel notebook posizionando il cursore nella cella e quindi premendo MAIUSC+INVIO.
La cella Configure Libraries and Packages risulta completata quando viene visualizzato il messaggio di avvio dell'applicazione Spark insieme a informazioni aggiuntive, come illustrato nella didascalia della schermata seguente.
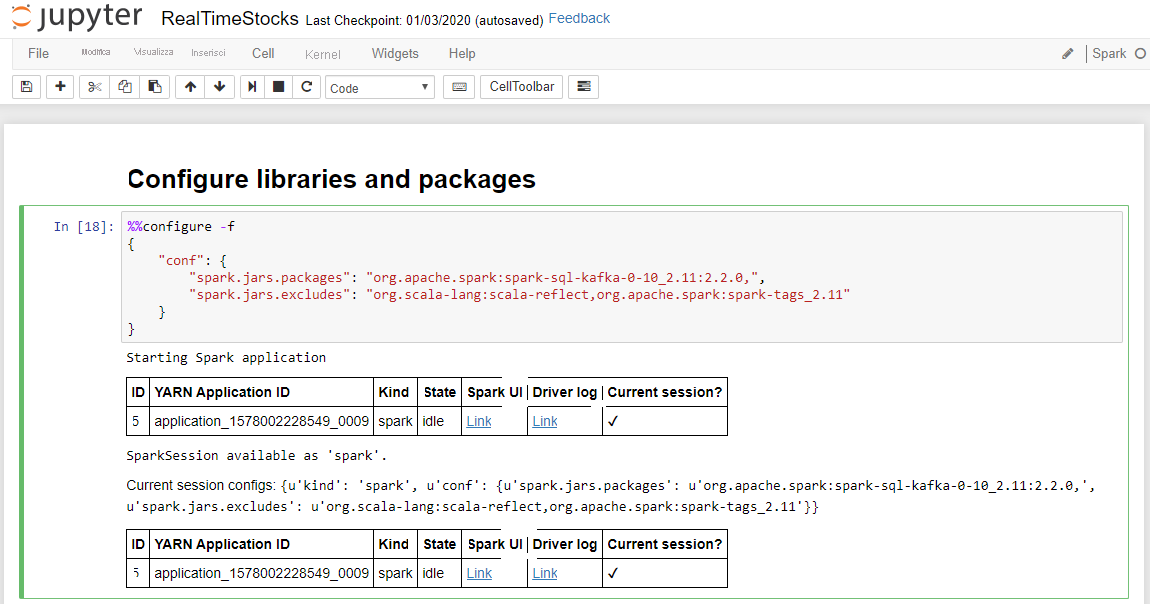
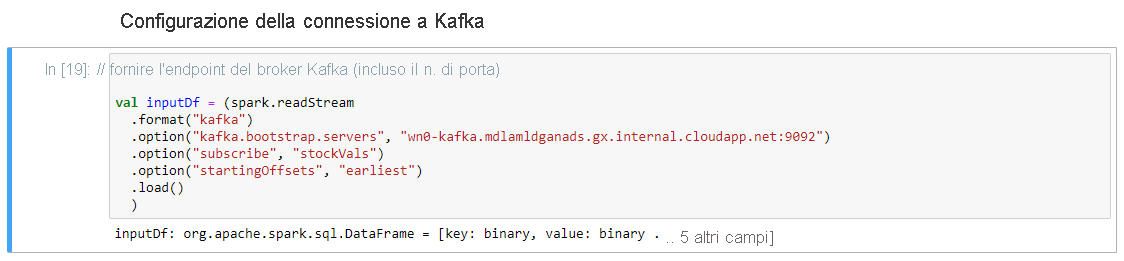
Nella riga .option("kafka.bootstrap.servers", "") della cella Set-up Connection to Kafka immettere il broker Kafka all'interno del secondo set di virgolette. Ad esempio, .option("kafka.bootstrap.servers", "wn0-kafka.mdlamldganads.gx.internal.cloudapp.net:9092") e quindi premere MAIUSC+INVIO per eseguire la cella.
La cella Set-up Connection to Kafka risulta completata quando viene visualizzato il messaggio seguente: inputDf: org.apache.spark.sql.DataFrame = [key: binary, value: binary ... 5 more fields]. Per la lettura dei dati, Spark usa l'API readStream.
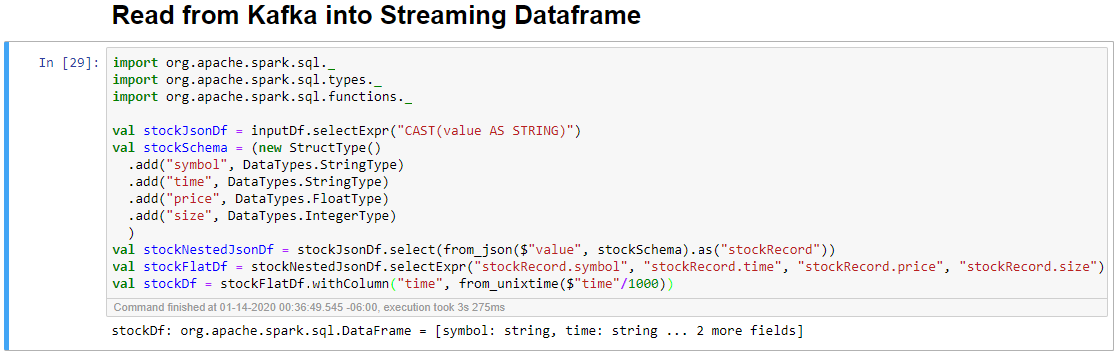
Selezionare la cella Read from Kafka into Streaming Dataframe e quindi premere MAIUSC+INVIO per eseguirla.
La cella risulta completata quando viene visualizzato il messaggio seguente: stockDf: org.apache.spark.sql.DataFrame = [symbol: string, time: string ... 2 more fields]
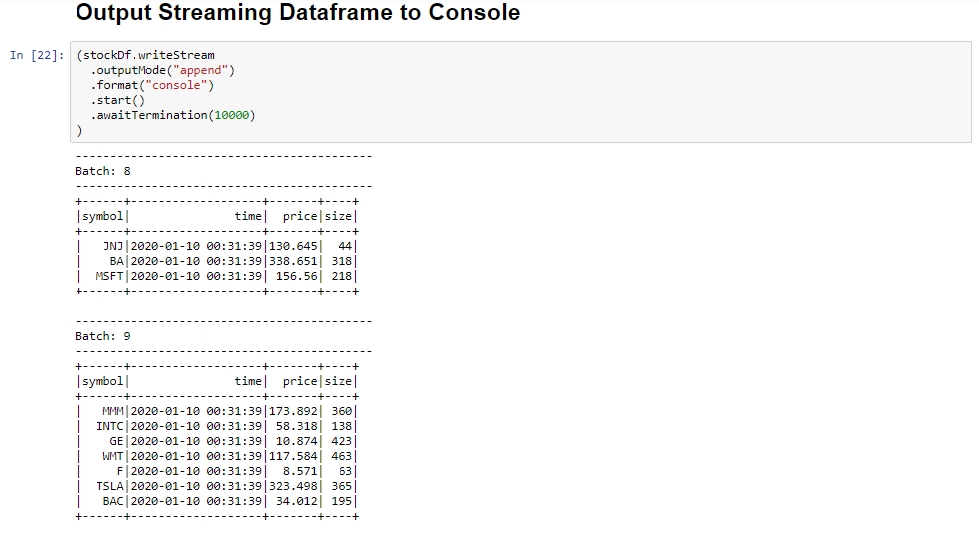
Selezionare la cella Output Streaming Dataframe to Console e quindi premere MAIUSC+INVIO per eseguirla.
La cella risulta completata quando vengono visualizzate informazioni simili a quelle riportate di seguito. L'output mostra il valore di ogni cella passata nel microbatch e viene riportato un batch al secondo.
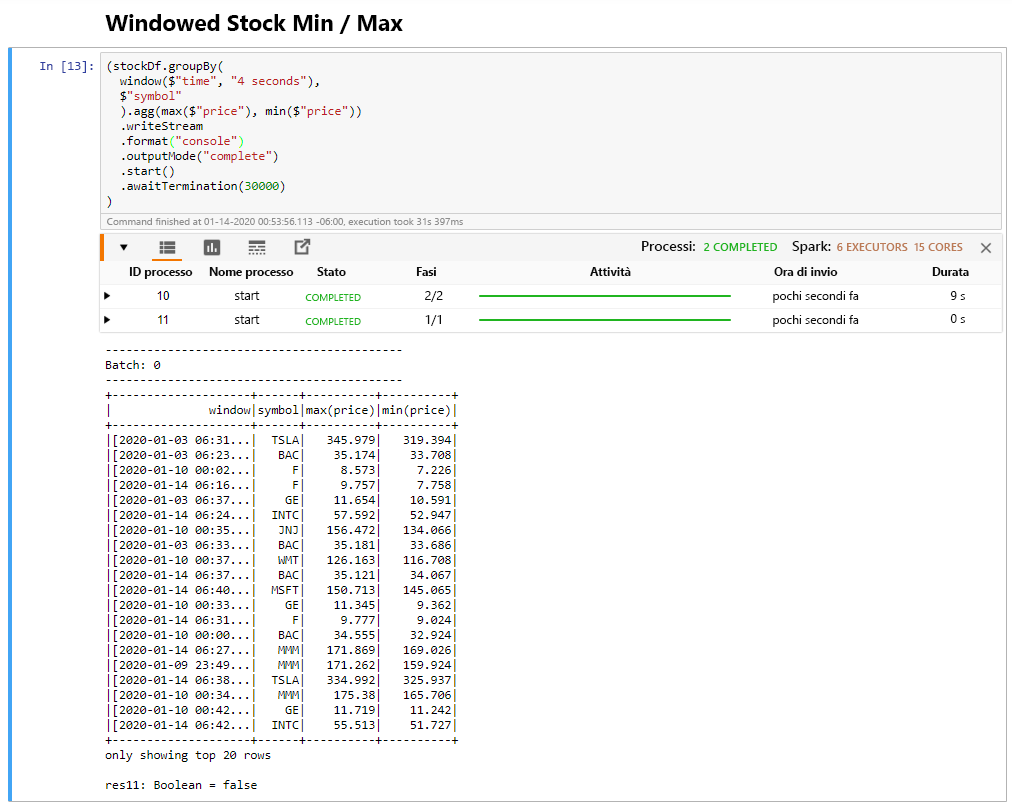
Selezionare la cella Windowed Stock Min / Max e quindi premere MAIUSC+INVIO per eseguirla.
La cella risulta completata quando fornisce il prezzo massimo e minimo per ogni titolo nella finestra di 4 secondi, come definita nella cella. Come spiegato in un'unità precedente, la disponibilità di informazioni su finestre temporali specifiche è uno dei vantaggi che è possibile ottenere usando Spark Structured Streaming.
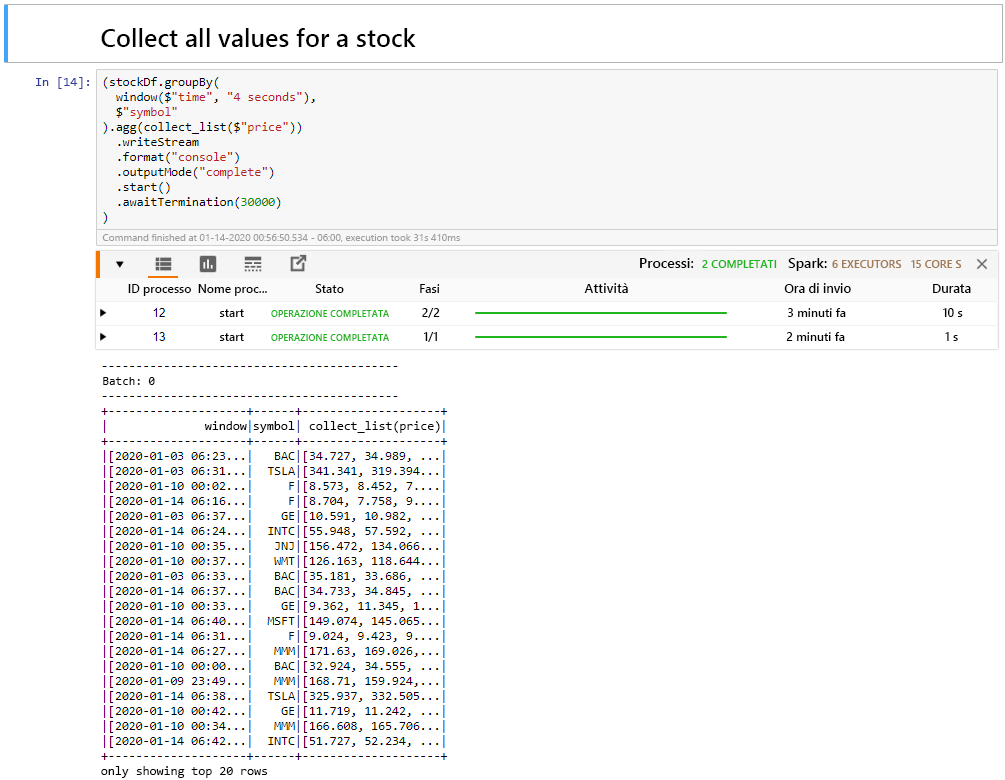
Selezionare la cella Collect all values for a stock e quindi premere MAIUSC+INVIO per eseguirla.
La cella risulta completata quando restituisce una tabella dei valori dei titoli azionari nella tabella. Il valore di outputMode è "complete" e quindi tutti i dati sono visualizzati.
In questa unità è stato caricato un notebook di Jupyter in un cluster Spark, è stata stabilita una connessione al cluster Kafka, sono stati passati i dati di streaming creati dal file producer Python al notebook di Spark, è stata definita una finestra temporale per i dati di streaming e sono stati visualizzati i valori massimi e minimi dei titoli azionari in tale finestra. Sono stati infine visualizzati tutti i valori dei titoli nella tabella. La generazione del flusso strutturato con Spark e Kafka è stata completata.