Inserimento di dati con Azure Databricks
Per poter usare i dati in Azure Databricks, è necessario prima inserire i dati nella piattaforma. Una volta nella piattaforma, l'ambiente di calcolo basato sul cloud consente di elaborare grandi volumi di dati in modo efficiente.
I dati in Azure Databricks vengono archiviati usando Apache Delta Lake, un sistema open source per la gestione dei file di dati in cui è possibile definire ed eseguire query sulle tabelle relazionali. Il percorso di archiviazione effettivo per i file di Delta Lake può variare. Azure Databricks supporta la connessione a servizi di archiviazione dati cloud, ad esempio Archiviazione di Azure e Azure Data Lake. Azure Databricks offre anche Unity Catalog come soluzione di governance per la gestione e il rilevamento dell'accesso ai dati e la derivazione dei dati in più archivi dati connessi.
Screenshot dell'aggiunta di dati ad Azure Databricks.
Esistono diversi modi per inserire dati in Azure Databricks, per cui è uno strumento versatile e potente per l'analisi dei dati. Ad esempio:
Uso di un connettore Databricks gestito in Lakeflow Connect
Azure Databricks Lakeflow Connect offre un framework per l'inserimento di dati da applicazioni SaaS, database e altre origini nel lakehouse usando connettori gestiti. Questi connettori definiscono come vengono configurati e gestiti l'autenticazione, le pipeline e le tabelle di destinazione. Per le origini SaaS, le parti principali sono una connessione (per l'autenticazione), una pipeline di inserimento serverless e tabelle Delta che archiviano i dati inseriti. I connettori di database includono gli stessi elementi, ma si basano anche su un gateway di inserimento eseguito sul calcolo classico e su un'area di archiviazione di staging nel catalogo Unity per contenere temporaneamente i dati estratti. L'orchestrazione viene gestita tramite job di Databricks e il controllo di accesso e auditing vengono gestiti tramite Unity Catalog.
L'uso di connettori gestiti consente di pianificare, ripetere e ridimensionare le pipeline di dati senza dover scrivere codice di inserimento personalizzato. L'inserimento incrementale è supportato, che consente di ridurre il carico nei sistemi di origine mantenendo aggiornate le tabelle. L'approccio enfatizza la governance coerente, la gestione degli schemi e il monitoraggio in origini dati diverse.
Sono disponibili i connettori gestiti seguenti:
- Google Analytics
- Salesforce
- Report di Workday
- SQL Server
- ServiceNow
- SharePoint
Caricare file in Azure Databricks
È possibile importare file CSV, TSV, JSON, XML, Avro, Parquet o di testo normale in Databricks per generare una tabella Delta. Questo approccio è destinato a file più piccoli (inferiori a 2 GB) trasferiti direttamente dal computer. Gli archivi compressi come ZIP o TAR non sono supportati. Durante il processo di caricamento, Databricks offre un'anteprima di un massimo di 50 righe ed è possibile modificare le impostazioni di formattazione per garantire che le colonne e i tipi di dati in file CSV o JSON vengano riconosciuti correttamente.
È anche possibile caricare file di qualsiasi formato, strutturato, semistrutturato o non strutturato, in un volume. Un volume è un oggetto Catalogo Unity che fornisce la governance per set di dati nontabulari e rappresenta uno spazio di archiviazione logico all'interno di un archivio oggetti cloud. I volumi consentono di accedere, archiviare, organizzare e applicare la governance ai file. Esistono due tipi di volumi:
- Volumi gestiti: archiviazione gestita da Databricks per casi d'uso semplici.
- Volumi esterni: governance applicata ai percorsi di archiviazione degli oggetti cloud esistenti.
Annotazioni
L'opzione DBFS consente di utilizzare il caricamento file del Sistema di File tradizionale di Databricks. Questo non è più supportato.
Inserire file con l'API Apache Spark
Apache Spark è la piattaforma di calcolo nativa per Azure Databricks e supporta le API per più linguaggi di programmazione, ad esempio Scala, Java, PySpark (una variante ottimizzata per Spark di Python) e SQL. Per l'inserimento semplice dei dati nell'archiviazione remota, è possibile scrivere codice che si connette e importa i dati necessari.
Ecco un esempio che usa wget per eseguire il pull di un file remoto in /tmp/ nel nodo driver, usare Spark per leggerlo dal percorso locale e quindi salvarlo come tabella Delta in Databricks:
# Step 1: Use wget to download the file (e.g., a CSV from a public URL)
# In Databricks, prefix shell commands with "!"
!wget https://<location>/airtravel.csv -O /tmp/airtravel.csv
# Step 2: Load the downloaded file into a Spark DataFrame
df = spark.read.format("csv") \
.option("header", "true") \
.option("inferSchema", "true") \
.load("file:/tmp/airtravel.csv")
# Step 3: Preview the data
df.show(5)
# Step 4: Save as a Delta table
df.write.format("delta").mode("overwrite").saveAsTable("default.airtravel")
Caricare dati usando COPY INTO con un'entità servizio
È possibile usare il COPY INTO comando per caricare dati da un contenitore di Azure Data Lake Storage (ADLS) nell'account Azure in una tabella in Databricks SQL.
COPY INTO my_json_data
FROM 'abfss://container@storageAccount.dfs.core.windows.net/jsonData'
FILEFORMAT = JSON;
Pipeline dichiarative di Lakeflow
Lakeflow Declarative Pipelines è un framework dichiarativo per lo sviluppo e l'esecuzione di pipeline di dati batch e di streaming in SQL e Python. Supporta orchestrazione automatizzata, tentativi, isolamento degli errori, evoluzione dello schema, elaborazione incrementale e CDC Change Data Capture di tipo 1 e 2.
Un flusso è il concetto di elaborazione dei dati di base in Pipeline dichiarative di Lakeflow, che supporta sia la semantica di streaming che quella batch. Un flusso legge i dati da un'origine, applica la logica di elaborazione definita dall'utente e scrive il risultato in una destinazione.
È anche possibile gestire la qualità dei dati con le aspettative della pipeline, che consentono di definire regole di convalida che garantiscano che i dati soddisfino gli standard necessari prima di essere scritti nella destinazione.
Di seguito è riportato un esempio di pipeline dichiarativa:
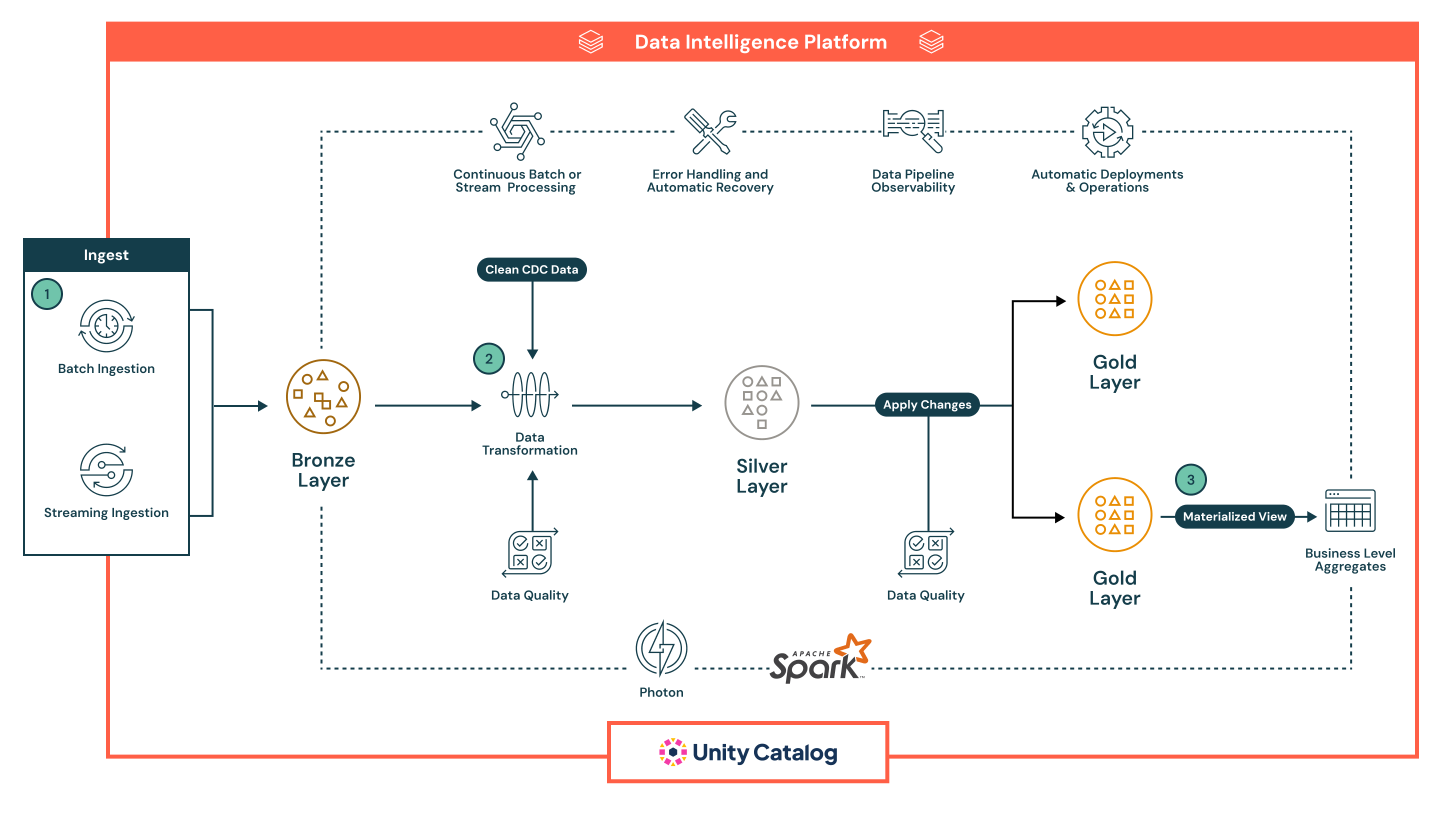
In questo esempio, i dati vengono prima posizionati nel livello Bronze sotto forma non elaborata per la derivazione e la rielaborazione sicura, quindi passano al livello Silver , dove vengono puliti, arricchiti, convalidati con controlli di qualità inline ed elaborati su larga scala con Spark, prima di raggiungere il livello Gold , che offre set di dati curati e pronti per l'azienda per BI, Machine Learning e casi d'uso avanzati come il rilevamento cronologico.
Azure Data Factory
Azure Data Factory (ADF) consente di copiare dati da e verso Azure Databricks Delta Lake usando l'attività di copia predefinita. Quando funge da origine, ADF può estrarre dati da tabelle Delta in Databricks e spostarli in sink supportati; quando funge da sink, può caricare i dati in tabelle Delta Lake da origini supportate.
Lo spostamento dei dati viene orchestrato richiamando il cluster Databricks per gestire il trasferimento e ADF supporta sia i runtime di integrazione di Azure che i runtime di integrazione self-hosted a seconda dell'ambiente.
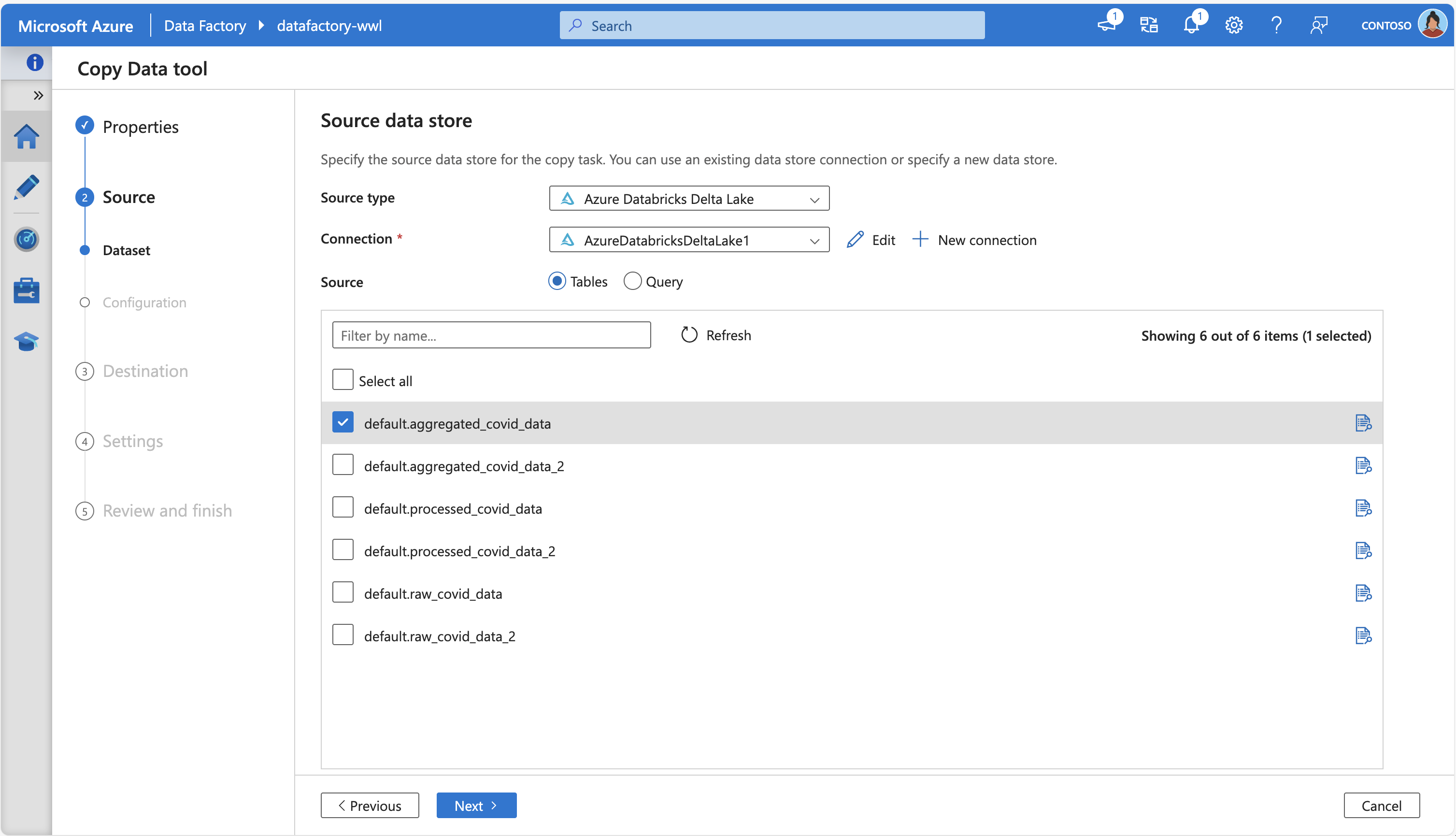
Lo screenshot seguente mostra lo strumento Copia dati di Azure Data Factory, connettendosi ad Azure Databricks Delta Lake per recuperare alcune tabelle di origine:
I flussi di dati di mapping di ADF offrono inoltre un'esperienza ETL senza codice: possono originare o destinarsi a dati in formato Delta su Archiviazione Azure, abilitando trasformazioni senza scrivere codice, in esecuzione su Azure Integration Runtime gestito.
Hub eventi di Azure e hub IoT
Per l'inserimento dati in tempo reale, Hub eventi di Azure e hub IoT sono le scelte più adatte. Consentono di trasmettere i dati direttamente in Azure Databricks, in modo da poter elaborare e analizzare i dati mano a mano che arrivano. L'inserimento e l'analisi dei dati in tempo reale sono utili per scenari come il monitoraggio di eventi live o il rilevamento dei dati di dispositivi IoT (Internet delle cose).
Hub eventi di Azure ha un endpoint compatibile con Kafka che funziona con il connettore Structured Streaming di Kafka in Databricks Runtime. È possibile configurare le pipeline dichiarative di Lakeflow per collegarsi a un'istanza di Event Hubs e consumare eventi da un topic.