Esercizio - Usare PolyBase per eseguire query su un file Parquet
In questo esercizio:
- Installare e abilitare PolyBase.
- Creare un database.
- Creare una chiave master del database per proteggere le credenziali con ambito database.
- Creare credenziali con ambito database per accedere all'origine dati.
- Creare l'origine dati.
- Eseguire una query e modificare i dati archiviati nell'origine dati pubblica.
- Creare un formato di file esterno e una tabella esterna.
Installare PolyBase
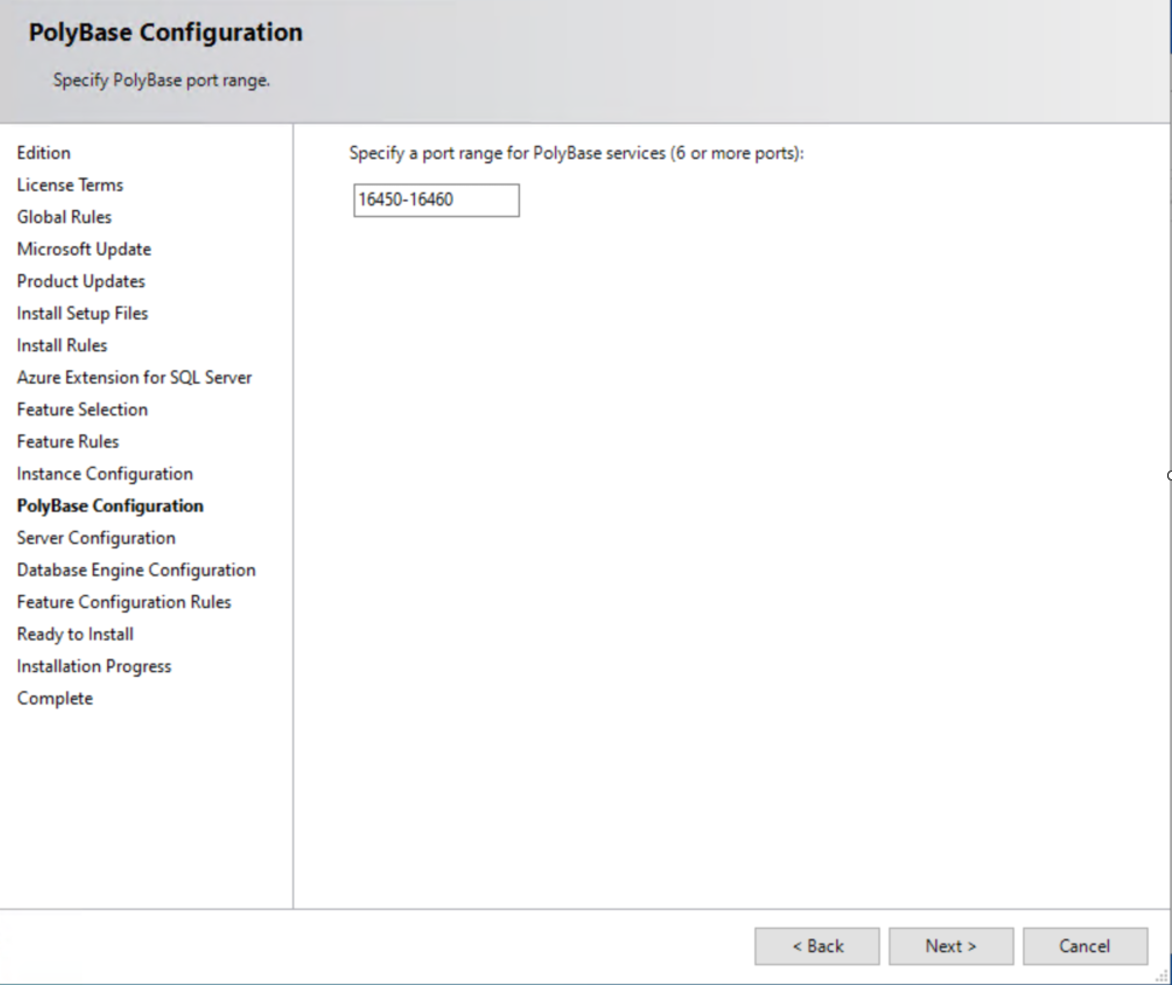
È possibile installare PolyBase con l'eseguibile di installazione di SQL Server durante l'installazione iniziale o aggiungerlo come funzionalità in un secondo momento. Nella pagina Selezione funzionalità di SQL Server setup.exeselezionare Servizio query PolyBase per dati esterni.

I servizi PolyBase richiedono l'abilitazione delle porte del firewall per connettersi a origini dati esterne. Per impostazione predefinita, PolyBase usa porte comprese tra 16450 e 16460.
L'installazione di PolyBase installa due servizi PolyBase, il motore PolyBase di SQL Server e lo spostamento dei dati PolyBase di SQL Server. Per informazioni complete e prerequisiti per l'installazione di PolyBase, vedere:
Abilitare PolyBase
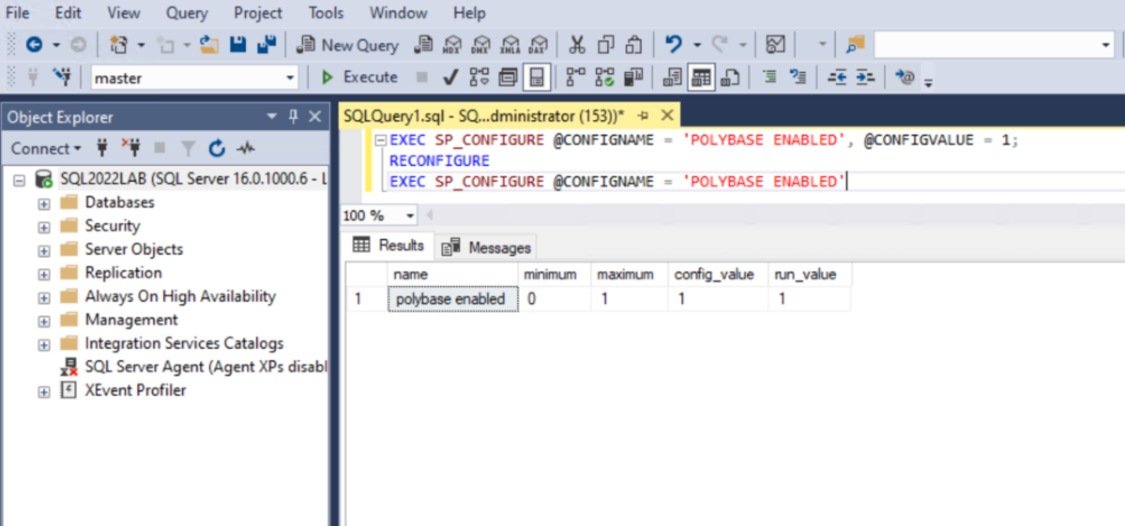
Dopo aver installato il servizio, connettersi all'istanza di SQL Server 2025 in SQL Server Management Studio (SSMS) ed eseguire il comando seguente per abilitare PolyBase.
EXEC SP_CONFIGURE @CONFIGNAME = N'POLYBASE ENABLED', @CONFIGVALUE = 1;
RECONFIGURE;
Annotazioni
In questo esercizio si eseguono query sui file Apache Parquet usando l'API REST PolyBase, quindi non è necessario abilitare o configurare i servizi di spostamento dati PolyBase di SQL Server o del motore PolyBase di SQL Server .
Creazione di un database
Eseguire il comando seguente in SSMS per creare un database per questo esercizio denominato Demo1. Se il database è già stato creato, lo script lo elimina e lo ricrea.
USE MASTER;
IF EXISTS (SELECT * FROM sys.databases WHERE [name] = N'Demo1')
BEGIN
ALTER DATABASE Demo1 SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE IF EXISTS Demo1
END;
CREATE DATABASE Demo1;
USE Demo1;
Creare la chiave master del database
È necessario creare una chiave master del database per garantire la sicurezza delle credenziali con ambito database. Nell'esempio seguente viene creata la chiave con una password generata in modo casuale e viene richiesto un backup.
DECLARE @randomWord VARCHAR(64) = NEWID();
DECLARE @createMasterKey NVARCHAR(500) = N'
IF NOT EXISTS (SELECT * FROM sys.symmetric_keys WHERE name = ''##MS_DatabaseMasterKey##'')
CREATE MASTER KEY ENCRYPTION BY PASSWORD = ' + QUOTENAME(@randomWord, '''')
EXECUTE sp_executesql @createMasterKey;
SELECT * FROM sys.symmetric_keys;
Per comprendere e gestire meglio le chiavi di crittografia in un ambiente di produzione, vedere:
Creare le credenziali con ambito database
Le credenziali con ambito database sono responsabili dell'archiviazione delle credenziali usate dall'origine dati per connettersi all'endpoint. Questo esempio usa un endpoint pubblico, quindi le credenziali non necessitano di un segreto.
IF EXISTS (SELECT * FROM sys.database_scoped_credentials WHERE name = N'PublicCredential')
DROP DATABASE SCOPED CREDENTIAL PublicCredential;
CREATE DATABASE SCOPED CREDENTIAL PublicCredential
WITH IDENTITY = 'SHARED ACCESS SIGNATURE',
SECRET = '<KEY>'; -- This example doesn't need the SECRET because the data source is public
Creare l'origine dati
L'esempio usa un set di dati Parquet sul COVID disponibile pubblicamente archiviato in Archiviazione BLOB di Azure. Usare il database con ambito PublicCredential creato per stabilire la connessione.
Valori LOCATION:
- Prefisso:
abs - Account di archiviazione di Azure:
pandemicdatalake - Percorso completo dell'account di archiviazione di Azure:
pandemicdatalake.blob.core.windows.net - Nome contenitore:
public - Percorso completo del contenitore:
public/curated/covid-19/bing_covid-19_data/latest
IF EXISTS (SELECT * FROM sys.external_data_sources WHERE name = N'Public_Covid') DROP EXTERNAL DATA SOURCE Public_Covid;
CREATE EXTERNAL DATA SOURCE Public_Covid
WITH (
LOCATION = 'abs://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/bing_covid-19_data/latest',
CREDENTIAL = [PublicCredential]
);
- Per un elenco completo delle origini dati e dei prefissi corrispondenti, vedere CREATE EXTERNAL DATA SOURCE.
- Per altre informazioni sul set di dati pubblico, vedere Bing COVID-19.
Eseguire query sui dati con OPENROWSET
È possibile usare OPENROWSET per accedere ed esplorare i dati. OPENROWSET è ottimizzato per scenari di esplorazione dei dati e del carico di lavoro ad hoc.
Valori OPENROWSET:
- BULK: nome e estensione del file. BULK aggiunge automaticamente alle informazioni sull'origine dati, quindi il percorso completo del file è
abs://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/bing_covid-19_data/latest/bing_covid-19_data.parquet - FORMATO:
PARQUET - DATA_SOURCE: informazioni di connessione, in questo caso la nuova origine dati
Public_Covid
SELECT TOP 1000 *
FROM OPENROWSET
(BULK 'bing_covid-19_data.parquet'
, FORMAT = 'PARQUET'
, DATA_SOURCE = 'Public_Covid')
AS [COVID_Dataset]
L'esempio seguente usa la flessibilità T-SQL per eseguire query sul file Parquet in tempo reale, proprio come una tabella normale. Per restituire il numero di casi confermati per stato degli Stati Uniti in ordine decrescente, eseguire la query seguente:
SELECT [COVID_Dataset].admin_region_1,
SUM(CAST([COVID_Dataset].confirmed AS BIGINT)) AS Confirmed
FROM OPENROWSET
(BULK 'bing_covid-19_data.parquet'
, FORMAT = 'PARQUET'
, DATA_SOURCE = 'Public_Covid')
AS [COVID_Dataset]
WHERE [COVID_Dataset].country_region = 'United States' AND
[COVID_Dataset].admin_region_1 IS NOT NULL
GROUP BY [COVID_Dataset].admin_region_1
ORDER BY confirmed DESC
Creare una tabella esterna ed eseguire query sulla tabella
OPENROWSET è ottimizzato per l'esecuzione ad hoc e l'esplorazione dei dati. Le tabelle esterne sono più adatte per l'accesso ricorrente, perché possono usare anche le statistiche.
Individuare lo schema della tabella esterna
Per creare una tabella esterna, determinare prima di tutto le colonne e il tipo. Lo schema proviene da un file esterno, quindi potrebbe richiedere molto tempo per determinare con precisione i tipi di dati e gli intervalli. Fortunatamente, è possibile usare la stored procedure sp_describe_first_result_set (Transact-SQL) per velocizzare questo processo.
DECLARE @tsql NVARCHAR(MAX) = 'SELECT TOP 1000 *
FROM OPENROWSET
(BULK ''bing_covid-19_data.parquet''
, FORMAT = ''PARQUET''
, DATA_SOURCE = ''Public_Covid'')
AS [COVID_Dataset]';
EXEC sys.sp_describe_first_result_set @tsql;
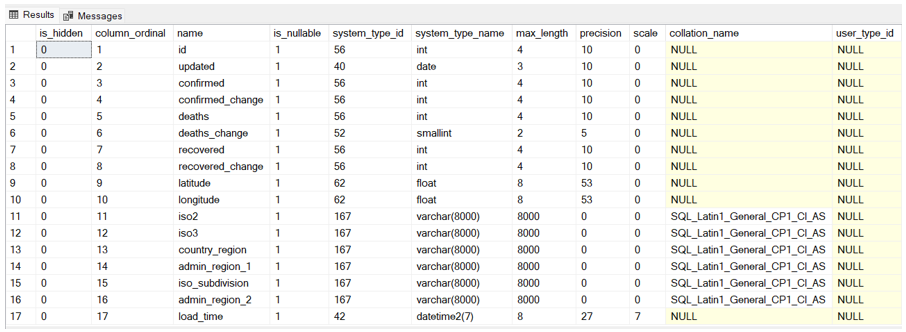
Puoi vedere che sp_describe_first_result_set ha restituito i nomi delle colonne, i tipi, la lunghezza, la precisione e persino la collatione dell'origine dati.
Creare il formato di file esterno
Poiché è necessario fare riferimento al file Parquet alla tabella esterna, è prima necessario eseguire CREATE EXTERNAL FILE FORMAT per aggiungere il formato di file Parquet. La definizione del formato di file è importante per le tabelle esterne perché specifica il layout e il tipo di compressione effettivi.
Eseguire il comando seguente:
IF EXISTS (SELECT * FROM sys.external_file_formats WHERE name = N'ParquetFileFormat')
DROP EXTERNAL FILE FORMAT ParquetFileFormat;
CREATE EXTERNAL FILE FORMAT ParquetFileFormat WITH(FORMAT_TYPE = PARQUET);
Creare la tabella esterna
Infine, con tutte le informazioni appena acquisite e il formato di file esterno creato, è possibile creare la tabella esterna usando lo script seguente:
IF EXISTS (SELECT * FROM sys.external_file_formats WHERE name = N'ParquetFileFormat')
DROP EXTERNAL FILE FORMAT ParquetFileFormat;
CREATE EXTERNAL FILE FORMAT ParquetFileFormat WITH(FORMAT_TYPE = PARQUET);
-- 8.3 CREATE EXTERNAL TABLE
IF OBJECT_ID(N'ext_covid_data', N'ET') IS NOT NULL
DROP EXTERNAL TABLE ext_covid_data;
CREATE EXTERNAL TABLE ext_covid_data
(
id int,
updated date,
confirmed int,
confirmed_change int,
deaths int,
deaths_change smallint,
recovered int,
recovered_change int,
latitude float,
longitude float,
iso2 varchar(8000),
iso3 varchar(8000),
country_region varchar(8000),
admin_region_1 varchar(8000),
iso_subdivision varchar(8000),
admin_region_2 varchar(8000),
load_time datetime2(7)
)
WITH
(
LOCATION = 'bing_covid-19_data.parquet'
, FILE_FORMAT = ParquetFileFormat
, DATA_SOURCE = Public_Covid
);
CREATE STATISTICS [Stats_ext_covid_data_updated] ON ext_covid_data([updated]);
SELECT TOP 1000 * FROM ext_covid_data;
Annotazioni
I nomi delle colonne devono corrispondere alle colonne archiviate nel file Parquet oppure SQL Server non è in grado di identificare le colonne e restituisce NULL.
Dopo aver creato la tabella ext_covid_dataesterna , è possibile aggiungere statistiche sulle colonne aggiornate per garantire l'efficienza. Per maggiori informazioni sulle statistiche delle tabelle esterne, vedere CREATE STATISTICS (Transact-SQL).
In questa unità è stato usato PolyBase per connettersi a un'origine dati esterna e si è usato OPENROWSET o una tabella esterna per eseguire query sul file Parquet. Nell'esercizio successivo si usano i servizi PolyBase per connettersi e creare una tabella esterna da un database nel database SQL di Azure.