Concetti relativi alla rete neurale profonda
Prima di scoprire come eseguire il training di un modello di Machine Learning di una rete neurale profonda (DNN, Deep Neural Network), è opportuno prendere in considerazione quello che si sta tentando di ottenere. Machine Learning riguarda la stima di un'etichetta in base ad alcune caratteristiche di una particolare osservazione. In termini semplici, un modello di Machine Learning è una funzione che calcola y (etichetta) da x (le funzionalità): f(x)=y.
Esempio di classificazione semplice
Si supponga, ad esempio, che l'osservazione sia costituita dalle misure di un pinguino.

In particolare, le misure riguardano:
- Lunghezza del becco del pinguino.
- Profondità del becco del pinguino.
- Lunghezza della pinna del pinguino.
- Peso del pinguino.
In questo caso, le caratteristiche (x) sono un vettore di quattro valori, o matematicamente, x=[x1,x2,x3,x4].
Si supponga che l'etichetta che si sta tentando di prevedere (y) sia la specie del pinguino e che ci siano tre specie possibili:
- Adelie
- Gentoo
- Chinstrap
Questo è un esempio di un problema di classificazione , in cui il modello di Machine Learning deve prevedere la classe più probabile a cui appartiene l'osservazione. Un modello di classificazione consente di ottenere questo risultato stimando un'etichetta costituita dalla probabilità per ogni classe. In altre parole, y è un vettore di tre valori di probabilità; uno per ognuna delle classi possibili: y=[P(0),P(1),P(2)].
Per eseguire il training del modello di Machine Learning, è possibile usare le osservazioni per le quali si conosce già l'etichetta true. Ad esempio, potresti avere le seguenti misurazioni di caratteristiche per un campione adelie :
x=[37.3, 16.8, 19.2, 30.0]
Si sa già che si tratta di un esempio di Adelie (classe 0), quindi una funzione di classificazione perfetta dovrebbe produrre un'etichetta che indica una probabilità di 100% per la classe 0 e una probabilità 0% per le classi 1 e 2:
y=[1, 0, 0]
Modello di rete neurale profonda
Quindi, come si usa il Deep Learning per creare un modello di classificazione per il modello di classificazione del pinguino? Ecco un esempio:
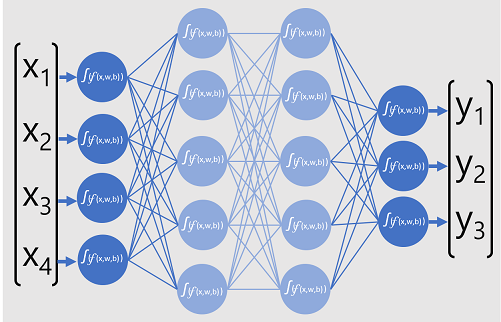
Il modello di rete neurale profonda per il classificatore è costituito da più livelli di neuroni artificiali. In questo caso sono presenti quattro livelli:
- Livello di input con un neurone per ogni valore di input previsto (x).
- Due cosiddetti strati nascosti , ognuno contenente cinque neuroni.
- Livello di output contenente tre neuroni, uno per ogni valore di probabilità di classe (y) da stimare dal modello.
A causa dell'architettura a più livelli della rete, questo tipo di modello viene talvolta definito perceptron a più livelli. Inoltre, si noti che tutti i neuroni nei livelli di input e nascosti sono connessi a tutti i neuroni nei livelli successivi. Questo è un esempio di una rete completamente connessa.
Quando si crea un modello di questo tipo, è necessario definire un livello di input che supporti il numero di caratteristiche che il modello elaborerà e un livello di output che rifletta il numero di output che si prevede che produca. È possibile scegliere il numero di livelli nascosti da includere e il numero di neuroni in ognuno di essi. Tuttavia, non è possibile controllare i valori di input e output per questi livelli, che sono determinati dal processo di training del modello.
Training di una rete neurale profonda
Il processo di training per una rete neurale profonda è costituito da più iterazioni, denominate epoche. Per il primo periodo, si inizia assegnando valori di inizializzazione casuali per il peso (w) e i valori di distorsione b . Il processo è quindi il seguente:
- Le caratteristiche per le osservazioni dei dati con valori di etichetta noti vengono inviate al livello di input. In genere, queste osservazioni sono raggruppate in batch (spesso definite mini batch).
- I neuroni applicano quindi la loro funzione e, se attivati, trasmettono il risultato al livello successivo finché il livello di output non produce una stima.
- La stima viene confrontata con il valore noto effettivo e viene calcolata la quantità di varianza tra i valori stimati e true (che chiamiamo perdita).
- In base ai risultati, i valori rivisti per i pesi e i valori di bias vengono calcolati per ridurre la perdita e queste regolazioni vengono retropropagate ai neuroni negli strati della rete.
- Il periodo successivo ripete il passaggio in avanti del training in batch con i valori rivisti per il peso e la distorsione, nella speranza di migliorare l'accuratezza del modello riducendo la perdita.
Nota
L'elaborazione delle caratteristiche di training come batch consente di migliorare l'efficienza del processo di training elaborando contemporaneamente più osservazioni come una matrice di caratteristiche con vettori di pesi e distorsioni. Le funzioni algebriche lineari che operano con matrici e vettori includono anche funzionalità di elaborazione grafica 3D, motivo per cui i computer con unità di elaborazione grafica (GPU) assicurano prestazioni nettamente migliori per il training dei modelli di Deep Learning rispetto ai computer che hanno solo un'unità di elaborazione centrale (CPU).
Informazioni dettagliate sulle funzioni di perdita e la retropropagazione
La descrizione precedente del processo di training di Deep Learning ha indicato che la perdita dal modello viene calcolata e usata per rivedere i valori relativi a peso e distorsione. Come funziona esattamente tutto questo?
Calcolo della perdita
Si supponga che uno dei campioni passati attraverso il processo di training contenga caratteristiche di un campione adelie (classe 0). L'output corretto proveniente dalla rete sarà [1, 0, 0]. Si supponga ora che l'output prodotto dalla rete sia [0,4, 0,3, 0,3]. Confrontando questi elementi, è possibile calcolare una varianza assoluta per ogni elemento (in altre parole, quanto ogni valore stimato si discosta da quello che dovrebbe essere) come [0,6, 0,3, 0,3].
In realtà, avendo effettivamente a che fare con più osservazioni, in genere la varianza si aggrega, ad esempio elevando al quadrato i singoli valori di varianza e calcolandone la media, per ottenere come risultato un singolo valore di perdita media, come 0,18.
Ottimizzatori
Ora la questione si fa interessante. La perdita viene calcolata usando una funzione che opera sui risultati del livello finale della rete, sempre con una funzione. Il livello finale della rete opera sugli output dei livelli precedenti, sempre con una funzione. Di conseguenza, l'intero modello dal livello di input fino al calcolo della perdita è solo una grande funzione annidata. Le funzioni hanno alcune caratteristiche molto utili, tra cui:
- È possibile concettualizzare una funzione come riga del tracciato confrontandone l'output con ognuna delle relative variabili.
- È possibile usare il calcolo differenziale per calcolare la derivata della funzione in qualsiasi punto rispetto alle relative variabili.
Si consideri la prima di queste funzionalità. È possibile tracciare la riga della funzione per mostrare come un singolo valore di peso venga confrontato con la perdita e contrassegnare su tale riga il punto in cui il valore del peso corrente corrisponde a quello della perdita corrente.
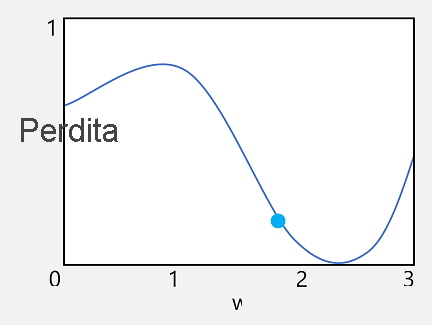
A questo punto è possibile applicare la seconda caratteristica di una funzione. La derivata di una funzione per un dato punto indica se il coefficiente angolare (o gradiente) dell'output della funzione (in questo caso, la perdita) aumenta o diminuisce rispetto a una variabile della funzione (in questo caso, il valore del peso). Una derivata positiva indica che la funzione è in aumento, mentre una negativa significa che è in diminuzione. In questo caso, in corrispondenza del punto tracciato per il valore del peso corrente, la funzione presenta un gradiente verso il basso. In altre parole, l'aumento del peso produrrà come effetto la riduzione della perdita.
Si usa un ottimizzatore per applicare questo stesso trucco per tutte le variabili di peso e distorsione nel modello e determinare in quale direzione è necessario regolarle (verso l'alto o verso il basso) per ridurre la quantità complessiva di perdita nel modello. Sono disponibili più algoritmi di ottimizzazione comunemente usati, tra cui discesa del gradiente stocastico (SGD),tasso di apprendimento adattivo (ADADELTA),stima di slancio adattivo (Adam) e altri; tutti progettati per capire come regolare i pesi e le distorsioni per ridurre al minimo la perdita.
Velocità di apprendimento
A questo punto, la domanda più ovvia è di quanto deve modificare i valori di peso e distorsione l'ottimizzatore? Se si esamina il tracciato per il valore del peso, si noterà che a un aumento minimo del peso seguirà una riduzione della riga della funzione (con una riduzione della perdita), ma se si aumenta troppo il peso, la riga della funzione inizierà a risalire, quindi è possibile che la perdita effettivamente aumenti e dopo il periodo successivo potrebbe essere necessario ridurre il peso.
La dimensione della regolazione è controllata da un parametro impostato per il training denominato frequenza di apprendimento. Una velocità di apprendimento bassa comporta rettifiche minime (pertanto può richiedere più periodi per ridurre al minimo la perdita), mentre una velocità di apprendimento elevata comporta rettifiche maggiori.