Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo fornisce soluzioni ai problemi relativi alla coda di invio dei log.
Che cos'è la coda di invio dei log?
Le modifiche apportate a un database del gruppo di disponibilità nella replica primaria , ad esempio INSERT, UPDATEe DELETE, vengono scritte nel log delle transazioni e inviate alle repliche secondarie del gruppo di disponibilità. La coda di invio log definisce il numero di record di log nei file di log del database primario che non sono stati inviati alle repliche secondarie.
Sintomi ed effetti della coda di invio del log
La coda di invio log archivia tutti i dati vulnerabili
Se la replica primaria viene persa in un'emergenza improvvisa e si esegue il failover nella replica secondaria in cui queste modifiche non sono ancora arrivate, tali modifiche non verranno visualizzate nella nuova copia della replica primaria del database. Ciò esclude tutte le modifiche archiviate quando vengono eseguiti backup completi del database e del log.
La crescita della coda di invio dei log causa un aumento della crescita dei file di log delle transazioni
Per un database definito in un gruppo di disponibilità, Microsoft SQL Server deve conservare nella replica primaria tutte le transazioni nel log delle transazioni che non sono ancora state recapitate alle repliche secondarie. La coda di invio del log rappresenta la quantità di modifiche registrate nella replica primaria che non possono essere troncate durante i normali eventi di troncamento del log, ad esempio durante un backup del log del database. Una coda di invio di log di grandi dimensioni e in crescita può esaurire lo spazio disponibile nell'unità che ospita il file di log del database o può superare le dimensioni massime del file di log delle transazioni configurate. Per altre informazioni, vedere Errore 9002 quando il log delle transazioni è di grandi dimensioni.
Varie funzionalità di diagnostica segnalano la coda di invio dei log dei log del gruppo di disponibilità
Il dashboard Always On nei report di SQL Server Management Studio sulla coda di invio dei log. Potrebbe segnalare che il gruppo di disponibilità non è integro.
Come verificare la presenza di code di invio dei log
La coda di invio dei log è una misura per database. È possibile controllare questo valore usando il dashboard Always On nella replica primaria o usando le sys.dm_hadr_database_replica_states DMV (Dynamic Management Views) nella replica primaria o secondaria. Monitor prestazioni contatori vengono usati per verificare la presenza di code di invio dei log sulla replica secondaria.
Le sezioni successive forniscono metodi per monitorare attivamente la coda di invio dei log del database del gruppo di disponibilità.
Query sys.dm_hadr_database_replica_state
La sys.dm_hadr_database_replica_states DMV segnala una riga per ogni database del gruppo di disponibilità. Una colonna del report è log_send_queue_size. Questo valore è la dimensione della coda di invio log in kilobyte (KB). È possibile configurare una query, ad esempio la query seguente, per monitorare qualsiasi tendenza nelle dimensioni della coda di invio del log. La query viene eseguita nella replica primaria. Usa il is_local=0 predicato per segnalare i dati per la replica secondaria, dove log_send_queue_size e log_send_rate sono rilevanti.
WHILE 1=1
BEGIN
SELECT drcs.database_name, ars.role_desc, drs.log_send_queue_size, drs.log_send_rate,
ars.recovery_health_desc, ars.connected_state_desc, ars.operational_state_desc, ars.synchronization_health_desc, *
FROM sys.dm_hadr_availability_replica_states ars JOIN sys.dm_hadr_database_replica_cluster_states drcs ON ars.replica_id=drcs.replica_id
JOIN sys.dm_hadr_database_replica_states drs ON drcs.group_database_id=drs.group_database_id
WHERE ars.role_desc='SECONDARY' AND drs.is_local=0
waitfor delay '00:00:30'
END
L'output sarà simile a quello riportato di seguito.

Esaminare la coda di invio dei log nel dashboard Always On
Per esaminare la coda di invio dei log, seguire questa procedura:
Aprire il dashboard Always On in SQL Server Management Studio (SSMS) facendo clic con il pulsante destro del mouse su un gruppo di disponibilità in SSMS Esplora oggetti.
Selezionare Mostra dashboard.
I database del gruppo di disponibilità sono elencati per ultimo e sono presenti alcuni dati segnalati nei database. Sebbene le dimensioni della coda di invio log (KB) e la frequenza di invio log (KB/sec) non siano elencate per impostazione predefinita, è possibile aggiungerle a questa visualizzazione, come illustrato nello screenshot nel passaggio successivo.
Per aggiungere queste colonne, fare clic con il pulsante destro del mouse sull'intestazione di colonna del database del gruppo di disponibilità e scegliere dall'elenco delle colonne disponibili.
Per aggiungere dimensioni coda di invio log, fare clic con il pulsante destro del mouse sull'intestazione visualizzata come evidenziata in rosso nello screenshot seguente.

Per impostazione predefinita, il dashboard Always On aggiorna automaticamente questi dati ogni 60 secondi.



Esaminare la coda di invio log in Monitor prestazioni
La coda di invio log è specifica per ogni database di replica secondaria. Per esaminare quindi la coda di invio log di un database del gruppo di disponibilità, seguire questa procedura:
Aprire Monitor prestazioni nella replica secondaria.
Selezionare il pulsante Aggiungi (contatore).
In Contatori disponibili selezionare i contatori SQLServer:Replica di database e Coda di invio log.
Nella casella di riepilogo Istanza selezionare il database del gruppo di disponibilità da controllare per la coda di invio dei log.
Selezionare Aggiungi e OK.
Ecco come potrebbe apparire l'aumento della coda di invio dei log.


Interpretazione dei valori di accodamento dei log
In questa sezione viene illustrato come interpretare i valori delle dimensioni della coda di invio del log.
Quando il log invia accodamento non è valido? Quanto deve essere tollerato l'accodamento di invio del log?
Si potrebbe presupporre che se la coda di invio log segnala un valore pari a 0, ciò significa che non si verifica alcun accodamento di invio del log al momento del report. Tuttavia, quando l'ambiente di produzione è occupato, è consigliabile osservare che la coda di invio dei log segnala spesso un valore diverso da zero anche in un ambiente AlwaysOn integro. Durante la produzione tipica, è consigliabile osservare questa fluttuazione tra 0 e un valore diverso da zero.
Se si osserva un aumento della coda di invio dei log nel tempo, viene garantita un'ulteriore indagine. Questa attività aggiuntiva indica che qualcosa è cambiato. Se si osserva una crescita improvvisa nella coda di invio dei log, le misurazioni seguenti sono utili per la risoluzione dei problemi:
- Frequenza di invio log (KB/sec) (dashboard AlwaysOn)
- sys.dm_hadr_database_replica_states (DMV)
- Replica di database::Transazioni con mirroring/sec (Monitor prestazioni)
Ottenere le percentuali di base per la frequenza di invio del log e le transazioni con mirroring/sec
Durante le prestazioni AlwaysOn integre, monitorare la frequenza di invio del log e i valori delle transazioni con mirroring/sec per i database del gruppo di disponibilità occupato. Che aspetto hanno durante gli orari di ufficio in genere occupati? Come appaiono durante i periodi di manutenzione, quando le transazioni di grandi dimensioni determinano una maggiore velocità effettiva delle transazioni nel sistema? È possibile confrontare questi valori quando si osserva l'aumento della coda di invio log per determinare le modifiche apportate. Il carico di lavoro potrebbe essere maggiore del solito. Se la frequenza di invio del log è inferiore al solito, potrebbe essere necessario eseguire ulteriori indagini per determinare il motivo.
I volumi del carico di lavoro sono importanti
Quando si hanno carichi di lavoro di grandi dimensioni ,ad esempio un'istruzione UPDATE su 1 milione di righe, una ricompilazione dell'indice in una tabella da 1 terabyte o anche un batch ETL che inserisce milioni di righe, è consigliabile che venga visualizzata una crescita della coda di invio dei log, immediatamente o nel corso del tempo. Questo è previsto quando un numero elevato di modifiche viene apportato improvvisamente nel database del gruppo di disponibilità.
Come diagnosticare la coda di invio dei log
Dopo aver identificato la coda di invio dei log per un database del gruppo di disponibilità specifico, è necessario verificare la presenza di diverse possibili cause radice del problema, come descritto nelle sezioni seguenti.
Importante
Per un output significativo del tipo di attesa, verificare la presenza di un aumento nella coda di invio del log usando uno dei metodi descritti nelle sezioni precedenti quando si monitora per le condizioni seguenti.
Sistema troppo occupato
Controllare se il carico di lavoro nella replica primaria sta sovraccaricando le CPU del sistema. Se viene visualizzato un aumento della coda di invio dei log, eseguire una query sulla sys.dm_os_schedulers DMV e monitorare per high runnable_tasks_count. Questo conteggio indica le attività in sospeso eseguite in quel momento.
SELECT scheduler_address, scheduler_id, cpu_id, status, current_tasks_count, runnable_tasks_count, current_workers_count, active_workers_count
FROM sys.dm_os_schedulers
La tabella seguente è un esempio di risultati. Un aumento del runnable_tasks_count valore indica che un numero elevato di attività è in attesa di tempo cpu.
| scheduler_address | scheduler_id | cpu_id | stato | current_tasks_count | runnable_tasks_count | current_workers_count | active_workers_count |
|---|---|---|---|---|---|---|---|
| 0x000002778D 200040 | 0 | 0 | VISIBILE OFFLINE | 1 | 0 | 2 | 1 |
| 0x000002778D 220040 | 1 | 1 | VISIBILE ONLINE | 108 | 12 | 115 | 107 |
| 0x000002778D 240040 | 2 | 2 | VISIBILE ONLINE | 113 | 2 | 123 | 113 |
| 0x000002778D 260040 | 3 | 3 | VISIBILE ONLINE | 105 | 11 | 116 | 105 |
| 0x000002778D 480040 | 4 | 4 | VISIBILE ONLINE | 108 | 15 | 117 | 108 |
| 0x000002778D 4A0040 | 5 | 5 | VISIBILE ONLINE | 100 | 25 | 110 | 99 |
| 0x000002778D 4C0040 | 6 | 6 | VISIBILE ONLINE | 105 | 23 | 113 | 105 |
| 0x000002778D 4E0040 | 7 | 7 | VISIBLE | 109 | 25 | 116 | 109 |
| 0x000002778D 700040 | 8 | 8 | VISIBILE ONLINE | 98 | 10 | 112 | 98 |
| 0x000002778D 720040 | 9 | 9 | VISIBILE ONLINE | 114 | 1 | 130 | 114 |
| 0x000002778D 740040 | 10 | 10 | VISIBILE ONLINE | 110 | 25 | 120 | 110 |
| 0x000002778D 760040 | 11 | 11 | VISIBILE ONLINE | 83 | 8 | 93 | 83 |
| 0x000002778D A00040 | 12 | 12 | VISIBILE ONLINE | 104 | 4 | 117 | 104 |
| 0x000002778D A20040 | 13 | 13 | VISIBILE ONLINE | 108 | 32 | 118 | 108 |
| 0x000002778D A40040 | 14 | 14 | VISIBILE ONLINE | 102 | 12 | 113 | 102 |
| 0x000002778D A60040 | 15 | 15 | VISIBILE ONLINE | 104 | 16 | 116 | 103 |
Soluzione: se si rileva un valore elevato runnable_task_count, ridurre il carico di lavoro nel sistema o aumentare il numero di CPU disponibili per il sistema.
Latenza di rete
Questa condizione è particolarmente comune se la replica secondaria è fisicamente remota dalla replica primaria. I gruppi di disponibilità multisito consentono ai clienti di distribuire copie dei dati aziendali in più siti per il ripristino di emergenza e la creazione di report. In questo modo, le modifiche quasi in tempo reale sono disponibili per le copie dei dati di produzione in posizioni remote.
Se una replica secondaria è ospitata lontano dalla replica primaria, la coda di invio dei log può essere causata dalla latenza di rete e dall'impossibilità di inviare modifiche al database secondario remoto con la stessa velocità con cui vengono prodotte nel database di replica primaria.
Importante
SQL Server usa una singola connessione per sincronizzare le modifiche dal database primario alle repliche secondarie. Pertanto, se una replica secondaria è remota, la larghezza della pipe non influirà sulla quantità di dati che SQL Server può inviare. Questa quantità dipende invece dalla latenza di rete nella pipe (velocità di connessione).
Testare la latenza di rete
Controllare se le impostazioni del controllo del flusso contribuiscono alla latenza di rete
I gruppi di disponibilità di Microsoft SQL Server usano controlli di flusso per evitare un consumo eccessivo di risorse di rete, memoria e altre risorse in tutte le repliche di disponibilità. Questi controlli di controllo del flusso non influiscono sullo stato di integrità della sincronizzazione delle repliche di disponibilità. Tuttavia, possono influire sulle prestazioni complessive dei database di disponibilità, incluso RPO.
Le versioni successive di SQL Server modificano le soglie in corrispondenza della quale viene immesso il controllo del flusso. Ciò consente di alleviare l'effetto che il controllo del flusso ha sui sintomi, ad esempio la coda di invio dei log. Per altre informazioni sul controllo del flusso e sulla cronologia delle modifiche apportate alle soglie di controllo del flusso, vedere Gate di controllo del flusso.
È possibile monitorare il controllo del flusso usando Monitor prestazioni per acquisire dati nella replica primaria. Per monitorare il controllo del flusso di database, aggiungere contatori SQLServer:Replica di database e selezionare i contatori Ritardo del controllo del flusso di database e Controlli flusso di database/sec . Nella finestra di dialogo Istanza selezionare il database del gruppo di disponibilità da controllare per il controllo del flusso di database. Per rilevare e monitorare il controllo del flusso di replica di disponibilità, aggiungere contatori SQLServer:Availability Replica e selezionare i contatori Flow Control Time (ms/sec) e Flow Control/sec .
Controllare se il riavvio di Windows congestione contribuisce alla latenza di rete
I problemi di prestazioni di rete che causano la coda di invio dei log possono essere attivati impostando l'impostazione TCP Riavvio di Windows congestione su True. Questa è l'impostazione predefinita in Windows Server 2016. Assicurarsi che il riavvio della finestra di congestione sia impostato su False nei server Windows che ospitano repliche del gruppo di disponibilità in cui viene osservata la coda di invio dei log.
PS C:\WINDOWS\system32> Get-NetTCPSetting | Select SettingName, CwndRestart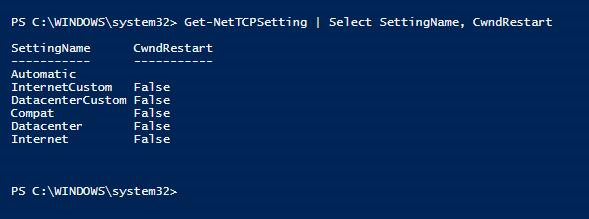
Per altre informazioni su come impostare la proprietà Tcp Congestion Windows Restart su False, vedere Set-NetTCPSetting (NetTCPIP).For more information about how to set the TCP Congestion Windows Restart property to False, see Set-NetTCPSetting (NetTCPIP).
Vedere anche Monitorare le prestazioni per i gruppi di disponibilità AlwaysOn per informazioni sul processo di sincronizzazione. Questo articolo illustra anche come calcolare alcune delle metriche chiave e fornisce collegamenti ad alcuni degli scenari comuni di risoluzione dei problemi relativi alle prestazioni.
Usare ping per ottenere un esempio di latenza
In una riga di comando in node1 (replica primaria), ping node2 (replica secondaria):
C:\Users\customer>ping node2 Pinging node2.customer.corp.company.com [<ip address>] with 32 bytes of data: Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=94ms Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=97ms Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=94ms Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=119ms Ping statistics for 2<ip address>: Packets: Sent = 4, Received = 4, Lost = 0 (0% loss), Approximate round trip times in milli-seconds: Minimum = 94ms, Maximum = 119ms, Average = 101msTestare la velocità effettiva della rete da primaria a secondaria usando uno strumento indipendente
Usare uno strumento come NTttcp per rilevare in modo indipendente la velocità effettiva di rete tra le repliche primarie e secondarie usando una singola connessione. La latenza di rete è una causa comune per la coda di invio dei log. I passaggi seguenti illustrano come usare uno strumento indipendente, ad esempio NTttcp, per misurare la velocità effettiva di rete.
Importante
SQL Server invia le modifiche dalla replica primaria alla replica secondaria usando una singola connessione. Nella sezione seguente viene configurato ed eseguito NTttcp per usare una singola connessione (allo stesso modo di SQL Server) per confrontare con precisione la velocità effettiva.
È possibile scaricare NTttcp da Github - microsoft/ntttcp.
Per eseguire NTttcp, seguire questa procedura:
Scaricare e copiare lo strumento nei server basati su SQL Server primario e secondario.
Nel server di replica secondario aprire una finestra del prompt dei comandi con privilegi elevati, passare alla cartella dello strumento NTttcp e quindi eseguire il comando seguente:
ntttcp.exe -r -m 1,0,<secondaryipaddress>-a 16 -t 60Note
In questo comando
<secondaryipaddress>è un segnaposto per l'indirizzo IP effettivo del server di replica secondario.Nel server di replica primario aprire una finestra del prompt dei comandi con privilegi elevati, passare alla cartella dello strumento NTttcp e quindi eseguire di nuovo il comando seguente specificando di nuovo l'indirizzo IP effettivo del server di replica secondario:
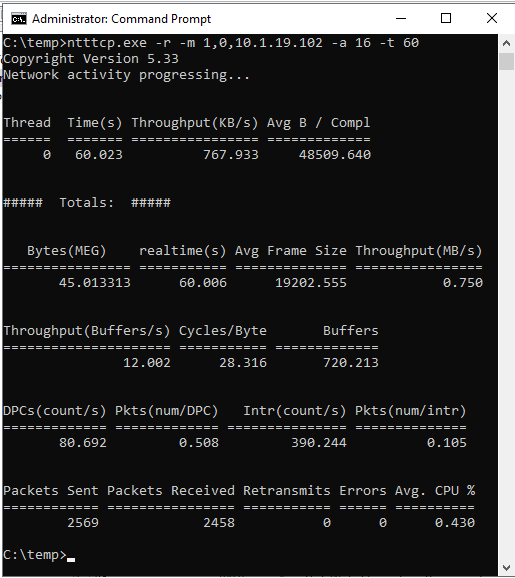
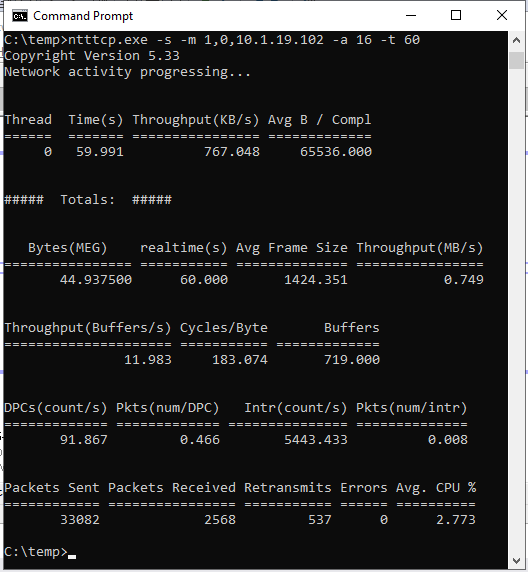
ntttcp.exe -s -m 1,0,<secondaryipaddress>-a 16 -t 60Gli screenshot seguenti mostrano NTttcp in esecuzione nelle repliche secondarie e primarie. A causa della latenza di rete, lo strumento può inviare solo 739 KB/sec di dati. Questo è ciò che si può aspettare che SQL Server sia in grado di inviare.
NTttcp nella replica secondaria
NTttcp nella replica primaria
Esaminare i contatori Monitor prestazioni
Verificare i report di NTttcp. Una transazione di grandi dimensioni viene eseguita in SQL Server nella replica primaria. Dopo aver avviato Monitor prestazioni nella replica primaria, aggiungere il contatore Network Interface::Bytes Sent/sec. Questo contatore conferma che la replica primaria può inviare circa 777 KB/sec di dati. È simile al valore di 739 KB/sec segnalato dal test NTttcp.

È anche utile confrontare il valore SQL Server::D atabases::Log Bytes Flushed/sec nella replica primaria con SQL Server::D atabase Replica::Log Bytes ricevuti/sec per lo stesso database nella replica secondaria. In media, si osservano ~20 MB/sec di modifiche create nel database "agdb". Tuttavia, la replica secondaria riceve, in media, solo 5,4 MB di modifiche. Ciò causerà la coda di invio del log nella replica primaria delle modifiche in sospeso nel log delle transazioni del database che non sono ancora state inviate alla replica secondaria.
Byte log replica primaria scaricati/sec per il database "agdb"

Byte del log della replica secondaria ricevuti/sec per il database agdb
