Risoluzione dei problemi di accodamento del ripristino in un gruppo di disponibilità Always On
Questo articolo fornisce soluzioni ai problemi correlati all'accodamento del ripristino.
Che cos'è l'accodamento del ripristino?
Le modifiche apportate alla replica primaria in un database del gruppo di disponibilità vengono inviate a tutte le repliche secondarie definite nello stesso gruppo di disponibilità. Dopo che queste modifiche arrivano alle repliche secondarie, vengono prima scritte nel file di log delle transazioni del database del gruppo di disponibilità. Microsoft SQL Server usa quindi l'operazione di ripristino o ripristino per aggiornare i file di database.
Se le modifiche apportate a un gruppo di disponibilità arrivano e si rafforzano nel file di log delle transazioni del database più velocemente di quanto possano essere ripristinate, viene creata una coda di ripristino . Questa coda è costituita da transazioni del log delle transazioni protette che non sono state ripristinate e ripristinate nel database.
Sintomi ed effetto dell'accodamento del ripristino (rollforward)
L'esecuzione di query su repliche primarie e secondarie restituisce risultati diversi
I carichi di lavoro di sola lettura che eseguono query sulle repliche secondarie potrebbero eseguire query su dati non aggiornati. Se si verifica l'accodamento del ripristino, le modifiche apportate ai dati nel database di replica primaria potrebbero non essere riflesse nel database secondario quando si eseguono query sugli stessi dati.
Anche se le modifiche arrivano al database secondario e vengono scritte nel file di log del database, le modifiche non verranno sottoposte a query finché non vengono ripristinate e ripristinate nei file di database. L'operazione di ripristino è ciò che rende leggibili tali modifiche.
Per altre informazioni, vedere la sezione Data latency on secondary replica di "Differenze tra le modalità di disponibilità per un gruppo di disponibilità Always On".
Il tempo di failover è più lungo o viene superato il valore RTO
Obiettivo tempo di ripristino (RTO) è il tempo massimo di inattività del database che un'organizzazione può gestire. RTO descrive anche la velocità con cui l'organizzazione può ottenere nuovamente l'accesso al database dopo un'interruzione. Se in una replica secondaria è presente una coda di ripristino sostanziale quando si verifica un failover, il ripristino potrebbe richiedere più tempo. Dopo il ripristino, il database passa al ruolo primario e rappresenta lo stato del database esistente prima del failover. Un tempo di ripristino più lungo può ritardare la ripresa della produzione dopo un failover.
Diverse funzionalità di diagnostica segnalano l'accodamento del ripristino del gruppo di disponibilità
Nel caso della coda di ripristino, il dashboard Always On in SQL Server Management Studio (SSMS) potrebbe segnalare un gruppo di disponibilità non integro.
Come controllare la coda di ripristino (rollforward)
La coda di ripristino è una misura per database che può essere controllata usando il dashboard Always On nella replica primaria o usando la sys.dm_hadr_database_replica_states DMV (Dynamic Management View) nella replica primaria o secondaria. Monitor prestazioni contatori controllano l'accodamento del ripristino e la velocità di recupero. Questi contatori devono essere controllati sulla replica secondaria.
Le sezioni successive forniscono metodi per monitorare attivamente la coda di ripristino del database del gruppo di disponibilità.
Sys.dm_hadr_database_replica_states di query
La sys.dm_hadr_database_replica_states DMV segnala una riga per ogni database del gruppo di disponibilità. Una colonna del report è redo_queue_size. Questo valore corrisponde alle dimensioni della coda di ripristino misurate in kilobyte. È possibile configurare una query simile alla query seguente per monitorare qualsiasi tendenza nelle dimensioni della coda di ripristino ogni 30 secondi. La query viene eseguita nella replica primaria. Usa il is_local=0 predicato per segnalare i dati per la replica secondaria, dove redo_queue_size e redo_rate sono rilevanti.
WHILE 1=1
BEGIN
SELECT drcs.database_name, ars.role_desc, drs.redo_queue_size, drs.redo_rate,
ars.recovery_health_desc, ars.connected_state_desc, ars.operational_state_desc, ars.synchronization_health_desc, *
FROM sys.dm_hadr_availability_replica_states ars JOIN sys.dm_hadr_database_replica_cluster_states drcs ON ars.replica_id=drcs.replica_id
JOIN sys.dm_hadr_database_replica_states drs ON drcs.group_database_id=drs.group_database_id
WHERE ars.role_desc='SECONDARY' AND drs.is_local=0
waitfor delay '00:00:30'
END
Ecco l'aspetto dell'output.

Esaminare la coda di ripristino nel dashboard di Always On
Per esaminare la coda di ripristino, seguire questa procedura:
Aprire il dashboard Always On in SSMS facendo clic con il pulsante destro del mouse su un gruppo di disponibilità in SSMS Esplora oggetti.
Selezionare Mostra dashboard.
I database del gruppo di disponibilità sono elencati per ultimi e sono presenti alcuni dati segnalati nei database. Anche se le dimensioni della coda di rollforward (KB) e la frequenza di rollforward (KB/sec) non sono elencate per impostazione predefinita, è possibile aggiungerle a questa visualizzazione, come illustrato nello screenshot nel passaggio successivo.
Per aggiungere questi contatori, fare clic con il pulsante destro del mouse sull'intestazione sopra i report del database e scegliere dall'elenco delle colonne disponibili.
Per aggiungere Dimensioni coda di rollforward (KB) e Frequenza di rollforward (KB/sec), fare clic con il pulsante destro del mouse sull'intestazione evidenziata in rosso nello screenshot seguente.
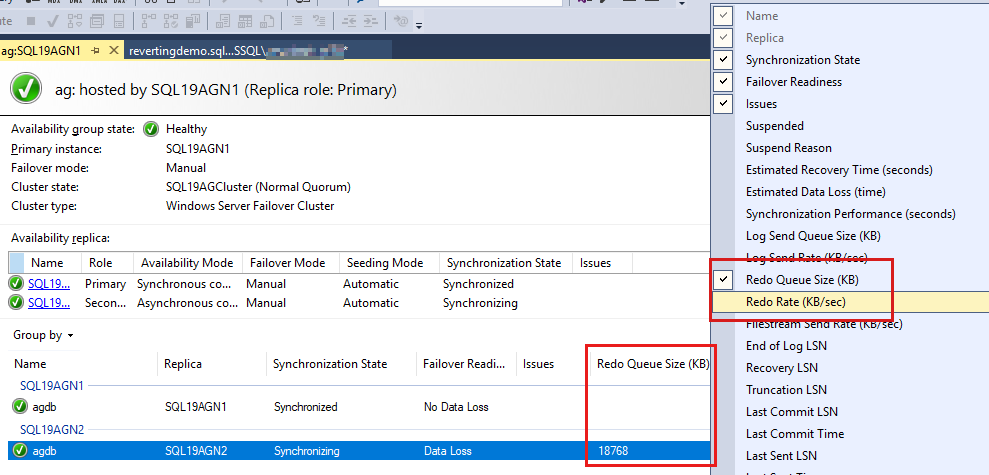
Per impostazione predefinita, il dashboard Always On aggiorna automaticamente le dimensioni della coda di rollforward (KB) e la frequenza di rollforward (KB/sec) ogni 60 secondi.
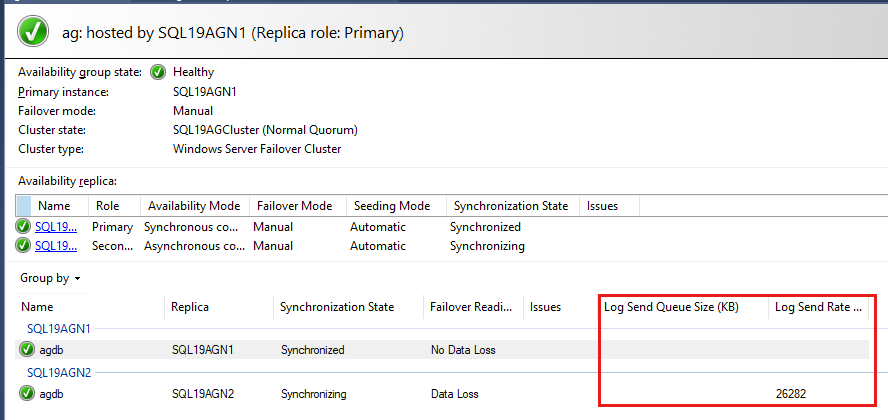


Esaminare la coda di ripristino in Monitor prestazioni
Le dimensioni della coda di ripristino sono univoche per ogni replica e database secondario. Pertanto, per esaminare la coda di ripristino di un database del gruppo di disponibilità, seguire questa procedura:
Aprire Monitor prestazioni nella replica secondaria.
Selezionare il pulsante Aggiungi (contatore).
In Contatori disponibili selezionare SQLServer:Replica database, quindi selezionare Coda di ripristino e Ripeti byte/sec contatori.
Nella casella di riepilogo Istanza selezionare il database del gruppo di disponibilità da monitorare per l'accodamento del ripristino.
Selezionare Aggiungi>OK.
Ecco come potrebbe apparire l'aumento delle code di ripristino.
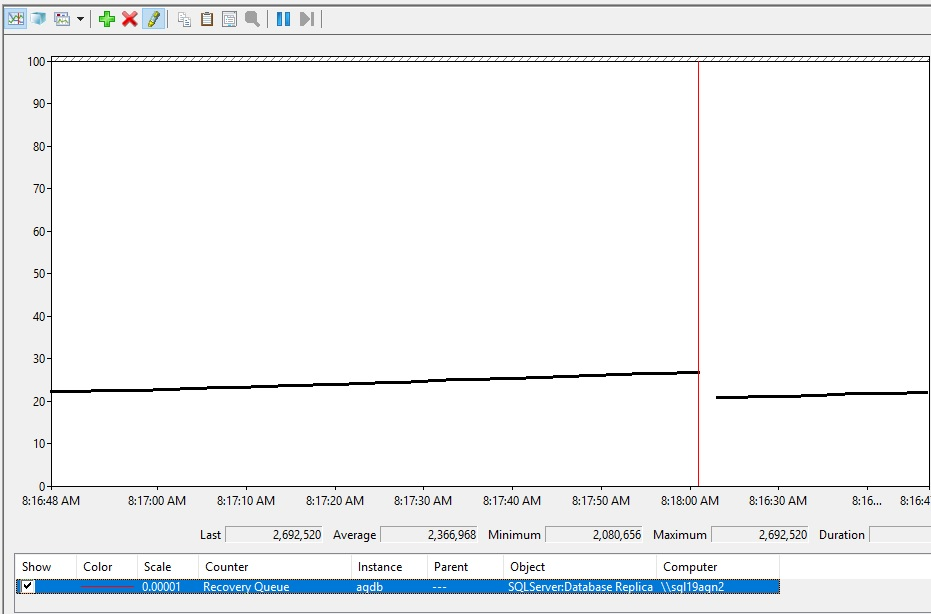

Interpretazione dei valori di accodamento del ripristino
Questa sezione illustra come interpretare i valori correlati all'accodamento del ripristino determinato nella sezione precedente.
Quando è un problema l'accodamento del ripristino? Quanta coda di ripristino è consigliabile tollerare?
Si potrebbe presumere che se la coda di ripristino segnala un valore pari a 0, ciò significa che al momento del report non si verifica alcuna accodamento di ripristino. Tuttavia, quando l'ambiente di produzione è occupato, è consigliabile osservare che la coda di ripristino segnala spesso un valore diverso da zero anche in un ambiente AlwaysOn integro. Durante la produzione tipica, è consigliabile osservare che questo valore varia tra 0 e un valore diverso da zero.
Se si osserva un aumento dell'accodamento del ripristino nel tempo, è necessaria un'ulteriore indagine. Questa attività aggiuntiva indica che è stato modificato qualcosa. Se si osserva una crescita improvvisa nella coda di ripristino, le misurazioni seguenti sono utili per la risoluzione dei problemi:
- Frequenza di rollforward dei log (KB/sec) (dashboard AlwaysOn)
- Redo_rate nel sys.dm_hadr_database_replica_states DMV
Ottenere le tariffe di base per la frequenza di rollforward
Durante le prestazioni AlwaysOn integre, monitorare la frequenza di rollforward nei database del gruppo di disponibilità occupato. Che aspetto hanno durante gli orari di ufficio in genere occupati? Quali sono queste frequenze durante i periodi di manutenzione, quando le transazioni di grandi dimensioni (ricompilazioni degli indici, processi ETL) determinano una velocità effettiva delle transazioni più elevata nel sistema? È possibile confrontare questi valori quando si osserva l'aumento delle code di ripristino per determinare cosa è cambiato. Il carico di lavoro potrebbe essere maggiore del solito. Se la frequenza di rollforward è inferiore, potrebbe essere necessaria un'ulteriore indagine per determinare il motivo.
I volumi del carico di lavoro sono importanti
Quando si dispone di carichi di lavoro di grandi dimensioni, ad esempio un'istruzione UPDATE su un milione di righe, una ricompilazione dell'indice in una tabella da 1 terabyte o anche un batch ETL che inserisce milioni di righe, si dovrebbe prevedere un aumento della coda di ripristino, immediatamente o nel tempo. Ciò è previsto quando un numero elevato di modifiche viene apportato improvvisamente nel database del gruppo di disponibilità.
Come diagnosticare l'accodamento del ripristino (rollforward)
Dopo aver identificato l'accodamento del ripristino per un database del gruppo di disponibilità di replica secondario specifico, connettersi alla replica secondaria e quindi eseguire una query sys.dm_exec_requests per determinare e wait_typewait_time per i thread di ripristino. Ecco una query che può essere eseguita in un ciclo. Si sta cercando una frequenza elevata di uno o più tipi di attesa e anche tempi di attesa per tali tipi di attesa. Ecco una query di esempio che viene eseguita ogni secondo e segnala i tipi di attesa e i tempi di attesa per il gruppo di disponibilità "agdb":
WHILE (1=1)
BEGIN
SELECT db_name(database_id) AS dbname, command, session_id, database_id, wait_type, wait_time,
os.runnable_tasks_count, os.pending_disk_io_count FROM sys.dm_exec_requests der JOIN sys.dm_os_schedulers os
ON der.scheduler_id=os.scheduler_id
WHERE command IN('PARALLEL REDO HELP TASK', 'PARALLEL REDO TASK', 'DB STARTUP')
AND database_id= db_id('agdb')
waitfor delay '00:00:05.000'
END
Importante
Per un output significativo del tipo di attesa, è consigliabile osservare un aumento delle code di ripristino quando si usa uno dei metodi descritti in precedenza per monitorare questa condizione.
In questo esempio vengono segnalati alcuni tipi di attesa correlati a I/O (PAGEIOLATCH_UP, PAGEIOATCH_EX). Monitorare per verificare se questi tipi di attesa continuano ad avere i valori più grandi wait_times , come indicato nella colonna successiva.

SQL Server ripetere i tipi di attesa
Quando viene identificato un tipo di attesa, vedere l'articolo seguente SQL Server 2016/2017: Modello e prestazioni della replica secondaria del gruppo di disponibilità - Microsoft Tech Community come riferimento incrociato per i tipi di attesa comuni che causano l'accodamento del ripristino e per la risoluzione del problema.
Thread di rollforward bloccati nei server di report secondari
Se la soluzione indirizza la creazione di report (query) sui database del gruppo di disponibilità nella replica secondaria, queste query di sola lettura acquisiscono blocchi di stabilità dello schema (Sch-S). Questi blocchi Sch-S possono impedire ai thread di rollforward di acquisire blocchi di modifica dello schema (Sch-M) (noti anche come "blocchi di modifica dello schema" o LCK_M_SCH_M) per apportare modifiche DDL (Data Definition Language), ad ALTER TABLE esempio o ALTER INDEX. Un thread di rollforward bloccato non può applicare i record di log fino a quando non viene sbloccato. Ciò può causare l'accodamento del ripristino.
Per verificare la presenza di prove cronologiche di un rollforward bloccato, aprire i file di traccia AlwaysOn_health Xevent nella replica secondaria usando SSMS. Cercare gli lock_redo_blocked eventi.

Usare Monitor prestazioni per monitorare attivamente l'impatto del rollforward bloccato sulla coda di ripristino. Aggiungere i contatori SQL Server::D atabase Replica::Redo blocked/sec e SQL Server::D atabase Replica::Recovery Queue. Lo screenshot seguente mostra un ALTER TABLE ALTER COLUMN comando eseguito sulla replica primaria mentre viene eseguita una query a esecuzione prolungata sulla stessa tabella nella replica secondaria. Il contatore Redo blocked/sec indica che il ALTER TABLE ALTER COLUMN comando viene eseguito. Mentre la query a esecuzione prolungata è in esecuzione nella stessa tabella nella replica secondaria, eventuali modifiche successive nel database primario causeranno un aumento della coda di ripristino.

Monitorare il tipo di attesa del blocco di modifica dello schema che il thread di rollforward tenta di acquisire. A tale scopo, usare la query descritta in precedenza per controllare i tipi di attesa segnalati per le operazioni di rollforward su sys.dm_exec_requests. È possibile osservare il tempo di attesa crescente per l'oggetto LCK_M_SCH_M nel blocco di rollforward in corso.

Rollforward a thread singolo
SQL Server introdotto il ripristino parallelo per i database di replica secondaria in Microsoft SQL Server 2016. Se si verificano code di ripristino quando si esegue SQL Microsoft Server 2012 o Microsoft SQL Server 2014, è possibile eseguire l'aggiornamento a una versione successiva del programma per migliorare le prestazioni di rollforward nell'ambiente di produzione.
Un rollforward a thread singolo può verificarsi anche in versioni di SQL Server più avanzate in cui viene usata l'architettura di ripristino parallelo. In queste versioni, un'istanza di SQL Server può usare fino a 100 thread per un rollforward parallelo. A seconda del numero di processori e dei database del gruppo di disponibilità, i thread di rollforward paralleli vengono allocati fino a un massimo di 100 thread totali. Se viene raggiunto il limite di rollforward di 100 thread, ad alcuni database del gruppo di disponibilità viene assegnato un singolo thread di rollforward.
Per determinare se il database del gruppo di disponibilità usa il ripristino parallelo, connettersi alla replica secondaria e usare la query seguente per determinare il numero di righe (thread) che applicano il ripristino per il database del gruppo di disponibilità. Nell'esempio seguente, se il database "agdb" è un singolo thread e il relativo comando è DB STARTUP, il carico di lavoro di ripristino potrebbe trarre vantaggio dal ripristino parallelo.
SELECT db_name(database_id) AS dbname, command, session_id, database_id, wait_type, wait_time,
os.runnable_tasks_count, os.pending_disk_io_count FROM sys.dm_exec_requests der JOIN sys.dm_os_schedulers os
ON der.scheduler_id=os.scheduler_id
WHERE command IN ('PARALLEL REDO HELP TASK', 'PARALLEL REDO TASK', 'DB STARTUP')
AND database_id= db_id('agdb')

Se si verifica che il database usi un rollforward a thread singolo, esaminare l'algoritmo descritto in precedenza per determinare se SQL Server supera il numero di 100 thread di lavoro dedicati al ripristino parallelo. Una condizione di questo tipo potrebbe essere il motivo per cui il database "agdb" usa solo un singolo thread per il ripristino.
SQL Server 2022 usa ora un nuovo algoritmo di recupero parallelo in modo che i thread di lavoro vengano assegnati per il ripristino parallelo in base al carico di lavoro. In questo modo si elimina la possibilità che un database occupato rimanga in un ripristino a thread singolo. Per altre informazioni, vedere la sezione Utilizzo dei thread per gruppi di disponibilità di "Prerequisiti, restrizioni e raccomandazioni per i gruppi di disponibilità Always On".