Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo fornisce indicazioni per la risoluzione dei problemi in cui una query di Microsoft SQL Server richiede una quantità eccessiva di tempo di fine (ore o giorni).
Sintomi
Questo articolo è incentrato sulle query che sembrano essere eseguite o compilate senza fine. Ovvero, l'utilizzo della CPU continua ad aumentare. Questo articolo non si applica alle query bloccate o in attesa di una risorsa mai rilasciata. In questi casi, l'utilizzo della CPU rimane costante o cambia solo leggermente.
Importante
Se una query viene lasciata per continuare l'esecuzione, potrebbe terminare. Questo processo potrebbe richiedere solo pochi secondi o diversi giorni. In alcune situazioni, la query potrebbe essere davvero infinita, ad esempio quando un ciclo WHILE non viene chiuso. Il termine "never-ending" viene usato qui per descrivere la percezione di una query che non termina.
Motivo
Le cause comuni delle query a esecuzione prolungata (senza fine) includono:
- Join a ciclo annidato (NL) in tabelle molto grandi: A causa della natura dei join NL, una query che unisce tabelle con un numero elevato di righe potrebbe essere eseguita per molto tempo. Per altre informazioni, vedere Join.
- Un esempio di join NL è l'uso di
TOP,FASToEXISTS. Anche se un join hash o merge potrebbe essere più veloce, l'utilità di ottimizzazione non può usare alcun operatore a causa dell'obiettivo della riga. - Un altro esempio di join NL è l'uso di un predicato join di disuguaglianza in una query. Ad esempio:
SELECT .. FROM tab1 AS a JOIN tab 2 AS b ON a.id > b.id. L'utilità di ottimizzazione non può usare un merge o un hash join.
- Un esempio di join NL è l'uso di
- Statistiche non aggiornate: Le query che selezionano un piano in base a statistiche obsolete potrebbero non essere ottimali e richiedere molto tempo per l'esecuzione.
- Cicli infiniti: Le query T-SQL che usano cicli WHILE potrebbero essere scritte in modo non corretto. Il codice risultante non lascia mai il ciclo e viene eseguito senza fine. Queste query non terminano mai. Vengono eseguiti fino a quando non vengono uccisi manualmente.
- Query complesse con molti join e tabelle di grandi dimensioni: Le query che coinvolgono molte tabelle unite in genere hanno piani di query complessi che potrebbero richiedere molto tempo per l'esecuzione. Questo scenario è comune nelle query analitiche che non filtrano le righe e che coinvolgono un numero elevato di tabelle.
- Indici mancanti: Le query possono essere eseguite in modo molto più rapido se vengono usati indici appropriati nelle tabelle. Gli indici consentono la selezione di un subset dei dati per consentire un accesso più rapido.
Soluzione
Passaggio 1: Individuare query senza fine
Cercare una query senza fine in esecuzione nel sistema. È necessario determinare se una query ha un tempo di esecuzione lungo, un tempo di attesa lungo (bloccato in un collo di bottiglia) o un lungo tempo di compilazione.
1.1 Eseguire una diagnostica
Eseguire la query di diagnostica seguente nell'istanza di SQL Server in cui la query senza fine è attiva:
DECLARE @cntr INT = 0
WHILE (@cntr < 3)
BEGIN
SELECT TOP 10 s.session_id,
r.status,
CAST(r.cpu_time / (1000 * 60.0) AS DECIMAL(10,2)) AS cpu_time_minutes,
CAST(r.total_elapsed_time / (1000 * 60.0) AS DECIMAL(10,2)) AS elapsed_minutes,
r.logical_reads,
r.wait_time,
r.wait_type,
r.wait_resource,
r.reads,
r.writes,
SUBSTRING(st.TEXT, (r.statement_start_offset / 2) + 1,
((CASE r.statement_end_offset
WHEN -1 THEN DATALENGTH(st.TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset) / 2) + 1) AS statement_text,
COALESCE(QUOTENAME(DB_NAME(st.dbid)) + N'.' + QUOTENAME(OBJECT_SCHEMA_NAME(st.objectid, st.dbid))
+ N'.' + QUOTENAME(OBJECT_NAME(st.objectid, st.dbid)), '') AS command_text,
r.command,
s.login_name,
s.host_name,
s.program_name,
s.last_request_end_time,
s.login_time,
r.open_transaction_count,
atrn.name as transaction_name,
atrn.transaction_id,
atrn.transaction_state
FROM sys.dm_exec_sessions AS s
JOIN sys.dm_exec_requests AS r ON r.session_id = s.session_id
CROSS APPLY sys.Dm_exec_sql_text(r.sql_handle) AS st
LEFT JOIN (sys.dm_tran_session_transactions AS stran
JOIN sys.dm_tran_active_transactions AS atrn
ON stran.transaction_id = atrn.transaction_id)
ON stran.session_id =s.session_id
WHERE r.session_id != @@SPID
ORDER BY r.cpu_time DESC
SET @cntr = @cntr + 1
WAITFOR DELAY '00:00:05'
END
1.2 Esaminare l'output
Esistono diversi scenari che possono causare l'esecuzione di una query per molto tempo: esecuzione prolungata, attesa prolungata e compilazione prolungata. Per altre informazioni sul motivo per cui una query potrebbe essere eseguita lentamente, vedere Esecuzione e attesa: perché le query sono lente?
Tempo di esecuzione lungo
I passaggi per la risoluzione dei problemi descritti in questo articolo sono applicabili quando si riceve un output simile al seguente, in cui il tempo della CPU aumenta proporzionalmente al tempo trascorso senza tempi di attesa significativi.
| session_id | stato | cpu_time_minutes | elapsed_time_minutes | logical_reads | wait_time_minutes | wait_type |
|---|---|---|---|---|---|---|
| 56 | in esecuzione | 64.40 | 23.50 | 0 | 0.00 | NULL |
La query viene eseguita continuamente se dispone di:
- Un aumento del tempo di CPU
- Stato di
runningorunnable - Tempo di attesa minimo o zero
- Nessun wait_type
In questo caso, la query legge le righe, l'unione, l'elaborazione dei risultati, il calcolo o la formattazione. Queste attività sono tutte azioni associate alla CPU.
Note
Le modifiche apportate in logical_reads non sono rilevanti in questo caso perché alcune richieste T-SQL associate alla CPU, ad esempio l'esecuzione di calcoli o un WHILE ciclo, potrebbero non eseguire alcuna lettura logica.
Se la query lenta soddisfa questi criteri, concentrarsi sulla riduzione del runtime. In genere, la riduzione del runtime comporta la riduzione del numero di righe che la query deve elaborare per tutta la durata applicando indici, riscrivendo la query o aggiornando le statistiche. Per altre informazioni, vedere la sezione Risoluzione .
Tempo di attesa lungo
Questo articolo non è applicabile agli scenari di attesa lunghi. In uno scenario di attesa, è possibile ricevere un output simile all'esempio seguente in cui l'utilizzo della CPU non cambia o cambia leggermente perché la sessione è in attesa di una risorsa:
| session_id | stato | cpu_time_minutes | elapsed_time_minutes | logical_reads | wait_time_minutes | wait_type |
|---|---|---|---|---|---|---|
| 56 | suspended | 0.03 | 4.20 | 50 | 4.10 | LCK_M_U |
Il tipo di attesa indica che la sessione è in attesa di una risorsa. Un lungo tempo trascorso e un lungo tempo di attesa indicano che la sessione è in attesa della maggior parte della durata per questa risorsa. Il tempo di CPU breve indica che è stato impiegato poco tempo per l'elaborazione della query.
Per risolvere i problemi relativi alle query lunghe a causa delle attese, vedere Risolvere i problemi relativi alle query a esecuzione lenta in SQL Server.
Tempo di compilazione lungo
In rari casi, è possibile osservare che l'utilizzo della CPU aumenta continuamente nel tempo, ma non dipende dall'esecuzione della query. Una compilazione eccessivamente lunga (l'analisi e la compilazione di una query) potrebbe invece essere la causa. In questi casi, controllare la transaction_name colonna di output per il valore .sqlsource_transform Questo nome di transazione indica una compilazione.
Passaggio 2: Raccogliere manualmente i log di diagnostica
Dopo aver determinato che nel sistema esiste una query senza fine, è possibile raccogliere i dati del piano della query per risolvere ulteriori problemi. Per raccogliere i dati, usare uno dei metodi seguenti, a seconda della versione di SQL Server.
- SQL Server 2008 - SQL Server 2014 (precedente a SP2)
- SQL Server 2014 (versioni successive a SP2) e SQL Server 2016 (precedenti a SP1)
- SQL Server 2016 (versioni successive a SP1) e SQL Server 2017
- SQL Server 2019 e versioni successive
Per raccogliere dati di diagnostica tramite SQL Server Management Studio (SSMS), seguire questa procedura:
Acquisire il codice XML del piano di esecuzione delle query stimato.
Esaminare il piano di query per scoprire se i dati mostrano indicazioni evidenti di ciò che causa la lentezza. Esempi di indicazioni tipiche includono:
- Analisi di tabelle o indici (esaminare le righe stimate)
- Cicli annidati basati su un set di dati di tabella esterno enorme
- Cicli annidati con un ramo di grandi dimensioni nel lato interno del ciclo
- Pool di tabelle
- Funzioni nell'elenco
SELECTche richiedono molto tempo per elaborare ogni riga
Se la query viene eseguita più rapidamente in qualsiasi momento, è possibile acquisire le esecuzioni "veloci" (piano di esecuzione XML effettivo) per confrontare i risultati.
Usare SQL LogScout per acquisire query senza fine
È possibile usare SQL LogScout per acquisire i log durante l'esecuzione di una query senza fine. Usare lo scenario di query senza fine con il comando seguente:
.\SQL_LogScout.ps1 -Scenario "NeverEndingQuery" -ServerName "SQLInstance"
Note
Questo processo di acquisizione dei log richiede che la query lunga consumi almeno 60 secondi di tempo della CPU.
SQL LogScout acquisisce almeno tre piani di query per ogni query che usa una CPU elevata. È possibile trovare nomi di file simili a servername_datetime_NeverEnding_statistics_QueryPlansXml_Startup_sessionId_#.sqlplan. È possibile usare questi file nel passaggio successivo quando si esaminano i piani per identificare il motivo per l'esecuzione di query lunghe.
Passaggio 3: Esaminare i piani raccolti
In questa sezione viene illustrato come esaminare i dati raccolti. Usa più piani di query XML (usando l'estensione .sqlplan) raccolti in Microsoft SQL Server 2016 SP1 e versioni successive.
Confrontare i piani di esecuzione seguendo questa procedura:
Aprire un file del piano di esecuzione delle query salvato in precedenza (
.sqlplan).Fare clic con il pulsante destro del mouse in un'area vuota del piano di esecuzione e selezionare Confronta Showplan.
Scegliere il secondo file del piano di query da confrontare.
Cercare frecce spesse che indicano un numero elevato di righe che passano tra gli operatori. Selezionare quindi l'operatore prima o dopo la freccia e confrontare il numero di righe effettive nei due piani.
Confrontare il secondo e il terzo piano per determinare se il flusso più grande di righe si verifica negli stessi operatori.
Per esempio:
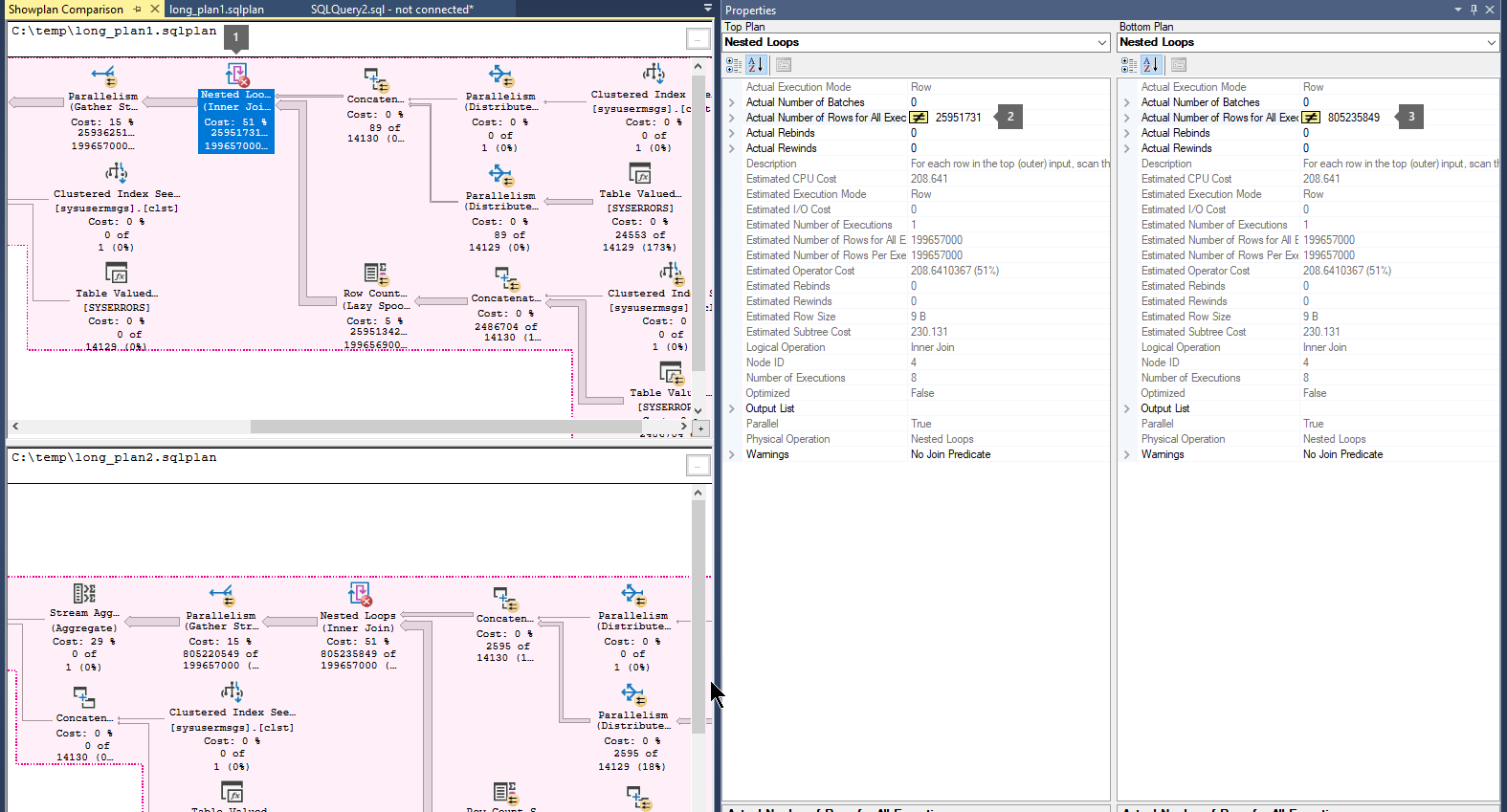

Passaggio 4: Risoluzione
Assicurarsi che le statistiche vengano aggiornate per le tabelle usate nella query.
Cercare le raccomandazioni sugli indici mancanti nel piano di query e applicare qualsiasi elemento trovato.
Semplificare la query:
- Usare predicati più selettivi
WHEREper ridurre i dati elaborati in anticipo. - Scomponerlo.
- Selezionare alcune parti nelle tabelle temporanee e aggiungerle in un secondo momento.
- Rimuovere
TOP,EXISTSeFAST(T-SQL) nelle query eseguite per molto tempo a causa di un obiettivo di riga dell'utilità di ottimizzazione.- In alternativa, usare
DISABLE_OPTIMIZER_ROWGOAL. Per altre informazioni, vedere Obiettivi di riga non autorizzati.
- In alternativa, usare
- Evitare di usare espressioni di tabella comuni in questi casi perché combinano istruzioni in una singola query di grandi dimensioni.
- Usare predicati più selettivi
Provare a usare hint per la query per produrre un piano migliore:
-
HASH JOINoMERGE JOINhint - Hint
FORCE ORDER - Hint
FORCESEEK RECOMPILE- USE
PLAN N'<xml_plan>'(se si dispone di un piano di query rapido che è possibile forzare)
-
Usare Query Store (QDS) per forzare un piano noto se tale piano esiste e se la versione di SQL Server supporta Query Store.