Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a: SQL Server
Questo articolo fornisce indicazioni sui problemi di I/O che causano un rallentamento delle prestazioni di SQL Server e su come risolvere i problemi.
Definire prestazioni di I/O lente
I contatori del monitoraggio delle prestazioni vengono usati per determinare le prestazioni di I/O lente. Questi contatori misurano quanto rapidamente il sottosistema di I/O serve in media ogni richiesta di I/O in base al tempo di clock. I contatori specifici del Monitor delle Prestazioni che misurano la latenza di I/O in Windows sono Avg Disk sec/ Read, Avg. Disk sec/Write, e Avg. Disk sec/Transfer (cumulativo di letture e scritture).
In SQL Server le operazioni funzionano allo stesso modo. In genere, si esamina se SQL Server segnala eventuali colli di bottiglia di I/O misurati in tempo di clock (millisecondi). SQL Server effettua richieste di I/O al sistema operativo chiamando le funzioni Win32, WriteFile()ad esempio , ReadFile()WriteFileGather(), e ReadFileScatter(). Quando invia una richiesta di I/O, SQL Server misura la durata della richiesta e la segnala usando tipi di attesa. SQL Server usa i tipi di attesa per indicare le attese di I/O in posizioni diverse del prodotto. Le attese riguardanti l'I/O sono:
Se queste attese superano 10-15 millisecondi in modo coerente, l'I/O viene considerato un collo di bottiglia.
Note
Per fornire contesto e prospettiva, nel mondo della risoluzione dei problemi di SQL Server, Microsoft CSS ha osservato casi in cui una richiesta di I/O ha impiegato oltre un secondo e anche fino a 15 secondi per trasferimento; un tale sistema di I/O necessita di ottimizzazione. Al contrario, Microsoft CSS ha visto sistemi in cui la velocità effettiva è inferiore a un millisecondo/trasferimento. Con la tecnologia SSD/NVMe di oggi, i tassi di velocità effettiva annunciati sono compresi in decine di microsecondi per trasferimento. Pertanto, la cifra di trasferimento di 10-15 millisecondi è una soglia molto approssimativa selezionata in base all'esperienza collettiva tra i tecnici di Windows e SQL Server nel corso degli anni. In genere, quando i numeri superano questa soglia approssimativa, gli utenti di SQL Server iniziano a visualizzare la latenza nei carichi di lavoro e a segnalarli. In definitiva, la velocità effettiva prevista di un sottosistema di I/O è definita dal produttore, dal modello, dalla configurazione, dal carico di lavoro e potenzialmente da più altri fattori.
Metodologia
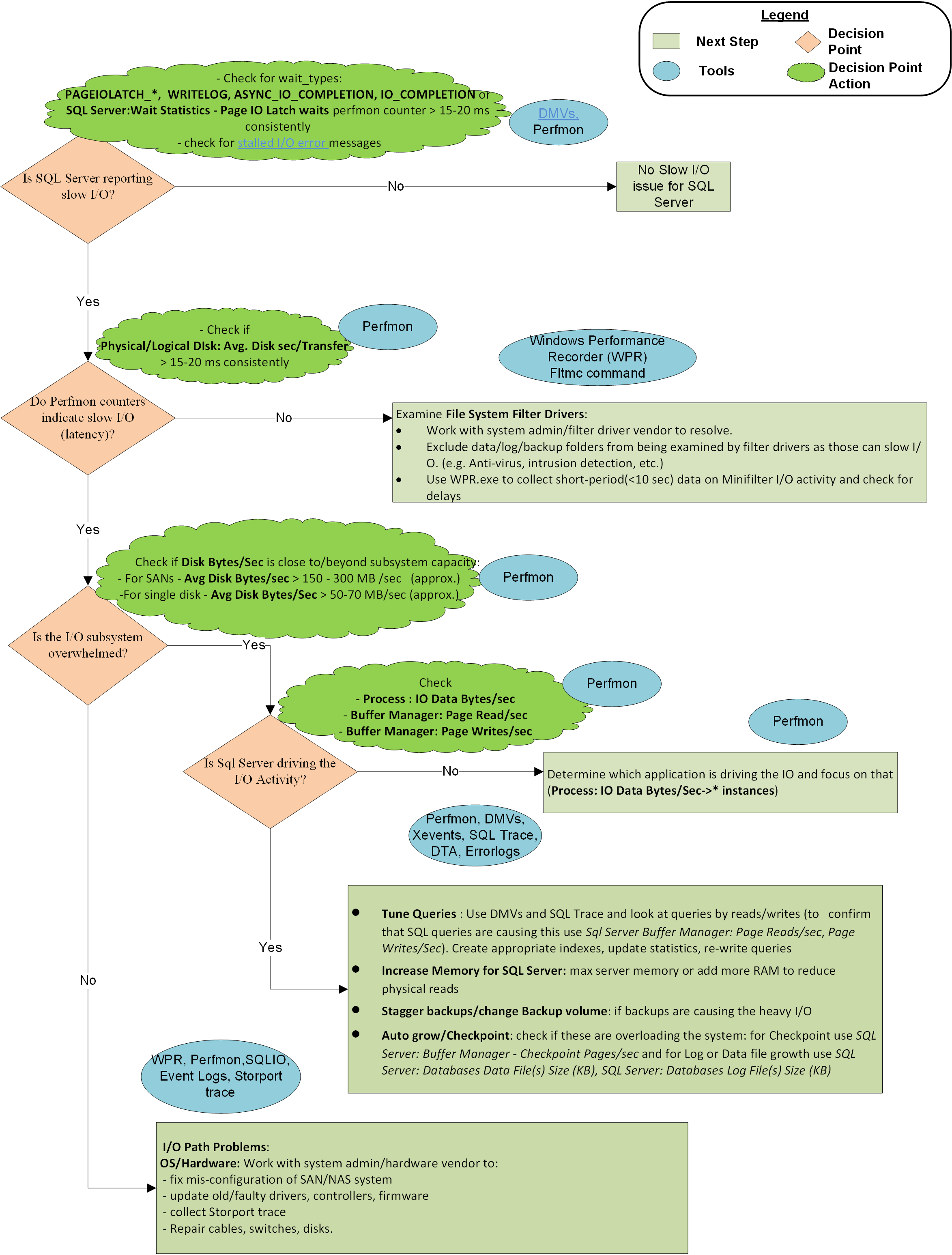
Un diagramma di flusso alla fine di questo articolo descrive la metodologia usata da Microsoft CSS per affrontare problemi di I/O lenti con SQL Server. Non è un approccio esaustivo o esclusivo, ma ha dimostrato di essere utile per isolare il problema e risolverlo.
La metodologia è descritta nei passaggi seguenti:
Passaggio 1: L'I/O dei report di SQL Server è lento?
SQL Server può segnalare la latenza di I/O in diversi modi:
- Tipi di attesa di I/O
- DMV
sys.dm_io_virtual_file_stats - Log degli errori o registro eventi dell'applicazione
Tipi di attesa di I/O
Determinare se è presente una latenza di I/O segnalata dai tipi di attesa di SQL Server. I valori PAGEIOLATCH_*, WRITELOGe ASYNC_IO_COMPLETION i valori di diversi altri tipi di attesa meno comuni devono in genere rimanere inferiori a 10-15 millisecondi per ogni richiesta di I/O. Se questi valori sono più coerenti, esiste un problema di prestazioni di I/O e richiede ulteriori indagini. La query seguente può essere utile per raccogliere queste informazioni di diagnostica nel sistema:
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
for ([int]$i = 0; $i -lt 100; $i++)
{
sqlcmd -E -S $sqlserver_instance -Q "SELECT r.session_id, r.wait_type, r.wait_time as wait_time_ms`
FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s `
ON r.session_id = s.session_id `
WHERE wait_type in ('PAGEIOLATCH_SH', 'PAGEIOLATCH_EX', 'WRITELOG', `
'IO_COMPLETION', 'ASYNC_IO_COMPLETION', 'BACKUPIO')`
AND is_user_process = 1"
Start-Sleep -s 2
}
Statistiche dei file in sys.dm_io_virtual_file_stats
Per visualizzare la latenza a livello di file di database come indicato in SQL Server, eseguire la query seguente:
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
sqlcmd -E -S $sqlserver_instance -Q "SELECT LEFT(mf.physical_name,100), `
ReadLatency = CASE WHEN num_of_reads = 0 THEN 0 ELSE (io_stall_read_ms / num_of_reads) END, `
WriteLatency = CASE WHEN num_of_writes = 0 THEN 0 ELSE (io_stall_write_ms / num_of_writes) END, `
AvgLatency = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 0 `
ELSE (io_stall / (num_of_reads + num_of_writes)) END,`
LatencyAssessment = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 'No data' ELSE `
CASE WHEN (io_stall / (num_of_reads + num_of_writes)) < 2 THEN 'Excellent' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 2 AND 5 THEN 'Very good' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 6 AND 15 THEN 'Good' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 16 AND 100 THEN 'Poor' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 100 AND 500 THEN 'Bad' `
ELSE 'Deplorable' END END, `
[Avg KBs/Transfer] = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 0 `
ELSE ((([num_of_bytes_read] + [num_of_bytes_written]) / (num_of_reads + num_of_writes)) / 1024) END, `
LEFT (mf.physical_name, 2) AS Volume, `
LEFT(DB_NAME (vfs.database_id),32) AS [Database Name]`
FROM sys.dm_io_virtual_file_stats (NULL,NULL) AS vfs `
JOIN sys.master_files AS mf ON vfs.database_id = mf.database_id `
AND vfs.file_id = mf.file_id `
ORDER BY AvgLatency DESC"
Esaminare le AvgLatency colonne e LatencyAssessment per comprendere i dettagli della latenza.
Errore 833 segnalato nel log degli errori o nel registro eventi dell'applicazione
In alcuni casi, è possibile osservare l'errore 833 SQL Server has encountered %d occurrence(s) of I/O requests taking longer than %d seconds to complete on file [%ls] in database [%ls] (%d) nel log degli errori. È possibile controllare i log degli errori di SQL Server nel sistema eseguendo il comando di PowerShell seguente:
Get-ChildItem -Path "c:\program files\microsoft sql server\mssql*" -Recurse -Include Errorlog |
Select-String "occurrence(s) of I/O requests taking longer than Longer than 15 secs"
Per altre informazioni su questo errore, vedere anche la sezione MSSQLSERVER_833 .
Passaggio 2: I contatori perfmon indicano la latenza di I/O?
Se SQL Server segnala la latenza di I/O, fare riferimento ai contatori del sistema operativo. È possibile determinare se si è verificato un problema di I/O esaminando il contatore Avg Disk Sec/Transferdella latenza . Il frammento di codice seguente indica un modo per raccogliere queste informazioni tramite PowerShell. Raccoglie i contatori in tutti i volumi del disco: "_total". Cambia a un volume di unità disco specifico, ad esempio "D:". Per trovare i volumi che ospitano i file di database, eseguire la query seguente in SQL Server:
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
sqlcmd -E -S $sqlserver_instance -Q "SELECT DISTINCT LEFT(volume_mount_point, 32) AS volume_mount_point `
FROM sys.master_files f `
CROSS APPLY sys.dm_os_volume_stats(f.database_id, f.file_id) vs"
Raccogli Avg Disk Sec/Transfer metriche sul volume di tua scelta.
clear
$cntr = 0
# replace with your server name, unless local computer
$serverName = $env:COMPUTERNAME
# replace with your volume name - C: , D:, etc
$volumeName = "_total"
$Counters = @(("\\$serverName" +"\LogicalDisk($volumeName)\Avg. disk sec/transfer"))
$disksectransfer = Get-Counter -Counter $Counters -MaxSamples 1
$avg = $($disksectransfer.CounterSamples | Select-Object CookedValue).CookedValue
Get-Counter -Counter $Counters -SampleInterval 2 -MaxSamples 30 | ForEach-Object {
$_.CounterSamples | ForEach-Object {
[pscustomobject]@{
TimeStamp = $_.TimeStamp
Path = $_.Path
Value = ([Math]::Round($_.CookedValue, 5))
turn = $cntr = $cntr +1
running_avg = [Math]::Round(($avg = (($_.CookedValue + $avg) / 2)), 5)
} | Format-Table
}
}
write-host "Final_Running_Average: $([Math]::Round( $avg, 5)) sec/transfer`n"
if ($avg -gt 0.01)
{
Write-Host "There ARE indications of slow I/O performance on your system"
}
else
{
Write-Host "There is NO indication of slow I/O performance on your system"
}
Se i valori di questo contatore sono costantemente superiori a 10-15 millisecondi, è necessario esaminare ulteriormente il problema. I picchi occasionali non vengono conteggiati nella maggior parte dei casi, ma assicurarsi di controllare la durata di un picco. Se il picco è durato un minuto o più, è più di un altipiano rispetto a un picco.
Se i contatori di Monitoraggio prestazioni non segnalano la latenza, ma SQL Server lo fa, il problema è tra SQL Server e Gestione partizioni, ovvero i driver di filtro. Gestione partizioni è un livello di I/O in cui il sistema operativo raccoglie i contatori Perfmon . Per risolvere la latenza, verificare le esclusioni appropriate dei driver di filtro e risolvere i problemi del driver di filtro. I driver di filtro vengono usati da programmi come software antivirus, soluzioni di backup, crittografia, compressione e così via. È possibile usare questo comando per elencare i driver di filtro nei sistemi e i volumi a cui si collegano. È quindi possibile cercare i nomi dei driver e i fornitori di software nell'articolo Altitudini filtro allocate.
fltmc instances
Per altre informazioni, vedere Come scegliere il software antivirus da eseguire nei computer che eseguono SQL Server.
Evitare di utilizzare Encrypting File System (EFS) e la compressione del file system poiché entrambi causano il passaggio da operazioni di I/O asincrono a sincrono, rendendole quindi più lente. Per altre informazioni, vedere l'articolo L'I/O del disco asincrono appare come sincrono in Windows.
Passaggio 3: Il sottosistema di I/O è sovraccarico oltre la capacità?
Se SQL Server e il sistema operativo indicano che il sottosistema di I/O è lento, verificare se la causa è il sovraccarico del sistema oltre la capacità. È possibile controllare la capacità esaminando i contatori Disk Bytes/Secdi I/O , Disk Read Bytes/Seco Disk Write Bytes/Sec. Assicurarsi di contattare l'amministratore di sistema o il fornitore dell'hardware per le specifiche di velocità effettiva previste per la rete SAN (o un altro sottosistema di I/O). Ad esempio, è possibile eseguire il push di non più di 200 MB/sec di I/O tramite una scheda HBA da 2 GB/sec o una porta dedicata di 2 GB/sec su un commutatore SAN. La capacità di throughput prevista definita dal produttore dell'hardware determina come procedere da qui.
clear
$serverName = $env:COMPUTERNAME
$Counters = @(
("\\$serverName" +"\PhysicalDisk(*)\Disk Bytes/sec"),
("\\$serverName" +"\PhysicalDisk(*)\Disk Read Bytes/sec"),
("\\$serverName" +"\PhysicalDisk(*)\Disk Write Bytes/sec")
)
Get-Counter -Counter $Counters -SampleInterval 2 -MaxSamples 20 | ForEach-Object {
$_.CounterSamples | ForEach-Object {
[pscustomobject]@{
TimeStamp = $_.TimeStamp
Path = $_.Path
Value = ([Math]::Round($_.CookedValue, 3)) }
}
}
Passaggio 4: SQL Server sta guidando l'attività di I/O pesante?
Se il sottosistema di I/O è sovraccarico oltre la capacità, verificare se SQL Server è il colpevole esaminando Buffer Manager: Page Reads/Sec (responsabile più comune) e Page Writes/Sec (decisamente meno comune) per l'istanza specifica. Se SQL Server è il driver di I/O principale e il volume di I/O è superiore a quello che il sistema può gestire, collaborare con i team di sviluppo di applicazioni o il fornitore di applicazioni per:
- Ottimizzare le query, ad esempio indici migliori, aggiornare le statistiche, riscrivere le query e riprogettare il database.
- Aumentare la memoria massima del server o aggiungere più RAM nel sistema. Più RAM memorizza nella cache più pagine di dati o indici senza ripetere frequentemente la lettura dal disco, riducendo così l'attività di I/O. Una maggiore memoria può anche ridurre
Lazy Writes/sec, che sono guidate dagli scaricamenti del Lazy Writer quando è frequente la necessità di archiviare più pagine di database nella limitata memoria disponibile. - Se si rileva che le scritture di pagina sono l'origine di un'attività di I/O pesante, esaminare
Buffer Manager: Checkpoint pages/secper controllare se è dovuto a enormi svuotamenti di pagina necessari per soddisfare le esigenze di configurazione dell'intervallo di ripristino. È possibile usare checkpoint indiretti per uniformare le operazioni di I/O nel tempo o aumentare la velocità di I/O dell'hardware.
Cause
In generale, i problemi seguenti sono i motivi principali per cui le query di SQL Server soffrono di latenza di I/O:
Problemi hardware:
Configurazione errata della SAN (commutatore, cavi, HBA, dispositivi di archiviazione)
È stata superata la capacità di I/O (disequilibrata nell'intera rete SAN, non solo nella memoria di back-end)
Problemi relativi a driver o firmware
I fornitori di hardware e/o gli amministratori di sistema devono essere coinvolti in questa fase.
Problemi di query: SQL Server sta saturando i volumi dei dischi con richieste di I/O ed esegue il push del sottosistema di I/O oltre la capacità, causando un'elevata velocità di trasferimento di I/O. In questo caso, la soluzione consiste nel trovare le query che causano un numero elevato di letture logiche (o scritture) e ottimizzare tali query per ridurre al minimo l'I/O del disco usando gli indici appropriati è il primo passaggio per eseguire questa operazione. Inoltre, mantenere aggiornate le statistiche man mano che forniscono a Query Optimizer informazioni sufficienti per scegliere il piano migliore. Inoltre, la progettazione errata del database e la progettazione di query possono causare un aumento dei problemi di I/O. Di conseguenza, la riprogettazione delle query e talvolta delle tabelle può risultare utile per migliorare l'I/O.
Driver di filtro: la risposta di I/O di SQL Server può essere gravemente influenzata se i driver di filtro del file system gestiscono un traffico di I/O intenso. Le esclusioni di file appropriate dall'analisi antivirus e la corretta progettazione del driver di filtro da parte dei fornitori di software sono consigliate per evitare l'impatto sulle prestazioni di I/O.
Altre applicazioni: un'altra applicazione nello stesso computer con SQL Server può saturare il percorso di I/O con richieste di lettura o scrittura eccessive. Questa situazione può spingere il sottosistema di I/O oltre i limiti di capacità e causare lentezza di I/O per SQL Server. Identificare l'applicazione e ottimizzarla o spostarla altrove per eliminare l'impatto sullo stack di I/O.
Rappresentazione grafica della metodologia
Informazioni sui tipi di attesa correlati a I/O
Di seguito sono riportate le descrizioni dei tipi di attesa comuni osservati in SQL Server quando vengono segnalati problemi di I/O del disco.
PAGEIOLATCH_EX
Si verifica quando un'attività è in attesa di un latch per una pagina di dati o di indice (buffer) in una richiesta di I/O. La richiesta di latch è in modalità esclusiva. Una modalità esclusiva viene usata quando il buffer viene scritto su disco. Attese prolungate possono indicare problemi con il sottosistema disco.
PAGEIOLATCH_SH
Si verifica quando un'attività è in attesa di un latch per una pagina dati o una pagina indice (buffer) durante una richiesta di I/O. La richiesta di latch è in modalità Condivisa. La modalità Condivisa viene usata quando il buffer viene letto dal disco. Attese prolungate possono indicare problemi con il sottosistema disco.
PAGEIOLATCH_UP
Si verifica quando un'operazione è in attesa di un latch per un buffer in una richiesta di I/O. La richiesta di latch è in modalità di aggiornamento. Attese prolungate possono indicare problemi con il sottosistema disco.
WRITELOG
Si verifica quando un'attività è in attesa del completamento dello scaricamento di un log delle transazioni. Uno scaricamento si verifica quando Gestione log scrive il relativo contenuto temporaneo su disco. Le operazioni comuni che causano lo scaricamento dei log sono i commit e i checkpoint delle transazioni.
I motivi comuni per i lunghi tempi di attesa WRITELOG sono i seguenti:
Latenza del disco di log delle transazioni: questa è la causa più comune di
WRITELOGtempi di attesa. In genere, è consigliabile mantenere i file di dati e di log in volumi separati. Le scritture del log delle transazioni sono sequenziali, mentre la lettura o scrittura di dati da un file di dati è casuale. La combinazione di file di dati e di log in un volume di unità disco (specialmente i dischi rigidi meccanici convenzionali) causerà un movimento eccessivo della testa del disco.Troppi file di log virtuali: troppi file di log virtuali (VLF) possono causare
WRITELOGattese. Troppi file VLF possono causare altri tipi di problemi, ad esempio un tempo di ripristino prolungato.Troppe transazioni di piccole dimensioni: mentre le transazioni di grandi dimensioni possono causare un blocco, troppe transazioni di piccole dimensioni possono causare un altro set di problemi. Se non si avvia in modo esplicito una transazione, qualsiasi operazione di inserimento, eliminazione o aggiornamento comporterà una transazione (questa transazione automatica viene chiamata transazione automatica). Se si eseguono 1.000 inserimenti in un ciclo, verranno generate 1.000 transazioni. Ogni transazione in questo esempio deve eseguire il commit, che comporta lo scaricamento di un log delle transazioni e 1.000 scaricamenti delle transazioni. Quando possibile, raggruppare singoli aggiornamenti, eliminare o inserire in una transazione più grande per ridurre gli scaricamenti del log delle transazioni e migliorare le prestazioni. Questa operazione può comportare un minor numero
WRITELOGdi attese.Problemi di pianificazione causano la mancata tempestività della pianificazione dei thread di Log Writer: prima di SQL Server 2016, un singolo thread di Log Writer eseguiva tutte le scritture di log. Se si sono verificati problemi con la pianificazione dei thread (ad esempio, cpu elevata), sia il thread del writer di log che gli scaricamenti dei log potrebbero essere ritardati. In SQL Server 2016 sono stati aggiunti fino a quattro thread del writer di log per aumentare la velocità effettiva di scrittura dei log. Consulta SQL 2016 - Funziona semplicemente più velocemente: più processi del writer del log. In SQL Server 2019 sono stati aggiunti fino a otto thread dello scrittore di log, migliorando ancora di più le prestazioni. Inoltre, in SQL Server 2019, ogni thread di lavoro normale può eseguire le scritture dei log direttamente anziché postare al thread del writer di log. Con questi miglioramenti,
WRITELOGle attese raramente vengono causate da problemi di pianificazione.
ASYNC_IO_COMPLETION
Si verifica quando si verificano alcune delle attività di I/O seguenti:
- Il provider di inserimento bulk ("Insert Bulk") utilizza questo tipo di attesa durante le operazioni di I/O.
- Lettura del file di annullamento in Log Shipping e indirizzamento dell'I/O asincrono per Log Shipping.
- Lettura dei dati effettivi dai file di dati durante un backup dei dati.
IO_COMPLETION
Si verifica durante l'attesa del completamento di operazioni di I/O. Questo tipo di attesa prevede in genere operazioni di I/O non correlate alle pagine di dati (buffer). Alcuni esempi:
- Lettura e scrittura su disco dei risultati di ordinamento/hash durante un overflow (controllare le prestazioni dell'archiviazione di tempdb).
- Lettura e scrittura di spool entusiasti su disco (controllare l'archiviazione del database temporaneo tempdb).
- Lettura dei blocchi di log dal log delle transazioni (durante qualsiasi operazione che causa la lettura del log dal disco, ad esempio il ripristino).
- Lettura di una pagina dal disco quando il database non è ancora configurato.
- Copia di pagine in uno snapshot del database (copia in scrittura).
- Chiusura del file di database e della decompressione dei file.
BACKUPIO
Si verifica quando un'attività di backup è in attesa di dati o è in attesa di un buffer per archiviare i dati. Questo tipo non è tipico, tranne quando un'attività è in attesa di un montaggio su nastro.