Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
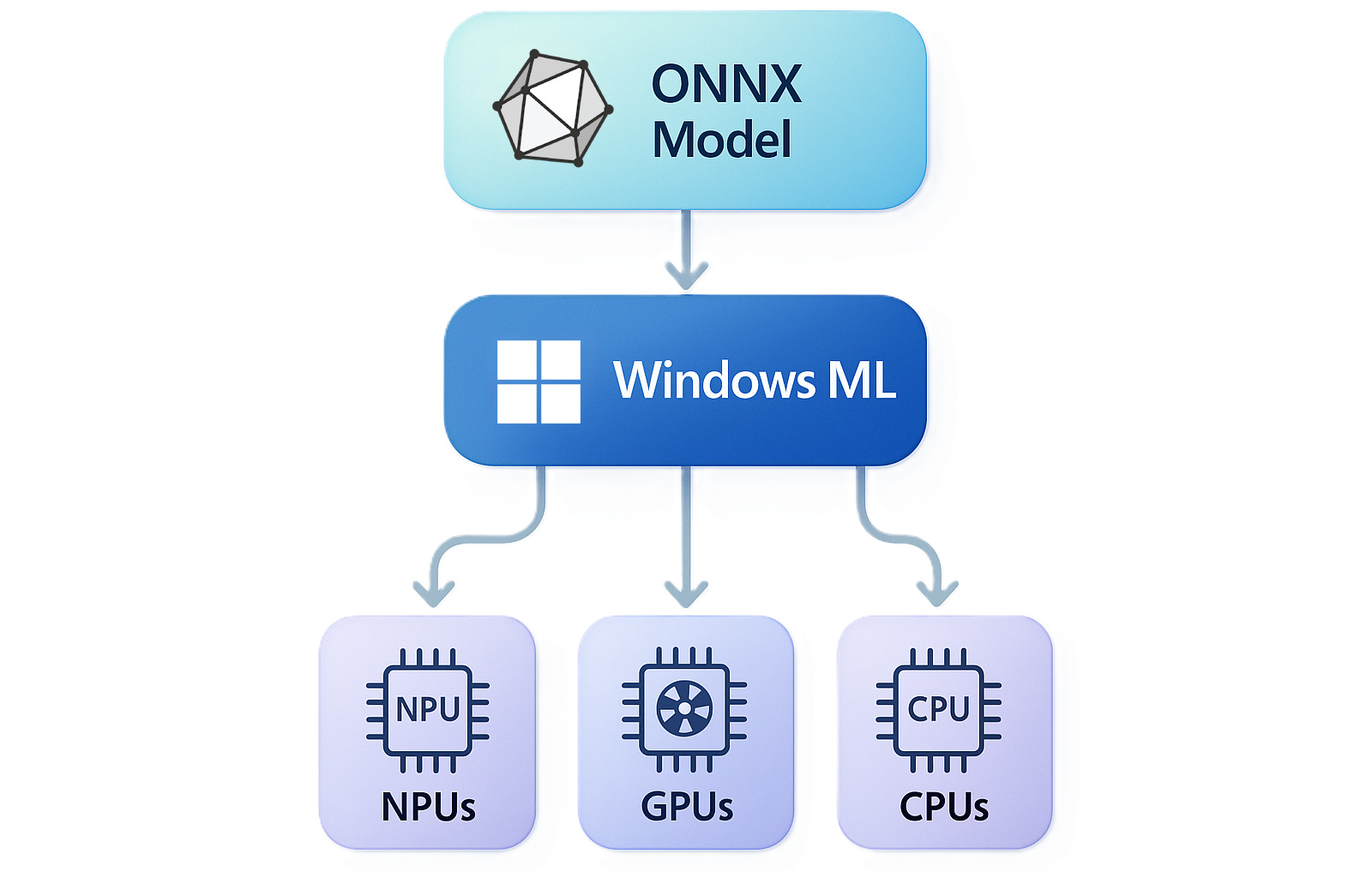
Windows ML è il framework di inferenza di intelligenza artificiale locale unificato e ad alte prestazioni per Windows, basato su ONNX Runtime. Con Windows ML, è possibile eseguire modelli di intelligenza artificiale localmente e accelerare l'inferenza su NPU, GPU e CPU tramite provider di esecuzione facoltativi gestiti e aggiornati da Windows. È possibile usare modelli di PyTorch, TensorFlow/Keras, TFLite, scikit-learn e altri framework con Windows ML.
Vantaggi principali
Windows ML semplifica l'inferenza dell'intelligenza artificiale in qualsiasi app di Windows:
- Eseguire l'intelligenza artificiale sul dispositivo : i modelli vengono eseguiti localmente nell'hardware dell'utente, mantenendo i dati privati, eliminando i costi del cloud e senza una connessione Internet.
- Usare i modelli già disponibili : usare modelli da PyTorch, TensorFlow, scikit-learn, Hugging Face e altro ancora.
- Accelerazione hardware, facilitata da Windows - Windows ML consente di accedere a NPU, GPU e CPU specifiche di IHV tramite provider di esecuzione che Windows installa e mantiene aggiornati tramite Windows Update, non è necessario aggregare i provider di esecuzione nella tua app.
- Un runtime, molte app — facoltativamente usare Windows ML come componente di sistema condiviso, così l'app rimane piccola e tutte le app nel dispositivo condividono lo stesso runtime aggiornato, anziché ogni app creare la propria copia personalizzata.
- Prestazioni leader di settore — Windows ML offre prestazioni to-the-metal su NPU e GPU, paragonabili a quelle di SDK dedicati come TensorRT per RTX o AI Engine Direct di Qualcomm. I risultati delle prestazioni variano in base alla configurazione hardware e al modello. Vedere Accelerare i modelli di intelligenza artificiale per indicazioni specifiche dell'hardware.
Perché usare Windows ML invece di Microsoft ORT?
Windows ML è la copia supportata da Windows e gestita di ONNX Runtime (ORT), disponibile come copia a livello di sistema o autonoma:
- Stesse API ONNX : nessuna modifica al codice di runtime ONNX esistente
- Supportato e manutenuto da Windows dal team di Windows
- Supporto hardware generale : viene eseguito su PC Windows (x64 e ARM64) e Windows Server con qualsiasi configurazione hardware
- Dimensioni dell'app più piccole facoltative : scegliere la distribuzione dipendente dal framework e condividere il runtime tra le app invece di creare una copia personalizzata
- Aggiornamenti sempre sempreverdi facoltativi : scegliere la distribuzione dipendente dal framework e gli utenti ottengono sempre il runtime più recente tramite Windows Update
Windows ML consente inoltre all'app di acquisire dinamicamente i provider di esecuzione più recenti per accelerare i modelli di intelligenza artificiale, senza portare gli EP nell'app e creare build separate per hardware diverso.
Consulta Introduzione a Windows ML per provare personalmente!
Accelerazione hardware su unità NPU, GPU e CPU
Windows ML consente di accedere ai provider di esecuzione che possono accelerare l'inferenza tra le tre classi di siliconi presenti nei PC Windows moderni:
- NPU — inferenza a basso consumo della batteria sul dispositivo, con le NPU più potenti disponibili nei PC Copilot+
- GPU : carichi di lavoro a velocità effettiva elevata, ad esempio immagini, video e intelligenza artificiale generativa, che in genere fornirà prestazioni massime su GPU discrete
- CPU : fallback universale, più accelerazioni CPU ottimizzate per IHV
Per il mapping completo da silicio a EP, i requisiti dei driver e le opzioni di origine EP, vedere Accelerare i modelli di intelligenza artificiale.
Requisiti di sistema
- OS: versione di Windows supportata da SDK per app di Windows
- Architettura: x64 o ARM64
- Hardware: qualsiasi configurazione pc (CPU, GPU integrate/discrete, NPU)
Annotazioni
Il supporto per CPU e GPU (tramite DirectML) è disponibile in tutte le versioni Windows supportate. I provider di esecuzione ottimizzati per l'hardware per le NPUs e l'hardware specifico delle GPU richiedono Windows 11 versione 24H2 (build 26100) o superiore. Per informazioni dettagliate, vedere Provider di esecuzione di Windows ML.
Ottimizzazione delle prestazioni
La versione più recente di Windows ML funziona direttamente con provider di esecuzione dedicati per GPU e NPU, offrendo prestazioni to-the-metal pari agli SDK dedicati del passato, ad esempio TensorRT per RTX, AI Engine Direct e l'estensione Intel per PyTorch. Windows ML è stato progettato per ottenere prestazioni ottimali per GPU e NPU di classe, senza richiedere all'app di distribuire SDK specifici di IHV. I risultati delle prestazioni variano in base alla configurazione hardware e al modello. Vedere Accelerare i modelli di intelligenza artificiale per indicazioni specifiche dell'hardware.
Conversione di modelli in ONNX
È possibile convertire i modelli da altri formati a ONNX in modo da poterli usare con Windows ML. Per altre informazioni, vedere la documentazione di Foundry Toolkit for Visual Studio Code su come convertire i modelli nel formato ONNX. Per altre informazioni sulla conversione di modelli PyTorch, TensorFlow e Hugging Face in ONNX, vedere anche le esercitazioni sul runtime ONNX .
Distribuzione del modello
Windows ML offre opzioni flessibili per la distribuzione di modelli di intelligenza artificiale:
- Condividere modelli tra app : scaricare e condividere in modo dinamico i modelli tra app da qualsiasi rete CDN senza creare bundle di file di grandi dimensioni
- Modelli locali - Includere i file di modello direttamente nel pacchetto dell'applicazione
Integrazione con Windows ecosistema di intelligenza artificiale
Windows ML funge da base per la piattaforma di intelligenza artificiale Windows più ampia:
- Windows API di intelligenza artificiale - Modelli predefiniti per le attività comuni
- Foundry Local - Modelli di intelligenza artificiale pronti per l'uso
- Modelli personalizzati - Accesso api Windows ML diretto per scenari avanzati
Fornire commenti e suggerimenti
È stato rilevato un problema o si hanno suggerimenti? Cercare o creare problemi nel SDK per app di Windows GitHub.
Passaggi successivi
- Eseguire modelli di intelligenza artificiale - Installare Windows ML ed eseguire il primo modello ONNX
- Accelerare i modelli di intelligenza artificiale - Aggiungere provider di esecuzione NPU, GPU o CPU per un'inferenza più veloce
- Trova o addestra modelli - Trova modelli compatibili con Windows ML
- Informazioni di riferimento API - API di runtime WinRT e ONNX nel pacchetto Microsoft.WindowsAppSDK.ML