Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Nella fase precedente di questa esercitazione è stato acquisito il set di dati che verrà usato per eseguire il training del modello di analisi dei dati con PyTorch. Ora è il momento di utilizzare quei dati.
Per eseguire il training del modello di analisi dei dati con PyTorch, è necessario completare i passaggi seguenti:
- Caricare i dati. Se hai completato il passaggio precedente di questa esercitazione, hai già gestito questo.
- Definire una rete neurale.
- Definire una funzione di perdita.
- Allenare il modello sui dati di addestramento.
- Testare la rete sui dati di test.
Definire una rete neurale
In questa esercitazione si creerà un modello di rete neurale di base con tre livelli lineari. La struttura del modello è la seguente:
Linear -> ReLU -> Linear -> ReLU -> Linear
Un livello lineare applica una trasformazione lineare ai dati in ingresso. È necessario specificare il numero di funzionalità di input e il numero di funzionalità di output che devono corrispondere al numero di classi.
Un livello ReLU è una funzione di attivazione che definisce tutte le caratteristiche in ingresso come 0 o superiore. Pertanto, quando viene applicato un livello ReLU, qualsiasi numero minore di 0 viene modificato in zero, mentre altri vengono mantenuti uguali. Il livello di attivazione verrà applicato ai due livelli nascosti e non verrà eseguita alcuna attivazione sull'ultimo livello lineare.
Parametri del modello
I parametri del modello dipendono dall'obiettivo e dai dati di training. Le dimensioni di input dipendono dal numero di funzionalità che si inserisce nel modello, quattro nel nostro caso. Le dimensioni di output sono tre perché esistono tre tipi possibili di Iris.
La rete, avendo tre livelli lineari, avrà 744 pesi (96+576+72).
La frequenza di apprendimento (lr) definisce come si adattano i pesi della nostra rete rispetto al gradiente di perdita. Più basso è, più lento sarà il training. In questa esercitazione verrà impostato lr su 0.01.
Come funziona la rete?
Qui stiamo costruendo una rete feed-forward. Durante il processo di addestramento, la rete elabora l'input attraverso tutti gli strati, calcola la funzione di perdita per comprendere quanto l'etichetta stimata dell'immagine sia distante da quella corretta e propaga i gradienti nella rete per aggiornare i pesi degli strati. Iterando su un enorme set di dati di input, la rete imparerà a impostare i propri pesi per ottenere i risultati migliori.
Una funzione forward calcola il valore della funzione di perdita e una funzione indietro calcola le sfumature dei parametri appresi. Quando si crea la rete neurale con PyTorch, è sufficiente definire la funzione forward. La funzione all'indietro verrà definita automaticamente.
- Copiare il codice seguente nel
DataClassifier.pyfile in Visual Studio per definire i parametri del modello e la rete neurale.
# Define model parameters
input_size = list(input.shape)[1] # = 4. The input depends on how many features we initially feed the model. In our case, there are 4 features for every predict value
learning_rate = 0.01
output_size = len(labels) # The output is prediction results for three types of Irises.
# Define neural network
class Network(nn.Module):
def __init__(self, input_size, output_size):
super(Network, self).__init__()
self.layer1 = nn.Linear(input_size, 24)
self.layer2 = nn.Linear(24, 24)
self.layer3 = nn.Linear(24, output_size)
def forward(self, x):
x1 = F.relu(self.layer1(x))
x2 = F.relu(self.layer2(x1))
x3 = self.layer3(x2)
return x3
# Instantiate the model
model = Network(input_size, output_size)
Dovrai anche definire il dispositivo di esecuzione in base a quello disponibile nel PC. PyTorch non dispone di una libreria dedicata per GPU, ma è possibile definire manualmente il dispositivo di esecuzione. Il dispositivo sarà una GPU Nvidia, se presente nel computer, altrimenti sarà la CPU.
- Copiare il codice seguente per definire il dispositivo di esecuzione:
# Define your execution device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("The model will be running on", device, "device\n")
model.to(device) # Convert model parameters and buffers to CPU or Cuda
- Come ultimo passaggio, definire una funzione per salvare il modello:
# Function to save the model
def saveModel():
path = "./NetModel.pth"
torch.save(model.state_dict(), path)
Annotazioni
Per altre informazioni sulla rete neurale, vedere PyTorch? Vedere la documentazione di PyTorch.
Definire una funzione di perdita
Una funzione di perdita calcola un valore che stima la distanza dell'output dalla destinazione. L'obiettivo principale è ridurre il valore della funzione di perdita modificando i valori del vettore di peso tramite backpropagation nelle reti neurali.
Il valore della perdita è diverso dall'accuratezza del modello. La funzione di perdita rappresenta il comportamento del modello dopo ogni iterazione di ottimizzazione nel set di training. L'accuratezza del modello viene calcolata sui dati di test e mostra la percentuale di stime corrette.
In PyTorch il pacchetto di rete neurale contiene varie funzioni di perdita che costituiscono i blocchi predefiniti delle reti neurali profonde. Per altre informazioni su queste specifiche, iniziare con la nota precedente. In questo caso si useranno le funzioni esistenti ottimizzate per la classificazione e si utilizzerà una funzione di perdita entropia incrociata e un ottimizzatore Adam. Nell'ottimizzatore, il tasso di apprendimento (lr) stabilisce quanto si stanno regolando i pesi della nostra rete rispetto al gradiente di perdita. Imposterai il valore a 0,001 qui: più sarà basso, più lento sarà l'addestramento.
- Copiare il codice seguente nel
DataClassifier.pyfile in Visual Studio per definire la funzione di perdita e un ottimizzatore.
# Define the loss function with Classification Cross-Entropy loss and an optimizer with Adam optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=0.001, weight_decay=0.0001)
Allenare il modello sui dati di addestramento.
Per addestrare il modello, è necessario iterare sull'iteratore dei dati, inserire gli input nella rete e ottimizzare. Per convalidare i risultati, è sufficiente confrontare le etichette stimate con le etichette effettive nel set di dati di convalida dopo ogni periodo di training.
Il programma visualizzerà la perdita durante l'addestramento, la perdita di convalida e l'accuratezza del modello per ogni epoca o per ogni iterazione completata sul set di addestramento. Salva il modello con la massima precisione e dopo 10 periodi, il programma visualizzerà l'accuratezza finale.
- Aggiungere il codice seguente al
DataClassifier.pyfile
# Training Function
def train(num_epochs):
best_accuracy = 0.0
print("Begin training...")
for epoch in range(1, num_epochs+1):
running_train_loss = 0.0
running_accuracy = 0.0
running_vall_loss = 0.0
total = 0
# Training Loop
for data in train_loader:
#for data in enumerate(train_loader, 0):
inputs, outputs = data # get the input and real species as outputs; data is a list of [inputs, outputs]
optimizer.zero_grad() # zero the parameter gradients
predicted_outputs = model(inputs) # predict output from the model
train_loss = loss_fn(predicted_outputs, outputs) # calculate loss for the predicted output
train_loss.backward() # backpropagate the loss
optimizer.step() # adjust parameters based on the calculated gradients
running_train_loss +=train_loss.item() # track the loss value
# Calculate training loss value
train_loss_value = running_train_loss/len(train_loader)
# Validation Loop
with torch.no_grad():
model.eval()
for data in validate_loader:
inputs, outputs = data
predicted_outputs = model(inputs)
val_loss = loss_fn(predicted_outputs, outputs)
# The label with the highest value will be our prediction
_, predicted = torch.max(predicted_outputs, 1)
running_vall_loss += val_loss.item()
total += outputs.size(0)
running_accuracy += (predicted == outputs).sum().item()
# Calculate validation loss value
val_loss_value = running_vall_loss/len(validate_loader)
# Calculate accuracy as the number of correct predictions in the validation batch divided by the total number of predictions done.
accuracy = (100 * running_accuracy / total)
# Save the model if the accuracy is the best
if accuracy > best_accuracy:
saveModel()
best_accuracy = accuracy
# Print the statistics of the epoch
print('Completed training batch', epoch, 'Training Loss is: %.4f' %train_loss_value, 'Validation Loss is: %.4f' %val_loss_value, 'Accuracy is %d %%' % (accuracy))
Testare il modello sui dati di test.
Dopo aver eseguito il training del modello, è possibile testare il modello con il set di dati di test.
Verranno aggiunte due funzioni di test. Il primo verifica il modello salvato nella parte precedente. Testerà il modello con il set di dati di test di 45 elementi e stamperà l'accuratezza del modello. Il secondo è una funzione facoltativa per testare la fiducia del modello nella stima di ognuna delle tre specie iris, rappresentate dalla probabilità di successo della classificazione di ogni specie.
- Aggiungere il codice seguente al file
DataClassifier.py.
# Function to test the model
def test():
# Load the model that we saved at the end of the training loop
model = Network(input_size, output_size)
path = "NetModel.pth"
model.load_state_dict(torch.load(path))
running_accuracy = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs, outputs = data
outputs = outputs.to(torch.float32)
predicted_outputs = model(inputs)
_, predicted = torch.max(predicted_outputs, 1)
total += outputs.size(0)
running_accuracy += (predicted == outputs).sum().item()
print('Accuracy of the model based on the test set of', test_split ,'inputs is: %d %%' % (100 * running_accuracy / total))
# Optional: Function to test which species were easier to predict
def test_species():
# Load the model that we saved at the end of the training loop
model = Network(input_size, output_size)
path = "NetModel.pth"
model.load_state_dict(torch.load(path))
labels_length = len(labels) # how many labels of Irises we have. = 3 in our database.
labels_correct = list(0. for i in range(labels_length)) # list to calculate correct labels [how many correct setosa, how many correct versicolor, how many correct virginica]
labels_total = list(0. for i in range(labels_length)) # list to keep the total # of labels per type [total setosa, total versicolor, total virginica]
with torch.no_grad():
for data in test_loader:
inputs, outputs = data
predicted_outputs = model(inputs)
_, predicted = torch.max(predicted_outputs, 1)
label_correct_running = (predicted == outputs).squeeze()
label = outputs[0]
if label_correct_running.item():
labels_correct[label] += 1
labels_total[label] += 1
label_list = list(labels.keys())
for i in range(output_size):
print('Accuracy to predict %5s : %2d %%' % (label_list[i], 100 * labels_correct[i] / labels_total[i]))
Aggiungere infine il codice principale. Verrà avviato il training del modello, salvato il modello e verranno visualizzati i risultati sullo schermo. Verranno eseguite solo due iterazioni [num_epochs = 25] sul set di training, quindi il processo di training non richiederà troppo tempo.
- Aggiungere il codice seguente al file
DataClassifier.py.
if __name__ == "__main__":
num_epochs = 10
train(num_epochs)
print('Finished Training\n')
test()
test_species()
Eseguiamo il test. Assicurarsi che i menu a discesa nella barra degli strumenti superiore siano impostati su Debug. Modifica Solution Platform in x64 per eseguire il progetto sul computer locale se il dispositivo è a 64-bit o in x86 se è a 32-bit.
- Per eseguire il progetto, fare clic sul
Start Debuggingpulsante sulla barra degli strumenti oppure premereF5.
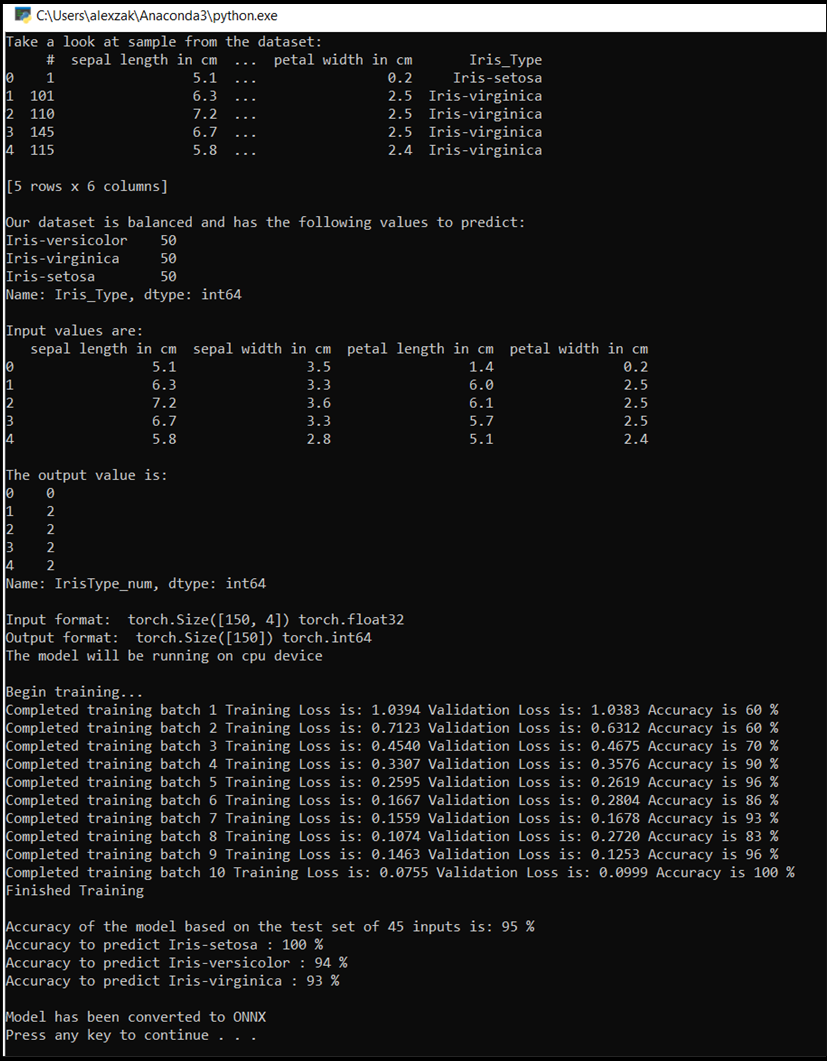
Quando la finestra della console apparirà, vedrai il processo di allenamento. Come definito, il valore della perdita verrà stampato ogni epoca. L'aspettativa è che il valore di perdita diminuisce con ogni ciclo.
Al termine del training, si dovrebbe prevedere di visualizzare l'output simile al seguente. I tuoi numeri non saranno esattamente gli stessi: l'allenamento dipende da molti fattori e non restituirà sempre risultati identici, ma dovrebbero sembrare simili.
Passaggi successivi
Ora che è disponibile un modello di classificazione, il passaggio successivo consiste nel convertire il modello nel formato ONNX.