Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
WinMLRunner è uno strumento per verificare se un modello viene eseguito correttamente quando viene valutato con le API di Windows ML. È anche possibile acquisire tempo di valutazione e utilizzo della memoria nella GPU e/o nella CPU. I modelli in formato .onnx o pb possono essere valutati in cui le variabili di input e output sono tensori o immagini. Esistono due modi per usare WinMLRunner:
- Scaricare lo strumento Python da riga di comando.
- Usare all'interno del dashboard WinML. Per altre informazioni, vedere la documentazione del dashboard WinML
Eseguire un modello
Aprire prima di tutto lo strumento Python scaricato. Passare alla cartella contenente WinMLRunner.exeed eseguire il file eseguibile come illustrato di seguito. Assicurati di sostituire il percorso di installazione con quello che corrisponde al tuo:
.\WinMLRunner.exe -model SqueezeNet.onnx
È anche possibile eseguire una cartella di modelli con un comando come il seguente.
WinMLRunner.exe -folder c:\data -perf -iterations 3 -CPU`\
Esecuzione di un modello valido
Di seguito è riportato un esempio di esecuzione corretta di un modello. Si noti che prima il modello carica e restituisce i metadati del modello. Il modello viene quindi eseguito separatamente sulla CPU e sulla GPU, visualizzando l'esito positivo dell'associazione, l'esito positivo della valutazione e l'output del modello.
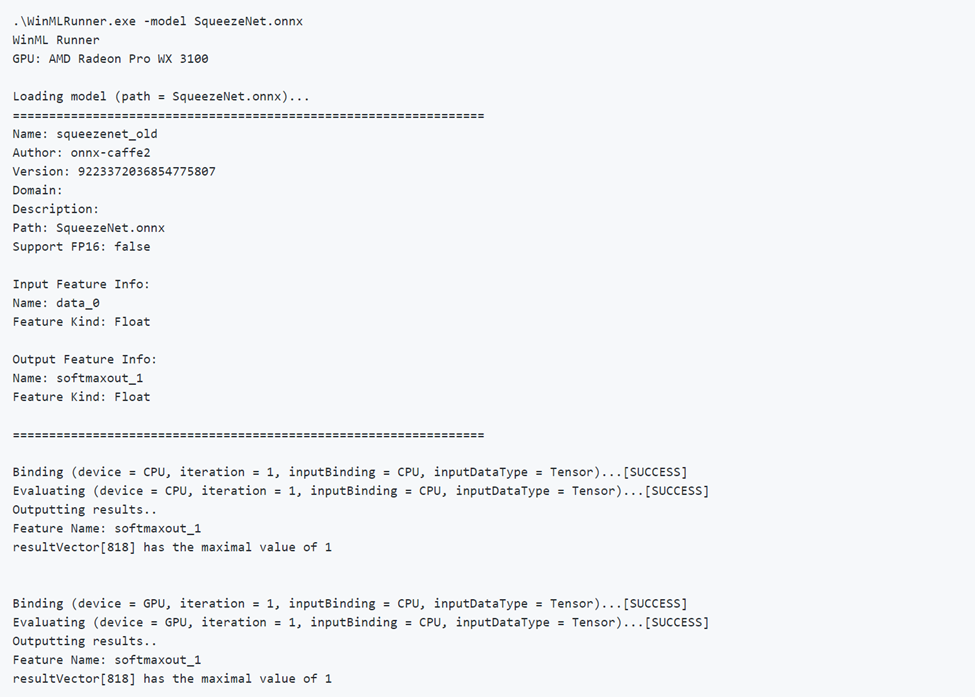
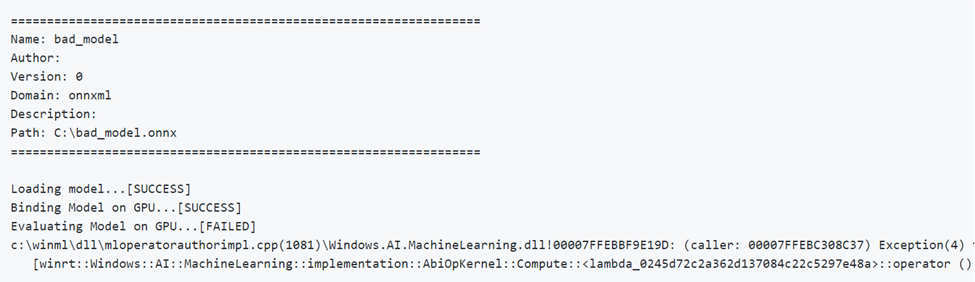
Esecuzione di un modello non valido
Di seguito è riportato un esempio di esecuzione di un modello con parametri non corretti. Si noti l'output FAILED durante la valutazione nella GPU.
Selezione e ottimizzazione dei dispositivi
Per impostazione predefinita, il modello viene eseguito separatamente nella CPU e nella GPU, ma è possibile specificare un dispositivo con un flag -CPU o -GPU. Di seguito è riportato un esempio di esecuzione di un modello 3 volte usando solo la CPU:
WinMLRunner.exe -model c:\data\concat.onnx -iterations 3 -CPU
Dati sulle prestazioni dei log
Usare il flag -perf per acquisire i dati sulle prestazioni. Di seguito è riportato un esempio di esecuzione di tutti i modelli nella cartella dei dati nella CPU e nella GPU separatamente 3 volte e l'acquisizione dei dati sulle prestazioni:
WinMLRunner.exe -folder c:\data iterations 3 -perf
Misurazioni delle prestazioni
Le misurazioni delle prestazioni seguenti verranno restituite nella riga di comando e .csv file per ogni operazione di caricamento, associazione e valutazione:
- Tempo in tempo reale (ms): tempo reale trascorso tra l'inizio e la fine di un'operazione.
- Tempo GPU (ms): tempo per il passaggio di un'operazione dalla CPU alla GPU ed esecuzione sulla GPU (nota: Load() non viene eseguito sulla GPU.
- Tempo CPU (ms): tempo per l'esecuzione di un'operazione sulla CPU.
- Utilizzo memoria dedicata e condivisa (MB): Utilizzo medio della memoria a livello di utente e kernel (in MB) durante la valutazione della CPU o della GPU.
- Working Set Memory (MB): Quantità di memoria DRAM richiesta dal processo sulla CPU durante la valutazione. Memoria dedicata (MB): quantità di memoria usata nella VRAM della GPU dedicata.
- Memoria condivisa (MB): Quantità di memoria usata nella DRAM dalla GPU.
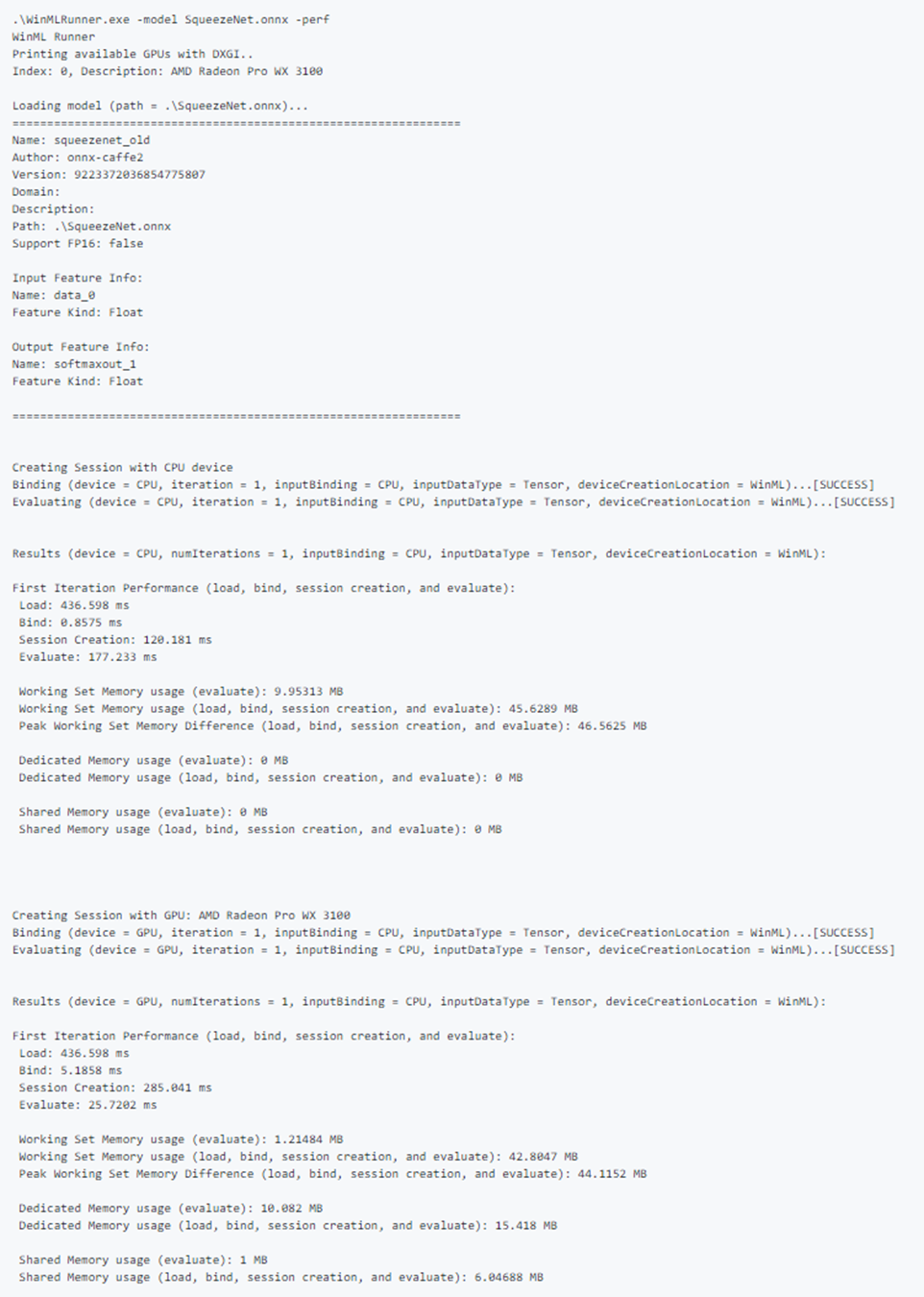
Output delle prestazioni di esempio:
Input di esempio di test
Eseguire un modello nella CPU e nella GPU separatamente e associando l'input alla CPU e alla GPU separatamente (4 esecuzioni totali):
WinMLRunner.exe -model c:\data\SqueezeNet.onnx -CPU -GPU -CPUBoundInput -GPUBoundInput
Eseguire un modello sulla CPU con l'input associato alla GPU e caricato come immagine RGB:
WinMLRunner.exe -model c:\data\SqueezeNet.onnx -CPU -GPUBoundInput -RGB
Acquisizione dei log di traccia
Se si vogliono acquisire i log di traccia usando lo strumento, è possibile usare i comandi logman insieme all'opzione di debug.
logman start winml -ets -o winmllog.etl -nb 128 640 -bs 128logman update trace winml -p {BCAD6AEE-C08D-4F66-828C-4C43461A033D} 0xffffffffffffffff 0xff -ets WinMLRunner.exe -model C:\Repos\Windows-Machine-Learning\SharedContent\models\SqueezeNet.onnx -debuglogman stop winml -ets
Il file winmllog.etl verrà visualizzato nella stessa directory del WinMLRunner.exe.
Lettura dei log di monitoraggio
Usando il traceprt.exe, eseguire il comando seguente dalla riga di comando.
tracerpt.exe winmllog.etl -o logdump.csv -of CSV
Aprire quindi il logdump.csv file.
In alternativa, è possibile usare Windows Performance Analyzer (da Visual Studio). Avviare Windows Performance Analyzer e aprire winmllog.etl.
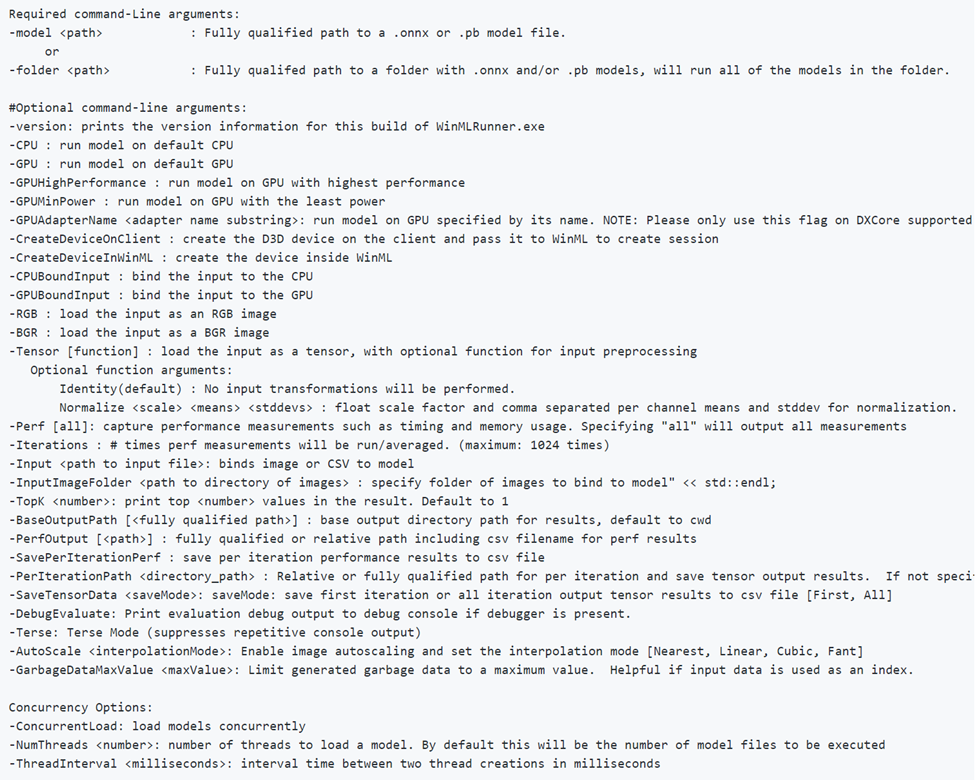
Si noti che -CPU, -GPU, -GPUHighPerformance, -GPUMinPower -BGR, -RGB, -tensor, -CPUBoundInput, -GPUBoundInput non si escludono a vicenda (ad esempio, è possibile combinare il numero di istanze desiderate per eseguire il modello con configurazioni diverse).
Caricamento di dll dinamiche
Se vuoi eseguire WinMLRunner con un'altra versione di WinML (ad esempio, confrontando le prestazioni con una versione precedente o testando una versione più recente), posiziona semplicemente i file windows.ai.machinelearning.dll e directml.dll nella stessa cartella di WinMLRunner.exe. WinMLRunner cercherà prima queste DLL ed eseguirà il fallback a C:/Windows/System32 se non le trova.
Problemi noti
- Gli input sequenza/mappa non sono ancora supportati (il modello viene semplicemente ignorato, quindi non blocca altri modelli in una cartella);
- Non è possibile eseguire in modo affidabile più modelli con l'argomento -folder con dati reali. Poiché è possibile specificare solo 1 input, le dimensioni dell'input non corrispondono alla maggior parte dei modelli. Attualmente, l'uso dell'argomento -folder funziona correttamente solo con i dati di Garbage;
- La generazione di input garbage come Gray o YUV non è attualmente supportata. Idealmente, la pipeline di dati di Garbage Data di WinMLRunner deve supportare tutti i tipi di input che è possibile assegnare a winml.