Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Integrare il riconoscimento vocale e la sintesi vocale (nota anche come TTS o sintesi vocale) direttamente nell'esperienza utente dell'app.
Riconoscimento vocale Il riconoscimento vocale converte le parole pronunciate dall'utente in testo per l'input del modulo, per la dettatura del testo, per specificare un'azione o un comando e per eseguire attività. Supporta sia le grammatiche predefinite per la dettatura di testo libero che per la ricerca Web e le grammatiche personalizzate create con Speech Recognition Grammar Specification (SRGS) versione 1.0.
Speech synthesis/Text to Speech (TTS) TTS usa un motore di sintesi vocale (voce) per convertire una stringa di testo in parole pronunciate. La stringa di input può essere un testo semplice, non elaborato o un più complesso Speech Synthesis Markup Language (SSML). SSML offre un modo standard per controllare le caratteristiche dell'output vocale, come pronuncia, volume, intonazione, ritmo o velocità ed enfasi.
Progettazione dell'interazione vocale
Quando si progetta e implementa il parlato in modo ponderato, può essere un modo efficace, accessibile e naturale per consentire alle persone di interagire con le applicazioni Windows, integrare o persino sostituire esperienze di interazione tradizionali basate su mouse, tastiera, controller o tocco.
Queste linee guida e consigli descrivono come integrare al meglio sia il riconoscimento vocale che il TTS nell'esperienza di interazione dell'app.
Se stai valutando il supporto delle interazioni vocali nella tua app, fai da te le domande seguenti:
- Quali azioni possono essere eseguite dagli utenti tramite il riconoscimento vocale? Possono spostarsi tra pagine, richiamare comandi o immettere dati come campi di testo, brevi note o messaggi lunghi?
- L'input vocale è un'opzione valida per completare un'attività?
- In che modo un utente sa quando è disponibile l'input vocale?
- L'app è sempre in ascolto o l'utente deve eseguire un'azione affinché l'app entri in modalità di ascolto?
- Quali frasi avviano un'azione o un comportamento? Le frasi e le azioni devono essere enumerate sullo schermo?
- Sono necessarie schermate di richiesta, conferma e disambiguazione o TTS?
- Qual è la finestra di dialogo di interazione tra app e utente?
- È necessario un vocabolario personalizzato o vincolato (ad esempio medicina, scienza o impostazioni locali) per il contesto dell'app?
- La connettività di rete è necessaria?
Input di testo
L'input di testo può variare dall'input di forma breve, ad esempio una singola parola o frase, a un input di modulo lungo, ad esempio più frasi, paragrafi o dettatura continua. L'input in formato breve è in genere inferiore a 10 secondi, mentre le sessioni di input in formato lungo possono durare fino a due minuti. L'input di tipo esteso può riavviarsi senza l'intervento dell'utente per dare l'impressione di una dettatura continua.
Fornire un segnale visivo per indicare che il riconoscimento vocale è supportato e disponibile per l'utente e se l'utente deve attivarlo. Ad esempio, usare un pulsante della barra dei comandi con un glifo del microfono (vedere Barre dei comandi) per visualizzare sia la disponibilità che lo stato.
Fornire feedback di riconoscimento continuo per ridurre al minimo qualsiasi apparente mancanza di risposta durante l'esecuzione del riconoscimento.
Consentire agli utenti di rivedere il testo di riconoscimento usando input da tastiera, richieste di ambiguità, suggerimenti o riconoscimento vocale aggiuntivo.
Arrestare il riconoscimento se l'input viene rilevato da un dispositivo diverso dal riconoscimento vocale, ad esempio tocco o tastiera. Questo input indica probabilmente che l'utente è passato a un'altra attività, ad esempio la correzione del testo di riconoscimento o l'interazione con altri campi modulo.
Specificare l'intervallo di tempo per il quale nessun input vocale indica che il riconoscimento è finito. Non riavviare automaticamente il riconoscimento dopo questo periodo di tempo, perché in genere indica che l'utente ha smesso di interagire con l'app.
In alcuni casi, potrebbe essere necessaria una connessione di rete per supportare il riconoscimento vocale. Se non è disponibile, disabilitare tutta l'interfaccia utente di riconoscimento continuo e terminare la sessione di riconoscimento.
Esecuzione di comandi
L'input vocale può avviare azioni, richiamare i comandi ed eseguire attività.
Se lo spazio è consentito, è consigliabile visualizzare le risposte supportate per il contesto dell'app corrente, con esempi di input valido. Questo approccio riduce le potenziali risposte che l'app deve elaborare ed elimina anche confusione per l'utente.
Provare a incorniciare le domande per ottenere una risposta più specifica possibile. Ad esempio, "Cosa si vuole fare oggi?" è molto aperto e richiede una definizione grammaticale molto grande a causa della varietà delle risposte. In alternativa, "Vuoi giocare o ascoltare musica?" vincola la risposta a una delle due risposte valide con una definizione grammaticale corrispondentemente piccola. Una piccola grammatica è molto più facile da creare e comporta risultati di riconoscimento molto più accurati.
Richiedere conferma all'utente quando l'attendibilità del riconoscimento vocale è bassa. Se la finalità dell'utente non è chiara, è preferibile ottenere chiarimenti rispetto all'avvio di un'azione imprevista.
Fornire un segnale visivo per indicare che il riconoscimento vocale è supportato e disponibile per l'utente e se l'utente deve attivarlo. Ad esempio, usare un pulsante della barra dei comandi con un glifo del microfono (vedere Linee guida per le barre dei comandi) per visualizzare sia la disponibilità che lo stato.
Se l'opzione di riconoscimento vocale è in genere fuori visualizzazione, valutare la possibilità di visualizzare un indicatore di stato nell'area del contenuto dell'app.
Se l'utente avvia il riconoscimento, è consigliabile usare l'esperienza di riconoscimento predefinita per la coerenza. L'esperienza predefinita include schermate personalizzabili con prompt, esempi, ambiguità, conferme ed errori.
Le schermate variano a seconda dei vincoli specificati:
Grammatica predefinita (dettatura o ricerca Web)
- Schermata Di ascolto.
- Schermata di Pensiero.
- Schermata di riconoscimento vocale o schermata di errore.
Elenco di parole o frasi o file di grammatica SRGS
- Schermata Di ascolto.
- Schermata Hai detto, se quanto detto dall'utente può essere interpretato in più modi.
- Schermata di riconoscimento vocale o schermata di errore.
Nella schermata Ascolto è possibile:
- Personalizzare il testo dell'intestazione.
- Specificare un testo di esempio di ciò che l'utente può pronunciare.
- Specificare se viene visualizzata la schermata "Ti ho sentito dire".
- Leggere di nuovo la stringa riconosciuta all'utente nella schermata Heard you say.
Le immagini seguenti illustrano un esempio del flusso di riconoscimento predefinito per un riconoscimento vocale che usa un vincolo definito da SRGS. In questo esempio il riconoscimento vocale ha esito positivo.
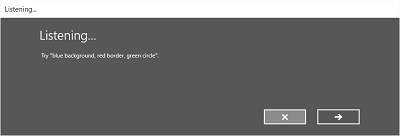
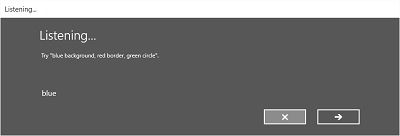
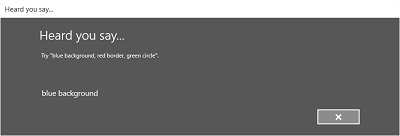
Sempre in ascolto
L'app può ascoltare e riconoscere l'input vocale non appena l'app viene avviata, senza l'intervento dell'utente.
Personalizzare i vincoli grammaticali in base al contesto dell'app. Questo approccio mantiene l'esperienza di riconoscimento vocale molto mirata e rilevante per l'attività corrente e riduce al minimo gli errori.
"Cosa posso dire?"
Quando si abilita l'input vocale, aiutare gli utenti a scoprire cosa l'app può comprendere e quali azioni può eseguire.
Se gli utenti abilitano il riconoscimento vocale, è consigliabile usare la barra dei comandi o un comando di menu per visualizzare tutte le parole e le frasi supportate nel contesto corrente.
Se il riconoscimento vocale è sempre attivo, è consigliabile aggiungere la frase "Cosa posso dire?" a ogni pagina. Quando l'utente dice questa frase, visualizzare tutte le parole e le frasi supportate nel contesto corrente. L'uso di questa frase offre agli utenti un modo coerente per individuare le funzionalità vocali nel sistema.
Errori di riconoscimento
Il riconoscimento vocale può non riuscire. Gli errori si verificano quando la qualità audio è scarsa, quando il riconoscitore rileva solo parte di una frase o quando il riconoscitore non rileva alcun input.
Gestire correttamente l'errore, aiutare l'utente a capire perché il riconoscimento non è riuscito e il ripristino.
L'app dovrebbe informare l'utente che il riconoscitore non li ha riconosciuti e che deve riprovare.
Valutare la possibilità di fornire esempi di una o più frasi supportate. È probabile che l'utente ripeta una frase suggerita, che aumenta il successo del riconoscimento.
Visualizzare un elenco di potenziali corrispondenze tra cui l'utente può scegliere. Questo approccio può essere molto più efficiente rispetto al processo di riconoscimento.
Supporta sempre tipi di input alternativi, particolarmente utili per la gestione degli errori di riconoscimento ripetuti. Ad esempio, è possibile suggerire all'utente di provare a usare una tastiera o usare il tocco o un mouse per selezionare da un elenco di potenziali corrispondenze.
Usare l'esperienza di riconoscimento vocale predefinita perché include schermate che informano l'utente che il riconoscimento non è riuscito e consente all'utente di eseguire un altro tentativo di riconoscimento.
Ascolta e cerca di risolvere i problemi nell'input audio. Il riconoscimento vocale può rilevare problemi con la qualità audio che potrebbero influire negativamente sull'accuratezza del riconoscimento vocale. È possibile usare le informazioni fornite dal riconoscimento vocale per informare l'utente del problema e consentire loro di intraprendere azioni correttive, se possibile. Ad esempio, se l'impostazione del volume sul microfono è troppo bassa, è possibile chiedere all'utente di parlare più forte o attivare il volume.
Vincoli
I vincoli o le grammatiche definiscono le parole pronunciate e le frasi che il riconoscimento vocale può corrispondere. È possibile specificare una delle grammatiche predefinite del servizio Web oppure creare una grammatica personalizzata installata con l'app.
Grammatiche predefinite
Le grammatiche di dettatura e ricerca Web predefinite forniscono il riconoscimento vocale per l'app senza che sia necessario creare una grammatica. Quando si usano queste grammatiche, un servizio Web remoto esegue il riconoscimento vocale e restituisce i risultati al dispositivo.
- La grammatica di dettatura a testo libero predefinita riconosce la maggior parte delle parole e delle frasi che un utente può pronunciare in una determinata lingua. È ottimizzato per riconoscere frasi brevi. Usare la dettatura senza testo quando non si vuole limitare i tipi di elementi che un utente può dire. Gli usi tipici includono la creazione di note o la dettatura del contenuto per un messaggio.
- La grammatica di ricerca Web, ad esempio una grammatica di dettatura, contiene un numero elevato di parole e frasi che un utente potrebbe pronunciare. Tuttavia, è ottimizzato per riconoscere i termini che le persone usano in genere durante la ricerca nel Web.
Annotazioni
Poiché le grammatiche di dettatura e ricerca Web predefinite possono essere di grandi dimensioni e perché sono online (non nel dispositivo), le prestazioni potrebbero non essere veloci quanto con una grammatica personalizzata installata nel dispositivo.
Queste grammatiche predefinite possono riconoscere fino a 10 secondi di input vocale e non richiedono alcuna operazione di creazione. Tuttavia, richiedono la connessione a una rete.
Grammatiche personalizzate
Progettare e creare una grammatica personalizzata e installarla con l'app. Il dispositivo esegue il riconoscimento vocale usando un vincolo personalizzato.
I vincoli elenco a livello di codice offrono un approccio leggero alla creazione di grammatiche semplici usando un elenco di parole o frasi. Un vincolo di elenco funziona bene per il riconoscimento di frasi brevi e distinte. Specificare esplicitamente tutte le parole in una grammatica migliora anche l'accuratezza del riconoscimento, poiché il motore di riconoscimento vocale deve elaborare solo il riconoscimento vocale per confermare una corrispondenza. È anche possibile aggiornare l'elenco a livello di codice.
Una grammatica SRGS è un documento statico che, a differenza di un vincolo elenco programmatico, usa il formato XML definito dalla versione 1.0 di SRGS. Una grammatica SRGS offre il massimo controllo sull'esperienza di riconoscimento vocale consentendo di acquisire più significati semantici in un singolo riconoscimento.
Ecco alcuni suggerimenti per la creazione di grammatiche SRGS:
- Mantenere ogni grammatica piccola. Le grammatiche che contengono meno frasi tendono a fornire un riconoscimento più accurato rispetto alle grammatiche più grandi che contengono molte frasi. È preferibile avere diverse grammatiche più piccole per scenari specifici rispetto a una singola grammatica per l'intera app.
- Informare gli utenti di cosa dire per ogni contesto dell'app e abilitare e disabilitare le grammatiche in base alle esigenze.
- Progettare ogni grammatica in modo che gli utenti possano parlare un comando in diversi modi. Ad esempio, usare la regola GARBAGE per trovare la corrispondenza con l'input vocale che la grammatica non definisce. Questa regola consente agli utenti di pronunciare parole aggiuntive che non hanno alcun significato per l'app. Ad esempio, "dammi", "e", "ehm", "forse" e così via.
- Usare l'elemento sapi:subset per trovare una corrispondenza con l'input vocale. Questo elemento è un'estensione Microsoft per la specifica SRGS che consente di trovare una corrispondenza con frasi parziali.
- Provare a evitare di definire frasi nella grammatica che contengono solo una sillaba. Il riconoscimento tende ad essere più accurato per le frasi contenenti due o più sillabe.
- Evitare di usare frasi simili. Ad esempio, frasi come "hello", "bellow" e "fellow" possono confondere il motore di riconoscimento e causare una scarsa accuratezza del riconoscimento.
Annotazioni
Il tipo di vincolo usato dipende dalla complessità dell'esperienza di riconoscimento che si vuole creare. Qualsiasi tipo può essere la scelta migliore per un'attività di riconoscimento specifica e potresti trovare usi per tutti i tipi di vincoli nella tua app.
Pronunce personalizzate
Se la tua app contiene un vocabolario specializzato con parole insolite o fittizie o parole con pronunce non comuni, potresti essere in grado di migliorare le prestazioni di riconoscimento per tali parole definendo pronunce personalizzate.
Per un piccolo elenco di parole e frasi o un elenco di parole e frasi usate raramente, creare pronunce personalizzate in una grammatica SRGS. Per altre informazioni, vedi Elemento token .
Per elenchi più grandi di parole e frasi o parole e frasi usate di frequente, creare documenti di lessico di pronuncia separati. Per altre informazioni, vedi Informazioni sui lessici e alfabeti fonetici .
Testing
Testare l'accuratezza del riconoscimento vocale e qualsiasi interfaccia utente di supporto con il gruppo di destinatari dell'app. Questo approccio consente di determinare l'efficacia dell'esperienza di interazione vocale nell'app. Ad esempio, gli utenti ottengono risultati di riconoscimento scarsi perché l'app non è in ascolto di una frase comune?
Modificare la grammatica per supportare questa frase o fornire agli utenti un elenco di frasi supportate. Se si specifica già l'elenco delle frasi supportate, assicurarsi che gli utenti possano trovarlo facilmente.
Sintesi vocale (TTS)
TTS genera l'output vocale da testo normale o SSML.
Cercate di progettare prompt che sono educati e incoraggianti.
Valutare se è necessario leggere stringhe lunghe di testo. È una cosa ascoltare un sms, ma piuttosto un altro per ascoltare un lungo elenco di risultati della ricerca difficili da ricordare.
Fornire controlli multimediali per consentire agli utenti di sospendere o arrestare TTS.
Ascolta tutte le stringhe TTS per assicurarti che esse siano comprensibili e suonino naturali.
- Concatenare una sequenza insolita di parole, numeri di parte, pronunce o punteggiatura può rendere una frase inintelligibile.
- Il parlato può sembrare innaturale quando la prosodia o la cadenza è diversa da come un parlante nativo direbbe una frase.
È possibile risolvere entrambi i problemi usando SSML anziché testo normale come input per il sintetizzatore vocale. Per ulteriori informazioni su SSML, vedi Usare SSML per controllare la sintesi vocale e il riferimento al Linguaggio di Marcatura per Sintesi Vocale.