Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Nell'argomento precedente (Come vengono trovate e scelte le risorse dal Sistema gestione risorse) è stata esaminata la corrispondenza dei qualificatori in generale. Questo argomento si focalizza sulla corrispondenza dei tag di lingua in modo più dettagliato.
Introduzione
Le risorse con qualificatori di tag di lingua vengono confrontate e con punteggi in base all'elenco di lingue di runtime dell'app. Per le definizioni dei diversi elenchi di lingue, vedere Informazioni sulle lingue del profilo utente e sulle lingue del manifesto dell'app. La corrispondenza per la prima lingua in un elenco si verifica prima della corrispondenza della seconda lingua in un elenco, anche per altre varianti regionali. Ad esempio, una risorsa per en-GB viene scelta su una risorsa fr-CA se il linguaggio di runtime dell'app è en-US. Solo se non sono presenti risorse per una forma di en è una risorsa per fr-CA scelta (si noti che la lingua predefinita dell'app non può essere impostata su nessuna forma di en in questo caso).
Il meccanismo di assegnazione dei punteggi usa i dati inclusi nel registro dei sottotag BCP-47 e in altre origini dati. Consente una sfumatura di punteggio con qualità diverse di corrispondenza e, quando sono disponibili più candidati, seleziona il candidato con il punteggio di corrispondenza migliore.
È quindi possibile contrassegnare il contenuto della lingua in termini generici, ma è comunque possibile specificare contenuto specifico quando necessario. Ad esempio, l'app potrebbe avere molte stringhe inglesi comuni sia alla Stati Uniti, alla Gran Bretagna che ad altre aree. L'assegnazione di tag a queste stringhe come "en" (inglese) consente di risparmiare spazio e sovraccarico di localizzazione. Quando è necessario fare delle distinzioni, ad esempio in una stringa contenente la parola "color/color", le versioni Stati Uniti e britanniche possono essere contrassegnate separatamente usando entrambi i sottotag di lingua e area geografica, rispettivamente come "en-US" e "en-GB".
Tag di lingua
Le lingue vengono identificate usando tag di lingua BCP-47 normalizzati e ben formati. I componenti del sottotag sono definiti nel registro dei sottotag BCP-47. La struttura normale per un tag di lingua BCP-47 è costituita da uno o più degli elementi del sottotag seguenti.
- Sottotag lingua (obbligatorio).
- Sottotag script (che può essere dedotto usando l'impostazione predefinita specificata nel Registro di sistema dei sottotag).
- Sottotag area (facoltativo).
- Sottotag variant (facoltativo).
Potrebbero essere presenti altri elementi del sottotag, ma avranno un effetto trascurabile sulla corrispondenza della lingua. Non sono definiti intervalli di linguaggio usando il carattere jolly (""), ad esempio "en-".
Corrispondenza di due lingue
Ogni volta che Windows confronta due lingue, viene in genere eseguita all'interno del contesto di un processo più ampio. Può essere nel contesto della valutazione di più lingue, ad esempio quando Windows genera l'elenco di lingue dell'applicazione (vedere Informazioni sulle lingue del profilo utente e sulle lingue del manifesto dell'app). Windows esegue questa operazione associando più lingue dalle preferenze utente alle lingue specificate nel manifesto dell'app. Il confronto potrebbe anche essere nel contesto della valutazione della lingua insieme ad altri qualificatori per una determinata risorsa. Un esempio è quando Windows risolve una particolare risorsa file in un particolare contesto di risorse; con la posizione iniziale dell'utente o la scala corrente o dpi del dispositivo come altri fattori (oltre alla lingua) che vengono inseriti nella selezione delle risorse.
Quando vengono confrontati due tag di lingua, al confronto viene assegnato un punteggio in base alla prossimità della corrispondenza.
| Corrispondenza | Punteggio | Esempio |
|---|---|---|
| Corrispondenza esatta | Il più alto | en-AU : en-AU |
| Corrispondenza variante (lingua, script, area, variante) | en-AU-variant1 : en-AU-variant1-t-ja | |
| Corrispondenza dell'area (lingua, script, area) | en-AU : en-AU-variant1 | |
| Corrispondenza parziale (linguaggio, script) | ||
| - Corrispondenza dell'area macro | en-AU : en-053 | |
| - Corrispondenza indipendente dall'area geografica | en-AU : en | |
| - Corrispondenza di affinità ortografica (supporto limitato) | en-AU : en-GB | |
| - Corrispondenza dell'area preferita | en-AU : en-US | |
| - Qualsiasi corrispondenza tra le regioni | en-AU : en-CA | |
| Lingua non determinata (qualsiasi corrispondenza di lingua) | en-AU : und | |
| Nessuna corrispondenza (mancata corrispondenza dello script o mancata corrispondenza del tag di lingua principale) | Più basso | en-AU : fr-FR |
Corrispondenza esatta
I tag sono esattamente uguali (tutti gli elementi del sottotag corrispondono). Un confronto può essere promosso a questo tipo di corrispondenza da una corrispondenza variante o area. Ad esempio, en-US corrisponde a en-US.
Corrispondenza variante
I tag corrispondono ai sottotag di lingua, script, area e variante, ma differiscono in altri termini.
Corrispondenza dell'area geografica
I tag corrispondono ai sottotag di lingua, script e area, ma differiscono in altri termini. Ad esempio, de-DE-1996 corrisponde a de-DE e en-US-x-Pirate corrisponde a en-US.
Corrispondenze parziali
I tag corrispondono nei sottotag della lingua e dello script, ma differiscono nella regione o in qualche altro sottotag. Ad esempio, en-US corrisponde a en o en-US corrisponde a en-*.
Corrispondenza dell'area macro
I tag corrispondono ai sottotag di lingua e script; entrambi i tag hanno sottotag di area, uno dei quali indica un'area macro che include l'altra area. I sottotag di area macro sono sempre numerici e derivano dai codici paese e area geografica della Divisione delle Statistiche delle Nazioni Unite M.49. Per informazioni dettagliate sull'ambito delle relazioni, vedere Composizione di aree geografiche macro (continentali), sotto-regioni geografiche e gruppi economici selezionati.
Nota I codici ONU per "raggruppamenti economici" o "altri raggruppamenti" non sono supportati in BCP-47.
Nota Un tag con il sottotag macro-region "001" è considerato equivalente a un tag indipendente dall'area. Ad esempio, "es-001" e "es" vengono considerati come sinonimi.
Corrispondenza indipendente dall'area geografica
I tag corrispondono ai sottotag di lingua e script e un solo tag ha un tag di area. Una corrispondenza padre è preferibile rispetto ad altre corrispondenze parziali.
Corrispondenza di affinità ortografica
I tag corrispondono ai sottotag di lingua e script e i sottotag di area hanno affinità ortografica. L'affinità si basa sui dati gestiti in Windows che definiscono aree associate specifiche della lingua, ad esempio "en-IE" e "en-GB".
Corrispondenza dell'area preferita
I tag corrispondono ai sottotag di lingua e script e uno dei sottotag di area è il sottotag di area predefinito per la lingua. Ad esempio, "fr-FR" è l'area predefinita per il sottotag "fr". Fr-FR è quindi una corrispondenza migliore per fr-BE rispetto a fr-CA. Ciò si basa sui dati gestiti in Windows che definiscono un'area predefinita per ogni lingua in cui Windows viene localizzato.
Corrispondenza di pari livello
I tag corrispondono ai sottotag di linguaggio e script e hanno entrambi sottotag di area, ma non vengono definite altre relazioni tra di esse. In caso di più corrispondenze di pari livello, l'ultimo elemento di pari livello enumerato sarà il vincitore, in assenza di una corrispondenza più alta.
Lingua non determinata
Una risorsa può essere contrassegnata come "und" per indicare che corrisponde a qualsiasi lingua. Questo tag può essere usato anche con un tag script per filtrare le corrispondenze in base allo script. Ad esempio, "und-Latn" corrisponderà a qualsiasi tag di lingua che usa lo script latino. Per ulteriori dettagli, vedi la sezione seguente.
Mancata corrispondenza dello script
Quando i tag corrispondono solo al tag di lingua primaria ma non allo script, la coppia viene considerata non corrispondente e viene contrassegnata al di sotto del livello di una corrispondenza valida.
Nessuna corrispondenza.
I sottotag della lingua primaria non corrispondenti vengono segnati al di sotto del livello di una corrispondenza valida. Ad esempio, zh-Hant non corrisponde a zh-Hans.
Esempi
Una lingua utente "zh-Hans-CN" (Cinese semplificato (Cina)) corrisponde alle risorse seguenti nell'ordine di priorità indicato. Una X indica che non esiste alcuna corrispondenza.
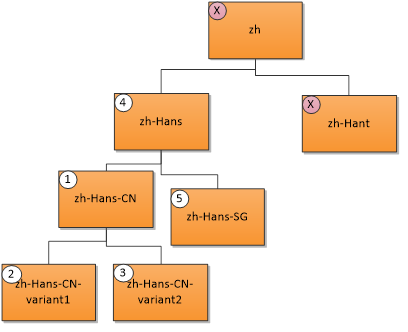
- Corrispondenza esatta; 2. & 3. Corrispondenza dell'area geografica; 4. Corrispondenza padre; 5. Corrispondenza di pari livello.
Quando un sottotag di linguaggio ha un valore Suppress-Script definito nel Registro di sistema dei sottotag BCP-47, viene eseguita la corrispondenza corrispondente, prendendo il valore del codice script eliminato. Ad esempio, en-Latn-US corrisponde a en-US. In questo esempio successivo la lingua utente è "en-AU" (inglese (Australia)).
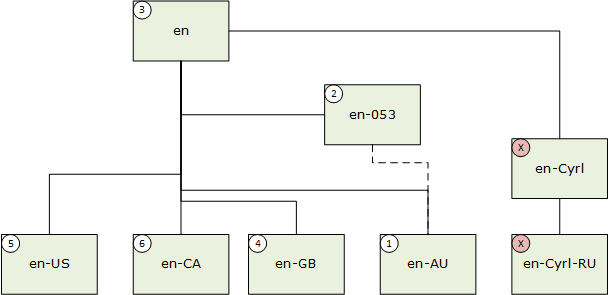
- Corrispondenza esatta; 2. Corrispondenza dell'area macro; 3. Corrispondenza indipendente dall'area geografica; 4. Corrispondenza di affinità ortografica; 5. Corrispondenza dell'area preferita; 6. Corrispondenza di pari livello.
Corrispondenza di una lingua a un elenco di lingue
A volte, la corrispondenza viene eseguita come parte di un processo più grande di corrispondenza di una singola lingua a un elenco di lingue. Ad esempio, potrebbe esserci una corrispondenza di una singola risorsa basata sulla lingua all'elenco di lingue di un'app. Il punteggio della corrispondenza viene ponderato in base alla posizione della prima lingua corrispondente nell'elenco. Minore è la lingua nell'elenco, più basso sarà il punteggio.
Quando l'elenco di lingue contiene due o più varianti regionali con lo stesso sottotag di lingua e script, i confronti per il primo tag di lingua vengono assegnati solo per corrispondenze esatte, varianti e aree geografiche. Le partite parziali di assegnazione dei punteggi vengono posticipate all'ultima variante regionale. In questo modo gli utenti possono controllare correttamente il comportamento di corrispondenza per l'elenco di lingue. Il comportamento di corrispondenza può includere la possibilità di scegliere una corrispondenza esatta per un elemento secondario nell'elenco rispetto a una corrispondenza parziale per il primo elemento dell'elenco, se è presente un terzo elemento che corrisponde alla lingua e allo script del primo elemento. Ecco un esempio.
- Elenco di lingue (in ordine): "pt-PT" (portoghese (Portogallo)), "en-US" (inglese (Stati Uniti)), "pt-BR" (portoghese (Brasile)).
- Risorse: "en-US", "pt-BR".
- Risorsa con il punteggio più alto: "en-US".
- Descrizione: il confronto inizia con "pt-PT", ma non trova una corrispondenza esatta. A causa della presenza di "pt-BR" nell'elenco delle lingue dell'utente, la corrispondenza parziale viene posticipata al confronto con "pt-BR". Il confronto tra lingue successive è "en-US", che ha una corrispondenza esatta. Quindi, la risorsa vincente è "en-US".
OPPURE
- Elenco di lingue (in ordine): "es-MX" (spagnolo (Messico)), "es-HO" (spagnolo (Honduras)).
- Risorse: "en-ES", "es-HO".
- Risorsa con il punteggio più alto: "es-HO".
Lingua non determinata ("und")
Il tag di lingua "und" può essere usato per specificare una risorsa che corrisponde a qualsiasi lingua in assenza di una corrispondenza migliore. Può essere considerato simile all'intervallo di linguaggio BCP-47 "" o "-<script>". Ecco un esempio.
- Elenco di lingue: "en-US", "zh-Hans-CN".
- Risorse: "zh-Hans-CN", "und".
- Risorsa con il punteggio più alto: "und".
- Descrizione: il confronto inizia con "en-US", ma non trova una corrispondenza basata su "en" (parziale o superiore). Poiché è presente una risorsa contrassegnata con "und", l'algoritmo corrispondente lo usa.
Il tag "und" consente a più lingue di condividere una singola risorsa e di consentire la gestione di singole lingue come eccezioni. Ad esempio,
- Elenco di lingue: "zh-Hans-CN", "en-US".
- Risorse: "zh-Hans-CN", "und".
- Risorsa con il punteggio più alto: "zh-Hans-CN".
- Descrizione: il confronto trova una corrispondenza esatta per il primo elemento e quindi non verifica la presenza della risorsa con etichetta "und".
È possibile usare "und" con un tag script per filtrare le risorse in base allo script. Ad esempio,
- Elenco di lingue: "ru".
- Risorse: "und-Latn", "und-Cyrl", "und-Arab".
- Risorsa con il punteggio più alto: "und-Cyrl".
- Descrizione: il confronto non trova una corrispondenza per "ru" (parziale o superiore) e quindi corrisponde al tag di lingua "und". Il valore suppress-script "Cyrl" associato al tag di lingua "ru" corrisponde alla risorsa "und-Cyrl".
Affinità regionale ortografica
Quando vengono confrontati due tag di lingua con differenze di sottotag di area, alcune coppie di aree possono avere un'affinità più elevata tra loro rispetto ad altre. Gli unici gruppi affinati supportati sono per l'inglese ("en"). I sottotag di area "PH" (Filippine) e "LR" (Liberia) hanno affinità ortografica con il sottotag dell'area "STATI UNITI". Tutti gli altri sottotag di area sono associati al sottotag dell'area "GB" (Regno Unito). Pertanto, quando sono disponibili sia le risorse "en-US" che "en-GB", un elenco di lingue "en-HK" (inglese (Hong Kong SAR)) otterrà un punteggio superiore con risorse "en-GB" rispetto alle risorse "en-US".
Gestione delle lingue con molte varianti regionali
Alcune lingue hanno comunità di parlante di grandi dimensioni in aree diverse che usano diverse varietà di tale lingua, ad esempio inglese, francese e spagnolo, che sono tra quelle più spesso supportate nelle app multilingue. Le differenze regionali possono includere differenze nell'ortografia (ad esempio, "colore" rispetto a "colore") o differenze di dialetto come il vocabolario (ad esempio, "camion" rispetto a "camion").
Queste lingue con varianti regionali significative presentano determinate sfide quando si crea un'app pronta per il mondo: "Quante varianti regionali diverse devono essere supportate?" "Quali?" "Qual è il modo più conveniente per gestire questi asset varianti regionali per la mia app?" Oltre l'ambito di questo argomento, rispondere a tutte queste domande. Tuttavia, i meccanismi di corrispondenza del linguaggio in Windows offrono funzionalità che consentono di gestire le varianti regionali.
Le app spesso supportano solo una singola varietà di qualsiasi lingua specificata. Si supponga che un'app disponga di risorse per una sola varietà di inglese che devono essere usate dai parlanti inglesi indipendentemente dall'area da cui provengono. In questo caso, il tag "en" senza alcun sottotag di area rifletterebbe tale aspettativa. Tuttavia, le app potrebbero aver usato storicamente un tag come "en-US" che include un sottotag di area. In questo caso, funzionerà anche: l'app usa una sola varietà di inglese e Windows gestisce la corrispondenza di una risorsa contrassegnata per una variante regionale con una preferenza di lingua utente per una variante regionale diversa in modo appropriato.
Se due o più varietà regionali saranno supportate, tuttavia, una differenza come "en" e "en-US" può avere un impatto significativo sull'esperienza utente e diventa importante considerare quali sottotag di area usare.
Si supponga di voler fornire localizzazioni francesi separate per il francese usato in Canada rispetto al francese europeo. Per il francese canadese, è possibile usare "fr-CA". Per i parlanti europei, la localizzazione userà francese (Francia) e quindi "fr-FR" può essere usata per questo. Ma cosa succede se un determinato utente proviene dal Belgio, con una preferenza di lingua "fr-BE"; che otterranno? L'area "BE" è diversa da "FR" e "CA", che suggerisce una corrispondenza "qualsiasi area" per entrambi. Tuttavia, la Francia è la regione preferita per il francese, quindi "fr-FR" verrà considerata la corrispondenza migliore in questo caso.
Si supponga di aver localizzato per la prima volta l'app per una sola varietà di stringhe francesi (Francia), ma qualificarle in modo generico come "fr" e quindi si vuole aggiungere il supporto per il francese canadese. Probabilmente solo alcune risorse devono essere ri-tradotte per il francese canadese. È possibile continuare a usare tutti gli asset originali mantenendoli qualificati come "fr" e aggiungere solo il piccolo set di nuovi asset usando "fr-CA". Se la preferenza per la lingua utente è "fr-CA", l'asset "fr-CA" avrà un punteggio di corrispondenza superiore rispetto all'asset "fr". Tuttavia, se la preferenza per la lingua utente è per qualsiasi altra varietà di francese, l'asset indipendente dall'area geografica "fr" sarà una corrispondenza migliore rispetto all'asset "fr-CA".
Come altro esempio, si supponga di voler fornire localizzazioni spagnole separate per i parlanti dalla Spagna rispetto ai parlanti dell'America Latina. Si supponga inoltre che le traduzioni per l'America Latina siano state fornite da un fornitore in Messico. È consigliabile usare "es-ES" (Spagna) e "es-MX" (Messico) per due set di risorse? In caso affermativo, ciò potrebbe creare problemi per i parlanti di altre regioni dell'America Latina, ad esempio Argentina o Colombia, poiché otterrebbero le risorse "es-ES". In questo caso, esiste un'alternativa migliore: è possibile usare un sottotag di area macro, "es-419" per riflettere che si intende utilizzare gli asset per i parlanti di qualsiasi parte dell'America Latina o dei Caraibi.
I tag di lingua e i sottotag di area geografica indipendenti dall'area geografica possono essere molto efficaci se si desidera supportare diverse varietà regionali. Per ridurre al minimo il numero di asset separati necessari, è possibile qualificare un determinato asset in modo che rifletta la copertura più ampia per cui è applicabile. Integrare quindi un asset ampiamente applicabile con una variante più specifica in base alle esigenze. Un asset con qualificatore linguistico indipendente dall'area geografica verrà usato per gli utenti di qualsiasi varietà a livello di area, a meno che non esista un altro asset con un qualificatore più specifico a livello di area applicabile a tale utente. Ad esempio, un asset "en" corrisponderà a un utente australiano inglese, ma un asset con "en-053" (inglese usato in Australia o Nuova Zelanda) sarà una corrispondenza migliore per tale utente, mentre un asset con "en-AU" sarà la corrispondenza migliore possibile.
L'inglese ha bisogno di considerazioni speciali. Se un'app aggiunge localizzazione per due varietà inglesi, è probabile che queste siano per l'inglese statunitense e per il Regno Unito o "internazionale", inglese. Come indicato in precedenza, alcune aree esterne agli Stati Uniti seguono Stati Uniti convenzioni di ortografia e la corrispondenza delle lingue di Windows prende in considerazione questa considerazione. In questo scenario non è consigliabile usare il tag region-neutral "en" per una delle varianti; usare invece "en-GB" e "en-US". Se una determinata risorsa non richiede varianti separate, tuttavia, è possibile usare "en". Se "en-GB" o "en-US" viene sostituito da "en", ciò interferisce con l'affinità regionale ortografica fornita da Windows. Se viene aggiunta una terza localizzazione in inglese, usare un sottotag specifico o di area macro per le varianti aggiuntive in base alle esigenze (ad esempio, "en-CA", "en-AU" o "en-053"), ma continuare a usare "en-GB" e "en-US".