Profilatura precisa delle chiamate API Direct3D (Direct3D 9)
- La profilatura accurata di Direct3D è difficile
- Come profilare in modo accurato una sequenza di rendering Direct3D
- Profilatura delle modifiche dello stato Direct3D
- Riepilogo
- Appendice
Una volta ottenuta un'applicazione Microsoft Direct3D funzionale e si vuole migliorarne le prestazioni, in genere si usa uno strumento di profilatura predefinito o una tecnica di misurazione personalizzata per misurare il tempo necessario per eseguire una o più chiamate API (Application Programming Interface). Se questa operazione è stata eseguita ma si ottengono risultati di intervallo che variano da una sequenza di rendering alla successiva oppure si stanno facendo ipotesi che non contengono risultati effettivi dell'esperimento, le informazioni seguenti possono aiutare a capire perché.
Le informazioni fornite qui si basano sul presupposto di avere una conoscenza e un'esperienza con quanto segue:
- Programmazione C/C++
- Programmazione api Direct3D
- Misurazione della tempistica dell'API
- Scheda video e driver software
- Possibili risultati inspiegabili dall'esperienza di profilatura precedente
La profilatura accurata di Direct3D è difficile
Un profiler segnala la quantità di tempo impiegato in ogni chiamata API. Questa operazione viene eseguita per migliorare le prestazioni individuando e ottimizzando i punti caldi. Esistono diversi tipi di profiler e tecniche di profilatura.
- Un profiler di campionamento rimane inattiva gran parte del tempo, risvegliandosi a intervalli specifici per campionare (o per registrare) le funzioni eseguite. Restituisce la percentuale di tempo impiegato in ogni chiamata. In genere, un profiler di campionamento non è molto invasivo per l'applicazione e ha un impatto minimo sull'overhead per l'applicazione.
- Un profiler di strumentazione misura il tempo effettivo necessario per la restituzione di una chiamata. Richiede la compilazione di delimitatori di avvio e arresto in un'applicazione. Un profiler di strumentazione è relativamente più invasivo per un'applicazione rispetto a un profiler di campionamento.
- È anche possibile usare una tecnica di profilatura personalizzata con un timer ad alte prestazioni. Questo produce risultati molto simili a un profiler di strumentazione.
Il tipo di tecnica di profilatura o profiler usato è solo parte della sfida di generare misurazioni accurate.
La profilatura offre risposte che consentono di ottenere prestazioni di budget. Si supponga, ad esempio, di sapere che una chiamata API calcola una media di migliaia di cicli di clock da eseguire. È possibile affermare alcune conclusioni sulle prestazioni, ad esempio le seguenti:
- Una CPU a 2 GHz (che impiega il 50% del relativo rendering temporale) è limitata alla chiamata di questa API 1 milione di volte al secondo.
- Per ottenere 30 fotogrammi al secondo, non è possibile chiamare questa API più di 33.000 volte per fotogramma.
- È possibile eseguire il rendering solo di oggetti 3.3K per fotogramma (presupponendo che 10 di queste chiamate API per la sequenza di rendering di ogni oggetto).
In altre parole, se si dispone di tempo sufficiente per ogni chiamata API, è possibile rispondere a una domanda di budget, ad esempio il numero di primitive di cui è possibile eseguire il rendering in modo interattivo. Ma i numeri non elaborati restituiti da un profiler di strumentazione non risponderanno in modo accurato alle domande di budget. Ciò è dovuto al fatto che la pipeline grafica presenta problemi di progettazione complessi, ad esempio il numero di componenti che devono eseguire il lavoro, il numero di processori che controllano il flusso di lavoro tra i componenti e le strategie di ottimizzazione implementate nel runtime e in un driver progettato per rendere la pipeline più efficiente.
Ogni chiamata API passa attraverso diversi componenti
Ogni chiamata viene elaborata da diversi componenti nel percorso dall'applicazione alla scheda video. Si consideri, ad esempio, la sequenza di rendering seguente contenente due chiamate per disegnare un singolo triangolo:
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
Il diagramma concettuale seguente illustra i diversi componenti attraverso i quali le chiamate devono passare.

L'applicazione richiama Direct3D che controlla la scena, gestisce le interazioni dell'utente e determina la modalità di esecuzione del rendering. Tutto questo lavoro viene specificato nella sequenza di rendering, che viene inviata al runtime usando chiamate API Direct3D. La sequenza di rendering è virtualmente indipendente dall'hardware, ovvero le chiamate API sono indipendenti dall'hardware, ma un'applicazione ha una conoscenza delle funzionalità supportate da una scheda video.
Il runtime converte queste chiamate in un formato indipendente dal dispositivo. Il runtime gestisce tutte le comunicazioni tra l'applicazione e il driver, in modo che un'applicazione venga eseguita su più componenti hardware compatibili (a seconda delle funzionalità necessarie). Quando si misura una chiamata di funzione, un profiler di strumentazione misura il tempo impiegato in una funzione e il tempo necessario per la restituzione della funzione. Una limitazione di un profiler di strumentazione è che potrebbe non includere il tempo necessario per inviare il lavoro risultante alla scheda video né il tempo necessario per elaborare il lavoro della scheda video. In altre parole, un profiler di strumentazione non è in grado di attribuire tutto il lavoro associato a ogni chiamata di funzione.
Il driver software usa conoscenze specifiche dell'hardware sulla scheda video per convertire i comandi indipendenti dal dispositivo in una sequenza di comandi della scheda video. I driver possono anche ottimizzare la sequenza di comandi inviati alla scheda video, in modo che il rendering sulla scheda video venga eseguito in modo efficiente. Queste ottimizzazioni possono causare problemi di profilatura perché la quantità di lavoro svolto non è quella che sembra essere (potrebbe essere necessario comprendere le ottimizzazioni per tener conto di esse). Il driver restituisce in genere il controllo al runtime prima che la scheda video abbia completato l'elaborazione di tutti i comandi.
La scheda video esegue la maggior parte del rendering combinando i dati dai buffer dei vertici e degli indici, le trame, le informazioni sullo stato di rendering e i comandi grafici. Al termine del rendering della scheda video, il lavoro creato dalla sequenza di rendering è completato.
Ogni chiamata API Direct3D deve essere elaborata da ogni componente (il runtime, il driver e la scheda video) per eseguire il rendering di qualsiasi elemento.
Sono presenti più processori che controllano i componenti
La relazione tra questi componenti è ancora più complessa, perché l'applicazione, il runtime e il driver sono controllati da un processore e la scheda video è controllata da un processore separato. Il diagramma seguente mostra due tipi di processori: un'unità di elaborazione centrale (CPU) e un'unità di elaborazione grafica (GPU).
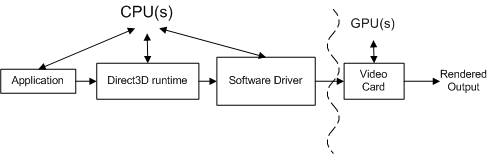
I sistemi PC hanno almeno una CPU e una GPU, ma possono avere più di una o entrambe. Le CPU si trovano sulla scheda madre e le GPU si trovano sulla scheda madre o sulla scheda video. La velocità della CPU è determinata da un chip di clock sulla scheda madre e la velocità della GPU è determinata da un chip di clock separato. L'orologio della CPU controlla la velocità del lavoro svolto dall'applicazione, dal runtime e dal driver. L'applicazione invia il lavoro alla GPU tramite il runtime e il driver.
La CPU e la GPU vengono in genere eseguite a velocità diverse, indipendenti l'una dall'altra. La GPU può rispondere al lavoro non appena il lavoro è disponibile (presupponendo che la GPU abbia terminato l'elaborazione del lavoro precedente). Il lavoro della GPU viene eseguito in parallelo con il lavoro della CPU come evidenziato dalla linea curva nella figura precedente. Un profiler in genere misura le prestazioni della CPU, non della GPU. Ciò rende difficile la profilatura, perché le misurazioni effettuate da un profiler di strumentazione includono il tempo cpu, ma potrebbero non includere il tempo gpu.
Lo scopo della GPU è l'offload dell'elaborazione dalla CPU a un processore progettato appositamente per il lavoro grafico. Nelle schede video moderne, la GPU sostituisce gran parte del lavoro di trasformazione e illuminazione nella pipeline dalla CPU alla GPU. In questo modo si riduce notevolmente il carico di lavoro della CPU, lasciando più cicli di CPU disponibili per altre elaborazioni. Per ottimizzare un'applicazione grafica per ottenere prestazioni ottimali, è necessario misurare le prestazioni della CPU e della GPU e bilanciare il lavoro tra i due tipi di processori.
Questo documento non illustra gli argomenti relativi alla misurazione delle prestazioni della GPU o al bilanciamento del lavoro tra la CPU e la GPU. Per comprendere meglio le prestazioni di una GPU (o di una scheda video specifica), visitare il sito Web del fornitore per cercare altre informazioni sulle prestazioni della GPU. Questo documento è invece incentrato sul lavoro svolto dal runtime e dal driver riducendo il lavoro della GPU a una quantità trascurabile. Ciò è, in parte, basato sull'esperienza che le applicazioni che riscontrano problemi di prestazioni sono in genere limitate dalla CPU.
Le ottimizzazioni del runtime e del driver possono mascherare le misurazioni dell'API
Il runtime include un'ottimizzazione delle prestazioni incorporata che può sovraccaricare la misurazione di una singola chiamata. Ecco uno scenario di esempio che illustra questo problema. Si consideri la sequenza di rendering seguente:
BeginScene();
...
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
...
EndScene();
Present();
Esempio 1: Sequenza di rendering semplice
Esaminando i risultati delle due chiamate nella sequenza di rendering, un profiler di strumentazione potrebbe restituire risultati simili ai seguenti:
Number of cycles for SetTexture : 100
Number of cycles for DrawPrimitive : 950,500
Il profiler restituisce il numero di cicli di CPU necessari per elaborare il lavoro associato a ogni chiamata. Tenere presente che la GPU non è ancora inclusa in questi numeri perché la GPU non ha ancora iniziato a lavorare su questi comandi. Poiché IDirect3DDevice9::D rawPrimitive richiedeva quasi un milione di cicli da elaborare, potresti concludere che non è molto efficiente. Tuttavia, si vedrà presto perché questa conclusione non è corretta e come è possibile generare risultati che possono essere usati per il budget.
La misurazione delle modifiche dello stato richiede un'attenta sequenza di rendering
Tutte le chiamate diverse da IDirect3DDevice9::D rawPrimitive, DrawIndexedPrimitive o Clear (ad esempio SetTexture, SetVertexDeclaration e SetRenderState) generano una modifica dello stato. Ogni modifica dello stato imposta lo stato della pipeline che controlla come verrà eseguito il rendering.
Le ottimizzazioni nel runtime e/o nel driver sono progettate per velocizzare il rendering riducendo la quantità di lavoro necessaria. Di seguito sono riportate alcune ottimizzazioni di modifica dello stato che possono inquinare le medie dei profili:
- Un driver (o il runtime) potrebbe salvare una modifica dello stato come stato locale. Poiché il driver potrebbe operare in un algoritmo "differita" (posticipando il lavoro fino a quando non è assolutamente necessario), il lavoro associato ad alcune modifiche di stato potrebbe essere ritardato.
- Il runtime (o un driver) può rimuovere le modifiche di stato ottimizzando. Un esempio potrebbe essere quello di rimuovere una modifica dello stato ridondante che disabilita l'illuminazione perché l'illuminazione è stata disabilitata in precedenza.
Non esiste un modo infallibile per esaminare una sequenza di rendering e concludere quali modifiche di stato impostano un bit dirty e rinviano il lavoro, o semplicemente verranno rimosse dall'ottimizzazione. Anche se è possibile identificare le modifiche di stato ottimizzate nel runtime o nel driver di oggi, è probabile che il runtime o il driver di domani vengano aggiornati. Inoltre, non si sa cosa fosse lo stato precedente, quindi è difficile identificare le modifiche dello stato ridondanti. L'unico modo per verificare il costo di una modifica dello stato consiste nel misurare la sequenza di rendering che include le modifiche dello stato.
Come si può notare, le complicazioni causate dalla presenza di più processori, comandi elaborati da più componenti e ottimizzazioni integrate nei componenti rendono difficile la profilatura. Nella sezione successiva, ognuna di queste problematiche di profilatura verrà risolta. Verranno visualizzate sequenze di rendering Direct3D di esempio, con le tecniche di misurazione associate. Con questa conoscenza, sarà possibile generare misurazioni accurate e ripetibili su singole chiamate.
Come profilare in modo accurato una sequenza di rendering Direct3D
Ora che alcune delle problematiche di profilatura sono state evidenziate, questa sezione illustra le tecniche che consentono di generare misurazioni del profilo che possono essere usate per il budget. Le misurazioni di profilatura accurate e ripetibili sono possibili se si comprende la relazione tra i componenti controllati dalla CPU e come evitare ottimizzazioni delle prestazioni implementate dal runtime e dal driver.
Per iniziare, è necessario essere in grado di misurare accuratamente il tempo di esecuzione di una singola chiamata API.
Selezionare uno strumento di misurazione accurato, ad esempio QueryPerformanceCounter
Il sistema operativo Microsoft Windows include un timer ad alta risoluzione che può essere usato per misurare i tempi trascorsi ad alta risoluzione. È possibile restituire il valore corrente di un timer di questo tipo usando QueryPerformanceCounter. Dopo aver richiamato QueryPerformanceCounter per restituire i valori di avvio e arresto, la differenza tra i due valori può essere convertita nel tempo trascorso effettivo (in secondi) usando QueryPerformanceCounter.
I vantaggi dell'uso di QueryPerformanceCounter sono che sono disponibili in Windows ed è facile da usare. È sufficiente racchiudere le chiamate con una chiamata QueryPerformanceCounter e salvare i valori di avvio e arresto. Di conseguenza, questo documento illustra come usare QueryPerformanceCounter per profilare i tempi di esecuzione, in modo analogo al modo in cui un profiler di strumentazione lo misura. Ecco un esempio che illustra come incorporare QueryPerformanceCounter nel codice sorgente:
BeginScene();
...
// Start profiling
LARGE_INTEGER start, stop, freq;
QueryPerformanceCounter(&start);
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
QueryPerformanceCounter(&stop);
stop.QuadPart -= start.QuadPart;
QueryPerformanceFrequency(&freq);
// Stop profiling
...
EndScene();
Present();
Esempio 2: Implementazione della profilatura personalizzata con QPC
start e stop sono due interi di grandi dimensioni che conterranno i valori di avvio e arresto restituiti dal timer ad alte prestazioni. Si noti che QueryPerformanceCounter(&start) viene chiamato subito prima che SetTexture e QueryPerformanceCounter(&stop) venga chiamato subito dopo DrawPrimitive. Dopo aver ottenuto il valore di arresto, QueryPerformanceFrequency viene chiamato per restituire freq, ovvero la frequenza del timer ad alta risoluzione. In questo esempio ipotetico si supponga di ottenere i risultati seguenti per l'avvio, l'arresto e il freq:
| Variabile locale | Numero di tick |
|---|---|
| Avvio | 1792998845094 |
| stop | 1792998845102 |
| Freq | 3579545 |
È possibile convertire questi valori nel numero di cicli necessari per eseguire le chiamate API come segue:
# ticks = (stop - start) = 1792998845102 - 1792998845094 = 8 ticks
# cycles = CPU speed * number of ticks / QPF
# 4568 = 2 GHz * 8 / 3,579,545
In altre parole, sono necessari circa 4568 cicli di clock per elaborare SetTexture e DrawPrimitive in questo computer a 2 GHz. È possibile convertire questi valori nel tempo effettivo impiegato per eseguire tutte le chiamate come segue:
(stop - start)/ freq = elapsed time
8 ticks / 3,579,545 = 2.2E-6 seconds or between 2 and 3 microseconds.
L'uso di QueryPerformanceCounter richiede l'aggiunta di misurazioni di avvio e arresto alla sequenza di rendering e l'uso di QueryPerformanceFrequency per convertire la differenza (numero di tick) nel numero di cicli cpu o in tempo effettivo. L'identificazione della tecnica di misurazione è un buon punto di partenza per lo sviluppo di un'implementazione di profilatura personalizzata. Ma prima di saltare e iniziare a fare misurazioni, è necessario sapere come gestire la scheda video.
Concentrarsi sulle misurazioni della CPU
Come indicato in precedenza, la CPU e la GPU funzionano in parallelo per elaborare il lavoro generato dalle chiamate API. Un'applicazione reale richiede la profilatura di entrambi i tipi di processori per scoprire se l'applicazione è limitata dalla CPU o limitata dalla GPU. Poiché le prestazioni gpu sono specifiche del fornitore, sarebbe molto difficile produrre risultati in questo documento che coprono la varietà di schede video disponibili.
Invece, questo documento si concentrerà solo sulla profilatura del lavoro eseguito dalla CPU usando una tecnica personalizzata per misurare il runtime e il lavoro del driver. Il lavoro della GPU verrà ridotto a una quantità insignificante, in modo che i risultati della CPU siano più visibili. Un vantaggio di questo approccio è che questa tecnica produce risultati nell'Appendice che dovrebbe essere in grado di correlare con le misurazioni. Per ridurre il lavoro richiesto dalla scheda video a un livello insignificante, è sufficiente ridurre il lavoro di rendering al minimo possibile. Questa operazione può essere eseguita limitando le chiamate di disegno per eseguire il rendering di un singolo triangolo e può essere ulteriormente vincolata in modo che ogni triangolo contenga solo un pixel.
L'unità di misura usata in questo documento per misurare il lavoro della CPU sarà il numero di cicli di clock della CPU anziché l'ora effettiva. I cicli di clock della CPU hanno il vantaggio che è più portabile (per le applicazioni limitate dalla CPU) rispetto al tempo trascorso effettivo tra i computer con velocità di CPU diverse. Questa operazione può essere facilmente convertita in tempo effettivo, se necessario.
Questo documento non tratta gli argomenti relativi al bilanciamento del carico di lavoro tra la CPU e la GPU. Tenere presente che l'obiettivo di questo documento non è misurare le prestazioni complessive di un'applicazione, ma mostrare come misurare accuratamente il tempo necessario per il runtime e il driver per elaborare le chiamate API. Con queste misurazioni accurate, è possibile eseguire l'attività di budget della CPU per comprendere determinati scenari di prestazioni.
Controllo delle ottimizzazioni di runtime e driver
Con una tecnica di misurazione identificata e una strategia per ridurre il lavoro della GPU, il passaggio successivo consiste nel comprendere le ottimizzazioni di runtime e driver che si ottengono nel modo in cui si esegue la profilatura.
Il lavoro della CPU può essere suddiviso in tre bucket: il lavoro dell'applicazione, il lavoro di runtime e il lavoro del driver. Ignorare il lavoro dell'applicazione perché è sotto controllo programmatore. Dal punto di vista dell'applicazione, il runtime e il driver sono come caselle nere, perché l'applicazione non ha alcun controllo su ciò che viene implementato in essi. La chiave è comprendere le tecniche di ottimizzazione che possono essere implementate nel runtime e nel driver. Se non si conoscono queste ottimizzazioni, è molto facile passare alla conclusione sbagliata circa la quantità di lavoro che la CPU sta facendo in base alle misurazioni del profilo. In particolare, ci sono due argomenti correlati a qualcosa denominato buffer dei comandi e a cosa può fare per offuscare la profilatura. Questi argomenti sono:
- Ottimizzazione del runtime con il buffer dei comandi. Il buffer dei comandi è un'ottimizzazione del runtime che riduce l'impatto di una transizione in modalità. Per controllare l'intervallo della transizione in modalità, vedere Controllo del buffer dei comandi.
- Negazione degli effetti di intervallo del buffer dei comandi. Il tempo trascorso di una transizione in modalità può avere un impatto significativo sulle misurazioni di profilatura. La strategia per questa operazione consiste nel rendere grande la sequenza di rendering rispetto alla transizione in modalità.
Controllo del buffer dei comandi
Quando un'applicazione effettua una chiamata API, il runtime converte la chiamata API in un formato indipendente dal dispositivo (che chiameremo un comando) e la archivia nel buffer dei comandi. Il buffer dei comandi viene aggiunto al diagramma seguente.
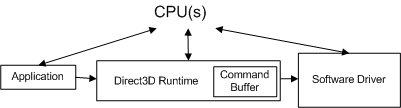
Ogni volta che l'applicazione effettua un'altra chiamata API, il runtime ripete questa sequenza e aggiunge un altro comando al buffer dei comandi. A un certo punto, il runtime svuota il buffer (inviando i comandi al driver). In Windows XP, svuotando il buffer dei comandi viene eseguita una transizione in modalità mentre il sistema operativo passa dal runtime (in esecuzione in modalità utente) al driver (in esecuzione in modalità kernel), come illustrato nel diagramma seguente.
- modalità utente: modalità processore senza privilegi che esegue il codice dell'applicazione. Le applicazioni in modalità utente non possono accedere ai dati di sistema, ad eccezione dei servizi di sistema.
- modalità kernel: modalità processore con privilegi in cui viene eseguito il codice esecutivo basato su Windows. Un driver o un thread in esecuzione in modalità kernel ha accesso a tutta la memoria di sistema, l'accesso diretto all'hardware e le istruzioni della CPU per eseguire operazioni di I/O con l'hardware.
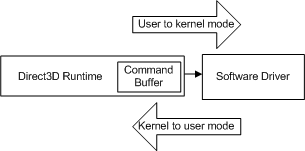
La transizione avviene ogni volta che la CPU passa dalla modalità utente alla modalità kernel (e viceversa) e il numero di cicli necessari è elevato rispetto a una singola chiamata API. Se il runtime ha inviato ogni chiamata API al driver quando è stato richiamato, ogni chiamata API comporta il costo di una transizione in modalità.
Il buffer dei comandi è invece un'ottimizzazione del runtime progettata per ridurre il costo effettivo della transizione in modalità. Il buffer dei comandi accoda molti comandi driver in preparazione di una singola transizione in modalità singola. Quando il runtime aggiunge un comando al buffer dei comandi, il controllo viene restituito all'applicazione. Un profiler non ha modo di sapere che i comandi del driver probabilmente non sono ancora stati inviati al driver. Di conseguenza, i numeri restituiti da un profiler di strumentazione off-the-shelf sono fuorvianti perché misura il funzionamento del runtime, ma non il lavoro del driver associato.
Risultati del profilo senza transizione in modalità
Usando la sequenza di rendering dell'esempio 2, ecco alcune misurazioni di intervallo tipiche che illustrano la grandezza di una transizione in modalità. Supponendo che le chiamate SetTexture e DrawPrimitive non causino una transizione in modalità, un profiler di strumentazione predefinito potrebbe restituire risultati simili ai seguenti:
Number of cycles for SetTexture : 100
Number of cycles for DrawPrimitive : 900
Ognuno di questi numeri è il tempo necessario per il runtime per aggiungere queste chiamate al buffer dei comandi. Poiché non esiste alcuna transizione in modalità, il driver non ha ancora eseguito alcun lavoro. I risultati del profiler sono accurati, ma non misurano tutte le operazioni che la sequenza di rendering causerà l'esecuzione della CPU.
Risultati del profilo con una transizione in modalità
A questo punto, esaminare cosa accade per lo stesso esempio quando si verifica una transizione in modalità. Questa volta, si supponga che SetTexture e DrawPrimitive causi una transizione in modalità. Ancora una volta, un profiler di strumentazione fuori uso potrebbe restituire risultati simili ai seguenti:
Number of cycles for SetTexture : 98
Number of cycles for DrawPrimitive : 946,900
Il tempo misurato per SetTexture è lo stesso, tuttavia, l'aumento significativo della quantità di tempo impiegato in DrawPrimitive è dovuto alla transizione della modalità. Ecco cosa sta accadendo:
- Si supponga che il buffer dei comandi abbia spazio per un comando prima dell'avvio della sequenza di rendering.
- SetTexture viene convertito in un formato indipendente dal dispositivo e aggiunto al buffer dei comandi. In questo scenario, questa chiamata riempie il buffer dei comandi.
- Il runtime tenta di aggiungere DrawPrimitive al buffer dei comandi, ma non può, perché è pieno. Il runtime svuota invece il buffer dei comandi. In questo modo viene eseguita la transizione in modalità kernel. Si supponga che la transizione abbia circa 5000 cicli. Questo tempo contribuisce al tempo trascorso in DrawPrimitive.
- Il driver elabora quindi il lavoro associato a tutti i comandi svuotati dal buffer dei comandi. Si supponga che il tempo del driver per elaborare i comandi che quasi riempito il buffer dei comandi sia di circa 935.000 cicli. Si supponga che il driver associato a SetTexture sia di circa 2750 cicli. Questo tempo contribuisce al tempo trascorso in DrawPrimitive.
- Al termine del funzionamento del driver, la transizione in modalità utente restituisce il controllo al runtime. Il buffer dei comandi è ora vuoto. Si supponga che la transizione abbia circa 5000 cicli.
- La sequenza di rendering viene completata convertendo DrawPrimitive e aggiungendola al buffer dei comandi. Si supponga che questo richiede circa 900 cicli. Questo tempo contribuisce al tempo trascorso in DrawPrimitive.
Riepilogando i risultati, viene visualizzato quanto illustrato di seguito:
DrawPrimitive = kernel-transition + driver work + user-transition + runtime work
DrawPrimitive = 5000 + 935,000 + 2750 + 5000 + 900
DrawPrimitive = 947,950
Proprio come la misurazione per DrawPrimitive senza la transizione in modalità (900 cicli), la misurazione per DrawPrimitive con la transizione in modalità (947.950 cicli) è accurata ma inutile in termini di budget del lavoro della CPU. Il risultato contiene il lavoro di runtime corretto, il lavoro del driver per SetTexture, il driver funziona per tutti i comandi che hanno preceduto SetTexture e due transizioni in modalità. Tuttavia, la misurazione manca il lavoro del driver DrawPrimitive .
Una transizione in modalità può verificarsi in risposta a qualsiasi chiamata. Dipende da ciò che era in precedenza nel buffer dei comandi. È necessario controllare la transizione della modalità per comprendere il funzionamento della CPU (runtime e driver) a ogni chiamata. A tale scopo, è necessario un meccanismo per controllare il buffer dei comandi e la tempistica della transizione in modalità.
Meccanismo di query
Il meccanismo di query in Microsoft Direct3D 9 è stato progettato per consentire al runtime di eseguire query sulla GPU per ottenere lo stato di avanzamento e restituire determinati dati dalla GPU. Durante la profilatura, se il lavoro della GPU è ridotto a icona in modo da avere un impatto trascurabile sulle prestazioni, è possibile restituire lo stato dalla GPU per misurare il lavoro del driver. Dopo tutto, il lavoro del driver è completo quando la GPU ha visto i comandi del driver. Inoltre, il meccanismo di query può essere coassiato per controllare due caratteristiche del buffer dei comandi importanti per la profilatura: quando il buffer dei comandi svuota e la quantità di lavoro nel buffer.
Ecco la stessa sequenza di rendering usando il meccanismo di query:
// 1. Create an event query from the current device
IDirect3DQuery9* pEvent;
m_pD3DDevice->CreateQuery(D3DQUERYTYPE_EVENT, &pEvent);
// 2. Add an end marker to the command buffer queue.
pEvent->Issue(D3DISSUE_END);
// 3. Empty the command buffer and wait until the GPU is idle.
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
// 4. Start profiling
LARGE_INTEGER start, stop;
QueryPerformanceCounter(&start);
// 5. Invoke the API calls to be profiled.
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
// 6. Add an end marker to the command buffer queue.
pEvent->Issue(D3DISSUE_END);
// 7. Force the driver to execute the commands from the command buffer.
// Empty the command buffer and wait until the GPU is idle.
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
// 8. End profiling
QueryPerformanceCounter(&stop);
Esempio 3: Uso di una query per controllare il buffer dei comandi
Ecco una spiegazione più dettagliata di ognuna di queste righe di codice:
- Creare una query evento creando un oggetto query con D3DQUERYTYPE_EVENT.
- Aggiungere un marcatore di evento di query al buffer dei comandi chiamando Issue(D3DISSUE_END). Questo marcatore indica al driver di tenere traccia quando la GPU termina l'esecuzione di qualsiasi comando preceduto dall'indicatore.
- La prima chiamata svuota il buffer dei comandi perché la chiamata a GetData con D3DGETDATA_FLUSH forza il svuotare il buffer dei comandi. Ogni chiamata successiva controlla la GPU per vedere quando termina l'elaborazione di tutto il lavoro del buffer dei comandi. Questo ciclo non restituisce S_OK finché la GPU non è inattiva.
- Esempio dell'ora di inizio.
- Richiamare le chiamate API profilate.
- Aggiungere un secondo indicatore di evento di query al buffer dei comandi. Questo marcatore verrà usato per tenere traccia del completamento delle chiamate.
- La prima chiamata svuota il buffer dei comandi perché la chiamata a GetData con D3DGETDATA_FLUSH forza il svuotare il buffer dei comandi. Quando la GPU termina l'elaborazione di tutto il lavoro del buffer dei comandi, GetData restituisce S_OK e il ciclo viene chiuso perché la GPU è inattiva.
- Esempio dell'ora di arresto.
Ecco i risultati misurati con QueryPerformanceCounter e QueryPerformanceFrequency:
| Variabile locale | Numero di tick |
|---|---|
| Avvio | 1792998845060 |
| stop | 1792998845090 |
| Freq | 3579545 |
Conversione di tick in cicli ancora una volta (in un computer a 2 GHz):
# ticks = (stop - start) = 1792998845090 - 1792998845060 = 30 ticks
# cycles = CPU speed * number of ticks / QPF
# 16,450 = 2 GHz * 30 / 3,579,545
Ecco la suddivisione del numero di cicli per chiamata:
Number of cycles for SetTexture : 100
Number of cycles for DrawPrimitive : 900
Number of cycles for Issue : 200
Number of cycles for GetData : 16,450
Il meccanismo di query ha consentito di controllare il runtime e il lavoro del driver che viene misurato. Per comprendere ognuno di questi numeri, ecco cosa accade in risposta a ognuna delle chiamate API, insieme ai tempi stimati:
La prima chiamata svuota il buffer dei comandi chiamando GetData con D3DGETDATA_FLUSH. Quando la GPU termina l'elaborazione di tutto il lavoro del buffer dei comandi, GetData restituisce S_OK e il ciclo viene chiuso perché la GPU è inattiva.
La sequenza di rendering inizia convertendo SetTexture in un formato indipendente dal dispositivo e aggiungendolo al buffer dei comandi. Si supponga che questo richiede circa 100 cicli.
DrawPrimitive viene convertito e aggiunto al buffer dei comandi. Si supponga che questo richiede circa 900 cicli.
Il problema aggiunge un marcatore di query al buffer dei comandi. Si supponga che questo richiede circa 200 cicli.
GetData fa sì che il buffer dei comandi venga svuotato, forzando la transizione in modalità kernel. Si supponga che questo richiede circa 5000 cicli.
Il driver elabora quindi il lavoro associato a tutte e quattro le chiamate. Si supponga che il tempo del driver per elaborare SetTexture sia di circa 2964 cicli, DrawPrimitive è di circa 3600 cicli, Problema è di circa 200 cicli. Il tempo totale del driver per tutti e quattro i comandi è quindi di circa 6450 cicli.
Nota
Il driver richiede anche un po ' di tempo per vedere qual è lo stato della GPU. Poiché il lavoro della GPU è semplice, la GPU deve essere già eseguita. GetData restituirà S_OK in base alla probabilità che la GPU sia terminata.
Al termine del funzionamento del driver, la transizione in modalità utente restituisce il controllo al runtime. Il buffer dei comandi è ora vuoto. Si supponga che questo richiede circa 5000 cicli.
I numeri per GetData includono:
GetData = kernel-transition + driver work + user-transition
GetData = 5000 + 6450 + 5000
GetData = 16,450
driver work = SetTexture + DrawPrimitive + Issue =
driver work = 2964 + 3600 + 200 = 6450 cycles
Il meccanismo di query usato in combinazione con QueryPerformanceCounter misura tutto il lavoro della CPU. Questa operazione viene eseguita con una combinazione di marcatori di query e confronti dello stato delle query. Gli indicatori di query di avvio e arresto aggiunti al buffer dei comandi vengono usati per controllare la quantità di lavoro nel buffer. Attendendo che venga restituito il codice restituito corretto, la misurazione iniziale viene eseguita poco prima dell'avvio di una sequenza di rendering pulita e la misurazione dell'arresto viene eseguita subito dopo che il driver ha terminato il lavoro associato al contenuto del buffer dei comandi. In questo modo si acquisisce in modo efficace il lavoro della CPU eseguito dal runtime e dal driver.
Ora che si conoscono il buffer dei comandi e l'effetto che può avere sulla profilatura, è necessario sapere che esistono alcune altre condizioni che possono causare la svuotazione del buffer dei comandi da parte del runtime. È necessario prestare attenzione a queste sequenze di rendering. Alcune di queste condizioni sono in risposta alle chiamate API, altre sono in risposta alle modifiche delle risorse nel runtime. Una delle condizioni seguenti causerà una transizione in modalità:
- Quando uno dei metodi di blocco (Lock) viene chiamato su un buffer dei vertici, un buffer di indice o una trama (in determinate condizioni con determinati flag).
- Quando viene creato un buffer di vertici o un dispositivo, un buffer di indice o una trama.
- Quando un dispositivo o un vertex buffer, un buffer di indice o una trama vengono eliminati definitivamente dall'ultima versione.
- Quando viene chiamato ValidateDevice.
- Quando viene chiamato Present.
- Quando il buffer dei comandi si riempie.
- Quando viene chiamato GetData con D3DGETDATA_FLUSH.
Prestare attenzione a verificare queste condizioni nelle sequenze di rendering. Ogni volta che viene aggiunta una transizione in modalità, verranno aggiunti 10.000 cicli di lavoro del driver alle misurazioni di profilatura. Inoltre, il buffer dei comandi non viene ridimensionato in modo statico. Il runtime può modificare le dimensioni del buffer in risposta alla quantità di lavoro generata dall'applicazione. Si tratta di un'altra ottimizzazione dipendente da una sequenza di rendering.
Prestare quindi attenzione alle transizioni della modalità di controllo durante la profilatura. Il meccanismo di query offre un metodo affidabile per svuotare il buffer dei comandi in modo da poter controllare la tempistica della transizione in modalità, nonché la quantità di lavoro contenuta nel buffer. Tuttavia, anche questa tecnica può essere migliorata riducendo il tempo di transizione della modalità per renderla insignificante rispetto al risultato misurato.
Rendere grande la sequenza di rendering rispetto alla transizione in modalità
Nell'esempio precedente, l'opzione in modalità kernel e il commutatore in modalità utente utilizzano circa 10.000 cicli che non hanno nulla a che fare con il runtime e il funzionamento del driver. Poiché la transizione della modalità è incorporata nel sistema operativo, non può essere ridotta a zero. Per rendere irrilevante la transizione in modalità, la sequenza di rendering deve essere modificata in modo che il lavoro del driver e del runtime sia un ordine di grandezza maggiore rispetto ai commutatori in modalità. È possibile provare a eseguire una sottrazione per rimuovere le transizioni, ma ammortizzando il costo di una sequenza di rendering molto più grande è più affidabile.
La strategia per ridurre la transizione della modalità fino a quando non diventa irrilevante è aggiungere un ciclo alla sequenza di rendering. Ad esempio, esaminare i risultati della profilatura se viene aggiunto un ciclo che ripeterà la sequenza di rendering 1500 volte:
// Initialize the array with two textures, same size, same format
IDirect3DTexture* texArray[2];
CreateQuery(D3DQUERYTYPE_EVENT, pEvent);
pEvent->Issue(D3DISSUE_END);
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
LARGE_INTEGER start, stop;
// Now start counting because the video card is ready
QueryPerformanceCounter(&start);
// Add a loop to the render sequence
for(int i = 0; i < 1500; i++)
{
SetTexture(taxArray[i%2]);
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
pEvent->Issue(D3DISSUE_END);
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
QueryPerformanceCounter(&stop);
Esempio 4: Aggiungere un ciclo alla sequenza di rendering
Ecco i risultati misurati con QueryPerformanceCounter e QueryPerformanceFrequency:
| Variabile locale | Numero di Tic |
|---|---|
| Avvio | 1792998845000 |
| stop | 1792998847084 |
| Freq | 3579545 |
L'uso di QueryPerformanceCounter misura ora 2.840 tick. La conversione dei segni di graduazione in cicli è identica a quella già mostrata:
# ticks = (stop - start) = 1792998847084 - 1792998845000 = 2840 ticks
# cycles = machine speed * number of ticks / QPF
# 6,900,000 = 2 GHz * 2840 / 3,579,545
In altre parole, sono necessari circa 6,9 milioni di cicli in questo computer a 2 GHz per elaborare le 1500 chiamate nel ciclo di rendering. Tra i cicli di 6,9 milioni, la quantità di tempo nelle transizioni in modalità è di circa 10.000, quindi ora i risultati del profilo misurano quasi interamente il lavoro associato a SetTexture e DrawPrimitive.
Si noti che l'esempio di codice richiede una matrice di due trame. Per evitare un'ottimizzazione di runtime che rimuove SetTexture se imposta lo stesso puntatore a trama ogni volta che viene chiamato, usa semplicemente una matrice di due trame. In questo modo, ogni volta che si passa attraverso il ciclo, il puntatore di trama cambia e viene eseguito il lavoro completo associato a SetTexture . Assicurarsi che entrambe le trame siano le stesse dimensioni e formato, in modo che nessun altro stato cambierà quando la trama viene eseguita.
Ora hai una tecnica per la profilatura di Direct3D. Si basa sul contatore delle prestazioni elevate (QueryPerformanceCounter) per registrare il numero di tick necessari per elaborare il lavoro della CPU. Il lavoro è controllato attentamente per essere il runtime e il driver associato alle chiamate API usando il meccanismo di query. Una query fornisce due mezzi di controllo: prima di svuotare il buffer dei comandi prima dell'avvio della sequenza di rendering e in secondo luogo per restituire al termine del lavoro della GPU.
Finora, questo documento ha illustrato come profilare una sequenza di rendering. Ogni sequenza di rendering è stata abbastanza semplice, contenente una singola chiamata DrawPrimitive e una chiamata SetTexture. Questa operazione è stata eseguita per concentrarsi sul buffer dei comandi e sull'uso del meccanismo di query per controllarlo. Ecco un breve riepilogo di come profilare una sequenza di rendering arbitraria:
- Usare un contatore ad alte prestazioni, ad esempio QueryPerformanceCounter, per misurare il tempo necessario per elaborare ogni chiamata API. Usare QueryPerformanceFrequency e la frequenza di clock della CPU per convertirla nel numero di cicli cpu per ogni chiamata API.
- Ridurre al minimo la quantità di lavoro della GPU eseguendo il rendering di elenchi di triangoli, in cui ogni triangolo contiene un pixel.
- Usare il meccanismo di query per svuotare il buffer dei comandi prima della sequenza di rendering. Ciò garantisce che la profilatura acquisisca la quantità corretta di runtime e driver associati alla sequenza di rendering.
- Controllare la quantità di lavoro aggiunta al buffer dei comandi con marcatori di evento di query. Questa stessa query rileva quando la GPU termina il proprio lavoro. Poiché il lavoro della GPU è semplice, questo equivale praticamente a misurare quando il lavoro del driver viene completato.
Tutte queste tecniche vengono usate per profilare le modifiche dello stato. Supponendo di aver letto e compreso come controllare il buffer dei comandi e aver completato correttamente le misurazioni di base in DrawPrimitive, è possibile aggiungere modifiche di stato alle sequenze di rendering. Esistono alcuni problemi di profilatura aggiuntivi quando si aggiungono modifiche dello stato a una sequenza di rendering. Se si prevede di aggiungere modifiche di stato alle sequenze di rendering, assicurarsi di continuare nella sezione successiva.
Profilatura delle modifiche dello stato Direct3D
Direct3D usa molti stati di rendering per controllare quasi ogni aspetto della pipeline. Le API che causano modifiche dello stato includono qualsiasi funzione o metodo diverso dalle chiamate Draw*Primitive.
Le modifiche di stato sono difficili perché potrebbe non essere possibile visualizzare il costo di una modifica dello stato senza rendering. Questo è il risultato dell'algoritmo lazy usato dal driver e dalla GPU per rinviare il lavoro fino a quando non è assolutamente necessario. In generale, è necessario seguire questa procedura per misurare una singola modifica dello stato:
- Profilo DrawPrimitive per primo.
- Aggiungere una modifica dello stato alla sequenza di rendering e profilare la nuova sequenza.
- Sottrarre la differenza tra le due sequenze per ottenere il costo della modifica dello stato.
Naturalmente, tutto ciò che si è appreso sull'uso del meccanismo di query e l'inserimento della sequenza di rendering in un ciclo per negare il costo della transizione in modalità è ancora applicabile.
Profilatura di una modifica dello stato semplice
A partire da una sequenza di rendering che contiene DrawPrimitive, ecco la sequenza di codice per misurare il costo dell'aggiunta di SetTexture:
// Get the start counter value as shown in Example 4
// Initialize a texture array as shown in Example 4
IDirect3DTexture* texArray[2];
// Render sequence loop
for(int i = 0; i < 1500; i++)
{
SetTexture(0, texArray[i%2];
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
// Get the stop counter value as shown in Example 4
Esempio 5: Misurazione di una chiamata API di modifica dello stato
Si noti che il ciclo contiene due chiamate, SetTexture e DrawPrimitive. La sequenza di rendering esegue un ciclo di 1500 volte e genera risultati simili ai seguenti:
| Variabile locale | Numero di Tic |
|---|---|
| Avvio | 1792998860000 |
| stop | 1792998870260 |
| Freq | 3579545 |
La conversione dei segni di graduazione in cicli restituisce di nuovo:
# ticks = (stop - start) = 1792998870260 - 1792998860000 = 10,260 ticks
# cycles = machine speed * number of ticks / QPF
5,775,000 = 2 GHz * 10,260 / 3,579,545
Dividendo per il numero di iterazioni nel ciclo restituisce:
5,775,000 cycles / 1500 iterations = 3850 cycles for one iteration
Ogni iterazione del ciclo contiene una modifica dello stato e una chiamata di disegno. Sottraendo il risultato della sequenza di rendering DrawPrimitive:
3850 - 1100 = 2750 cycles for SetTexture
Questo è il numero medio di cicli da aggiungere SetTexture a questa sequenza di rendering. Questa stessa tecnica può essere applicata ad altre modifiche di stato.
Perché SetTexture viene chiamato modifica di stato semplice? Poiché lo stato impostato è vincolato in modo che la pipeline eseleva la stessa quantità di lavoro ogni volta che lo stato viene modificato. Vincolare entrambe le trame alla stessa dimensione e allo stesso formato garantisce la stessa quantità di lavoro per ogni chiamata SetTexture .
Profilatura di una modifica dello stato che deve essere attivata/disattivata
Esistono altre modifiche di stato che causano la modifica della quantità di lavoro eseguita dalla pipeline grafica per ogni iterazione del ciclo di rendering. Ad esempio, se z-testing è abilitato, ogni colore pixel aggiorna una destinazione di rendering solo dopo che il valore z del nuovo pixel viene testato sul valore z per il pixel esistente. Se z-testing è disabilitato, questo test per pixel non viene eseguito e l'output viene scritto molto più velocemente. L'abilitazione o la disabilitazione dello stato z-test modifica notevolmente la quantità di lavoro eseguita (dalla CPU e dalla GPU) durante il rendering.
SetRenderState richiede uno stato di rendering specifico e un valore di stato per abilitare o disabilitare z-testing. Il valore di stato specifico viene valutato in fase di esecuzione per determinare la quantità di lavoro necessaria. È difficile misurare questa modifica dello stato in un ciclo di rendering e precondire comunque lo stato della pipeline in modo che cambi. L'unica soluzione consiste nell'attivare o disattivare la modifica dello stato durante la sequenza di rendering.
Ad esempio, la tecnica di profilatura deve essere ripetuta due volte come segue:
- Iniziare profilando la sequenza di rendering DrawPrimitive. Chiamare questa linea di base.
- Profilare una seconda sequenza di rendering che attiva o disattiva la modifica dello stato. Il ciclo di sequenza di rendering contiene:
- Modifica dello stato per impostare lo stato in una condizione "false".
- DrawPrimitive esattamente come la sequenza originale.
- Modifica dello stato per impostare lo stato in una condizione "true".
- Secondo DrawPrimitive per forzare la realizzazione della seconda modifica dello stato.
- Trovare la differenza tra le due sequenze di rendering. A tale scopo, eseguire le operazioni seguenti:
- Moltiplicare la sequenza DrawPrimitive di base per 2 perché nella nuova sequenza sono presenti due chiamate DrawPrimitive.
- Sottrarre il risultato della nuova sequenza dalla sequenza originale.
- Dividere il risultato per 2 per ottenere il costo medio di entrambe le modifiche di stato "false" e "true".
Con la tecnica di ciclo usata nella sequenza di rendering, il costo della modifica dello stato della pipeline deve essere misurato attivando o disattivando lo stato da una condizione "true" a una condizione "false" e viceversa, per ogni iterazione nella sequenza di rendering. Il significato di "true" e "false" qui non sono letterali, questo significa semplicemente che lo stato deve essere impostato in condizioni opposte. In questo modo entrambe le modifiche di stato vengono misurate durante la profilatura. Naturalmente tutto ciò che si è appreso sull'uso del meccanismo di query e l'inserimento della sequenza di rendering in un ciclo per negare il costo della transizione in modalità è ancora applicabile.
Ecco ad esempio la sequenza di codice per misurare il costo di attivazione o disattivazione del test z:
// Get the start counter value as shown in Example 4
// Add a loop to the render sequence
for(int i = 0; i < 1500; i++)
{
// Precondition the pipeline state to the "false" condition
SetRenderState(D3DRS_ZENABLE, FALSE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 0)*3, 1);
// Set the pipeline state to the "true" condition
SetRenderState(D3DRS_ZENABLE, TRUE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 1)*3, 1);
}
// Get the stop counter value as shown in Example 4
Esempio 5: Misurazione di una modifica dello stato di attivazione/disattivazione
Il ciclo attiva/disattiva lo stato eseguendo due chiamate SetRenderState. La prima chiamata SetRenderState disabilita z-testing e la seconda SetRenderState abilita z-testing. Ogni SetRenderState è seguito da DrawPrimitive in modo che il lavoro associato alla modifica dello stato venga elaborato dal driver invece di impostare solo un bit dirty nel driver.
Questi numeri sono ragionevoli per questa sequenza di rendering:
| Variabile locale | Numero di tick |
|---|---|
| Avvio | 1792998845000 |
| stop | 1792998861740 |
| Freq | 3579545 |
La conversione dei segni di graduazione in cicli restituisce di nuovo:
# ticks = (stop - start) = 1792998861740 - 1792998845000 = 15,120 ticks
# cycles = machine speed * number of ticks / QPF
9,300,000 = 2 GHz * 16,740 / 3,579,545
Dividendo per il numero di iterazioni nel ciclo restituisce:
9,300,000 cycles / 1500 iterations = 6200 cycles for one iteration
Ogni iterazione del ciclo contiene due modifiche di stato e due chiamate di disegno. Sottraendo le chiamate di disegno (presupponendo 1100 cicli) lascia:
6200 - 1100 - 1100 = 4000 cycles for both state changes
Questo è il numero medio di cicli per entrambi i cambiamenti di stato, quindi il tempo medio per ogni modifica dello stato è:
4000 / 2 = 2000 cycles for each state change
Di conseguenza, il numero medio di cicli per abilitare o disabilitare z-testing è di 2000 cicli. Vale la pena notare che QueryPerformanceCounter sta misurando z-enable metà del tempo e z-disable metà del tempo. Questa tecnica misura effettivamente la media di entrambe le variazioni di stato. In altre parole, si misura il tempo per attivare o disattivare uno stato. Usando questa tecnica, non è possibile sapere se i tempi di abilitazione e disabilitazione sono equivalenti perché è stata misurata la media di entrambi. Tuttavia, questo è un numero ragionevole da usare quando si esegue il budget di uno stato di attivazione/disattivazione come applicazione che causa questa modifica dello stato può farlo solo attivando o disattivando questo stato.
Ora è possibile applicare queste tecniche e profilarne tutte le modifiche di stato desiderate, giusto? Non esattamente. È comunque necessario prestare attenzione alle ottimizzazioni progettate per ridurre la quantità di lavoro che deve essere eseguita. Esistono due tipi di ottimizzazioni da tenere presenti durante la progettazione delle sequenze di rendering.
Prestare attenzione alle ottimizzazioni delle modifiche di stato
La sezione precedente illustra come profilare entrambi i tipi di modifiche di stato: una semplice modifica dello stato vincolata a generare la stessa quantità di lavoro per ogni iterazione e una modifica dello stato di attivazione/disattivazione che modifica notevolmente la quantità di lavoro svolto. Cosa accade se si prende la sequenza di rendering precedente e si aggiunge un'altra modifica dello stato? Ad esempio, questo esempio accetta la sequenza di rendering z-enable> e aggiunge un confronto z-func:
// Add a loop to the render sequence
for(int i = 0; i < 1500; i++)
{
// Precondition the pipeline state to the opposite condition
SetRenderState(D3DRS_ZFUNC, D3DCMP_NEVER);
// Precondition the pipeline state to the opposite condition
SetRenderState(D3DRS_ZENABLE, FALSE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 0)*3, 1);
// Now set the state change you want to measure
SetRenderState(D3DRS_ZFUNC, D3DCMP_ALWAYS);
// Now set the state change you want to measure
SetRenderState(D3DRS_ZENABLE, TRUE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 1)*3, 1);
}
Lo stato z-func imposta il livello di confronto durante la scrittura nel buffer z (tra il valore z di un pixel corrente con il valore z di un pixel nel buffer di profondità). D3DCMP_NEVER disattiva il confronto z-testing mentre D3DCMP_ALWAYS imposta l'esecuzione del confronto ogni volta che viene eseguito z-testing.
La profilatura di una di queste modifiche di stato in una sequenza di rendering con DrawPrimitive genera risultati simili ai seguenti:
| Modifica stato singolo | Numero medio di cicli |
|---|---|
| solo D3DRS_ZENABLE | 2000 |
oppure
| Modifica stato singolo | Numero medio di cicli |
|---|---|
| solo D3DRS_ZFUNC | 600 |
Tuttavia, se si profila sia D3DRS_ZENABLE che D3DRS_ZFUNC nella stessa sequenza di rendering, è possibile visualizzare risultati simili ai seguenti:
| Entrambe le modifiche di stato | Numero medio di cicli |
|---|---|
| D3DRS_ZENABLE + D3DRS_ZFUNC | 2000 |
È possibile prevedere che il risultato sia la somma di 2000 e 600 cicli (o 2600) perché il driver esegue tutte le operazioni associate all'impostazione di entrambi gli stati di rendering. La media è invece di 2000 cicli.
Questo risultato riflette un'ottimizzazione della modifica dello stato implementata nel runtime, nel driver o nella GPU. In questo caso, il driver potrebbe visualizzare il primo SetRenderState e impostare uno stato dirty che posticiperebbe il lavoro fino a un secondo momento. Quando il driver vede il secondo SetRenderState, lo stesso stato dirty potrebbe essere impostato in modo ridondante e lo stesso lavoro verrebbe posticipato ancora una volta. Quando viene chiamato DrawPrimitive , il lavoro associato allo stato dirty viene infine elaborato. Il driver esegue il lavoro una sola volta, il che significa che le prime due modifiche di stato vengono effettivamente consolidate dal driver. Analogamente, le modifiche apportate al terzo e al quarto stato vengono effettivamente consolidate dal driver in un unico stato quando viene chiamato il secondo DrawPrimitive . Il risultato netto è che il driver e la GPU elaborano una singola modifica di stato per ogni chiamata di disegno.
Questo è un buon esempio di ottimizzazione del driver dipendente dalla sequenza. Il driver ha posticipato il lavoro due volte impostando uno stato dirty e quindi ha eseguito il lavoro una volta per cancellare lo stato dirty. Questo è un buon esempio del tipo di miglioramento dell'efficienza che può avvenire quando il lavoro viene posticipato fino a quando non è assolutamente necessario.
Come si sa quali modifiche di stato impostano uno stato dirty internamente e quindi posticipano il lavoro fino a un secondo momento? Solo eseguendo il test delle sequenze di rendering (o parlando con i writer driver). I driver vengono aggiornati e migliorati periodicamente, in modo che l'elenco delle ottimizzazioni non sia statico. C'è un solo modo per sapere assolutamente quali costi di modifica dello stato in una determinata sequenza di rendering, su un determinato set di hardware; e questo per misurarlo.
Prestare attenzione alle ottimizzazioni DrawPrimitive
Oltre alle ottimizzazioni delle modifiche di stato, il runtime tenterà di ottimizzare il numero di chiamate di disegno che il driver deve elaborare. Si consideri, ad esempio, di nuovo le chiamate di disegno:
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 3); // Draw 3 primitives, vertices 0 - 8
DrawPrimitive(D3DPT_TRIANGLELIST, 9, 4); // Draw 4 primitives, vertices 9 - 20
Esempio 5a: Due chiamate di disegno
Questa sequenza contiene due chiamate di disegno, che il runtime si consolida in una singola chiamata equivalente a:
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 7); // Draw 7 primitives, vertices 0 - 20
Esempio 5b: una singola chiamata di disegno concatenata
Il runtime concatena entrambe queste chiamate di disegno specifiche in una singola chiamata, riducendo il lavoro del driver del 50% perché il driver dovrà ora elaborare una sola chiamata di disegno.
In generale, il runtime concatena due o più chiamate DrawPrimitive back-to-back quando:
- Il tipo primitivo è un elenco di triangoli (D3DPT_TRIANGLELIST).
- Ogni chiamata DrawPrimitive successiva deve fare riferimento a vertici consecutivi all'interno del vertex buffer.
Analogamente, le condizioni corrette per la concatenazione di due o più chiamate back-to-back DrawIndexedPrimitive sono:
- Il tipo primitivo è un elenco di triangoli (D3DPT_TRIANGLELIST).
- Ogni chiamata DrawIndexedPrimitive successiva deve fare riferimento a indici consecutivi consecutivi all'interno del buffer di indice.
- Ogni chiamata DrawIndexedPrimitive successiva deve usare lo stesso valore per BaseVertexIndex.
Per impedire la concatenazione durante la profilatura, modificare la sequenza di rendering in modo che il tipo primitivo non sia un elenco di triangoli o modificare la sequenza di rendering in modo che non siano presenti chiamate back-to-back che utilizzano vertici consecutivi (o indici). In particolare, il runtime concatena anche le chiamate di disegno che soddisfano entrambe le condizioni seguenti:
- Quando la chiamata precedente è DrawPrimitive, se la chiamata di disegno successiva:
- usa un elenco di triangoli, AND
- specifica startVertex = precedente StartVertex + PrimitiveCount precedente * 3
- Quando si usa DrawIndexedPrimitive, se la chiamata di disegno successiva:
- usa un elenco di triangoli, AND
- specifica StartIndex = previous StartIndex + previous PrimitiveCount * 3, AND
- specifica BaseVertexIndex = baseVertexIndex precedente
Ecco un esempio più sottile di concatenazione di chiamate di disegno che è facile da ignorare quando si esegue la profilatura. Si supponga che la sequenza di rendering sia simile alla seguente:
for(int i = 0; i < 1500; i++)
{
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
Esempio 5c: modifica di uno stato e una chiamata di disegno
Il ciclo scorre fino a 1500 triangoli, impostando una trama e disegnando ogni triangolo. Questo ciclo di rendering richiede circa 2750 cicli per SetTexture e 1100 cicli per DrawPrimitive, come illustrato nelle sezioni precedenti. Si potrebbe prevedere in modo intuitivo che lo spostamento di SetTexture all'esterno del ciclo di rendering dovrebbe ridurre la quantità di lavoro svolto dal driver di 1500 * 2750 cicli, ovvero la quantità di lavoro associata alla chiamata a SetTexture 1500 volte. Il frammento di codice sarà simile al seguente:
SetTexture(...); // Set the state outside the loop
for(int i = 0; i < 1500; i++)
{
// SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
Esempio 5d: Esempio 5c con modifica dello stato all'esterno del ciclo
Lo spostamento di SetTexture all'esterno del ciclo di rendering riduce la quantità di lavoro associata a SetTexture perché viene chiamata una sola volta anziché 1500 volte. Un effetto secondario meno ovvio è che il lavoro per DrawPrimitive è ridotto anche da 1500 chiamate a 1 chiamata perché tutte le condizioni per la concatenazione delle chiamate di disegno sono soddisfatte. Quando viene elaborata la sequenza di rendering, il runtime elabora 1500 chiamate in una singola chiamata al driver. Spostando questa riga di codice, la quantità di lavoro del driver è stata ridotta drasticamente:
total work done = runtime + driver work
Example 5c: with SetTexture in the loop:
runtime work = 1500 SetTextures + 1500 DrawPrimitives
driver work = 1500 SetTextures + 1500 DrawPrimitives
Example 5d: with SetTexture outside of the loop:
runtime work = 1 SetTexture + 1 DrawPrimitive + 1499 Concatenated DrawPrimitives
driver work = 1 SetTexture + 1 DrawPrimitive
Questi risultati sono del tutto corretti, ma sono molto fuorvianti nel contesto della domanda originale. L'ottimizzazione delle chiamate di disegno ha causato la riduzione significativa della quantità di lavoro del driver. Si tratta di un problema comune quando si esegue la profilatura personalizzata. Quando si eliminano le chiamate da una sequenza di rendering, prestare attenzione a evitare la concatenazione delle chiamate di disegno. In effetti, questo scenario è un potente esempio della quantità di miglioramento delle prestazioni del driver possibili da questa ottimizzazione del runtime.
Ora si sa come misurare le modifiche dello stato. Iniziare profilando DrawPrimitive. Aggiungere quindi ogni modifica di stato aggiuntiva alla sequenza (in alcuni casi aggiungendo una chiamata e in altri casi aggiungendo due chiamate) e misurare la differenza tra le due sequenze. È possibile convertire i risultati in tick o cicli o tempo. Analogamente alla misurazione delle sequenze di rendering con QueryPerformanceCounter, la misurazione delle modifiche di stato individuali si basa sul meccanismo di query per controllare il buffer dei comandi e l'inserimento delle modifiche di stato in un ciclo per ridurre al minimo l'impatto delle transizioni in modalità. Questa tecnica misura il costo di attivazione/disattivazione di uno stato, poiché il profiler restituisce la media di abilitazione e disabilitazione dello stato.
Con questa funzionalità, è possibile iniziare a generare sequenze di rendering arbitrarie e misurare accuratamente il funzionamento del runtime e del driver associato. I numeri possono quindi essere usati per rispondere a domande di budget come "quante più di queste chiamate" possono essere effettuate nella sequenza di rendering mantenendo comunque una frequenza di fotogrammi ragionevole, presupponendo scenari limitati dalla CPU.
Riepilogo
Questo documento illustra come controllare il buffer dei comandi in modo che le singole chiamate possano essere profilate in modo accurato. I numeri di profilatura possono essere generati in tick, cicli o tempo assoluto. Rappresentano la quantità di lavoro di runtime e driver associati a ogni chiamata API.
Iniziare profilando una chiamata Draw*Primitive in una sequenza di rendering. Ricordare di:
- Usare QueryPerformanceCounter per misurare il numero di tick per ogni chiamata API. Usare QueryPerformanceFrequency per convertire i risultati in cicli o tempo, se si desidera.
- Usare il meccanismo di query per svuotare il buffer dei comandi prima dell'avvio.
- Includere la sequenza di rendering in un ciclo per ridurre al minimo l'impatto della transizione in modalità.
- Usare il meccanismo di query per misurare quando la GPU ha completato il lavoro.
- Prestare attenzione alla concatenazione di runtime che avrà un impatto significativo sulla quantità di lavoro svolto.
In questo modo è possibile ottenere prestazioni di base per DrawPrimitive che possono essere usate per la compilazione. Per profilare una modifica dello stato, seguire questi suggerimenti aggiuntivi:
- Aggiungere la modifica dello stato a un profilo di sequenza di rendering noto nella nuova sequenza. Poiché il test viene eseguito in un ciclo, è necessario impostare lo stato due volte in valori opposti, ad esempio abilitare e disabilitare per istanza.
- Confrontare la differenza nei tempi di ciclo tra le due sequenze.
- Per le modifiche di stato che modificano significativamente la pipeline (ad esempio SetTexture), sottrarre la differenza tra le due sequenze per ottenere il tempo per la modifica dello stato.
- Per le modifiche dello stato che modificano significativamente la pipeline (e quindi richiedono l'attivazione o disattivazione di stati come SetRenderState), sottrarre la differenza tra le sequenze di rendering e dividere per 2. Verrà generato il numero medio di cicli per ogni modifica dello stato.
Prestare tuttavia attenzione alle ottimizzazioni che causano risultati imprevisti durante la profilatura. Le ottimizzazioni delle modifiche di stato possono impostare stati dirty che causano il rinvio del lavoro. Ciò può causare risultati del profilo che non sono così intuitivi come previsto. Le chiamate di disegno concatenate ridurranno drasticamente il lavoro del conducente che può portare a conclusioni fuorvianti. Le sequenze di rendering pianificate con attenzione vengono usate per impedire che si verifichino modifiche di stato e disegnare concatenazioni di chiamate. Il trucco consiste nel impedire che le ottimizzazioni si verifichino durante la profilatura in modo che i numeri generati siano numeri di budget ragionevoli.
Nota
Duplicare questa strategia di profilatura in un'applicazione senza il meccanismo di query è più difficile. Prima di Direct3D 9 l'unico modo prevedibile per svuotare il buffer dei comandi consiste nel bloccare una superficie attiva (ad esempio una destinazione di rendering) per attendere che la GPU non sia inattiva. Ciò è dovuto al fatto che il blocco di una superficie forza il runtime a svuotare il buffer dei comandi nel caso in cui siano presenti comandi di rendering nel buffer che devono aggiornare la superficie prima che venga bloccata, oltre ad attendere il completamento della GPU. Questa tecnica è funzionale, anche se è più invadente che l'uso del meccanismo di query introdotto in Direct3D 9.
Appendice
I numeri in questa tabella sono un intervallo di approssimazioni per la quantità di operazioni di runtime e driver associate a ognuna di queste modifiche di stato. Le approssimazioni si basano sulle misurazioni effettive effettuate sui conducenti utilizzando le tecniche illustrate nel documento. Questi numeri sono stati generati usando il runtime direct3D 9 e sono dipendenti dal driver.
Le tecniche descritte in questo documento sono progettate per misurare il funzionamento del runtime e del driver. In generale, è poco pratico fornire risultati che corrispondono alle prestazioni della CPU e della GPU in ogni applicazione, in quanto ciò richiederebbe una matrice completa di sequenze di rendering. Inoltre, è particolarmente difficile eseguire il benchmark delle prestazioni della GPU perché dipende molto dalla configurazione dello stato nella pipeline prima della sequenza di rendering. Ad esempio, l'abilitazione della fusione alfa non influisce sulla quantità di lavoro della CPU necessaria, ma può avere un grande impatto sulla quantità di lavoro eseguita dalla GPU. Pertanto, le tecniche di questo documento vincolano il lavoro della GPU alla quantità minima possibile limitando la quantità di dati di cui è necessario eseguire il rendering. Ciò significa che i numeri nella tabella corrisponderanno più strettamente ai risultati ottenuti dalle applicazioni limitate dalla CPU (anziché da un'applicazione limitata dalla GPU).
È consigliabile usare le tecniche presentate per coprire gli scenari e le configurazioni più importanti. I valori nella tabella possono essere usati per confrontare i numeri generati. Poiché ogni driver varia, l'unico modo per generare i numeri effettivi che si noterà è generare risultati di profilatura usando gli scenari.
| Chiamata API | Numero medio di cicli |
|---|---|
| SetVertexDeclaration | 6500 - 11250 |
| SetFVF | 6400 - 11200 |
| SetVertexShader | 3000 - 12100 |
| SetPixelShader | 6300 - 7000 |
| SPECULARENABLE | 1900 - 11200 |
| SetRenderTarget | 6000 - 6250 |
| SetPixelShaderConstant (1 costante) | 1500 - 9000 |
| NORMALIZENORMALS | 2200 - 8100 |
| LightEnable | 1300 - 9000 |
| SetStreamSource | 3700 - 5800 |
| ILLUMINAZIONE | 1700 - 7500 |
| DIFFU edizione Standard MATERIALSOURCE | 900 - 8300 |
| AMBIENTMATERIALSOURCE | 900 - 8200 |
| COLORVERTEX | 800 - 7800 |
| SetLight | 2200 - 5100 |
| SetTransform | 3200 - 3750 |
| SetIndices | 900 - 5600 |
| AMBIENTALE | 1150 - 4800 |
| SetTexture | 2500 - 3100 |
| SPECULARMATERIALSOURCE | 900 - 4600 |
| EMISSIVEMATERIALSOURCE | 900 - 4500 |
| SetMaterial | 1000 - 3700 |
| ZENABLE | 700 - 3900 |
| WRAP0 | 1600 - 2700 |
| MINFILTER | 1700 - 2500 |
| MAGFILTER | 1700 - 2400 |
| SetVertexShaderConstant (1 costante) | 1000 - 2700 |
| CHIP | 1500 - 2100 |
| COLORARG2 | 1300 - 2000 |
| COLORARG1 | 1300 - 1980 |
| CULLMODE | 500 - 2570 |
| RITAGLIO | 500 - 2550 |
| DrawIndexedPrimitive | 1200 - 1400 |
| ADDRESSV | 1090 - 1500 |
| ADDRESSU | 1070 - 1500 |
| DrawPrimitive | 1050 - 1150 |
| SRGBTEXTURE | 150 - 1500 |
| STENCILMASK | 570 - 700 |
| STENCILZFAIL | 500 - 800 |
| STENCILREF | 550 - 700 |
| ALPHABLENDENABLE | 550 - 700 |
| STENCILFUNC | 560 - 680 |
| STENCILWRITEMASK | 520 - 700 |
| STENCILFAIL | 500 - 750 |
| ZFUNC | 510 - 700 |
| ZWRIT edizione Enterprise NABLE | 520 - 680 |
| STENCILENABLE | 540 - 650 |
| STENCILPASS | 560 - 630 |
| SRCBLEND | 500 - 685 |
| Two_Sided_StencilMODE | 450 - 590 |
| ALPHATESTENABLE | 470 - 525 |
| ALPHAREF | 460 - 530 |
| ALPHAFUNC | 450 - 540 |
| DESTBLEND | 475 - 510 |
| COLORWRIT edizione Enterprise NABLE | 465 - 515 |
| CCW_STENCILFAIL | 340 - 560 |
| CCW_STENCILPASS | 340 - 545 |
| CCW_STENCILZFAIL | 330 - 495 |
| SCISSORTESTENABLE | 375 - 440 |
| CCW_STENCILFUNC | 250 - 480 |
| SetScissorRect | 150 - 340 |
Argomenti correlati
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per