Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Un'operazione di clonazione di blocchi indica al file system di copiare un intervallo di byte di file per conto di un'applicazione. Il file di destinazione può essere uguale o diverso dal file di origine.
Un file system gestisce i mapping di cluster ed extent e può riuscire a eseguire la copia modificando i mapping dal numero di cluster virtuale (VCN) al numero di cluster logico (LCN) come operazione di metadati a basso costo, anziché leggere e scrivere i dati effettivi del file. In questo modo la copia può essere completata più velocemente e genera meno operazioni di I/O nella risorsa di archiviazione sottostante. Inoltre, più file possono ora condividere cluster logici dopo il clone del blocco, risparmiando capacità non archiviando cluster identici più volte su disco.
Un'operazione di clonazione di blocchi non interrompe l'isolamento fornito tra i file. Al termine della clonazione del blocco, le modifiche apportate al file di origine non si riflettono nella destinazione, né viceversa.
La clonazione di blocchi è disponibile solo nel tipo di file system ReFS a partire da Windows Server 2016. A partire dall'aggiornamento di Windows 11 Moment 5 (KB5034848) e dalle versioni successive delle build client Windows e Windows Server, la clonazione dei blocchi viene eseguita in modo nativo nelle operazioni di copia di Windows supportate.
Clonazione di blocchi in ReFS
A partire da Windows Server 2016, ReFS implementa la clonazione dei blocchi eseguendo il mapping dei cluster logici (ovvero posizioni fisiche in un volume) dall'area di origine all'area di destinazione. Quindi usa un meccanismo di copia alla scrittura per garantire l'isolamento tra tali aree. Le aree di origine e di destinazione possono trovarsi nello stesso file o in file diversi.
Questa implementazione richiede che gli offset del file iniziale e finale siano allineati ai limiti del cluster. In ReFS a partire da Windows Server 2016 i cluster hanno dimensioni di 4 KB per impostazione predefinita, ma facoltativamente possono essere impostati su 64 KB. Le dimensioni del cluster sono un set di parametri a livello di volume in fase di formato.
Implicazioni relative alle dimensioni e alle prestazioni del cluster
Le dimensioni del cluster di un volume ReFS influiscono direttamente sul comportamento di clonazione dei blocchi e sulle caratteristiche delle prestazioni:
- Dimensioni predefinite del cluster: 4 KB (scelta consigliata per la maggior parte dei carichi di lavoro)
- Dimensioni del cluster alternative: 64 KB (appropriato per carichi di lavoro di I/O sequenziali di grandi dimensioni)
Le dimensioni del cluster determinano la granularità in base alla quale si verificano operazioni di clonazione e copia su scrittura. Quando viene eseguita una scrittura su una regione di file che condivide cluster con un altro file (dopo un clone di blocco), ReFS utilizza un meccanismo di allocazione su scrittura che opera a livello di cluster.
- Solo il cluster modificato viene duplicato e scritto in una nuova posizione fisica
- I cluster non modificati all'interno della stessa area rimangono condivisi
- Questo comportamento si applica indipendentemente dal fatto che la clonazione dei blocchi sia stata avviata in modo esplicito tramite FSCTL_DUPLICATE_EXTENTS_TO_FILE o automaticamente dal sistema (Windows 11 Moment 5 e versioni successive)
Considerazioni sulle prestazioni
La scelta delle dimensioni del cluster ha implicazioni importanti per le prestazioni e il consumo di spazio:
- Cluster da 4 KB: offrire una migliore efficienza dello spazio per i carichi di lavoro con scritture casuali di piccole dimensioni (intervallo da KB a MB), perché solo 4 KB vengono duplicati per ogni cluster modificato. Tuttavia, ciò può comportare operazioni di copia su scrittura più frequenti.
- Cluster da 64 KB: ridurre il sovraccarico dei metadati e migliorare le prestazioni di I/O sequenziali, ma può comportare la duplicazione di fino a 64 KB per ogni scrittura in un'area condivisa, anche se la scrittura è inferiore a 64 KB.
Le dimensioni del cluster sono determinate in fase di formattazione e non possono essere modificate senza riformattare il volume. Per controllare le dimensioni correnti del cluster di un volume ReFS, usare il comando seguente:
fsutil fsinfo refsinfo <volume>
Per i volumi formattati automaticamente da Windows,ad esempio quando la clonazione di blocchi è abilitata per impostazione predefinita, il sistema usa le dimensioni predefinite del cluster di 4 KB, a meno che non siano configurate in modo esplicito durante la creazione del volume.
Restrizioni e osservazioni
- Le aree di origine e di destinazione devono iniziare e terminare in corrispondenza di un limite del cluster.
- L'area clonata deve avere una lunghezza inferiore a 4 GB.
- L'area di destinazione non deve estendersi oltre la fine del file. Se l'applicazione vuole estendere la destinazione con dati clonati, deve prima richiamare SetEndOfFile.
- Se le aree di origine e di destinazione si trovano nello stesso file, non devono sovrapporsi. L'applicazione può continuare suddividendo l'operazione di clonazione del blocco in più cloni di blocchi che non si sovrappongono più.
- I file di origine e di destinazione devono trovarsi nello stesso volume ReFS.
- I file di origine e di destinazione devono avere la stessa impostazione Dei flussi di integrità , ovvero i flussi di integrità devono essere abilitati in entrambi i file o disabilitati in entrambi i file.
- Se il file di origine è di tipo sparse, anche il file di destinazione deve essere di tipo sparse.
- L'operazione di clonazione del blocco interromperà i blocchi opportunistici condivisi (noti anche come blocchi opportunistici di livello 2).
- Il volume ReFS deve essere stato formattato con Windows Server 2016 o versione successiva e se windows Failover Clustering è in uso, il livello di funzionalità Clustering deve essere Windows Server 2016 o versione successiva in fase di formato.
Esempio
Si supponga di avere due file, X e Y, in cui ogni file è composto da 3 aree distinte. Ogni regione del file è memorizzata in una regione distinta del volume. Il file system archivia le informazioni a cui fanno riferimento ognuna di queste aree del volume in un'area file:
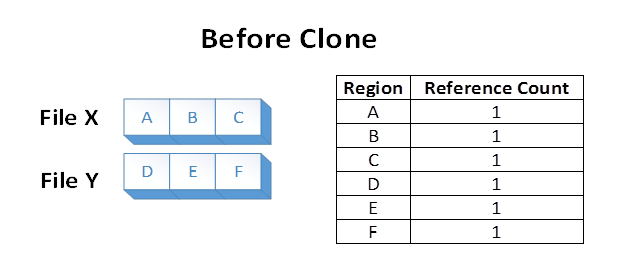
Si supponga ora che un'applicazione esegue un'operazione di clonazione di blocchi dal File X, sulle regioni del file A e B, su File Y all'offset dove si trova attualmente E. Il seguente stato del file system risulterà:
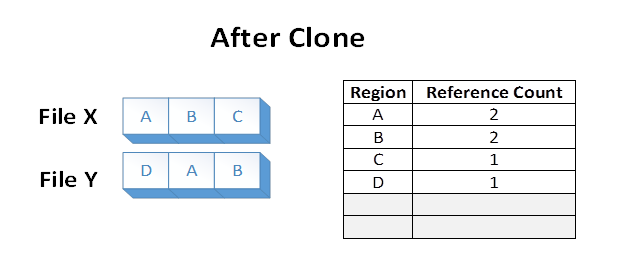
I dati nelle aree A e B sono stati effettivamente duplicati da File X a File Y modificando i mapping VCN a LCN all'interno del volume ReFS. Gli extent del disco che supportano le aree A e B non sono stati letti, né sono stati sovrascritti gli extent del disco che supportano le vecchie aree E e F durante l'operazione.
I file X e Y ora condividono cluster logici su disco. Ciò si riflette nei conteggi dei riferimenti visualizzati nella tabella. La condivisione comporta un consumo di capacità del volume inferiore rispetto a se le aree A e B sono state duplicate nel volume sottostante.
Si supponga ora che l'applicazione sovrascriva l'area A in File X. ReFS crea una copia duplicata di A, che ora chiameremo G. ReFS, quindi esegue il mapping di G in File X e applica la modifica. In questo modo si garantisce che l'isolamento tra i file venga mantenuto. I conteggi dei riferimenti vengono aggiornati in modo appropriato:
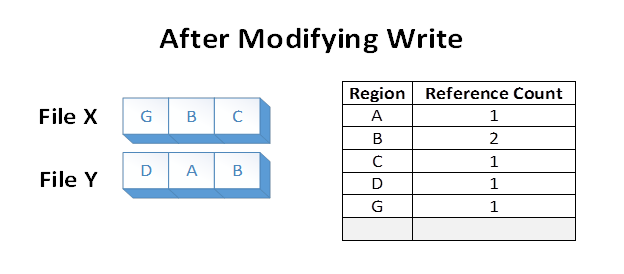
Dopo la modifica di scrittura, la regione B è ancora condivisa su disco. Si noti che se l'area A fosse più grande di un cluster, solo il cluster modificato sarebbe stato duplicato e la parte rimanente sarebbe rimasta condivisa.
Comportamento di Copia al Momento della Scrittura
Il meccanismo di allocazione alla scrittura opera a livello di cluster, che ha implicazioni importanti per le prestazioni e il consumo di spazio:
- Scrive dimensioni inferiori alla dimensione del cluster: una scrittura di qualsiasi dimensione in un cluster condiviso (anche 1 byte) provoca la duplicazione dell'intero cluster. Con le dimensioni predefinite del cluster da 4 KB, una scrittura da 1 KB in un'area condivisa comporta la copia di 4 KB.
- Scritture che si estendono su più cluster: se una scrittura si estende su più cluster, vengono duplicati solo i cluster modificati. Ad esempio, un'operazione di scrittura da 8 KB con cluster da 4 KB vengono duplicati 2 cluster (per un totale di 8 KB), mentre la stessa operazione di scrittura da 8 KB con cluster da 64 KB viene duplicato 1 cluster (per un totale di 64 KB).
- Scritture sequenziali di grandi dimensioni: per i carichi di lavoro che modificano spesso aree contigue di grandi dimensioni dopo la clonazione, dimensioni del cluster maggiori (64 KB) possono ridurre il sovraccarico riducendo al minimo il numero di operazioni di copia su scrittura.
Questa granularità a livello di cluster si applica a tutte le scritture dopo la clonazione di blocchi, inclusi gli scenari in cui Windows 11 Moment 5 e versioni successive eseguono automaticamente la clonazione dei blocchi durante le operazioni di copia.