Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Tradizionalmente, l'esecuzione di un sistema monolitico in più computer significava suddividere il sistema in componenti client e server separati. In questi sistemi, il componente client ha gestito l'interfaccia utente e il server ha fornito l'elaborazione back-end, ad esempio l'accesso al database, la stampa e così via. Man mano che i computer si sono moltiplicati, sono diminuiti i costi e sono diventati connessi da reti di larghezza di banda sempre più elevate, la suddivisione dei sistemi software in più componenti è diventata più conveniente, con ogni componente in esecuzione in un computer diverso e l'esecuzione di una funzione specializzata. Questo approccio semplificava lo sviluppo, la gestione, l'amministrazione e spesso migliorava le prestazioni e l'affidabilità, poiché l'errore in un computer non disabilitava necessariamente l'intero sistema.
In molti casi il sistema appare al client come un cloud opaco che esegue le operazioni necessarie, anche se il sistema distribuito è composto da singoli nodi, come illustrato nella figura seguente.
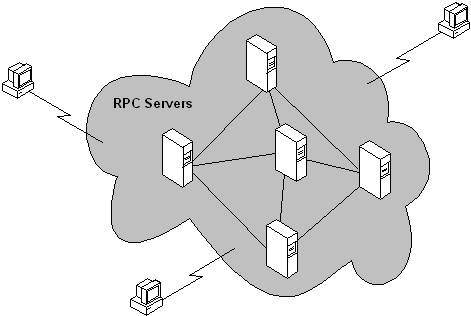
L'opacità del cloud viene mantenuta perché le operazioni di elaborazione vengono richiamate per conto del client. Di conseguenza, i client possono individuare un computer (un nodo ) all'interno del cloud e richiedere una determinata operazione; durante l'esecuzione dell'operazione, tale computer può richiamare funzionalità su altri computer all'interno del cloud senza esporre i passaggi aggiuntivi, o il computer in cui sono stati eseguiti, al client.
Con questo paradigma, i meccanismi di un sistema distribuito, simile al cloud, possono essere suddivisi in molti singoli scambi di pacchetti o conversazioni tra singoli nodi.
I sistemi client-server tradizionali hanno due nodi con ruoli e responsabilità predefiniti. I sistemi distribuiti moderni possono avere più di due nodi e i relativi ruoli sono spesso dinamici. In una conversazione un nodo può essere un client, mentre in un'altra conversazione il nodo può essere il server. In molti casi, il consumatore finale della funzionalità esposta è un cliente con un utente seduto davanti a una tastiera, guardando l'output. In altri casi, le funzioni di sistema distribuite vengono eseguite automaticamente, eseguendo operazioni in background.
Il sistema distribuito potrebbe non avere client e server dedicati per ogni particolare scambio di pacchetti, ma è importante ricordare che è presente un chiamante (o iniziatore, uno dei quali viene spesso definito client). C'è anche il destinatario della chiamata (spesso definito server). Non è necessario disporre di scambi di pacchetti bidirezionali nel formato request-reply di un sistema distribuito; spesso i messaggi vengono inviati solo in un modo.