Mosaic AI ベクトル検索
この記事では、Databricks のベクトル データベース ソリューションである Mosaic AI ベクトル検索について、その概要と仕組みなどを説明します。
Mosaic AI ベクトル検索とは
Mosaic AI ベクトル検索は、Databricks Data Intelligence プラットフォームに組み込まれ、そのガバナンスおよび生産性ツールと統合されたベクトル データベースです。 ベクトル データベースは、埋め込みを保存および取得するために最適化されたデータベースです。 埋め込みとは、データ (通常はテキストまたは画像データ) のセマンティック コンテンツの数学的表現です。 埋め込みは大規模言語モデルによって生成され、互いに類似したドキュメントまたは画像の検索に依存する、多くの GenAI アプリケーションの重要なコンポーネントです。 たとえば、RAG システム、レコメンダー システム、画像およびビデオ認識などがあります。
Mosaic AI ベクトル検索では、Delta テーブルからベクトル検索インデックスを作成します。 そのインデックスには、メタデータを含む埋め込みデータが含まれます。 それから、REST API を使用してそのインデックスにクエリを実行し、最も類似したベクトルを特定して、関連付けられているドキュメントを返すことができます。 基になる Delta テーブルが更新された場合に、自動的に同期するようにそのインデックスを構成することができます。
モザイク AI ベクター検索では、次の機能がサポートされます。
- ハイブリッド キーワードと類似性の検索。
- フィルター処理。
- ベクター検索エンドポイントを管理するためのアクセス制御リスト (ACL)。
- 選択した列のみを同期します。
- 生成された埋め込みを保存して同期します。
モザイク AI ベクター検索のしくみ
Mosaic AI ベクトル検索では、近似ニアレストネイバー探索に Hierarchical Navigable Small World (HNSW) アルゴリズムを使用し、埋め込みベクトルの類似性を測定するために L2 距離による距離メトリックを使用します。 コサイン類似度を使用したい場合は、データポイント埋め込みをベクトル検索にフィードする前に正規化する必要があります。 データ ポイントが正規化されると、L2 距離によって生成されるランク付けは、コサイン類似度によって生成されるランク付けと同じになります。
Mosaic AI ベクトル検索では、ベクトルベースの埋め込み検索と従来のキーワードベースの検索手法を組み合わせたハイブリッド キーワード類似性検索もサポートされています。 この手法は、クエリ内の正確な単語と一致させると同時に、ベクトルベースの類似性検索を使用して、クエリのセマンティック リレーションシップとコンテキストをキャプチャします。
ハイブリッド キーワード類似性検索では、これら 2 つの手法を統合することで、正確なキーワードだけでなく、概念的に似ているものも含まれるドキュメントを取得し、より包括的で関連性の高い検索結果を提供します。 この方法は、ソース データに純粋な類似性検索に適していない SKU や識別子などの一意のキーワードを含まれる RAG アプリケーションで特に便利です。
API の詳細については、Python SDK リファレンスと「ベクトル検索エンドポイントにクエリを実行する」を参照してください。
類似性検索の計算
類似性検索の計算では、次の式を使用します。
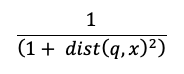
ここで dist は、以下のようなクエリ q とインデックス エントリ x との間のユークリッド距離です。
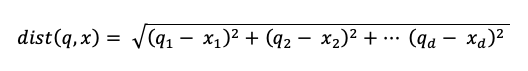
キーワード検索アルゴリズム
関連性スコアは、Okapi BM25を 使用して算出されます。 テキストまたは文字列の列はすべて検索されます。これには、テキストまたは文字列形式のソース テキスト埋め込みおよびメタデータ列も含まれます。 トークン化関数は、すべてのテキストを単語の境界で分割し、句読点を削除し、小文字に変換します。
類似性検索とキーワード検索を組み合わせる方法
類似性検索とキーワード検索結果は、Reciprocal Rank Fusion (RRF) 関数を使用して組み合わされます。
RRF はスコアを使用して、各ドキュメントを各手法で再スコアリングします。
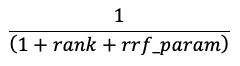
上記の数式では、ランクは 0 から始まり、各ドキュメントのスコアを合計し、スコアが最も高いドキュメントを返します。
rrf_param は、上位と下位のドキュメントの相対的な重要度を制御します。 文献に基づいて、rrf_param は 60 に設定されています。
スコアは、次の数式を使用して、最高スコアが 1、最低スコアが 0 になるように正規化されます。
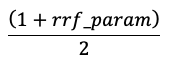
ベクター埋め込みを提供するためのオプション
Databricks 内でベクトル データベースを作成するには、まずベクトル埋め込みを提供する方法を決定する必要があります。 Databricks では、3 つのオプションがサポートされています:
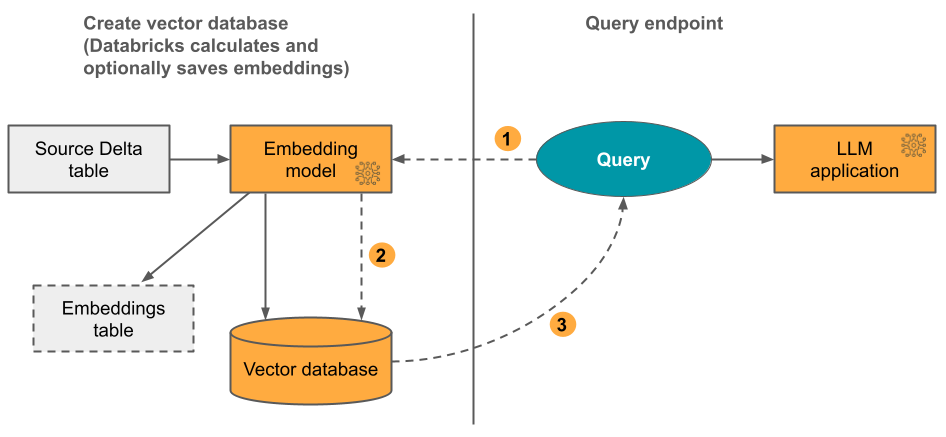
オプション 1: Databricks によってコンピューティングされた埋め込みを備えた Delta 同期インデックス テキスト形式のデータを含むソース Delta テーブルを指定します。 Databricks は、指定されたモデルを使用して埋め込みを計算し、必要に応じて Unity Catalog のテーブルに埋め込みを保存します。 Delta テーブルが更新されると、インデックスはその Delta テーブルとの同期を維持します。
次の図にこのプロセスを示します。
- クエリの埋め込みを計算してください。 クエリにはメタデータ フィルターを含めることができます。
- 類似性検索を実行して、最も関連性の高いドキュメントを特定してください。
- 最も関連性の高いドキュメントを返し、それをクエリに追加してください。
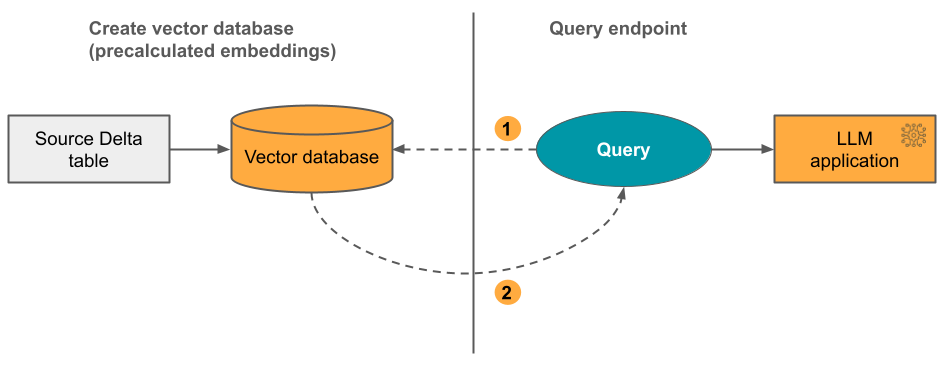
オプション 2: 自己管理型の埋め込みを備えた Delta 同期インデックス 事前計算された埋め込みを含むソース Delta テーブルを指定します。 Delta テーブルが更新されると、インデックスはその Delta テーブルとの同期を維持します。
次の図にこのプロセスを示します。
- クエリは埋め込みで構成され、メタデータ フィルターを含めることができます。
- 類似性検索を実行して、最も関連性の高いドキュメントを特定してください。 最も関連性の高いドキュメントを返し、それをクエリに追加してください。
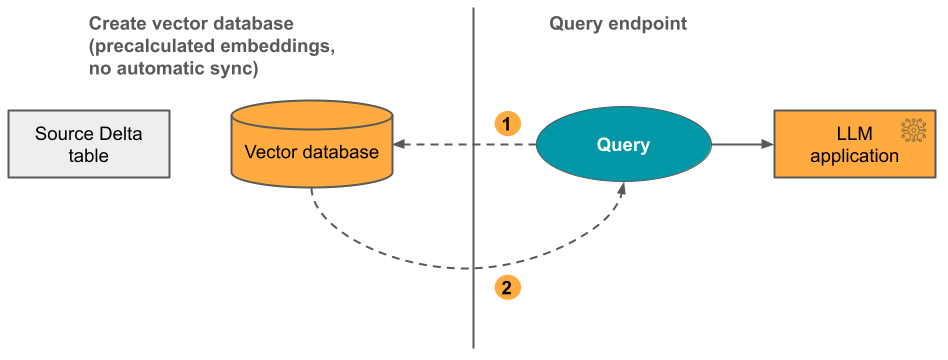
オプション 3: Direct Vector Access Index 埋め込みテーブルが変更される際、REST API を使用してインデックスを手動で更新する必要があります。
次の図にこのプロセスを示します。
Mosaic AI ベクトル検索の設定方法
Mosaic AI ベクトル検索を使用するには、以下のものを作成する必要があります。
- ベクトル検索エンドポイント。 このエンドポイントは、ベクトル検索インデックスを提供します。 REST API または SDK を使用して、エンドポイントにクエリを実行して更新することができます。 エンドポイントは、インデックスのサイズまたは同時要求の数をサポートするように、自動的にスケーリングされます。 手順については、「ベクトル検索エンドポイントを作成する」をご参照ください。
- ベクトル検索インデックス。 ベクトル検索インデックスは Delta テーブルから作成され、リアルタイムの近似最近傍探索を提供するように最適化されています。 検索の目的は、クエリと類似したドキュメントを特定することです。 ベクトル検索インデックスは、Unity Catalog 内で表示および管理されます。 手順については、「ベクトル検索インデックスを作成する」をご参照ください。
さらに、Databricks で埋め込みを計算することを選択した場合、事前に構成された Foundation Model API エンドポイントを使用するか、モデル提供エンドポイントを作成して、任意の埋め込みモデルを提供できます。 手順については、「Foundation Model API のトークン単位の支払い」または「生成 AI モデル提供エンドポイントを作成する」を参照してください。
そのモデル サービング エンドポイントに対してクエリを実行するには、REST API または Python SDK を使用します。 クエリでは、Delta テーブル内の任意の列に基づいて、フィルターを定義することができます。 詳細については、「クエリでのフィルターの使用」、「API リファレンス」、または「Python SDK リファレンス」を参照してください。
要件
- Unity Catalog 対応ワークスペース。
- サーバーレス コンピューティングが有効になっている。 手順については、「サーバーレス コンピューティングに接続する」を参照してください。
- 変更データ フィードが有効なソース テーブル。 手順については、「Azure Databricks で Delta Lake 変更データ フィードを使用する」を参照してください。
- インデックスを作成するカタログ スキーマに対する CREATE TABLE 特権。
- 有効にされた個人用アクセス トークン。
ベクター検索エンドポイントを作成および管理するためのアクセス許可は、アクセス制御リストを使用して構成されます。 ベクター検索エンドポイント ACL を参照してください。
データ保護と認証
Databricks では、データを保護するために次のセキュリティ制御が実装されています。
- Mosaic AI ベクトル検索に対するすべての顧客要求は、論理的に分離、認証、認可されます。
- Mosaic AI ベクトル検索では、すべての保存データ (AES-256) と転送中のデータ (TLS 1.2 以降) が暗号化されます。
Mosaic AI ベクトル検索では、次の 2 つの認証モードがサポートされています。
- 個人用アクセス トークン - 個人用アクセス トークンを使用して、Mosaic AI ベクトル検索で認証できます。 「個人用アクセス トークン認証」を参照してください。 ノートブック環境内で SDK を使用すると、認証用の PAT トークンが自動的に生成されます。
- サービス プリンシパル トークン - 管理者はサービス プリンシパル トークンを生成して、それを SDK または API に渡すことができます。 「サービス プリンシパルの使用」を参照してください。 運用環境のユース ケースの場合、Databricks ではサービス プリンシパル トークンを使用することをお勧めしています。
カスタマー マネージド キー (CMK) は、2024 年 5 月 8 日以降に作成されたエンドポイントでサポートされます。
使用状況とコストの監視
課金対象の使用状況システム テーブルを使用すると、ベクトル検索インデックスとエンドポイントに関連付けられている使用状況とコストを監視できます。 クエリの使用例を次に示します。
WITH all_vector_search_usage (
SELECT *,
CASE WHEN usage_metadata.endpoint_name IS NULL
THEN 'ingest'
ELSE 'serving'
END as workload_type
FROM system.billing.usage
WHERE billing_origin_product = 'VECTOR_SEARCH'
),
daily_dbus AS (
SELECT workspace_id,
cloud,
usage_date,
workload_type,
usage_metadata.endpoint_name as vector_search_endpoint,
SUM(usage_quantity) as dbus
FROM all_vector_search_usage
GROUP BY all
ORDER BY 1,2,3,4,5 DESC
)
SELECT * FROM daily_dbus
課金の使用状況テーブルの内容について詳しくは、「課金対象の使用状況システム テーブルのリファレンス」を参照してください。 追加のクエリは、次のノートブック例にあります。
ベクトル検索システム テーブルのクエリ ノートブック
リソースとデータ サイズの制限
次の表は、ベクトル検索のエンドポイントとインデックスのリソースとデータ サイズの制限をまとめたものです。
| リソース | 細分性 | Limit |
|---|---|---|
| ベクトル検索エンドポイント | ワークスペースごと | 100 |
| 埋め込み | エンドポイントあたり | 320,000,000 |
| 埋め込みディメンション | インデックスごと | 4096 |
| インデックス | エンドポイントあたり | 50 |
| 列 | インデックスごと | 50 |
| 列 | サポートされている型: Bytes、short、integer、long、float、double、boolean、string、timestamp、date | |
| メタデータ フィールド | インデックスごと | 20 |
| インデックス名 | インデックスごと | 128 文字 |
ベクトル検索インデックスの作成と更新には、次の制限が適用されます。
| リソース | 細分性 | Limit |
|---|---|---|
| 差分同期インデックスの行サイズ | インデックスごと | 100 KB |
| 差分同期インデックスの埋め込みソース列のサイズ | インデックスごと | 32764 バイト |
| 直接ベクトル インデックスの一括 upsert 要求サイズの制限 | インデックスごと | 10 MB |
| 直接ベクトル インデックスの一括削除要求サイズの制限 | インデックスごと | 10 MB |
クエリ API には、次の制限が適用されます。
| リソース | 細分性 | Limit |
|---|---|---|
| クエリ テキストの長さ | クエリごと | 32764 |
| 返される結果の最大数 | クエリごと | 10,000 |
制限事項
- 行レベルと列レベルのアクセス許可はサポートされていません。 ただし、フィルター API を使用して独自のアプリケーション レベルの ACL を実装できます。