チュートリアル: カスタム モデルをデプロイしてクエリを実行する
この記事では、カスタム モデル (Mosaic AI Model Serving を使用した従来の ML モデル) をデプロイおよびクエリ実行するための基本的な手順について説明します。 モデルは Unity Catalog またはワークスペース モデル レジストリに登録されている必要があります。
代わりに生成 AI モデルの提供とデプロイの詳細について確認するには、次の記事を参照してください。
手順 1: モデルをログに記録する
モデル提供のためにモデルを記録するには、以下のようなさまざまな方法があります。
| 記録手法 | 説明 |
|---|---|
| 自動ログ | これは、機械学習に Databricks Runtime を使用すると自動的に有効になります。 これは最も簡単な方法ですが、行える制御は減ります。 |
| MLflow の組み込みフレーバーを使用した記録 | MLflow の組み込みモデル フレーバーを使用して、モデルを手動で記録できます。 |
pyfunc を使用したカスタム記録 |
これは、カスタム モデルがある場合、または推論の前後に追加の手順が必要な場合に使用します。 |
次の例は、transformer フレーバーを使用して MLflow モデルを記録し、モデルに必要なパラメーターを指定する方法を示しています。
with mlflow.start_run():
model_info = mlflow.transformers.log_model(
transformers_model=text_generation_pipeline,
artifact_path="my_sentence_generator",
inference_config=inference_config,
registered_model_name='gpt2',
input_example=input_example,
signature=signature
)
モデルがログに記録されたら、モデルが Unity Catalog または MLflow Model Registry に登録されていることを確認してください。
手順 2: Serving UI を使用してエンドポイントを作成する
登録モデルが記録され、サービスを提供する準備ができたら、Serving UI を使用してモデル サービング エンドポイントを作成できます。
サイドバーの [Serving] をクリックして、Serving UI を表示します。
[提供エンドポイントの作成] をクリックします。
![Databricks UI の [モデル提供] ペイン](../../_static/images/machine-learning/serving-pane.png)
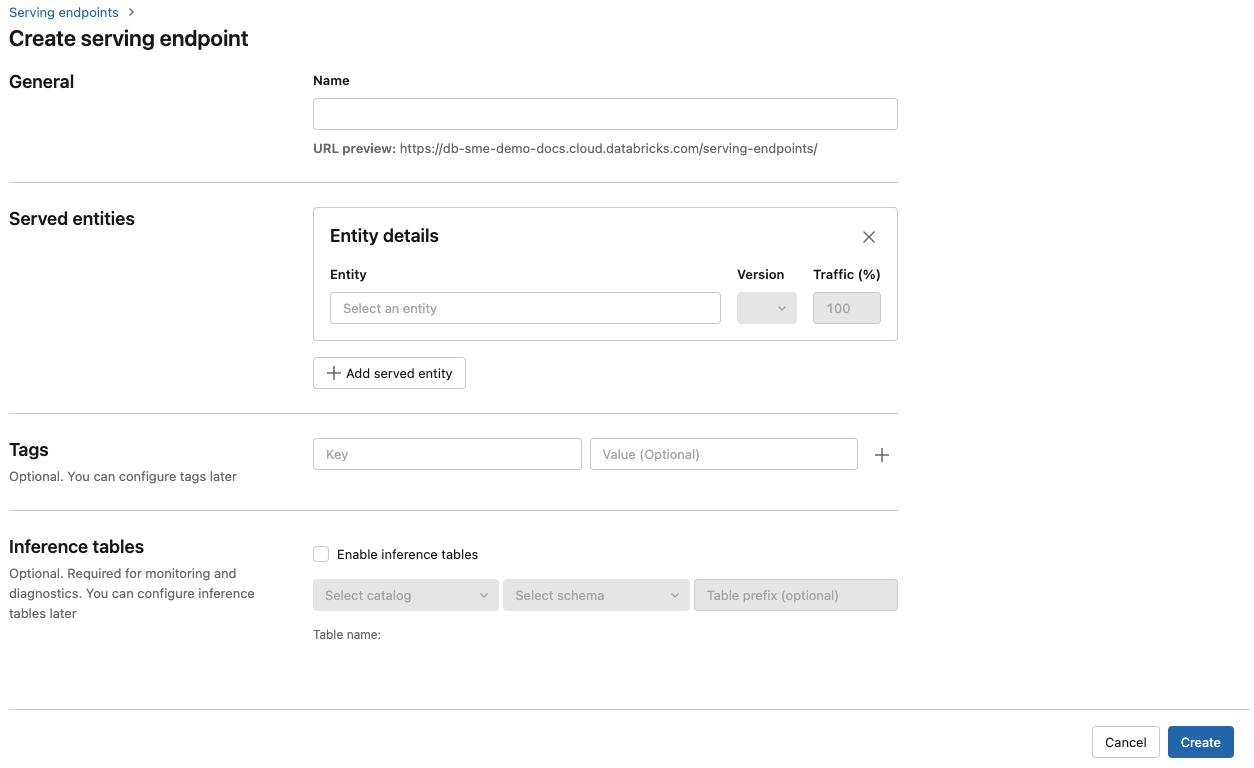
[名前] フィールドに、エンドポイントの名前を指定します。
[Served entities] (提供されるエンティティ) セクションで、次のようにします。
- [エンティティ] フィールドをクリックして、[Select served entity] (提供されるエンティティの選択) フォームを開きます。
- 提供するモデルの種類を選択します。 フォームは、選択内容に基づいて動的に更新されます。
- 提供したいモデルとモデルのバージョンを選択します。
- 提供されるモデルにルーティングするトラフィックの割合を選択します。
- 使用するコンピューティングのサイズを選択します。
- [Compute Scale-out] (コンピューティング スケールアウト) で、この提供されるモデルが同時に処理できる要求の数に対応するコンピューティング スケールアウトのサイズを選択します。 この数値は、QPS にモデル実行時間を掛けた値とほぼ同じである必要があります。
- 使用可能なサイズは、Small (要求数が 0 から 4 個の場合)、Medium (要求数が 8 から 16 個の場合)、Large (要求数が 16 から 64 個の場合) です。
- 使用しないときにエンドポイントをゼロにスケールダウンする必要があるかどうかを指定します。
Create をクリックしてください。 [提供エンドポイントの状態] が Not Ready となっている [提供エンドポイント] ページが表示されます。
Databricks Serving API を使用してプログラムでエンドポイントを作成したい場合は、「カスタム モデル サービング エンドポイントを作成する」を参照してください。
手順 3: エンドポイントにクエリを実行する
提供モデルをテストしてスコアリング要求を送信する最も簡単で最速の方法は、Serving UI を使用することです。
「サービス エンドポイント」ページで、[クエリ エンドポイント] を選択します。
モデル入力データを JSON 形式で挿入し、[要求の送信] をクリックします。 モデルが入力例でログに記録されている場合は、[例の表示] をクリックして入力例を読み込みます。
{ "inputs" : ["Hello, I'm a language model,"], "params" : {"max_new_tokens": 10, "temperature": 1} }
スコアリング要求を送信するには、サポートされているいずれかのキーと、入力形式に対応した JSON オブジェクトを使用して JSON を構築する必要があります。 サポートされている形式と、API を使ってスコアリング要求を送信する方法のガイダンスについては、「カスタム モデルのエンドポイントを提供するクエリ」をご覧ください。
Azure Databricks Serving UI の外部でサービス エンドポイントにアクセスする予定がある場合は、DATABRICKS_API_TOKEN が必要です。
重要
運用シナリオのセキュリティのベスト プラクティスとして、Databricks では、運用時の認証にコンピューター間 OAuth トークンを使用することをお勧めします。
テストおよび開発の場合は、Databricks では、ワークスペース ユーザーではなく、サービス プリンシパルに属する個人用アクセス トークンを使用することをお勧めします。 サービス プリンシパルのトークンを作成するには、「サービス プリンシパルのトークンを管理する」をご覧ください。
ノートブックの例
モデル提供を使用して MLflow transformers モデルを提供するためには、次のノートブックを参照してください。
Hugging Face transformers モデル ノートブックをデプロイする
モデル提供を使用して MLflow pyfunc モデルを提供するためには、次のノートブックを参照してください。 モデル デプロイのカスタマイズの詳細については、「Model Serving を使って Python コードをデプロイする」を参照してください。