ベクター インデックスのサイズと制限以下の維持
Azure AI 検索では、ベクター フィールドごとに、そのフィールドで指定されたアルゴリズム パラメーターを使用して内部ベクター インデックスを構築します。 Azure AI 検索では、ベクター インデックスのサイズにクォータが課せられるため、常に制限以下に維持されるように、ベクター サイズを見積もり、監視する方法を理解する必要があります。
Note
用語に関する注意。 内部的には、検索インデックスの物理データ構造には、生のコンテンツ (トークン化されていないコンテンツを必要とする検索パターンに使用)、転置インデックス (検索可能なテキスト フィールドに使用)、ベクター インデックス (検索可能なベクター フィールドに使用) が含まれます。 この記事では、各ベクター フィールドをサポートする内部ベクター インデックスの制限について説明します。
ヒント
ベクター量子化とストレージ構成は現在プレビュー段階です。 狭いデータ型、スカラー量子化、冗長ストレージの排除などの機能を使用して、ベクター クォータとストレージ クォータを超えないようにします。
クォータとベクター インデックスのサイズに関する重要なポイント
ベクター インデックスのサイズはバイト単位で測定されます。
ベクター クォータは、メモリの制約に基づいています。 すべての検索可能なベクター インデックスをメモリに読み込む必要があります。 同時に、他のランタイム操作用の十分なメモリも必要です。 ベクター クォータは、システム全体が安定し、すべてのワークロードに対してバランスが保たれるようにするために存在します。
ベクター インデックスは、すべてのインデックスはディスク クォータに従うという意味で、ディスク クォータの対象でもあります。 ベクター インデックス用の個別のディスク クォータはありません。
ベクター クォータは、パーティションごとに検索サービス全体に適用されます。つまり、パーティションを追加すると、ベクター クォータが上がります。 パーティションごとのベクター クォータは、新しいサービスでは高くなります。
パーティションのサイズと数量を確認する方法
検索サービスの制限が不明な場合、その情報を取得するには、次の 2 つの方法があります。
Azure portal で、検索サービスの [概要] ページにある [プロパティ] タブと [使用状況] タブの両方に、パーティションのサイズとストレージが表示されます。さらに、ベクター クォータとベクター インデックス サイズも表示されます。
Azure portal の [スケール] ページでは、パーティションの数とサイズを確認できます。
サービス作成日を確認する方法
2024 年 4 月 3 日より後に作成された新しいサービスでは、同じレベルの請求レートで古いサービスの 5 から 10 倍のベクター ストレージが提供されます。 サービスが古い場合、新しいサービスを作成してコンテンツを移行することを検討してください。
Azure portal で、検索サービスを含むリソース グループを開きます。
左側のペインの [設定] で、[デプロイ] を選択します。
検索サービス デプロイの場所を見つけます。 デプロイが多数ある場合は、フィルターを使用して "検索" を探します。
デプロイを選択します。 複数のデプロイがある場合は、一つずつクリックして、それがご利用の検索サービスであるかどうかを確認します。
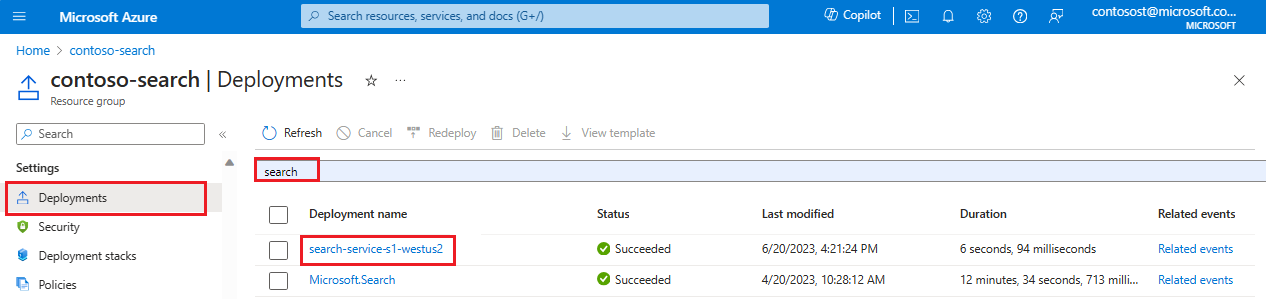
デプロイの詳細を展開します。 "作成済み" の表記と作成日が表示されるはずです。
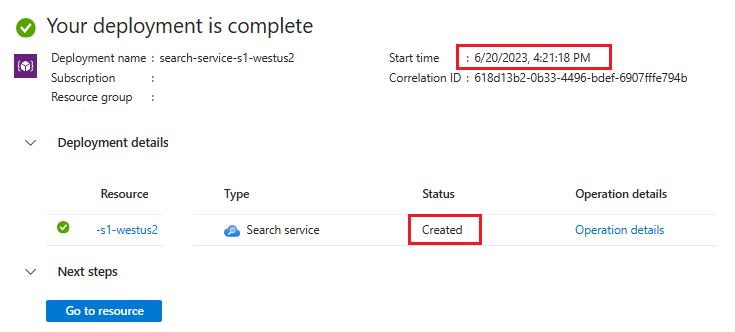
検索サービスの古さがわかったので、以下でサービスの作成方法に基づくベクトル クォータの制限を確認します。
ベクトル インデックス サイズを取得する方法
ベクトル メトリックの要求は、データ プレーン操作です。 Azure portal、REST API、または Azure SDK を使用して、サービス統計情報と個々のインデックスを通して、サービス レベルでベクトルの使用状況を取得できます。
使用状況の情報は、[概要] ページの [使用状況] タブで確認できます。ポータル ページは数分ごとに更新されるため、インデックスを更新したばかりの場合は、少し待ってから結果を確認してください。
次のスクリーンショットは、1 つのパーティションと 1 つのレプリカ用に構成された古い Standard 1 (S1) 検索サービスを対象にしています。
- ストレージ クォータはディスクの制約であり、検索サービス上のすべてのインデックス (ベクターと非ベクター) を含みます。
- ベクター インデックス サイズ クォータはメモリ制約です。 これは、検索サービスの各ベクター フィールドに対して作成されたすべての内部ベクター インデックスを読み込むのに必要なメモリ量です。
このスクリーンショットは、インデックス (ベクターと非ベクター) が使用可能なディスク ストレージのうち約 460 MB を消費することを示しています。 ベクター インデックスは、サービス レベルでほぼ 93 メガバイトのメモリを消費します。
![クォータに対するベクター インデックスの使用量を示す [概要] ページの [使用状況] タブのスクリーンショット。](media/vector-search-index-size/portal-vector-index-size.png#lightbox)
パーティションを追加または削除すると、ストレージ インデックスとベクター インデックス サイズの両方のクォータが増減します。 パーティション数を変更すると、タイルにストレージ クォータとベクター クォータの対応する変更が表示されます。
Note
ディスク上では、ベクター インデックスは 93 メガバイトではありません。 ディスク上でのベクター インデックスは、メモリ内のベクター インデックスの約 3 倍の領域を占有します。 詳細については、「ベクター フィールドがディスク ストレージに与える影響」を参照してください。
ベクトル インデックスのサイズに影響を与える要因
内部ベクトル インデックスのサイズに影響を与える 3 つの主要なコンポーネントがあります。
- 生のデータのサイズ
- 選択したアルゴリズムからのオーバーヘッド
- インデックス内のドキュメントの削除または更新によるオーバーヘッド
生のデータのサイズ
各ベクトルは通常、Collection(Edm.Single) 型のフィールド内の単精度浮動小数点数の配列です。
ベクトル データ構造体には、データの "生のサイズ" として次の計算で表されるストレージが必要です。 この "生のサイズ" を使用して、ベクトル フィールドのベクトル インデックス サイズの要件を推定します。
1 つのベクトルのストレージのサイズは、その次元によって決まります。 1 つのベクトルのサイズに、そのベクトル フィールドを含むドキュメントの数を乗算して、"生のサイズ" を取得します。
raw size = (number of documents) * (dimensions of vector field) * (size of data type)
| EDM データ型 | データ型のサイズ |
|---|---|
Collection(Edm.Single) |
4 バイト |
Collection(Edm.Half) |
2 バイト |
Collection(Edm.Int16) |
2 バイト |
Collection(Edm.SByte) |
1 バイト |
選択したアルゴリズムに起因するメモリ オーバーヘッド
すべての近似最近傍 (ANN) アルゴリズムは、効率的な検索を実現するために、メモリ内に追加のデータ構造体を生成します。 これらの構造体は、メモリ内で余分な領域を消費します。
HNSW アルゴリズムの場合、メモリ オーバーヘッドの範囲は 1% ~ 20% です。
ベクトルの生のサイズが増加するため、次元が高くなるとメモリ オーバーヘッドは小さくなりますが、追加のデータ構造体はグラフ内の接続に関する情報を格納するため固定サイズのままです。 その結果、追加のデータ構造体による影響は、全体のサイズに占める部分としては小さくなります。
HNSW パラメーター m の値を大きくすると、メモリ オーバーヘッドが大きくなります。これは、このパラメーターによって、インデックスの構築中に新しいベクトルごとに作成される双方向リンクの数が決まるためです。 これは、m がドキュメントあたり約 8 から 10 バイトに m を掛けた値であるためです。
次の表は、内部テストで観察されたオーバーヘッドの割合をまとめたものです。
| ディメンション | HNSW パラメーター (m) | オーバーヘッドの割合 |
|---|---|---|
| 96 | 4 | 20% |
| 200 | 4 | 8% |
| 768 | 4 | 2% |
| 1536 | 4 | %1 |
| 3072 | 4 | 0.5% |
これらの結果は、次元、HNSW パラメーター m、HNSW アルゴリズムのメモリ オーバーヘッドの関係を示しています。
インデックス内のドキュメントの削除または更新によるオーバーヘッド
ベクトル フィールドをもつドキュメントが削除または更新された場合 (更新は内部的に削除操作と挿入操作として表される)、基になるドキュメントは削除済みとしてマークされ、後続のクエリ中にスキップされます。 新しいドキュメントのインデックスが作成され、内部ベクトル インデックスが大きくなると、システムはこれらの削除されたドキュメントをクリーンアップし、リソースを回収します。 このことは、ドキュメントを削除してから、基になっているリソースが解放されるまでに、遅延が発生する可能性があることを示しています。
これは、"削除されたドキュメント率" と呼ばれます。 削除されたドキュメント率はサービスのインデックス作成特性によって変化するため、このパラメーターを推定する普遍的なヒューリスティックはなく、サービスについての有効な比率を返す API やスクリプトはありません。 削除されたドキュメント率は、お客様の半数で 10% 未満であることを確認しています。 削除や更新の頻度が高い傾向にある場合は、削除されたドキュメント率が高くなる可能性があります。
これが、ベクトル インデックスのサイズに影響を与えるもう 1 つの要因です。 残念ながら、現在の削除されたドキュメント率を表出させるメカニズムはありません。
メモリ内のデータの合計サイズの見積もり
これまで説明した要素を考慮して、ベクター インデックスの合計サイズを見積もるには、次の計算を使用します。
(raw_size) * (1 + algorithm_overhead (in percent)) * (1 + deleted_docs_ratio (in percent))
たとえば、1,536 次元の一般的な Azure OpenAI モデル text-embedding-ada-002 を使用しているとして、raw_size を計算するとします。 これは、1 つのドキュメントが 1,536 Edm.Single (floats) または 6,144 バイトを消費することを意味しています (各 Edm.Single は 4 バイトであるため)。 単一の 1,536 次元ベクトル フィールドをもつ 1,000 のドキュメントは、合計で 1,000 ドキュメント x 1536 floats/doc = 1,536,000 floats、つまり 6,144,000 バイトを消費します。
複数のベクトル フィールドがある場合は、インデックス内の各ベクトル フィールドについてこの計算を実行し、それらすべてを加算する必要があります。 たとえば、2 つの 1,536 次元ベクトル フィールドがある 1,000 個のドキュメントでは、1,000 doc x 2 フィールド x 1536 floats/doc x 4 バイト/float = 12,288,000 バイトを消費します。
ベクトル インデックス サイズを取得するには、この raw_size に アルゴリズムのオーバーヘッドと削除されたドキュメント率を乗算します。 選択した HNSW パラメーターのアルゴリズム オーバーヘッドが 10% で、削除されたドキュメント率が 10% の場合、6.144 MB * (1 + 0.10) * (1 + 0.10) = 7.434 MB となります。
ベクトル フィールドがディスク ストレージに与える影響
この記事のほとんどは、メモリ内のベクターのサイズに関する情報を提供します。 ディスク上のベクター サイズについて知りたい場合、ベクター データのディスク消費量は、メモリ内のベクター インデックスのサイズの約 3 倍になります。 たとえば、vectorIndexSize使用量が 100 MB (1,000 万バイト) の場合、ベクター インデックスを保存するために 300 MB 以上の storageSize クォータを使用したことになります。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示