Azure Data Box を使用してオンプレミスの HDFS ストアから Azure Storage に移行する
Data Box デバイスを使用することにより、Hadoop クラスターのオンプレミス HDFS ストアから Azure Storage (Blob ストレージまたは Data Lake Storage Gen2) にデータを移行できます。 Data Box Disk、80 TB の Data Box、または 770 TB の Data Box Heavy から選択できます。
この記事は、次のタスクを完了する上で役立ちます。
- データの移行を準備する
- データを Data Box Disk、Data Box または Data Box Heavy デバイスにコピーする
- Microsoft にデバイスを返送する
- ファイルとディレクトリにアクセス許可を適用します (Data Lake Storage Gen2 のみ)
前提条件
移行を完了するには、以下が必要です。
Azure Storage のアカウント
ソース データを含むオンプレミス Hadoop クラスター。
-
オンプレミス ネットワークに Data Box または Data Box Heavy をケーブル接続します。
準備ができたら始めましょう。
データを Data Box デバイスにコピーする
データが 1 つの Data Box デバイスに収まる場合は、そのデータを Data Box デバイスにコピーします。
データ サイズが Data Box デバイスの容量を超える場合は、オプションの手順を使用してデータを複数の Data Box デバイスに分割し、この手順を実行します。
オンプレミス HDFS ストアから Data Box デバイスにデータをコピーするには、いくつかの事項を設定し、DistCp ツールを使用します。
以下の手順に従って、Blob/オブジェクト ストレージの REST API を介して Data Box デバイスにデータをコピーします。 REST API インターフェイスでは、デバイスはクラスターに HDFS ストアとして表示されます。
REST を介してデータをコピーする前に、Data Box または Data Box Heavy 上で REST インターフェイスに接続するためにセキュリティおよび接続プリミティブを識別します。 Data Box のローカル Web UI にサインインして、 [接続とコピー] ページに移動します。 デバイスの Azure ストレージ アカウントに対して、[アクセスの設定] の下で [REST] を探して選択します。
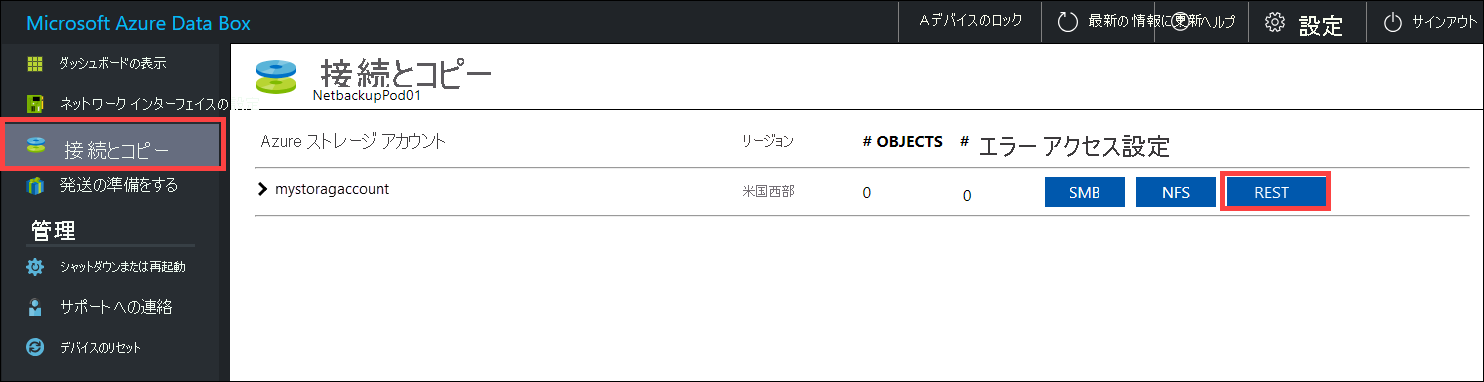
[ストレージ アカウントへのアクセスとデータのアップロード] ダイアログで [Blob service エンドポイント] と [ストレージ アカウント キー] をコピーします。 Blob service エンドポイントから、
https://と末尾のスラッシュを省略します。ここでは、エンドポイントは
https://mystorageaccount.blob.mydataboxno.microsoftdatabox.com/になります。 使用する URI のホスト部分はmystorageaccount.blob.mydataboxno.microsoftdatabox.comです。 たとえば、HTTP 経由の REST への接続の方法を参照してください。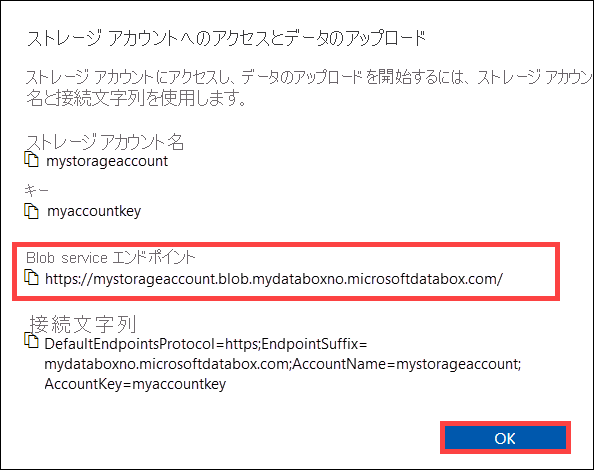
エンドポイントと、Data Box または Data Box Heavy ノードの IP アドレスを各ノードの
/etc/hostsに追加します。10.128.5.42 mystorageaccount.blob.mydataboxno.microsoftdatabox.comDNS を他のメカニズムを使用している場合は、Data Box エンドポイントを解決できることを確認する必要があります。
シェル変数
azjarsを、hadoop-azureおよびazure-storagejar ファイルの場所に設定します。 これらのファイルは Hadoop インストール ディレクトリ以下にあります。これらのファイルが存在するかどうかを確認するには、次のコマンドを使用します
ls -l $<hadoop_install_dir>/share/hadoop/tools/lib/ | grep azure。<hadoop_install_dir>プレースホルダーは、Hadoop をインストールしたディレクトリのパスに置き換えます。 必ず完全修飾パスを使用します。例 :
azjars=$hadoop_install_dir/share/hadoop/tools/lib/hadoop-azure-2.6.0-cdh5.14.0.jarazjars=$azjars,$hadoop_install_dir/share/hadoop/tools/lib/microsoft-windowsazure-storage-sdk-0.6.0.jarデータのコピーに使用するストレージ コンテナーを作成します。 このコマンドの一部として宛先ディレクトリも指定する必要があります。 この時点では、これはダミーの宛先ディレクトリになる可能性があります。
hadoop fs -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint>=<account_key> \ -mkdir -p wasb://<container_name>@<blob_service_endpoint>/<destination_directory><blob_service_endpoint>プレースホルダーは、実際の BLOB サービス エンドポイントの名前に置き換えます。<account_key>プレースホルダーは、実際のアカウントのアクセス キーに置き換えます。<container-name>プレースホルダーは、実際のコンテナーの名前に置き換えます。<destination_directory>プレースホルダーは、データのコピー先であるディレクトリの名前に置き換えます。
リスト コマンドを実行してコンテナーとディレクトリが作成されたことを確認します。
hadoop fs -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint>=<account_key> \ -ls -R wasb://<container_name>@<blob_service_endpoint>/<blob_service_endpoint>プレースホルダーは、実際の BLOB サービス エンドポイントの名前に置き換えます。<account_key>プレースホルダーは、実際のアカウントのアクセス キーに置き換えます。<container-name>プレースホルダーは、実際のコンテナーの名前に置き換えます。
Data Box Blob ストレージ内の先ほど作成したコンテナーに、Hadoop HDFS からデータをコピーします。 コピー先のディレクトリが見つからない場合、コマンドにより自動的に作成されます。
hadoop distcp \ -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint<>=<account_key> \ -filters <exclusion_filelist_file> \ [-f filelist_file | /<source_directory> \ wasb://<container_name>@<blob_service_endpoint>/<destination_directory><blob_service_endpoint>プレースホルダーは、実際の BLOB サービス エンドポイントの名前に置き換えます。<account_key>プレースホルダーは、実際のアカウントのアクセス キーに置き換えます。<container-name>プレースホルダーは、実際のコンテナーの名前に置き換えます。<exlusion_filelist_file>プレースホルダーは、ファイルの除外一覧を含むファイルの名前に置き換えます。<source_directory>プレースホルダーは、コピーするデータが格納されているディレクトリの名前に置き換えます。<destination_directory>プレースホルダーは、データのコピー先であるディレクトリの名前に置き換えます。
-libjarsオプションは、hadoop-azure*.jarと従属azure-storage*.jarファイルをdistcpで使用できるようにするために使用されます。 これは、一部のクラスターで既に行われている可能性があります。次の例は、
distcpコマンドを使用してデータをコピーする方法を示しています。hadoop distcp \ -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.mystorageaccount.blob.mydataboxno.microsoftdatabox.com=myaccountkey \ -filter ./exclusions.lst -f /tmp/copylist1 -m 4 \ /data/testfiles \ wasb://hdfscontainer@mystorageaccount.blob.mydataboxno.microsoftdatabox.com/dataコピー速度を向上させるには:
マッパーの数を変更してみてください。 (既定のマッパー数は 20 です。上記の例では、
m= 4 個のマッパーを使用しています。)-D fs.azure.concurrentRequestCount.out=<thread_number>を試してください。<thread_number>をマッパーあたりのスレッド数に置き換えます。 マッパー数とマッパーあたりのスレッド数の積m*<thread_number>は 32 を超えてはなりません。複数の
distcpを並行して実行してみてください。大きなファイルは小さなファイルよりもパフォーマンスが向上することに注意してください。
200 GB より大きいファイルがある場合は、次のパラメーターを使用してブロック サイズを 100 MB に変更することをお勧めします。
hadoop distcp \ -libjars $azjars \ -Dfs.azure.write.request.size= 104857600 \ -Dfs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -Dfs.azure.account.key.<blob_service_endpoint<>=<account_key> \ -strategy dynamic \ -Dmapreduce.map.memory.mb=16384 \ -Dfs.azure.concurrentRequestCount.out=8 \ -Dmapreduce.map.java.opts=-Xmx8196m \ -m 4 \ -update \ /data/bigfile wasb://hadoop@mystorageaccount.blob.core.windows.net/bigfile
Data Box を Microsoft に送付する
これらの手順に従って、Data Box デバイスを準備し、Microsoft に送付します。
デバイスの準備が完了した後は、BOM ファイルをダウンロードします。 後からこれらの BOM またはマニフェスト ファイルを使用して、データが Azure にアップロードされたことを確認します。
デバイスをシャット ダウンし、ケーブルを取り外します。
UPS で集荷のスケジュールを設定します。
Data Box デバイスの場合は、Data Box の送付に関するページを参照してください。
Data Box Heavy デバイスの場合は、Data Box Heavy の送付に関するページを参照してください。
Microsoft がデバイスを受け取ると、データ センター ネットワークに接続され、デバイスを注文したときに指定したストレージ アカウントにデータがアップロードされます。 すべてのデータが Azure にアップロードされたことを BOM ファイルに対して確認します。
ファイルとディレクトリにアクセス許可を適用します (Data Lake Storage Gen2 のみ)
Azure Storage アカウントに既にデータがあります。 次に、ファイルとディレクトリにアクセス許可を適用します。
Note
この手順は、データ ストアとして Azure Data Lake Storage Gen2 を使用している場合にのみ必要です。 階層型名前空間を持たない BLOB ストレージ アカウントだけをデータ ストアとして使用している場合は、このセクションをスキップできます。
Azure Data Lake Storage Gen2 の有効なアカウントのサービス プリンシパルを作成します。
サービス プリンシパルを作成するには、「操作方法: リソースにアクセスできる Microsoft Entra アプリケーションとサービス プリンシパルをポータルで作成する」を参照してください。
記事の「アプリケーションをロールに割り当てる」セクションの手順を実行するときに、必ずストレージ BLOB データ共同作成者ロールをサービス プリンシパルに割り当ててください。
記事の「サインインするための値を取得する」セクションの手順を実行するときは、アプリケーション ID、クライアント シークレット値をテキスト ファイルに保存します。 これらはすぐに必要になります。
それらのアクセス許可を使用してコピーされたファイルの一覧を生成する
オンプレミスの Hadoop クラスターから、次のコマンドを実行します。
sudo -u hdfs ./copy-acls.sh -s /{hdfs_path} > ./filelist.json
このコマンドでは、それらのアクセス許可を使用してコピーされたファイルの一覧が生成されます。
Note
HDFS 内のファイル数によっては、このコマンドの実行に時間がかかることがあります。
ID の一覧を生成し、それらを Microsoft Entra ID にマップする
copy-acls.pyスクリプトをダウンロードします。 この記事の「ヘルパー スクリプトをダウンロードし、それらを実行するようにエッジ ノードを設定する」セクションを参照してください。このコマンドを実行して、固有の ID の一覧を生成します。
./copy-acls.py -s ./filelist.json -i ./id_map.json -gこのスクリプトで、ADD ベースの ID にマップする必要がある ID を含む
id_map.jsonという名前のファイルが生成されます。テキスト エディターで
id_map.jsonファイルを開きます。ファイルに出現する各 JSON オブジェクトについて、マップされた適切な ID を使用して Microsoft Entra ユーザー プリンシパル名 (UPN) または ObjectId (OID) のいずれかの
target属性を更新します。 完了したら、ファイルを保存します。 次の手順でこのファイルが必要になります。
コピーしたファイルにアクセス許可を適用し、ID マッピングを適用する
このコマンドを実行して、Data Lake Storage Gen2 の有効なアカウントにコピーしたデータにアクセス許可を適用します。
./copy-acls.py -s ./filelist.json -i ./id_map.json -A <storage-account-name> -C <container-name> --dest-spn-id <application-id> --dest-spn-secret <client-secret>
<storage-account-name>プレースホルダーは、実際のストレージ アカウントの名前に置き換えます。<container-name>プレースホルダーは、実際のコンテナーの名前に置き換えます。<application-id>と<client-secret>のプレースホルダーは、サービス プリンシパルの作成時に収集したアプリケーション ID とクライアント シークレットに置き換えます。
付録: 複数の Data Box デバイスにデータを分割する
データを Data Box デバイスに移動する前に、ヘルパー スクリプトをダウンロードし、データが Data Box に収まるように編成されていることを確認し、不要なファイルを除外する必要があります。
ヘルパー スクリプトをダウンロードし、それらを実行するようにエッジ ノードを設定する
オンプレミス Hadoop クラスターのエッジ ノードまたはヘッド ノードから、次のコマンドを実行します。
git clone https://github.com/jamesbak/databox-adls-loader.git cd databox-adls-loaderこのコマンドで、ヘルパー スクリプトを含む GitHub リポジトリが複製されます。
ローカル コンピューターに jq パッケージがインストールされていることを確認します。
sudo apt-get install jqRequests python パッケージをインストールします。
pip install requests必要なスクリプトに実行アクセス許可を設定します。
chmod +x *.py *.sh
データが Data Box デバイスに収まるように編成されていることを確認する
データのサイズが 1 台の Data Box デバイスのサイズを超える場合は、複数のグループに分割してファイルを複数の Data Box デバイスに保存できるようにします。
データが 1 台の Data Box デバイスのサイズを超えない場合は、次のセクションに進むことができます。
管理者特権のアクセス許可を使用して、前のセクションのガイダンスに従ってダウンロードした
generate-file-listスクリプトを実行します。コマンド パラメーターの説明を次に示します。
sudo -u hdfs ./generate-file-list.py [-h] [-s DATABOX_SIZE] [-b FILELIST_BASENAME] [-f LOG_CONFIG] [-l LOG_FILE] [-v {DEBUG,INFO,WARNING,ERROR}] path where: positional arguments: path The base HDFS path to process. optional arguments: -h, --help show this help message and exit -s DATABOX_SIZE, --databox-size DATABOX_SIZE The size of each Data Box in bytes. -b FILELIST_BASENAME, --filelist-basename FILELIST_BASENAME The base name for the output filelists. Lists will be named basename1, basename2, ... . -f LOG_CONFIG, --log-config LOG_CONFIG The name of a configuration file for logging. -l LOG_FILE, --log-file LOG_FILE Name of file to have log output written to (default is stdout/stderr) -v {DEBUG,INFO,WARNING,ERROR}, --log-level {DEBUG,INFO,WARNING,ERROR} Level of log information to output. Default is 'INFO'.生成されたファイル一覧を HDFS にコピーして、DistCp ジョブにアクセスできるようにします。
hadoop fs -copyFromLocal {filelist_pattern} /[hdfs directory]
不要なファイルを除外する
DisCp ジョブからいくつかのディレクトリを除外する必要があります。 たとえば、クラスターの稼働を維持する状態情報を含むディレクトリを除外します。
DistCp ジョブを開始する予定のオンプレミス Hadoop クラスター上に、除外するディレクトリの一覧を指定するファイルを作成します。
次に例を示します。
.*ranger/audit.*
.*/hbase/data/WALs.*
次のステップ
HDInsight クラスターでの Data Lake Storage Gen2 の動作について学習します。 詳しくは、「Azure HDInsight クラスターで Azure Data Lake Storage Gen2 を使用する」をご覧ください。