Parquet 形式で Event Hubs からデータをキャプチャする
この記事では、ノー コード エディターを使用して、Azure Data Lake Storage Gen2 アカウントの Event Hubs のストリーミング データを Parquet 形式で自動的にキャプチャする方法について説明します。
必須コンポーネント
イベント ハブを持つ Azure Event Hubs 名前空間と、キャプチャされたデータを保存するコンテナーを持つ Azure Data Lake Storage Gen2 アカウント。 これらのリソースはパブリックにアクセスできる必要があり、ファイアウォールの内側に置いたり、Azure 仮想ネットワークでセキュリティ保護したりすることはできません。
イベント ハブがない場合は、クイック スタート: イベント ハブの作成の手順に従って作成します。
Data Lake Storage Gen2 アカウントがない場合は、ストレージ アカウントの作成の手順に従ってアカウントを作成します
Event Hubs のデータは、JSON、CSV、または Avro 形式でシリアル化される必要があります。 テスト目的の場合は、左側のメニューで [データの生成 (プレビュー)] を選択し、データセットに [Stocks data] を選択して、[送信] を選択します。
![サンプルの在庫データを生成するための [データの生成] ページを示すスクリーンショット。](media/capture-event-hub-data-parquet/stocks-data.png)
![サンプルの在庫データを生成するための [データの生成] ページを示すスクリーンショット。](media/capture-event-hub-data-parquet/stocks-data.png#lightbox)
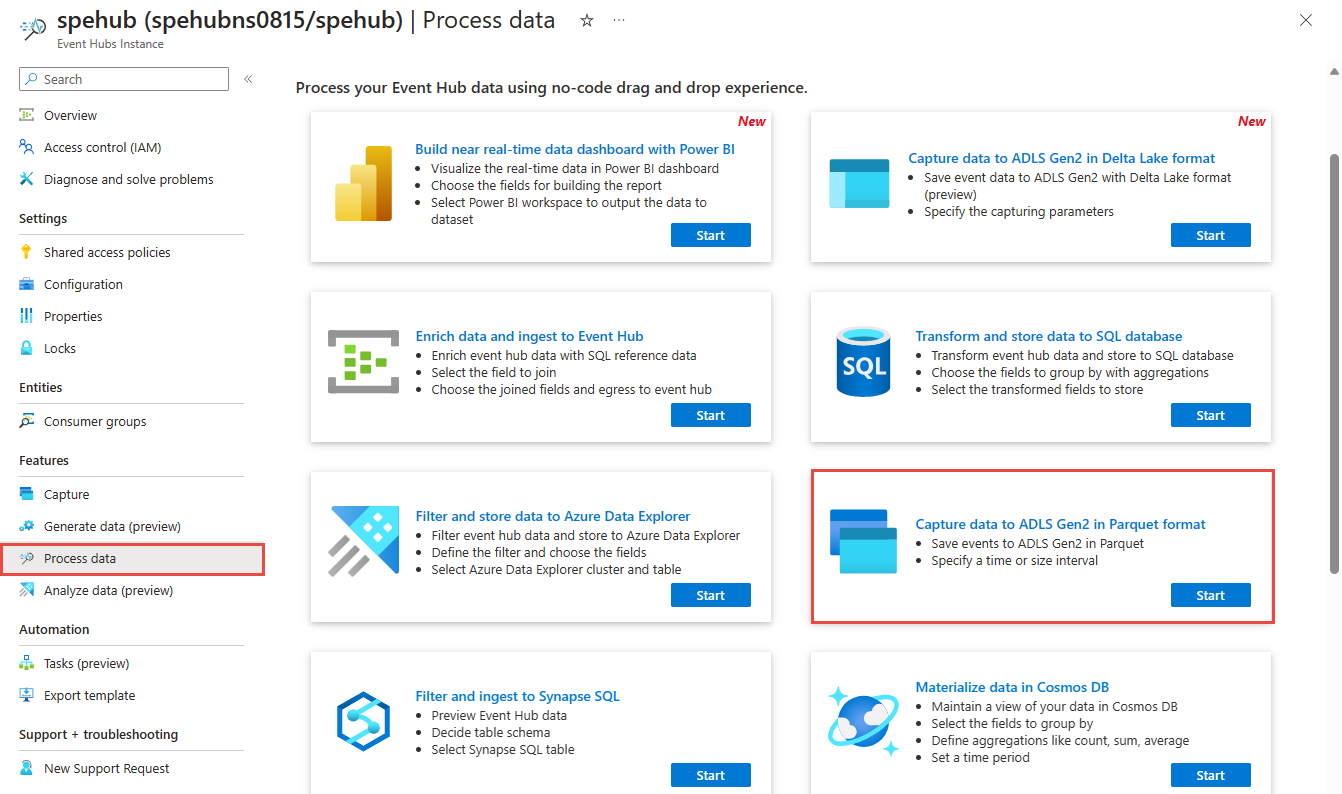
データをキャプチャするようにジョブを構成する
Azure Data Lake Storage Gen2 内のデータをキャプチャするように Stream Analytics ジョブを構成するには、次の手順に従います。
Azure portal で、イベント ハブに移動します。
左側のメニューの [機能] で [データの処理] を選択します。 次に、[データを Parquet 形式で ADLS Gen2 にキャプチャする] カードの [開始] を選択します。
Stream Analytics ジョブの名前を入力して、[作成] を選択します。
![ジョブ名を入力する [New Stream Analytics job] (新しい Stream Analytics ジョブ) ウィンドウを示すスクリーンショット。](media/capture-event-hub-data-parquet/new-stream-analytics-job-name.png)
Event Hubs でのデータの種類として [シリアル化] を指定し、ジョブが Event Hubs に接続するのに使用する [認証方法] を指定します。 次に、 [接続](Connect) を選択します。
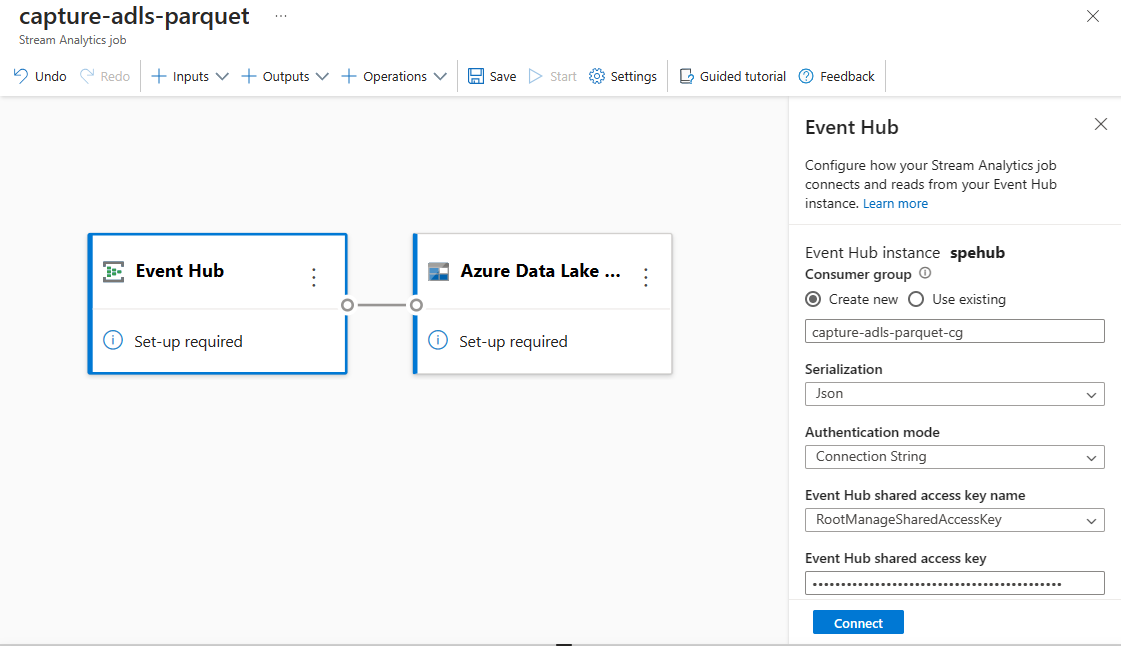
接続が正常に確立されると、次の情報が表示されます。
入力データに存在するフィールド。 [フィールドの追加] を選択するか、フィールドの横にある 3 つのドット記号を選択して削除または名前の変更を行うことができます。
ダイアグラム ビューの [データ プレビュー] テーブルでの受信データのライブ サンプル。 定期的に更新されます。 [ストリーミング プレビューの一時停止] を選択すると、サンプル入力の静的ビューを見ることができます。
![[Data Preview] (データのプレビュー) の下にサンプル データが示されているスクリーンショット。](media/capture-event-hub-data-parquet/edit-fields.png)
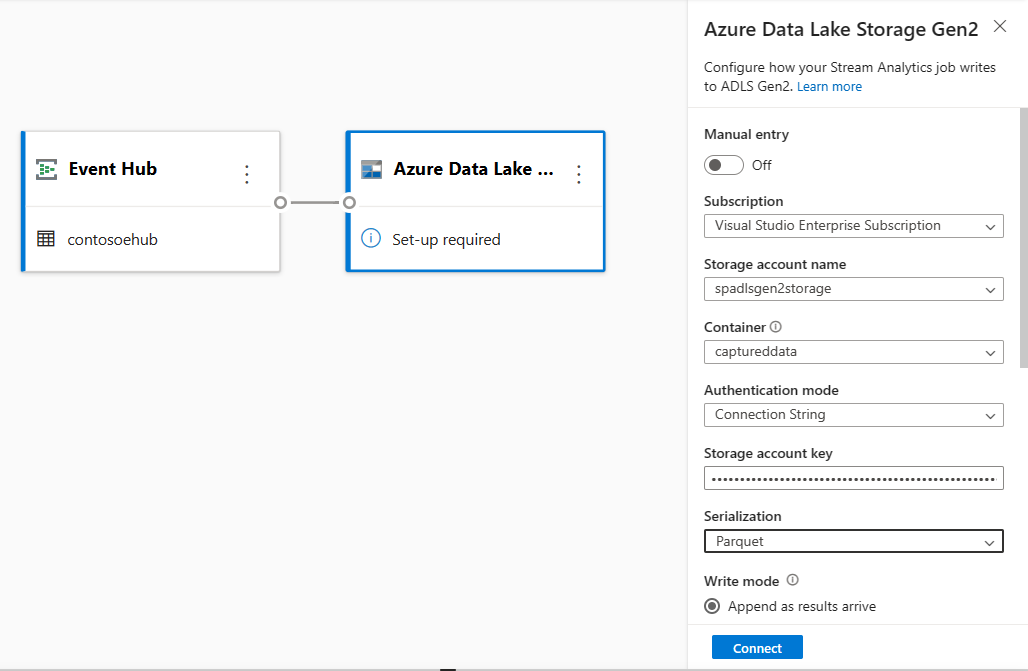
[Azure Data Lake Storage Gen2] タイルを選択して構成を編集します。
[Azure Data Lake Storage Gen2] 構成ページで、次の手順を行います。
ドロップダウン メニューから [サブスクリプション]、[ストレージ アカウント名]、[コンテナー] を選択します。
[サブスクリプション] が選択されると、[認証方法] と [ストレージ アカウント キー] が自動的に入力されます。
[シリアル化] 形式に [Parquet] を選択します。
ストリーミング BLOB の場合、ディレクトリのパス パターンは動的な値であると想定されます。 日付を、BLOB のファイルパスの一部にする必要があります。これは、
{date}として参照されます。 カスタム パス パターンの詳細については、「Azure Stream Analytics でのカスタム BLOB 出力のパーティション分割」を参照してください。![BLOB の接続構成を編集する [BLOB] ウィンドウを示す最初のスクリーンショット。](media/capture-event-hub-data-parquet/blob-configuration.png)
[接続] を選択します
接続が確立されると、出力データに存在するフィールドが表示されます。
コマンド バーで 「保存」 を選択して、構成を保存します。
![コマンド バーで [保存] ボタンが選択されていることを示すスクリーンショット。](media/capture-event-hub-data-parquet/save-configuration.png)
コマンド バーで [開始] を選択して、データをキャプチャするストリーミング フローを開始します。 次に、[Stream Analytics ジョブの開始] ウィンドウで次の手順を行います。
出力開始時刻を選択します。
価格プランを選択します。
ジョブを実行するストリーミング ユニット (SU) の数を選択します。 SU は、Stream Analytics ジョブを実行するために割り当てられているコンピューティング リソースを表しています。 詳細については、Azure Stream Analytics のストリーミング ユニットに関するページを参照してください。
![出力の開始時刻、ストリーミング ユニット、エラー処理を設定する [Stream Analytics ジョブの開始] ウィンドウを示すスクリーンショット。](media/capture-event-hub-data-parquet/start-job.png)
イベント ハブの [データの処理] ページの [Stream Analytics ジョブ] タブに Stream Analytic ジョブが表示されます。
![[データの処理] ページの Stream Analytics ジョブを示すスクリーンショット。](media/capture-event-hub-data-parquet/process-data-page-jobs.png)


![[Data Preview] (データのプレビュー) の下にサンプル データが示されているスクリーンショット。](media/capture-event-hub-data-parquet/edit-fields.png#lightbox)

![BLOB の接続構成を編集する [BLOB] ウィンドウを示す最初のスクリーンショット。](media/capture-event-hub-data-parquet/blob-configuration.png#lightbox)
![出力の開始時刻、ストリーミング ユニット、エラー処理を設定する [Stream Analytics ジョブの開始] ウィンドウを示すスクリーンショット。](media/capture-event-hub-data-parquet/start-job.png#lightbox)
![[データの処理] ページの Stream Analytics ジョブを示すスクリーンショット。](media/capture-event-hub-data-parquet/process-data-page-jobs.png#lightbox)
出力の確認
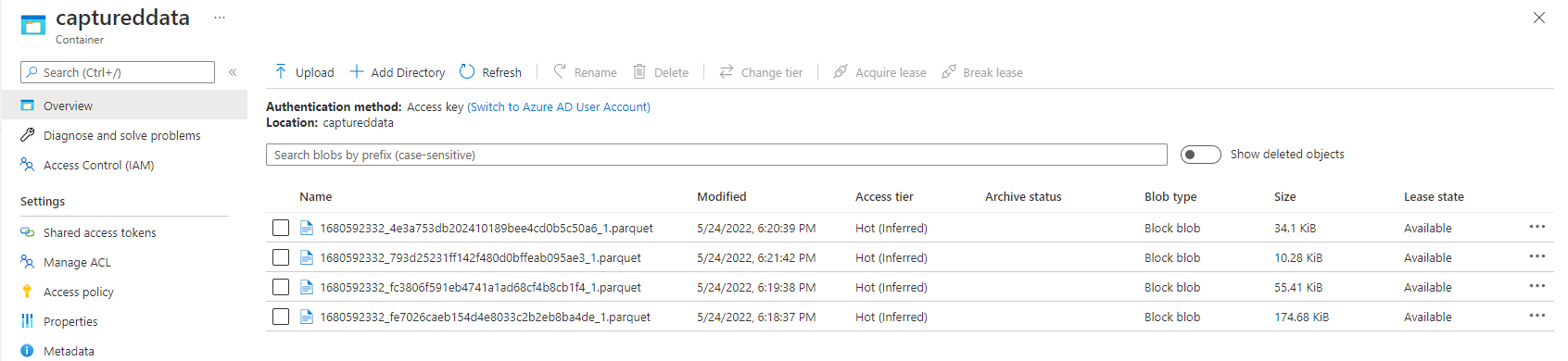
イベント ハブの [Event Hubs インスタンス] ページで、[データの生成] を選択し、データセットに [Stock data] を選択してから、[送信] を選択してサンプル データをイベント ハブに送信します。
Parquet ファイルが Azure Data Lake Storage コンテナーに生成されていることを確認します。
左側のメニューで [データの処理] を選択します。 [Stream Analytics ジョブ] タブに切り替えます。[メトリックを開く] を選択して監視します。
![[メトリックを開く] リンクの選択を示すスクリーンショット。](media/capture-event-hub-data-parquet/open-metrics-link.png)
入力イベントと出力イベントを示すメトリックのスクリーンショットの例を次に示します。

![[メトリックを開く] リンクの選択を示すスクリーンショット。](media/capture-event-hub-data-parquet/open-metrics-link.png#lightbox)

次の手順
これで、Stream Analytics のノー コード エディターを使用して、Event Hubs のデータを Parquet 形式で Azure Data Lake Storage Gen2 にキャプチャするジョブを作成する方法を確認しました。 次は、Azure Stream Analytics の詳細と、作成したジョブを監視する方法について学習します。