モデル ビルダーの概要としくみ
ML.NET モデル ビルダーは、直観的なグラフィックスでカスタムの機械学習モデルを構築、トレーニング、展開できる Visual Studio 拡張機能です。 自動機械学習 (AutoML) を使用して、さまざまな機械学習アルゴリズムと設定が探索され、シナリオに最適なアルゴリズムを見つけるのに役立ちます。
モデル ビルダーは機械学習の専門知識がなくても使用できます。 必要なものはいくつかのデータと解決すべき問題です。 モデル ビルダーでは、.NET アプリケーションにモデルを追加するコードが生成されます。

Model Builder プロジェクトを作成する
Model Builder を初めて起動すると、プロジェクトに名前を付け、そのプロジェクト内に mbconfig 構成ファイルを作成することが求められます。 mbconfig ファイルでは、セッションを再度開けるように Model Builder で行ったすべての操作が記録されます。
トレーニング後、*.mbconfig ファイルの下に次の 3 つのファイルが生成されます。
- Model.consumption.cs: このファイルには、
ModelInputとModelOutputのスキーマ、さらにモデルを使用するために生成されたPredict関数が含まれています。 - Model.training.cs: このファイルには、モデルのトレーニングのために Model Builder によって選択されたトレーニング パイプライン (データ変換、アルゴリズム、アルゴリズム ハイパーパラメーター) が含まれています。 このパイプラインを使用して、モデルを再トレーニングできます。
- Model.zip: これは、トレーニング済みの ML.NET モデルを表すシリアル化された zip ファイルです。
mbconfig ファイルを生成すると、名前の入力が求められます。 この名前は、消費、トレーニング、モデルの各ファイルに適用されます。 この場合、使用される名前は Model です。
シナリオ
さまざまなシナリオをモデル ビルダーに取り込み、自分のアプリケーションのための機械学習モデルを生成できます。
シナリオは、自分のデータを使用して行う予測の種類を説明するものです。 次に例を示します。
- 過去の販売データに基づいて今後の製品売上高を予測する。
- 顧客のレビューに基づいてセンチメントを肯定的と否定的に分類する。
- 銀行取引が不正であるかどうかを検出する。
- 顧客がフィードバックした問題を社内の該当チームに送信する。
各シナリオは、次のような異なる機械学習タスクにマッピングされます。
| タスク | シナリオ |
|---|---|
| 二項分類 | データ分類 |
| 多クラス分類 | データ分類 |
| 画像の分類 | 画像の分類 |
| テキスト分類 | テキスト分類 |
| 回帰 | 値の予測 |
| 推奨事項 | 推奨事項 |
| 予測 | 予測 |
たとえば、センチメントをポジティブまたはネガティブとして分類するシナリオは、二項分類タスクに該当します。
ML.NET でサポートされているさまざまな ML タスクに関する詳細については、「ML.NET での機械学習のタスク」を参照してください。
自分に最適な機械学習シナリオとは?
モデル ビルダーでは、シナリオを選択する必要があります。 シナリオの種類は、どのような種類の予測を行おうとしているかによって異なります。
表形式
データ分類
分類は、データをカテゴリに分類するために使用されます。
サンプル入力
サンプル出力
| SepalLength | SepalWidth | 花びらの長さ | 花びらの幅 | 種 |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 予測される種 |
|---|
| setosa |
値の予測
回帰タスクに属する値の予測は、数字の予測に使用されます。
サンプル入力
サンプル出力
| vendor_id | rate_code | passenger_count | trip_time_in_secs | trip_distance | payment_type | fare_amount |
|---|---|---|---|---|---|---|
| CMT | 1 | 1 | 1271 | 3.8 | CRD | 17.5 |
| 予測料金 |
|---|
| 4.5 |
推奨事項
推奨事項シナリオでは、他のユーザーとの好きや嫌いの類似度に基づいて、特定のユーザーに対する提案項目の一覧が予測されます。
ユーザーのセットと、"製品" のセット (購入する品目、映画、本、テレビ番組など)、およびそれらの製品に対するユーザーの "評価" のセットがある場合は、推奨事項シナリオを使用できます。
サンプル入力
サンプル出力
| UserId | 製品 ID | Rating |
|---|---|---|
| 1 | 2 | 4.2 |
| 予測された評価 |
|---|
| 4.5 |
予測
予測シナリオでは、時系列または季節コンポーネントを含む履歴データが使用されます。
予測シナリオを使用して、製品の需要または販売を予測できます。
サンプル入力
サンプル出力
| 日 | SaleQty |
|---|---|
| 1970 年 1 月 1 日 | 1000 |
| 3 日間の予測 |
|---|
| [1000,1001,1002] |
Computer Vision
画像の分類
イメージ分類は、さまざまなカテゴリのイメージ特定に使用されます。 これには、さまざまな種類の地形、動物、製造上の不具合などが含まれます。
一連のイメージがあり、イメージをさまざまなカテゴリに分類したいときは、イメージ分類シナリオを使用できます。
サンプル入力
サンプル出力

| 予測ラベル |
|---|
| 犬 |
オブジェクトの検出
オブジェクト検出は、画像内のエンティティの特定と分類に使用されます。 画像に含まれる車や人を見つけ、識別します。
オブジェクト検出は、画像に異なる種類のオブジェクトが複数含まれる場合に利用できます。
サンプル入力
サンプル出力

自然言語処理
テキスト分類
テキスト分類では、生テキスト入力が分類されます。
一連のドキュメントまたはコメントのセットがあり、それらをさまざまなカテゴリに分類したいときは、テキスト分類シナリオを使用できます。
入力の例
出力例
| 確認 |
|---|
| 私は本当にこのステーキが好きです! |
| センチメント |
|---|
| 正 |
環境
シナリオに基づき、お使いのコンピューター上のローカル環境で、または Azure 上のクラウドで、機械学習モデルをトレーニングできます。
ローカル環境でトレーニングする場合は、コンピューター リソース (CPU、メモリ、ディスク) の制約内で作業します。 クラウドでトレーニングする場合は、シナリオのニーズに合わせて、リソースをスケールアップできます (特に大規模なデータセット)。
| シナリオ | ローカル CPU | ローカル GPU | Azure |
|---|---|---|---|
| データ分類 | ✔️ | ❌ | ❌ |
| 値の予測 | ✔️ | ❌ | ❌ |
| 推奨 | ✔️ | ❌ | ❌ |
| 予測 | ✔️ | ❌ | ❌ |
| 画像分類 | ✔️ | ✔️ | ✔️ |
| 物体検出 | ❌ | ❌ | ✔️ |
| テキスト分類 | ✔️ | ✔️ | ❌ |
データ
シナリオを選択すると、Model Builder からデータセットを提供するように求められます。 このデータはモデルをトレーニングし、評価し、シナリオに最適なモデルを選択するために使用されます。
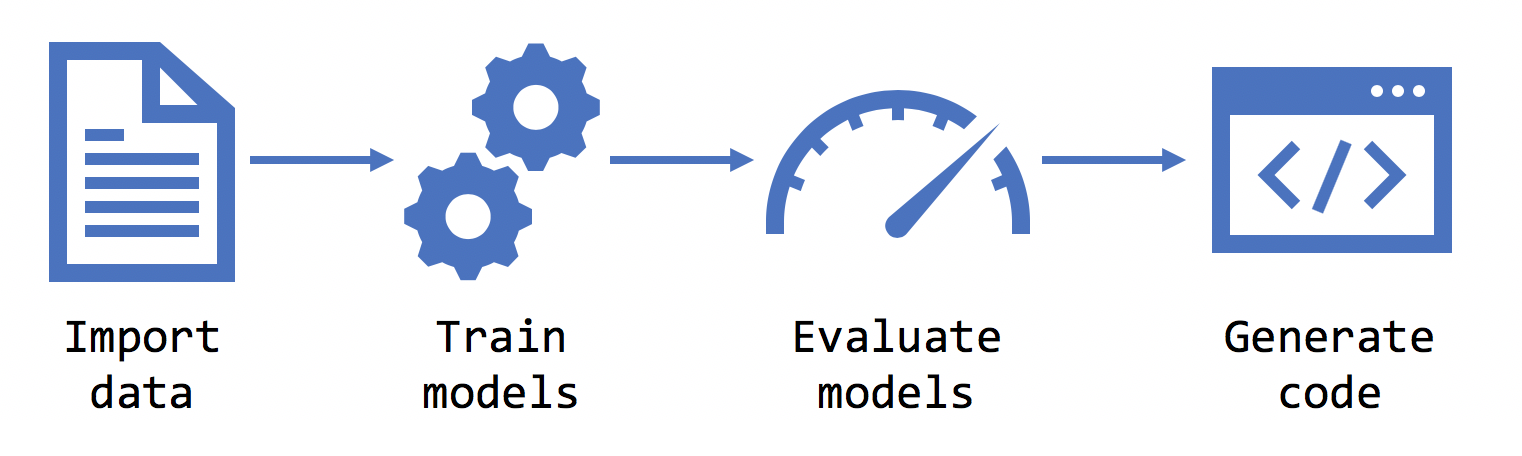
Model Builder は、.tsv、.csv、.txt 形式のデータセットと、SQL データベース形式をサポートしています。 .txt ファイルがある場合、列は ,、; または \t で区切る必要があります。
データセットがイメージで構成されている場合、サポートされているファイルの種類は .jpg と .pngです。
詳細については、「モデル ビルダーにトレーニング データを読み込む」を参照してください。
予測する出力を選択します (ラベル)
データセットは、トレーニング サンプルの行と属性の列からなるテーブルです。 各行の内容:
- ラベル (予測する属性)
- 特徴 (ラベルを予測するための入力として使用される属性)
家の価格予測シナリオの場合、特徴は次のようになります。
- 家の面積。
- 寝室と浴室の数。
- 郵便番号。
ラベルは、面積、寝室数、浴室数、郵便番号からなるその行の過去の住宅価格です。
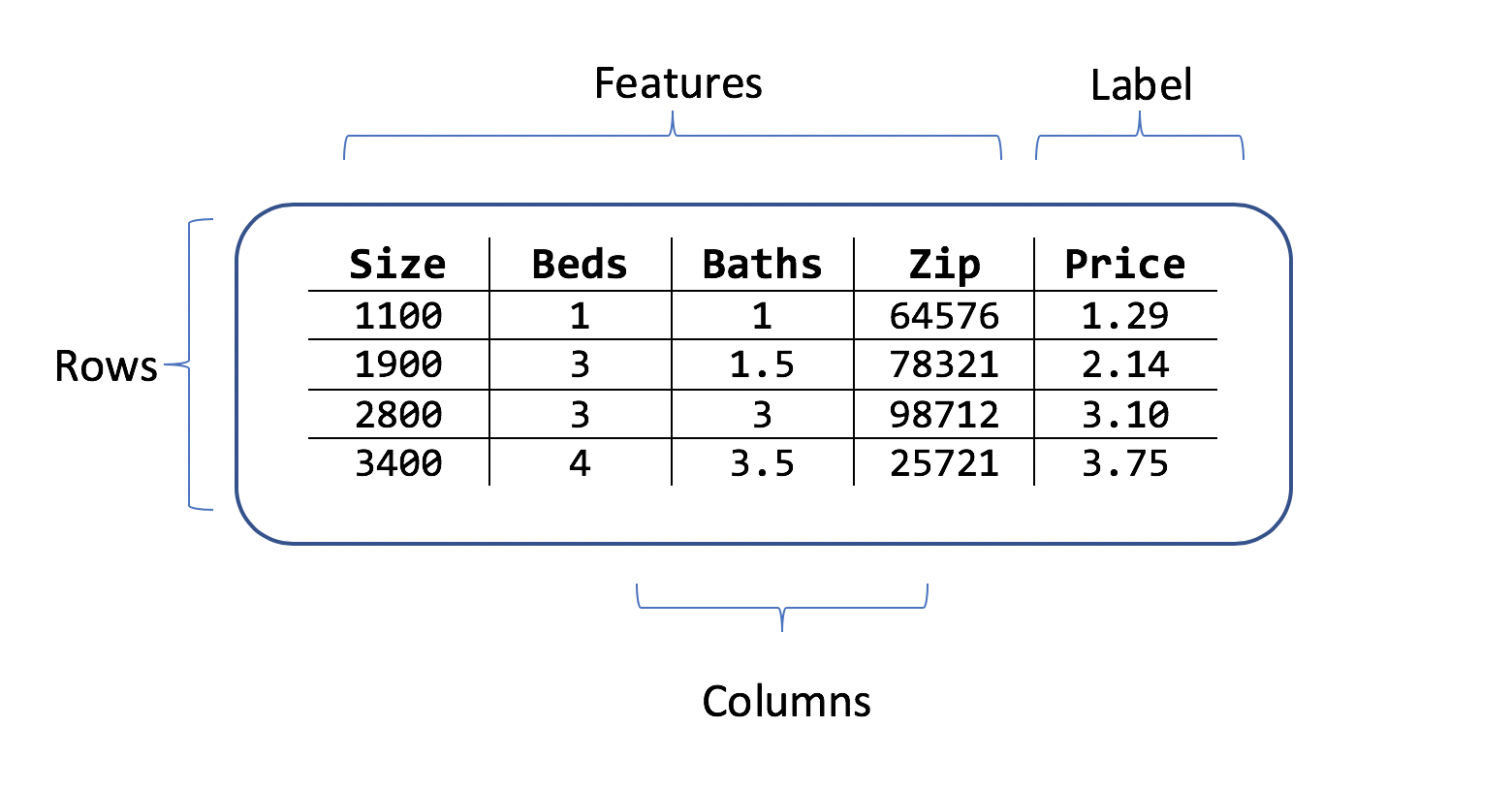
データセットの例
独自のデータをまだ用意していない場合、次のいずれかのデータセットをお試しください。
| シナリオ | 例 | データ | Label | 機能 |
|---|---|---|---|---|
| 分類 | 売上の異常を予測する | 製品の売上データ | 製品の売上 | 月 |
| Web サイトのコメントのセンチメントを予測する | Web サイトのコメント データ | ラベル (否定的なセンチメントのときは 1、肯定的なセンチメントのときは 0) | コメント、年度 | |
| クレジット カード取引の詐欺を予測する | クレジット カードのデータ | クラス (詐欺の場合は 1、それ以外の場合 0) | 金額、V1-V28 (匿名化された特徴) | |
| GitHub リポジトリでのイシューの種類を予測する | GitHub 問題のデータ | 面グラフ | タイトル、説明 | |
| 値の予測 | タクシー料金を予測する | タクシーの料金データ | Fare | 乗車時間、距離 |
| 画像の分類 | 花の種類を予測する | 花の画像 | 花の種類: デイジー、タンポポ、バラ、ヒマワリ、チューリップ | イメージ データ自体 |
| 推奨事項 | 好きな映画を予測する | 映画の評価 | ユーザー、映画 | Ratings |
トレーニング
シナリオ、環境、データ、ラベルを選択すると、モデル ビルダーによってモデルがトレーニングされます。
トレーニングとは何か?
トレーニングとは、モデル ビルダーがシナリオの質問に対する回答方法をモデルに教える自動プロセスです。 トレーニングが終わると、モデルは以前に見たことがない入力データで予測できます。 たとえば、住宅価格を予測しているなら、新しい住宅が市場に出たとき、その販売価格を予測できます。
モデル ビルダーで使用される機械学習は自動化されているため (AutoML)、トレーニング中に、ユーザーが入力したり、調整したりする必要がありません。
どのくらいの時間、トレーニングしますか?
モデル ビルダーは、AutoML を使用して複数のモデルを探索し、最適なパフォーマンスを発揮するモデルを見つけます。
トレーニング期間を長くすると、AutoML はより広い設定範囲でさらに多くのモデルを探索できます。
以下の表は、ローカル コンピューターにある一連のサンプル データセットで、優れたパフォーマンスを得るのに要した平均時間を示しています。
| データセットのサイズ | トレーニングの平均時間 |
|---|---|
| 0 - 10 MB | 10 秒 |
| 10 - 100 MB | 10 分 |
| 100 - 500 MB | 30 分 |
| 500 MB - 1 GB | 60 分 |
| 1 GB 超 | 3 時間超 |
これらは参考用の数字に過ぎません。 トレーニングの正確な長さは、次の条件によって異なります。
- モデルへの入力として使用されている特徴 (列) の数。
- 列の型。
- ML タスク。
- トレーニングに使用されるマシンの CPU、ディスク、およびメモリのパフォーマンス。
通常は、データセットとして 100 行より多くの行を使用することをお勧めします。それ以下では、何も結果が生成されない場合があります。
評価
評価は、モデルがどのくらい適切かを測定するプロセスです。 モデル ビルダーは、トレーニングしたモデルを使用して新しいテスト データで予測し、予測の精度を測定します。
モデル ビルダーでは、トレーニング セットとテスト セットにトレーニング データが分割されます。 トレーニング データ (80%) はモデルのトレーニングに使用されます。テスト データ (20%) はモデルの評価のための控えとなります。
モデルのパフォーマンスを把握するには
シナリオが機械学習タスクにマップされます。 各 ML タスクには、独自の評価メトリック セットがあります。
値の予測
値の予測問題の既定のメトリックは RSquared で、RSquared の値の範囲は 0 から 1 です。 最適な値は 1 です。つまり、RSquared の値が 1 に近いほど、モデルのパフォーマンスが向上します。
絶対損失、二乗損失、RMS 損失など、報告されるその他のメトリックは追加メトリックで、モデルのパフォーマンスを理解し、それを他の値の予測モデルと比較する目的で使用できます。
分類 (2 つのカテゴリ)
分類問題の既定のメトリックは正確度です。 正確度は、テスト データセットに基づいてモデルが正しく予測する比率を定めるものです。 100%、つまり 1.0 に近ければ近いほど、良いということになります。
真陽性率と擬陽性率を測定する AUC (曲線下面積) など、報告されるその他のメトリックは 0.50 以上であれば、モデルは許容されます。
F1 スコアなどの追加メトリックを使用すると、精度と再現率のバランスを制御できます。
分類 (3 つ以上のカテゴリ)
多クラス分類の既定のメトリックはマイクロ正確度です。 マイクロ正確度が 100%、つまり 1.0 に近ければ近いほど、良いということになります。
多クラス分類のもう 1 つの重要なメトリックはマクロ正確度です。マイクロ正確度と同様、1.0 に近いほど良いことになります。 これらの 2 種類の正確度は次のように考えるとよいでしょう。
- マイクロ正確度 — 受け取るチケットが適切なチームに分類される頻度はどのくらいですか。
- マクロ正確度: 平均的なチームの場合、受け取るチケットがそのチームにとって正しい頻度はどのくらいですか。
評価メトリックの詳細
詳しくは、モデルの評価メトリックに関する記事をご覧ください。
改善
モデルのパフォーマンス スコアが予想ほど良くない場合、次のことができます。
トレーニングの時間を長くします。 時間を増やせば、自動化された機械学習エンジンによって実験されるアルゴリズムや設定が増えます。
データを追加します。 高品質の機械学習モデルをトレーニングするにはデータ量が十分ではないことがあります。データセットの例の数が少ない場合は特にこれが当てはまります。
データのバランスを調整します。 分類タスクの場合、カテゴリ全体でトレーニング セットのバランスが取れていることを確認します。 たとえば、100 のトレーニング例に対してクラスが 4 つあるとき、90 個のレコードに最初の 2 つのクラス (tag1 と tag2) を使用するが、残りの 2 つ (tag3 と tag4) は残りの 10 個のレコードでのみ使用する場合、データにバランスが欠け、tag3 か tag4 を正しく予測することがモデルにとって難しくなります。
消費
評価フェーズ後、モデル ビルダーからモデル ファイルとコードが出力されます。このコードを使用し、モデルをアプリケーションに追加できます。 ML.NET モデルは zip ファイルで保存されます。 モデルを読み込み、使用するためのコードがソリューションに新しいプロジェクトとして追加されます。 モデル ビルダーからはサンプル コンソール アプリも追加されます。これを実行すると、実際に動作するモデルを確認できます。
また、Model Builder には、モデルを使用するプロジェクトを作成するオプションが用意されています。 現在、Model Builder では次のプロジェクトが作成されます。
- コンソール アプリ: モデルから予測を行う .NET コンソール アプリケーションが作成されます。
- Web API: インターネット上でモデルを使用できるようにする ASP.NET Core Web API が作成されます。
次の内容
Model Builder Visual Studio 拡張機能のインストール。
価格予測または回帰のシナリオをお試しください。
.NET
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示