Power Query のクエリ評価とクエリ フォールディングの概要
この記事では、M クエリがどのように処理され、データ ソース要求に変換されるかについて、基本的な概要を説明します。
Power Query の M スクリプト
すべてのクエリは、Power Query によって作成されたか、高度なエディターで自分が手動で作成したか、空白のドキュメントを使って入力したかに関わらず、Power Query M 式言語の関数と構文で構成されます。 このクエリは Power Query エンジンによって解釈および評価され、その結果が出力されます。 M スクリプトは、クエリを評価するために必要な一連の指示の役目を果たします。
ヒント
M スクリプトは、データの準備方法を説明するレシピと考えることができます。
M スクリプトを作成する最も一般的な方法は、Power Query エディターを使うことです。 たとえば、SQL Server データベースなどのデータ ソースに接続すると、画面の右側に、適用されたステップと呼ばれるセクションがあることに注意してください。 このセクションには、クエリで使用されるすべての手順または変換が表示されます。 この意味では、Power Query エディターは、必要な変換のために適した M スクリプトを作成し、使用するコードが有効になるようにするのに役立つ、インターフェイスとして機能します。
Note
M スクリプトは、次のために Power Query エディターで使用されます。
- クエリを一連の手順として表示し、新しいステップの作成または変更を行える。
- ダイアグラム ビューを表示する。

上の図では、以下のステップを含む [適用されたステップ] セクションが強調表示されています。
- [ソース]: データ ソースへの接続を作成します。 この場合は、SQL Server データベースへの接続です。
- [ナビゲーション]: データベース内の特定のテーブルに移動します。
- [削除された他の列]: 保持するテーブルの列を選択します。
- [並べ替えられた行]: 1 つ以上の列を使ってテーブルを並べ替えます。
- 上位の行を保持する: テーブルの一部の行のみをテーブルの先頭から保持するようにテーブルをフィルター処理します。
この一連のステップ名は、Power Query によって作成された M スクリプトを表示するためのわかりやすい方法です。 完全な M スクリプトを表示するには、いくつかの方法があります。 Power Query の [ビュー] タブで、[詳細エディター] を選択できます。[ホーム] タブの [クエリ] グループから [詳細エディター] を選択することもできます。Power Query の一部のバージョンでは、[表示] タブに移動し、[レイアウト] グループから [スクリプト ビュー]>[クエリのスクリプト] を選択して、クエリのスクリプトが表示されるように数式バーのビューを変更することもできます。

[適用されたステップ] ペインにある名前のほとんどが、M スクリプトでも同様に使用されています。 クエリの各ステップは、M 言語で 識別子 と呼ばれるものを使って名前が付けられます。 M ではステップ名の前後に余分な文字がラップされる場合がありますが、これらの文字は [適用されたステップ] には表示されません。 #"Kept top rows" はその一例です。これは、これらの余分な文字のために 引用符で囲まれた識別子 として分類されます。 引用符で囲まれた識別子を使用すると、キーワード、空白、コメント、演算子、区切り記号など、0 個以上の Unicode 文字からなる任意のシーケンスを識別子として使用できます。 M 言語の 識別子 の詳細 については、字句の構造に関する記事を参照してください。
Power Query エディターを使用してクエリを変更すると、クエリの M スクリプトが自動的に更新されます。 たとえば、前のイメージを開始点として使用して、[上位行を保持する] ステップ名を [上位 20 行] に変更すると、スクリプト ビューでこの変更が自動的に更新されます。

Power Query エディターを使って M スクリプトのすべてまたは大部分を作成することをお勧めしますが、M スクリプトの一部を手動で追加したり、変更したりすることもできます。 M 言語の詳細については、M 言語の公式ドキュメント サイトを参照してください。
Note
M スクリプトは M コードとも呼ばれ、Power Query M 言語を使用するすべてのコードに使用される用語です。 この記事のコンテキストでは、M スクリプトという用語が、Power Query クエリ内にあり、詳細エディター ウィンドウまたは数式バーのスクリプト ビューからアクセスできるコードを指す場合もあります。
Power Query のクエリ評価
次の図は、Power Query でクエリが評価される際に発生するプロセスを説明しています。
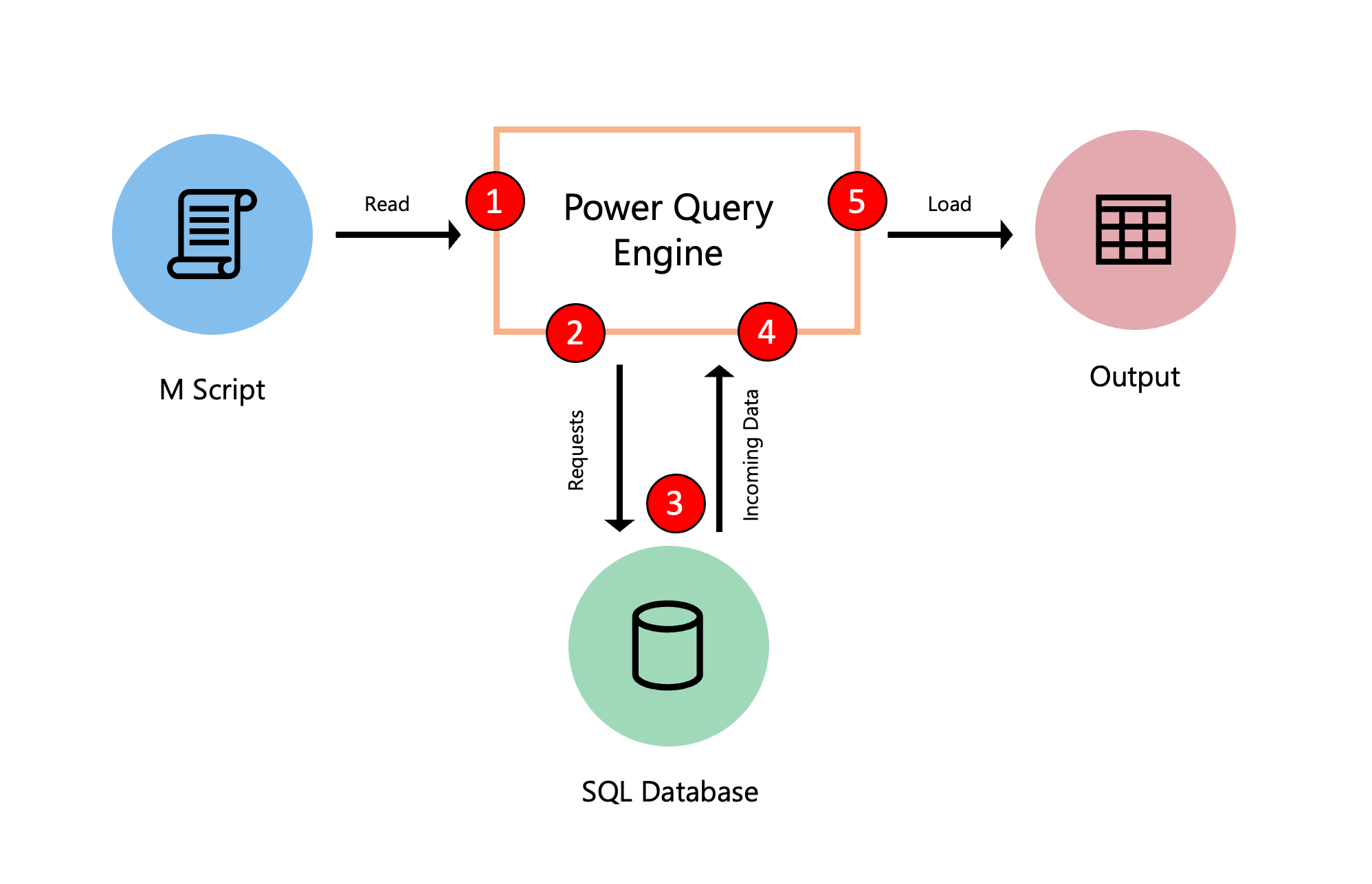
- (詳細エディター内にある) M スクリプトが Power Query エンジンに送信されます。 資格情報やデータ ソースのプライバシー レベルなど、その他の重要な情報も含まれています。
- Power Query により、データ ソースから抽出する必要のあるデータが決定され、データ ソースに要求が送信されます。
- データ ソースでは、要求されたデータを Power Query に転送することで、Power Query からの要求に応答します。
- Power Query がデータ ソースから受信データを受け取り、必要に応じて Power Query エンジンを使用して変換を実行します。
- 前のポイントから生成された結果がターゲットに読み込まれます。
Note
この例では SQL Database をデータ ソースとして使用するクエリを示していますが、その概念はデータ ソースの使用の有無にかかわらず当てはまります。
Power Query によって M スクリプトが読み取られると、最適化プロセスを通じてスクリプトが実行され、より効率的にクエリが評価されます。 このプロセスでは、データ ソースにオフロードできるクエリのステップ (変換) が判断されます。 また、Power Query エンジンを使用して評価する必要があるその他のステップも判断されます。 この最適化プロセスは クエリ フォールディング と呼ばれ、Power Query によって可能な限り多くの実行をデータ ソースにプッシュし、クエリの実行を最適化することが試みられます。
重要
Power Query M 式言語 (M 言語とも呼ばれます) のすべての規則が適用されます。 特に、遅延評価 は最適化プロセス中に重要な役割を果たします。 このプロセスでは、Power Query によって、具体的にクエリのどの変換を評価する必要があるかが把握されます。 また、Power Query によって、クエリの出力に必要ないため評価する必要がないその他の変換も把握されます。
さらに、複数のソースが関係する場合は、クエリを評価するときに、各データ ソースのデータ プライバシー レベルが考慮されます。 詳細については、「データ プライバシー ファイアウォールの背景」を参照してください
次の図は、この最適化プロセスで実行される各ステップを示しています。
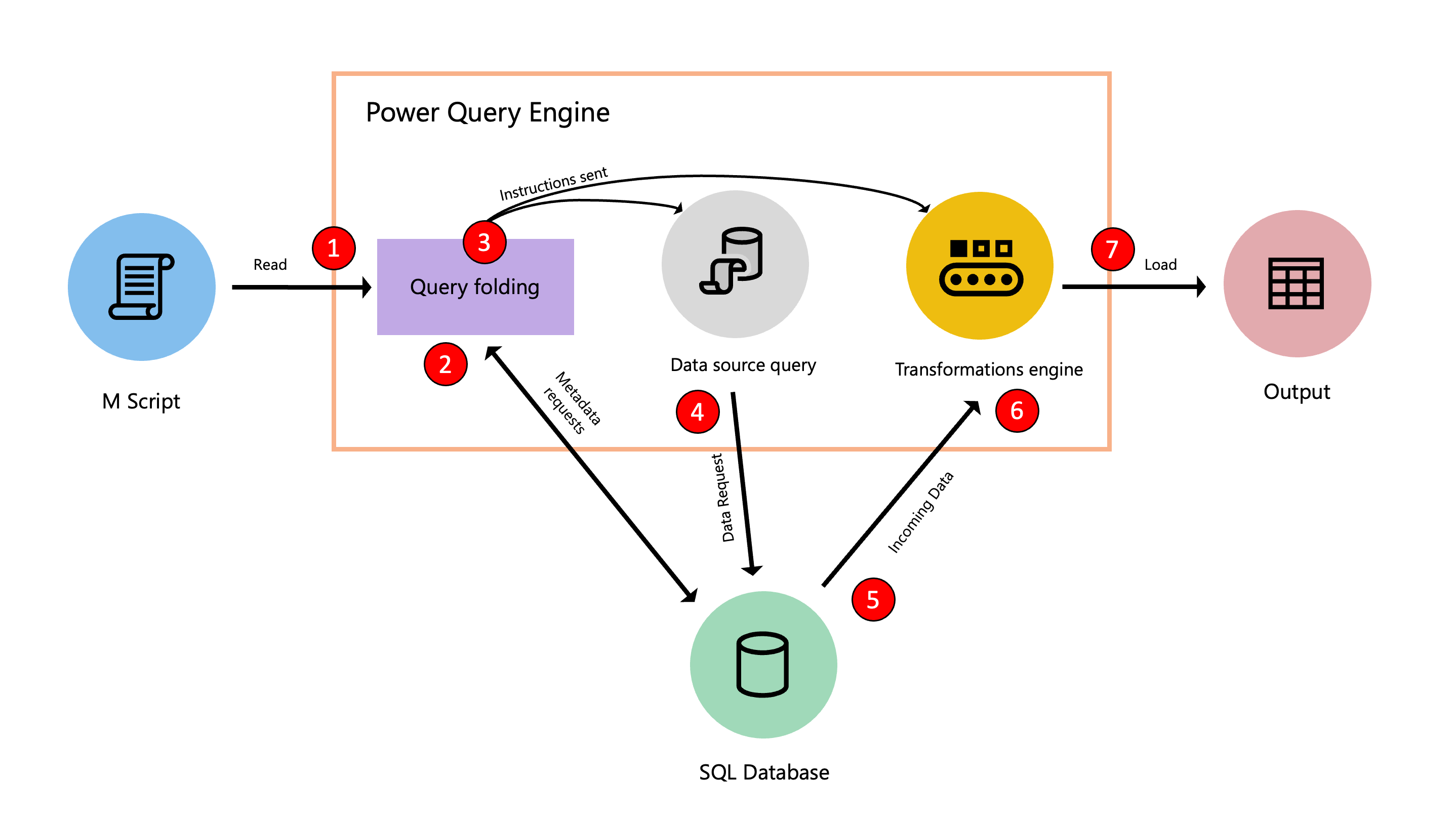
- (詳細エディター内にある) M スクリプトが Power Query エンジンに送信されます。 資格情報やデータ ソースのプライバシー レベルなど、その他の重要な情報も提供されます。
- クエリ フォールディング メカニズムは、メタデータ リクエストをデータ ソースに送信して、データ ソースの機能、テーブル スキーマ、データ ソースの異なるテーブル間の関係などを判断します。
- 受信したメタデータに基づいて、クエリ フォールディング メカニズムによって、データ ソースから抽出する情報と、Power Query エンジン内で実行する必要がある変換のセットが決定されます。 その指示は他の 2 つのコンポーネントに送信されます。そこで、データ ソースからのデータの取得と、必要に応じた Power Query エンジンでの受信データの変換が行われます。
- Power Query の内部コンポーネントが指示を受け取ると、Power Query はデータ ソース クエリを使用してデータ ソースに要求を送信します。
- データ ソースは Power Query から要求を受け取り、データを Power Query エンジンに転送します。
- データが Power Query 内に入った後、Power Query 内の変換エンジン (マッシュアップ エンジンとも呼ばれます) によって、データ ソースにフォールディングまたはオフロードできなかった変換が実行されます。
- 前のポイントから生成された結果がターゲットに読み込まれます。
Note
M スクリプトで使用される変換とデータ ソースに応じて、Power Query は受信データをストリーミングまたはバッファーするかどうかを決定します。
クエリ フォールディングの概要
クエリ フォールディングの目的は、クエリの評価の多くを、クエリの変換を計算できるデータ ソースにオフロードまたはプッシュすることです。
クエリ フォールディング メカニズムでは、M スクリプトをデータ ソースが解釈して実行できる言語に変換することで、この目的を達成します。 次に、その評価をデータ ソースにプッシュし、その評価の結果を Power Query に送信します。
多くの場合、この操作では、データ ソースから必要なすべてのデータを抽出し、Power Query エンジンで必要なすべての変換を実行するよりも、クエリの実行が高速になります。
データの取得エクスペリエンスを使用する場合、Power Query に従ってプロセスを実行し、最終的にデータ ソースに接続することができます。 これを行う場合、Power Query によって、データへのアクセス関数として分類される M 言語の一連の関数が使用されます。 これらの特定の関数では、データ ソースが理解できる言語を使い、データ ソースに接続するためのメカニズムとプロトコルが使用されます。
ただし、クエリ内の後続のステップは、クエリ フォールディング メカニズムによって最適化が試みられるステップまたは変換です。 その後、Power Query エンジンを使って処理する代わりに、データ ソースにオフロードできるかどうかがチェックされます。
重要
すべてのデータ ソース関数 (一般にクエリの [ソース] ステップとして表示されます) では、データ ソースのデータに対してそのネイティブ言語でクエリを実行します。 クエリ フォールディング メカニズムは、データ ソース関数の後に、クエリに適用されるすべての変換に対して使用されます。これにより、それらを変換して 1 つのデータ ソース クエリにまとめるか、データ ソースにオフロードできるできるだけ多くの変換にすることができます。
クエリの構造に応じて、次の 3 つのクエリ フォールディング メカニズムの結果が考えられます。
- 完全なクエリ フォールディング: クエリの変換がすべてデータ ソースにプッシュされ、Power Query エンジンでの処理が最小限になる場合。
- 部分的なクエリ フォールディング: クエリの (すべてではなく) 一部の変換だけがデータ ソースにプッシュできる場合。 この場合、変換のサブセットのみがデータ ソースで実行され、クエリの変換の残りの部分は Power Query エンジンで実行されます。
- クエリ フォールディングなし: データ ソースのネイティブ クエリ言語に変換できない変換がクエリに含まれている場合。その原因は、その変換がサポートされていないか、コネクタでクエリ フォールディングがサポートされていないかのいずれかです。 この場合、Power Query ではデータ ソースから生データを取得し、Power Query エンジンを使って、Power Query エンジン レベルで必要な変換を処理することで、必要な出力を生成します。
Note
クエリ フォールディング メカニズムは、主に、Microsoft SQL Server や OData フィードなどをはじめとする、構造化データ ソース用のコネクタで使用できます。 最適化フェーズ中に、エンジンによってクエリ内のステップの順序が変更される場合があります。
処理リソースが多く、クエリ フォールディング機能を備えているデータ ソースを利用すると、Power Query エンジンではなくデータ ソースで処理が行われるため、クエリの読み込み時間を短縮できます。
関連するコンテンツ
クエリ フォールディング メカニズムで考えられる 3 つの結果の詳細な例については、「クエリ フォールディングの例」を参照してください。
[適用されたステップ] ペインにあるクエリ フォールディング インジケーターの詳細については、クエリ フォールディング インジケーター を参照してください。