AlwaysOn 可用性グループを使用した AD FS 展開の設定
地域的に分散された可用性の高いトポロジでは、次のことが実現されます。
- 単一障害点の排除: フェールオーバー機能を使用すると、地球上の一部のデータセンターの 1 つがダウンした場合でも、可用性の高い AD FS インフラストラクチャを実現できます。
- パフォーマンスの向上: 提案された展開を使用して、高パフォーマンスの AD FS インフラストラクチャを提供できます。
AD FS は、地域的に分散された可用性の高いシナリオ用に構成できます。 次のガイドでは、SQL AlwaysOn 可用性グループの AD FS の概要を説明し、展開に関する考慮事項とガイダンスを示します。
概要 - AlwaysOn 可用性グループ
AlwaysOn 可用性グループの詳細については、AlwaysOn 可用性グループの概要 (SQL Server) に関するページをご覧ください。
AD FS SQL Server ファームのノードの観点から見ると、AlwaysOn 可用性グループは、単一の SQL Server インスタンスをポリシー/アーティファクト データベースとして置き換えます。 可用性グループ リスナーは、クライアント (AD FS セキュリティ トークン サービス) が SQL に接続するために使用するものです。 次の図は、AlwaysOn 可用性グループと AD FS SQL Server ファームを示しています。
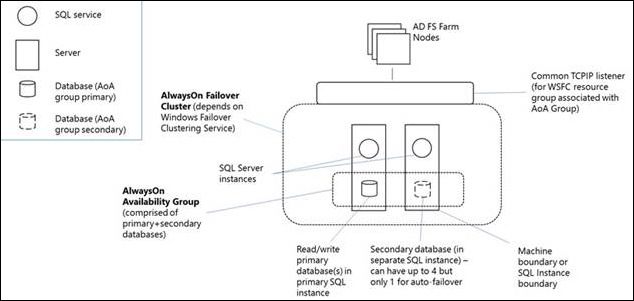
Always On 可用性グループ (AG) は、共にフェールオーバーする 1 つ以上のユーザー データベースです。 可用性グループは、1 つのプライマリ可用性レプリカと、共有ストレージを必要としないデータ保護のために SQL Server ログに基づくデータ移動を介して維持される 1 ~ 4 個のセカンダリ レプリカから構成されます。 各レプリカは、WSFC の別々のノードにある SQL Server のインスタンスによってホストされます。 可用性グループとこれに対応する仮想ネットワーク名は、WSFC クラスターのリソースとして登録されます。
プライマリ レプリカのノード上の可用性グループ リスナーは、受信クライアント要求に応答し、仮想ネットワーク名に接続します。そして、接続文字列の属性に基づいて各要求を適切な SQL Server インスタンスにリダイレクトします。 フェールオーバーが発生した場合は、共有物理リソースの所有権を他のノードに転送する代わりに、WSFC を利用して他の SQL Server インスタンス上でセカンダリ レプリカを再構成し、可用性グループのプライマリ レプリカにします。 その後、可用性グループの仮想ネットワーク名リソースが、そのインスタンスに転送されます。 任意の時点で、可用性グループのデータベースのプライマリ レプリカをホストできるのは、1 つの SQL Server インスタンスだけです。すべての関連付けられたセカンダリ レプリカは別々のインスタンスに存在する必要があり、各インスタンスは別々の物理ノードに存在する必要があります。
注意
マシンが Azure 上で実行されている場合は、Azure 仮想マシンを設定し、リスナー構成が AlwaysOn 可用性グループと通信できるようにします。 詳細については、仮想マシン: SQL Always On リスナーに関するページを参照してください。
AlwaysOn 可用性グループのその他の概要については、Always On 可用性グループの概要 (SQL Server) に関するページを参照してください。
注意
組織が複数のデータセンター間でフェールオーバーを必要とする場合は、各データセンターにアーティファクト データベースを作成し、要求処理の待機時間を短縮するバックグラウンド キャッシュを有効にすることをお勧めします。 これを行うには、手順に従って SQL を微調整し、待機時間を短縮します。
展開の手引き
- AD FS 展開の目標に適したデータベースを検討してください。 AD FS でデータベースを使用する目的は、フェデレーション サービスに関連する構成データを保存することであり、場合によってはトランザクション データもこのデータベースに保存されます。 AD FS ソフトウェアでは、フェデレーション サービスのデータを保存するためのデータベースとして、内蔵の Windows Internal Database (WID) または Microsoft SQL Server 2008 以降を選択できるようになっています。 次の表は、WID および SQL データベースでサポートされる機能の違いの説明をまとめたものです。
| カテゴリ | 特徴量 | WID でのサポート | SQL でのサポート |
|---|---|---|---|
| AD FS 機能 | フェデレーション サーバー ファーム展開 | はい | はい |
| AD FS 機能 | SAML アーティファクト解決。 注: これは、SAML アプリケーションでは一般的ではありません。 | いいえ | はい |
| AD FS 機能 | SAML/WS-Federation トークン リプレイ検出。 注: AD FS が外部 IDP からトークンを受信する場合にのみ必要です。 AD FS がフェデレーション パートナーとして動作しない場合、この操作は必要ありません。 | いいえ | はい |
| データベース機能 | プル レプリケーションを使用する基本的なデータベース冗長化 (データベースの読み取り専用コピーをホストする 1 つ以上のサーバーが、ソース サーバー ホストで行われた変更内容をデータベースの読み取り/書き込みコピーに要求する) | いいえ | いいえ |
| データベース機能 | クラスタリングやミラーリング (データベース層) などの高可用性ソリューションを使用するデータベース冗長化 | いいえ | はい |
| 追加機能 | OAuth Authcode のシナリオ | はい | はい |
100 以上の信頼関係を持つ大規模な組織で、内部ユーザーと外部ユーザーの両方にフェデレーション アプリケーションまたはサービスへのシングル サインオン アクセスを提供する必要がある場合は、SQL をお勧めします。
構成されている信頼関係が 100 以下の組織の場合、WID はデータとフェデレーション サービスの冗長性を提供します (各フェデレーション サーバーは、同じファーム内の他のフェデレーション サーバーに変更をレプリケートします)。 WID は、トークン リプレイ検出またはアーティファクトの解決をサポートしておらず、最大で 30 個のフェデレーション サーバーをサポートしています。 展開の計画の詳細については、こちらを参照してください。
SQL Server 高可用性ソリューション
SQL Server を AD FS 構成データベースとして使用している場合は、SQL Server レプリケーションを使用して、AD FS ファームの geo 冗長性を設定できます。 Geo 冗長性は、アプリケーションがあるサイトから別のサイトに切り替えることができるように、地理的に離れた 2 つのサイト間でデータをレプリケートします。 これにより、1 つのサイトで障害が発生した場合でも、2 番目のサイトですべての構成データを使用できるようになります。 SQL が展開の目標に適したデータベースの場合は、この展開ガイドに進んでください。
このガイドでは、次の手順について説明します。
- AD FS を展開する
- AlwaysOn 可用性グループを使用するように AD FS を構成する
- フェールオーバー クラスタリングの役割をインストールする
- クラスター検証テストを実行する
- Always On 可用性グループを有効にする
- AD FS データベースをバックアップする
- AlwaysOn 可用性グループを作成する
- 2 番目のノードにデータベースを追加する
- 可用性グループに可用性レプリカを参加させる
- SQL 接続文字列を更新する
AD FS を展開する
注意
マシンが Azure 上で実行されている場合、リスナーが Always On 可用性グループと通信できるようにするには、仮想マシンを特定の方法で構成する必要があります。 構成の詳細については、Azure SQL Server VM での可用性グループのロード バランサーの構成に関するページを参照してください。
この展開ガイドでは、例として 2 つの SQL サーバーを含む 2 つのノード ファームについて説明します。 AD FS を展開するには、以下の最初のリンクに従って、AD FS 役割サービスをインストールします。 AoA グループ用に構成するには、その役割に対して追加の手順が必要になります。
AlwaysOn 可用性グループを使用するように AD FS を構成する
AlwaysOn 可用性グループを使用する AD FS ファームを構成するには、AD FS 展開手順を少し変更する必要があります。 各サーバー インスタンスで、同じバージョンの SQL が実行されていることを確認します。 Always On 可用性グループの前提条件、制限事項、および推奨事項の完全な一覧については、こちらを参照してください。
- AlwaysOn 可用性グループを構成する前に、バックアップするデータベースを作成する必要があります。 AD FS は、新しい AD FS SQL Server ファームの最初のフェデレーション サービス ノードのセットアップと初期構成の一部として、データベースを作成します。 SQL サーバーを使用して、既存のファームのデータベース ホスト名を指定します。 AD FS 構成の一部として、SQL 接続文字列を指定する必要があります。そのため、SQL インスタンスに直接接続する最初の AD FS ファームを構成する必要があります (これは一時的なものです)。 SQL サーバー接続文字列を使用した AD FS ファーム ノードの構成など、AD FS ファームの構成に関する具体的なガイダンスについては、「フェデレーション サーバーを構成する」を参照してください。
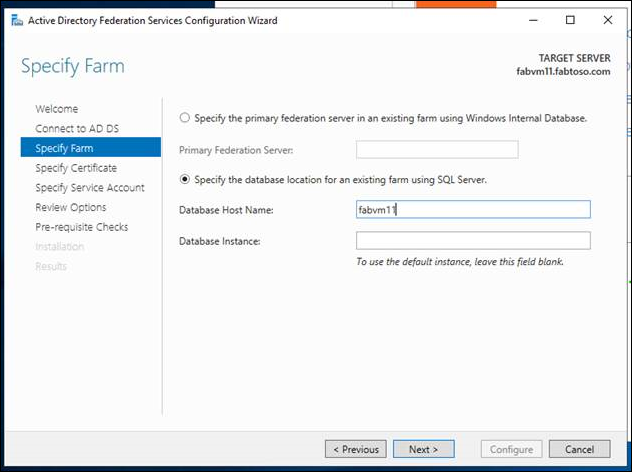
- SSMS を使用して対象のデータベース ホスト名に接続し、データベースへの接続を検証します。 フェデレーション ファームに別のノードを追加する場合は、対象のデータベースに接続します。
- AD FS ファームの SSL 証明書を指定します。
- ファームをサービス アカウントまたは gMSA に接続します。
- AD FS ファームの構成とインストールを完了します。
注意
Always On 可用性グループをインストールするには、SQL Server がドメイン アカウントで実行されている必要があります。 既定では、ローカル システムとして実行されます。
フェールオーバー クラスタリングの役割をインストールする
Windows Server フェールオーバー クラスター役割には、Windows Server サーバー フェールオーバー クラスターの詳細が表示されます。
- Server Manager を起動します。
- [管理] メニューで [役割と機能の追加] を選択します。
- [開始する前に] ページで、[次へ ] を選択します。
- [インストールの種類の選択] ページで [役割ベースまたは機能ベースのインストール] を選択してから、[次へ] を選択します。
- [対象サーバーの選択] ページで、この機能をインストールする SQL サーバーを選択し、[次へ] を選択します。
- [サーバーの役割の選択] ページで、 [次へ] を選択します。
- [機能の選択] ページで、[フェールオーバー クラスタリング] チェック ボックスをオンにします。
- [インストール オプションの確認] ページで、[インストール] を選択します。 フェールオーバー クラスタリング機能の場合はサーバーの再起動は必要ありません。
- インストールが完了したら、[閉じる] を選択します。
- フェールオーバー クラスター ノードとして追加する各サーバーに対してこの手順を繰り返します。
クラスター検証テストを実行する
- リモート サーバー管理ツールからフェールオーバー クラスター管理ツールをインストールしたコンピューター、またはフェールオーバー クラスタリング機能をインストールしたサーバーで、フェールオーバー クラスター マネージャーを起動します。 サーバーでこの操作を行うには、サーバー マネージャーを起動し、[ツール] メニューの [フェールオーバー クラスター マネージャー] を選択します。
- [フェールオーバー クラスター マネージャー] ペインで、[管理] の [構成の検証] を選択します。
- [開始する前に] ページで、[次へ] を選択します。
- [サーバーまたはクラスターの選択] ページで、フェールオーバー クラスター ノードとして追加するサーバーの NetBIOS 名または完全修飾ドメイン名を [名前の入力] ボックスに入力し、[追加] を選択します。 追加するサーバーごとに、この手順を繰り返します。 一度に複数のサーバーを追加するには、名前をコンマまたはセミコロンで区切って入力します。 たとえば、server1.contoso.com, server2.contoso.com という形式で入力します。 操作が完了したら、[次へ] をクリックします。
- [テスト オプション] ページで、[すべてのテストを実行する (推奨)] オプションを選択し、[次へ] を選択します。
- [確認] ページで、[次へ] を選択します。 検証ページに、実行されているテストのステータスが表示されます。
- [概要] ページで、次のいずれかの操作を実行します。
- テストが正常に完了し、構成がクラスタリングに適していることが示され、クラスターをすぐに作成する場合は、[検証されたノードを使用してクラスターを今すぐ作成する] チェック ボックスがオンになっていることを確認して [完了]を選択します。 次に、「フェールオーバー クラスターを作成する」の手順 4 に進みます。
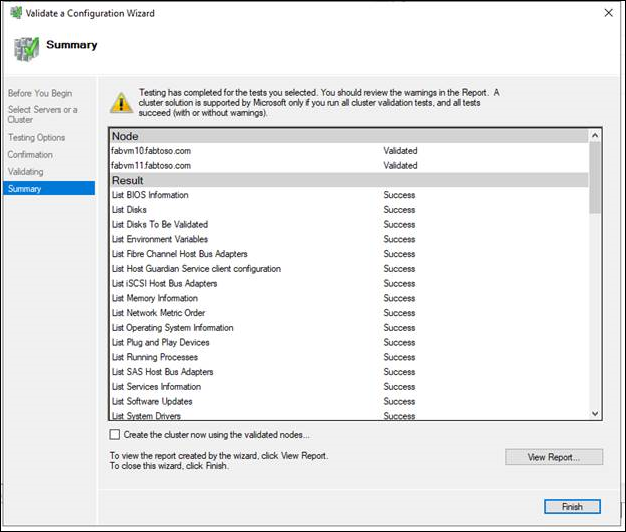
- テスト結果に警告またはエラーが示された場合は、[レポートの表示] を選択して詳細を確認し、修正する必要がある問題を特定します。 特定の検証テストで警告が発生した場合、フェールオーバー クラスターのこの面はサポートされるものの、推奨されるベスト プラクティスを満たしていない可能性があります。
注意
記憶域の永続的な予約の検証テストで警告が発生した場合は、ブログ記事「 Windows フェールオーバー クラスター検証の警告でディスクが記憶域の永続的な予約をサポートしていないことが示された場合 」を参照してください。 ハードウェア検証テストの詳細については、「フェールオーバー クラスター用ハードウェアを検証する」を参照してください。
フェールオーバー クラスターを作成する
この手順を完了するには、ログオンに使用するユーザー アカウントが、このトピックの「前提条件を検証する」セクションで説明した要件を満たしている必要があります。
- Server Manager を起動します。
- [ツール] メニューの [フェールオーバー クラスター マネージャー] を選択します。
- [フェールオーバー クラスター マネージャー] ペインで、[管理] の [クラスターの作成] を選択します。 クラスターの作成ウィザードが表示されます。
- [開始する前に] ページで、[次へ] を選択します。
- [サーバーの選択] ページで [名前の入力] ボックスに、フェールオーバー クラスター ノードとして追加するサーバーの NetBIOS 名または完全修飾ドメイン名を入力し、[追加] を選択します。 追加するサーバーごとに、この手順を繰り返します。 一度に複数のサーバーを追加するには、名前をコンマまたはセミコロンで区切って入力します。 たとえば、server1.contoso.com; server2.contoso.com という形式で入力します。 操作が完了したら、[次へ] をクリックします。
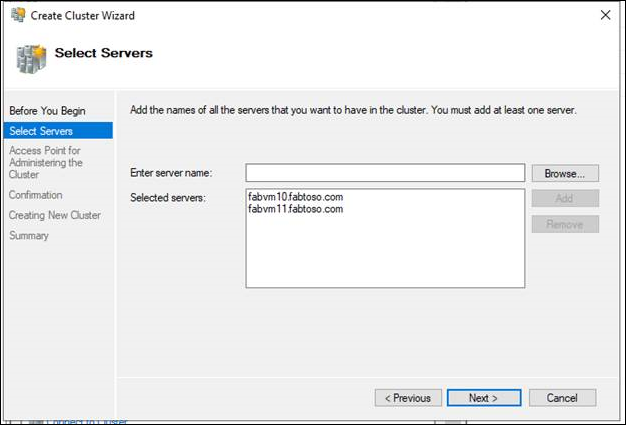
Note
「構成の検証」の手順で検証を実行した直後後にクラスターの作成を選択した場合、[サーバーの選択] ページは表示されません。 検証済みのノードはクラスターの作成ウィザードに自動的に追加されるため、それらをもう一度入力する必要はありません。
- 検証を省略した場合、[検証の警告] ページが表示されます。 クラスター検証を実行することを強くお勧めします。 Microsoft によってサポートされるのは、すべての検証テストに合格したクラスターのみです。 検証テストを実行するには、[はい] を選択し、[次へ] を選択します。 「構成の検証」の手順に従って構成の検証ウィザードを完了します。
- [クラスター管理用のアクセス ポイント] ページで、次の手順に従います。
- [クラスター名] ボックスに、クラスターを管理するために使用する名前を入力します。 この操作の前に、次の情報を参照してください。
- クラスターの作成中に、この名前はクラスター コンピューター オブジェクト ( クラスター名オブジェクト または CNOとも呼ぶ) として AD DS に登録されます。 クラスターの NetBIOS 名を指定した場合、CNO はクラスター ノードのコンピューター オブジェクトが存在する場所に作成されます。 これは既定のコンピューター コンテナーまたは OU です。
- CNO 用として別の場所を指定するには、OU の識別名を [クラスター名] ボックスに入力します。 たとえば、次のように入力します。 CN=ClusterName, OU=Clusters, DC=Contoso, DC=com.
- ドメイン管理者が CNO をクラスター ノードが存在する場所とは異なる OU にプレステージした場合は、ドメイン管理者が指定する識別名を指定します。
- DHCP を使用するように構成されているネットワーク アダプターがサーバーに存在しない場合は、フェールオーバー クラスター用として 1 つ以上の静的 IP アドレスを構成する必要があります。 クラスター管理用に使用する各ネットワークの隣にあるチェック ボックスをオンにします。 選択したネットワークの隣にある [アドレス] フィールドを選択し、クラスターに割り当てる IP アドレスを入力します。 この IP アドレス (1 つまたは複数) は、ドメイン ネーム システム (DNS) でクラスター名に関連付けられます。
- 操作が完了したら、[次へ] をクリックします。
- [確認] ページで、設定を確認します。 既定では、[使用可能な記憶域をすべてクラスターに追加する] チェック ボックスがオンになっています。 次のいずれかの場合は、このチェック ボックスをオフにします。
- 記憶域を後で構成する。
- クラスター化された記憶域スペースをフェールオーバー クラスター マネージャーまたはフェールオーバー クラスタリング Windows PowerShell コマンドレットで作成する予定であり、ファイル サービスおよび記憶域サービスで記憶域スペースをまだ作成していない。 詳細については、「クラスター化された記憶域スペースを展開する」を参照してください。
- [次へ] を選択して、フェールオーバー クラスターを作成します。
- [概要] ページで、フェールオーバー クラスターが正常に作成されたことを確認します。 警告またはエラーが発生した場合は、概要ページの出力を確認するか、[レポートの表示] を選択して詳細なレポートを参照します。 [完了] を選択します。
- クラスターが作成されたことを確認するには、クラスター名がナビゲーション ツリーの [フェールオーバー クラスター マネージャー] の下に表示されていることを確認します。 クラスター名を展開し、[ノード]、[記憶域]、または [ネットワーク] の下のアイテムを選択すると、関連付けられているリソースが表示されます。 DNS でクラスター名が正常にレプリケートされるまで若干の時間がかかる場合があります。 DNS での登録とレプリケーションが正常に完了した後に、サーバー マネージャーで [すべてのサーバー] を選択すると、クラスター名がサーバーとして表示され、[管理状態] が [オンライン] になります。
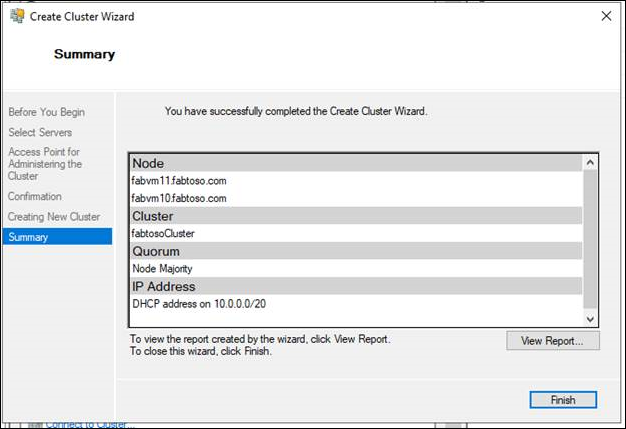
SQL Server 構成マネージャーで Always On 可用性グループを有効化する
- Always On 可用性グループ有効にする SQL Server インスタンスをホストする Windows Server フェールオーバー クラスター (WSFC) ノードに接続します。
- [スタート] ボタンをクリックし、[すべてのプログラム]、[Microsoft SQL Server]、[構成ツール] の順にポイントして、[SQL Server 構成マネージャー] をクリックします。
- SQL Server 構成マネージャーで、[SQL Server のサービス] をクリックし、[SQL Server (
<instance name>)] を右クリックして、[プロパティ] をクリックします。<instance name>は、Always On 可用性グループを有効にするローカル サーバー インスタンスの名前です。 - [AlwaysOn 高可用性] タブを選択します。
- Windows フェールオーバー クラスター名フィールドに、ローカル フェールオーバー クラスターの名前が表示されていることを確認します。 このフィールドが空白の場合、現在、このサーバー インスタンスでは Always On 可用性グループがサポートされていません。 ローカル コンピューターがクラスター ノードではないか、WSFC クラスターがシャットダウンされているか、このエディションの SQL Server では Always On 可用性グループがサポートされていません。
- [AlwaysOn 可用性グループを有効にする] チェック ボックスをオンにし、 [OK] をクリックします。 SQL Server 構成マネージャーによって変更内容が保存されます。 その後、 SQL Server サービスを手動で再起動する必要があります。 業務上の要件に合った時間帯を選んで再起動することができます。 SQL Server サービスが再起動されると、Always On が有効になり、IsHadrEnabled サーバー プロパティが 1 に設定されます。
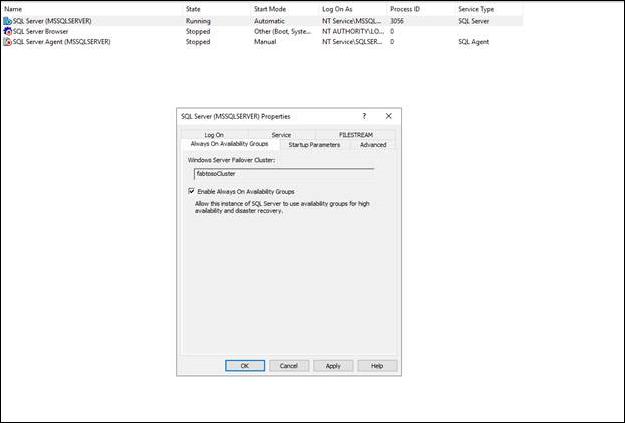
AD FS データベースをバックアップする
AD FS 構成データベースと、完全なトランザクション ログを含むアーティファクト データベースをバックアップします。 バックアップは、選択した宛先に配置します。 AD FS アーティファクト データベースと構成データベースをバックアップします。
- [タスク] > [バックアップ] > [完全] > [バックアップ ファイルに追加] > [OK] で作成
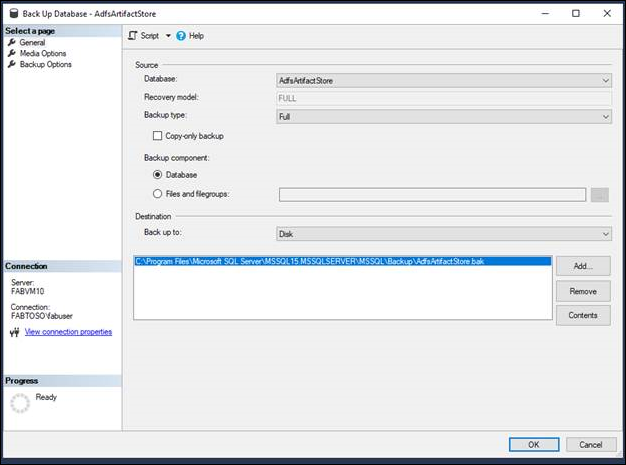
新しい可用性グループを作成する
- オブジェクト エクスプローラーで、プライマリ レプリカをホストするサーバー インスタンスに接続します。
- [AlwaysOn 高可用性] ノードと [可用性グループ] ノードを展開します。
- 新しい可用性グループ ウィザードを起動するには、[新しい可用性グループ ウィザード] をクリックします。
- このウィザードの初回実行時には、[説明] ページが表示されます。 今後このページを省略するには、[次回からこのページを表示しない] をクリックします。 このページの内容を確認してから、[次へ] をクリックします。
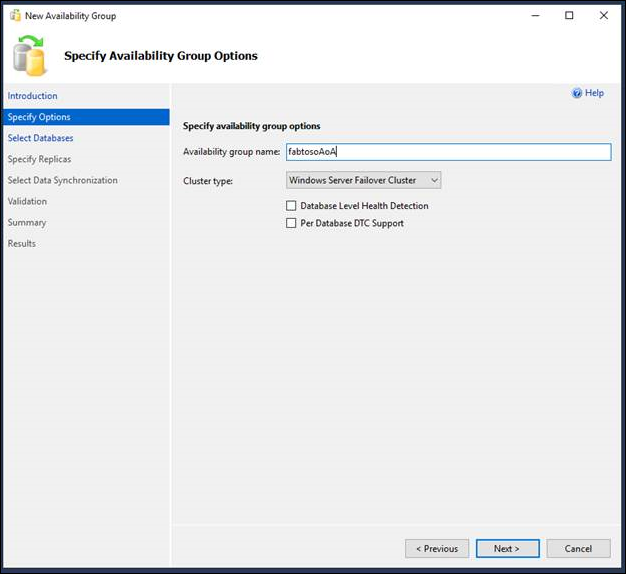
- [可用性グループ オプションの指定] ページの [可用性グループ名] フィールドに、新しい可用性グループの名前を入力します。 この名前は、クラスターおよびドメイン全体で一意となる有効な SQL Server 識別子であることが必要です。 可用性グループ名の最大文字数は 128 文字です。 e
- 次に、クラスター タイプを指定します。 使用できるクラスター タイプは、SQL Server バージョンとオペレーティング システムによって異なります。 WSFC、EXTERNAL、NONE のいずれかを選択してください。 詳細については、「Specify Availability Group Name Page」 ([可用性グループ名の指定] ページ) を参照してください。
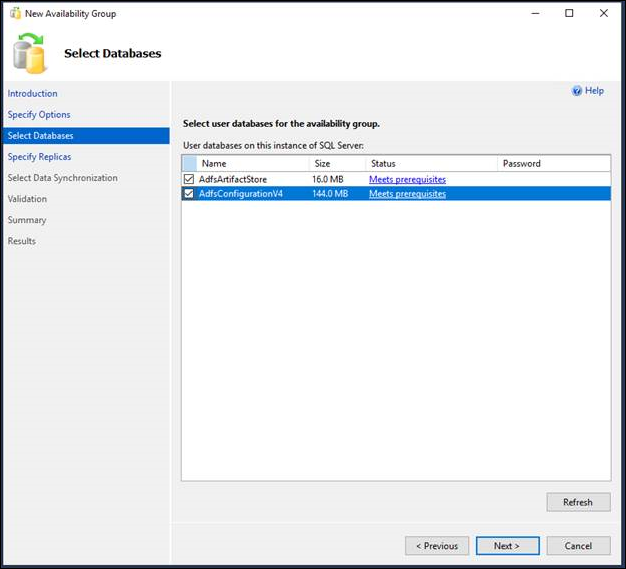
- [データベースの選択] ページのグリッドに、接続されているサーバー インスタンス上の 可用性データベースとして利用できるユーザー データベースが一覧表示されます。 新しい可用性グループに追加する 1 つまたは複数のデータベースを一覧から選択します。 これらのデータベースが初期プライマリ データベースとなります。 一覧の各データベースの [サイズ] 列には、データベースのサイズが表示されます (わかっている場合)。 [状態] 列は、データベースが可用性データベースとしての前提条件を満たしているかどうかを示します。 前提条件が満たされていない場合は、簡単な状態説明によって、データベースが不適格である理由が示されます (完全復旧モデルを使用していない、など)。 詳細については、状態の説明をクリックしてください。 要件を満たすようにデータベースを変更した場合は、[更新] をクリックして、データベース グリッドを最新の情報に更新します。 データベースにデータベース マスター キーが含まれている場合、[パスワード] 列にデータベース マスター キーのパスワードを入力します。
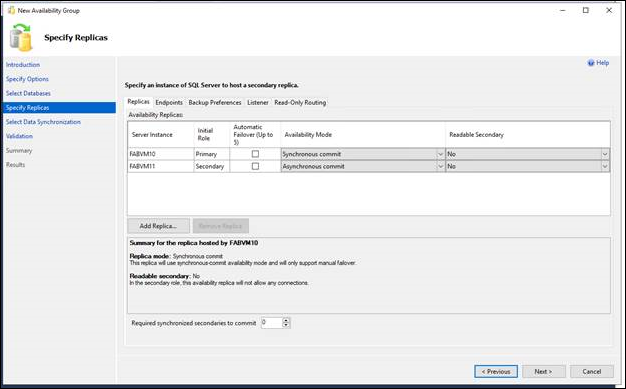
8. [レプリカの指定] ページで、新しい可用性グループの 1 つまたは複数のレプリカを指定し、構成します。 このページには、4 つのタブがあります。 次の表では、これらのタブについて説明します。 詳細については、レプリカの指定ページ (新しい可用性グループ ウィザード: レプリカの追加ウィザード) に関するトピックを参照してください。
| タブ | 簡単な説明 |
|---|---|
| レプリカ | このタブを使用して、セカンダリ レプリカをホストする SQL Server の各インスタンスを指定します。 現在接続しているサーバー インスタンスでプライマリ レプリカをホストする必要があることに注意してください。 |
| エンドポイント | このタブを使用して、既存の任意のデータベース ミラーリング エンドポイントを検証します。また、サービス アカウントが Windows 認証を使用しているサーバー インスタンスでエンドポイントが不足している場合は、エンドポイントを自動的に作成します。 |
| バックアップの設定 | このタブを使用して、可用性グループ全体についてバックアップの設定を指定し、各可用性レプリカのバックアップ優先順位を指定します。 |
| リスナー | このタブを使用して、可用性グループ リスナーを作成します。 既定では、ウィザードによってリスナーは作成されません。 |
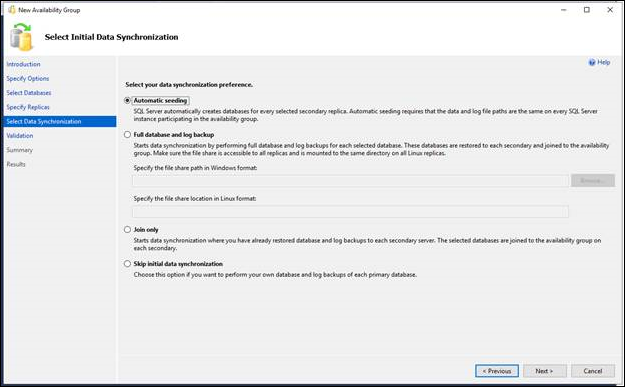
- [最初のデータの同期を選択] ページで、新しいセカンダリ データベースを作成して可用性グループに参加させる方法を選択します。 次のいずれかのオプションを選択します。
- 自動シード処理
- グループの各データベースのセカンダリ レプリカが SQL Server で自動的に作成されます。 自動シード処理には、データとログ ファイルのパスが、グループに参加しているすべての SQL Server インスタンスで同じである必要があります。 SQL Server 2016 (13.x) 以降で使用できます。 Always On 可用性グループの自動初期化に関するページを参照してください。
- 完全なデータベースとログ バックアップ
- 使用している環境が、初期データの同期を自動的に開始するための要件を満たす場合は、このオプションを選択します (詳細については、このトピックの「前提条件、制限事項、および推奨事項」をご覧ください)。 [完全]を選択すると、可用性グループを作成後、ウィザードはすべてのプライマリ データベースとそのトランザクション ログをネットワーク共有にバックアップし、セカンダリ レプリカをホストするすべてのサーバー インスタンスでそのバックアップを復元します。 その後、ウィザードは、すべてのセカンダリ データベースを可用性グループに参加させます。 [すべてのレプリカからアクセス可能な共有ネットワーク場所を指定] フィールドで、レプリカをホストするサーバー インスタンスが読み取り/書き込み権限を持つバックアップ共有を指定します。 詳細については、このトピックの「前提条件」をご覧ください。 検証手順で、指定されたネットワークの場所が有効であることを確認するテストが行われます。このテストにより、プライマリ レプリカにデータベースが作成されますが、その名前は "BackupLocDb_" に GUID を続ける方式で付けられます。さらに、指定されたネットワークの場所にバックアップが実行され、セカンダリ レプリカでそれが復元されます。 このデータベースがウィザードで削除できなかった場合、そのバックアップ履歴とバックアップ ファイルと共に削除しておくことをお勧めします。
- [参加のみ]
- セカンダリ レプリカをホストするサーバー インスタンス上のセカンダリ データベースを手動で準備した場合は、このオプションを選択できます。 ウィザードは、既存のセカンダリ データベースを可用性グループに参加させます。
- [最初のデータの同期をスキップ]
- プライマリ データベースの独自のデータベースとログ バックアップを使用する場合は、このオプションを選択します。 詳細については、「AlwaysOn セカンダリ データベース上のデータ移動の開始 (SQL Server)」を参照してください。
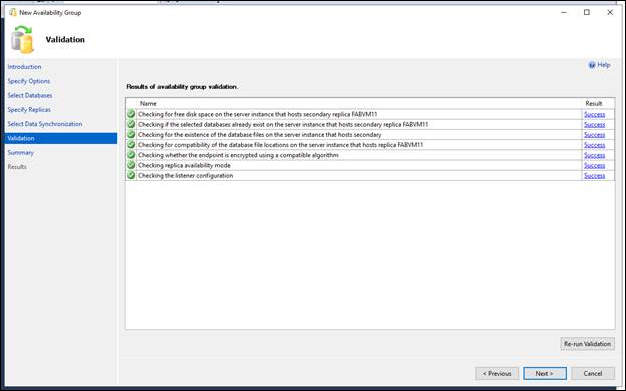
[検証] ページでは、このウィザードで指定した値が、新しい可用性グループ ウィザードの要件を満たしているかどうかが確認されます。 変更が必要な場合は、 [戻る] をクリックして前のウィザード ページに戻り、値を変更できます。 その後、[次へ] をクリックして [検証] ページに戻り、[検証の再実行] をクリックします。
[概要] ページで、新しい可用性グループに対して選択した内容を確認します。 変更が必要な場合は、[戻る] をクリックして、該当するページに戻ります。 必要な変更を加えたら、[次へ] をクリックして、[概要] ページに戻ります。
注意
新しい可用性レプリカをホストするサーバー インスタンスの SQL Server サービス アカウントがログインとして存在しない場合は、新しい可用性グループ ウィザードでログインを作成する必要があります。 [概要] ページには、作成するログインの情報が表示されます。 [完了] をクリックすると、SQL Server サービス アカウントに対してこのログインが作成され、ログインに CONNECT 権限が付与されます。 選択内容に問題がなければ、[スクリプト] をクリックして、ウィザードが実行する手順のスクリプトを作成することもできます。 新しい可用性グループを作成して構成するには、[完了] をクリックします。
- 可用性グループの作成手順 (エンドポイントの構成、可用性グループの作成、グループへのセカンダリ レプリカの参加) の進行状況が、[進行状況] ページに表示されます。
- 以上の手順が完了すると、[結果] ページに各手順の結果が表示されます。 これらのすべての手順が成功した場合は、新しい可用性グループが完全に構成されます。 手順のいずれかでエラーが発生した場合は、手動で構成を完了するか、失敗した手順に対してウィザードを使用する必要があります。 特定のエラーの原因については、[結果] 列の [エラー] リンクをクリックします。 ウィザードでの作業が完了したら、[閉じる] をクリックして終了します。
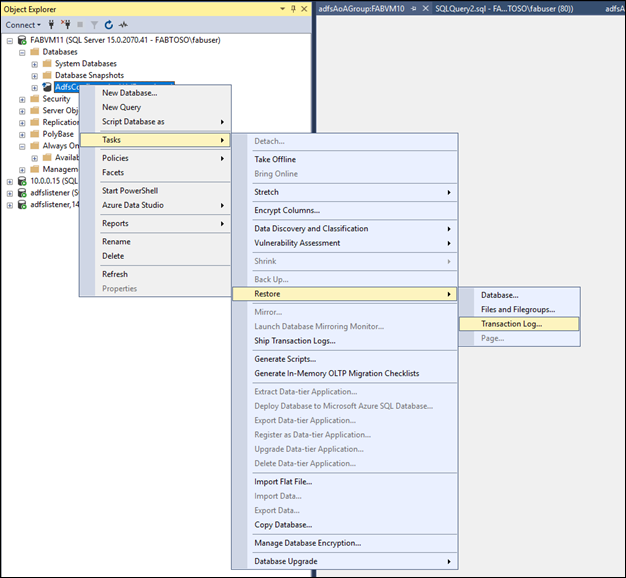
セカンダリ ノードでデータベースを追加する
作成したバックアップ ファイルを使用して、セカンダリ ノードの UI からアーティファクト データベースを復元します。
データベースを非復旧状態で復元します。
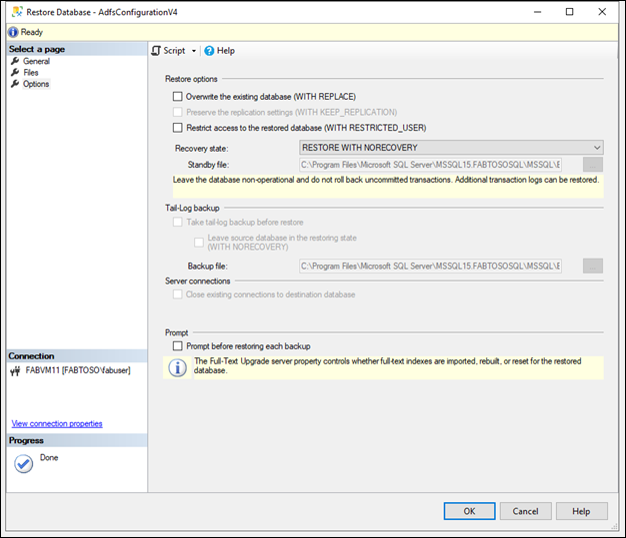
構成データベースを復元するプロセスを繰り返します。
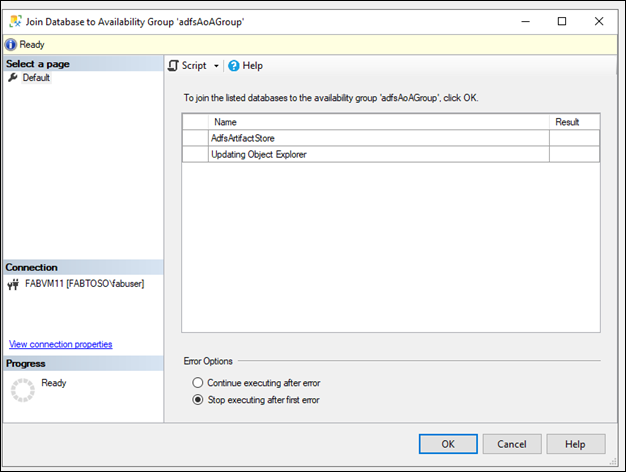
可用性グループに可用性レプリカを参加させる
- オブジェクト エクスプローラーで、セカンダリ レプリカをホストするサーバー インスタンスに接続し、サーバー名をクリックしてサーバー ツリーを展開します。
- [AlwaysOn 高可用性] ノードと [可用性グループ] ノードを展開します。
- 接続先のセカンダリ レプリカの可用性グループを選択します。
- セカンダリ レプリカを右クリックし、[可用性グループへの参加] をクリックします。
- これにより、[可用性グループへのレプリカの追加] ダイアログ ボックスが開きます。
- セカンダリ レプリカを可用性グループに参加させるには、[OK] をクリックします。
SQL 接続文字列を更新する
最後に、AlwaysOn 可用性グループのリスナーの DNS アドレスを使用する SQL 接続文字列を更新するために、PowerShell を使用して AD FS プロパティを編集します。 各ノードで構成データベースの変更を実行し、すべての AD FS ノードで AD FS サービスを再起動します。 初期カタログ値は、ファームのバージョンに基づいて変更されます。
PS:\>$temp= Get-WmiObject -namespace root/ADFS -class SecurityTokenService
PS:\>$temp.ConfigurationdatabaseConnectionstring=”data source=<SQLCluster\SQLInstance>; initial catalog=adfsconfiguration;integrated security=true”
PS:\>$temp.put()
PS:\> Set-AdfsProperties –artifactdbconnection ”Data source=<SQLCluster\SQLInstance >;Initial Catalog=AdfsArtifactStore;Integrated Security=True”