カスタム画像分析モデルを作成する
重要
この機能は非推奨になりました。 2025 年 1 月 10 日に、Azure AI Image Analysis 4.0 Custom Image Classification、Custom Object Detection、Product Recognition プレビュー API は廃止されます。 この日以降、これらのサービスへの API 呼び出しは失敗します。
モデルの円滑な動作を維持するには、現在一般提供されている Azure AI Custom Vision に移行してください。 Custom Vision は、これらの廃止機能と同様の機能を提供しています。
Image Analysis 4.0 では、独自のトレーニング画像を使用してカスタム モデルをトレーニングできます。 画像に手動でラベルを付けることで、モデルをトレーニングして画像にカスタム タグを適用したり (画像分類)、カスタム オブジェクトを検出したり (物体検出) できます。 Image Analysis 4.0 モデルは、"少数ショット" の学習で特に効果的であるため、少ないトレーニング データでも正確なモデルを取得できます。
このガイドでは、カスタム画像分類モデルを作成してトレーニングする方法について説明します。 画像分類モデルと物体検出モデルトレーニングの、いくつかの違いを説明します。
Note
モデルのカスタマイズは REST API と Vision Studio を通じて使用できますが、クライアント言語 SDK を通じてはできません。
前提条件
- Azure サブスクリプション。 無料で作成できます。
- Azure サブスクリプションを入手したら、Azure portal で Vision リソースを作成し、キーとエンドポイントを取得します。 Vision Studio を使用し、このガイドに従っている場合は、米国東部リージョンでリソースを作成する必要があります。 デプロイされたら、 [リソースに移動] を選択します。 後で使用するために、キーとエンドポイントを一時的な場所にコピーしておきます。
- Azure Storage リソース。 ストレージ リソースを作成します。
- 分類モデルのトレーニングに使用する画像のセット。 GitHub 上のサンプル画像のセットを使用することができます。 または、独自の画像を使用できます。 1 つのクラスあたり約 3 ~ 5 個の画像のみが必要です。
Note
待ち時間が長くなる可能性があるため、ビジネス上重要な環境ではカスタム モデルを使用しないことをお勧めします。 お客様が Vision Studio でカスタム モデルをトレーニングすると、それらのカスタム モデルはトレーニング対象の Vision リソースに属し、お客様は Analyze Image API を使用してそれらのモデルを呼び出すことができます。 これらの呼び出しを行うと、カスタム モデルがメモリに読み込まれ、予測インフラストラクチャが初期化されます。 このような場合、お客様は予測結果を受け取るために予想よりも長い待機時間が発生する可能性があります。
新しいカスタム モデルの作成
まず、Vision Studio に移動し、[画像分析] タブを選択します。次に、[モデルのカスタマイズ] タイルを選択します。
![[モデルのカスタマイズ] タイルのスクリーンショット。](../media/customization/customization-tile.png)
続いて、Azure アカウントでサインインし、Vision リソースを選択します。 アカウントがない場合は、この画面から作成できます。
![[リソースの選択] 画面のスクリーンショット。](../media/customization/select-resource.png)
トレーニング画像を準備する
Azure BLOB ストレージ コンテナーにトレーニング画像をアップロードする必要があります。 Azure portal でストレージ リソースに移動し、[ストレージ ブラウザー] タブに移動します。ここでは、BLOB コンテナーを作成し、画像をアップロードできます。 それらをすべてをコンテナーのルートに配置します。
データセットを追加する
カスタム モデルをトレーニングするには、画像とそのラベル情報をトレーニング データとして提供するデータセットにそのモデルを関連付ける必要があります。 Vision Studio で、[データセット] タブを選択してデータセットを表示します。
新しいデータセットを作成するには、[新しいデータセットの追加] を選択します。 ポップアップ ウィンドウで、名前を入力し、ユース ケースのデータセットの種類を選択します。 画像分類モデルは画像全体にコンテンツ ラベルを適用し、物体検出モデルは画像内の特定の場所にオブジェクト ラベルを適用します。 製品認識モデルは、小売製品の検出用に最適化された物体検出モデルのサブカテゴリです。
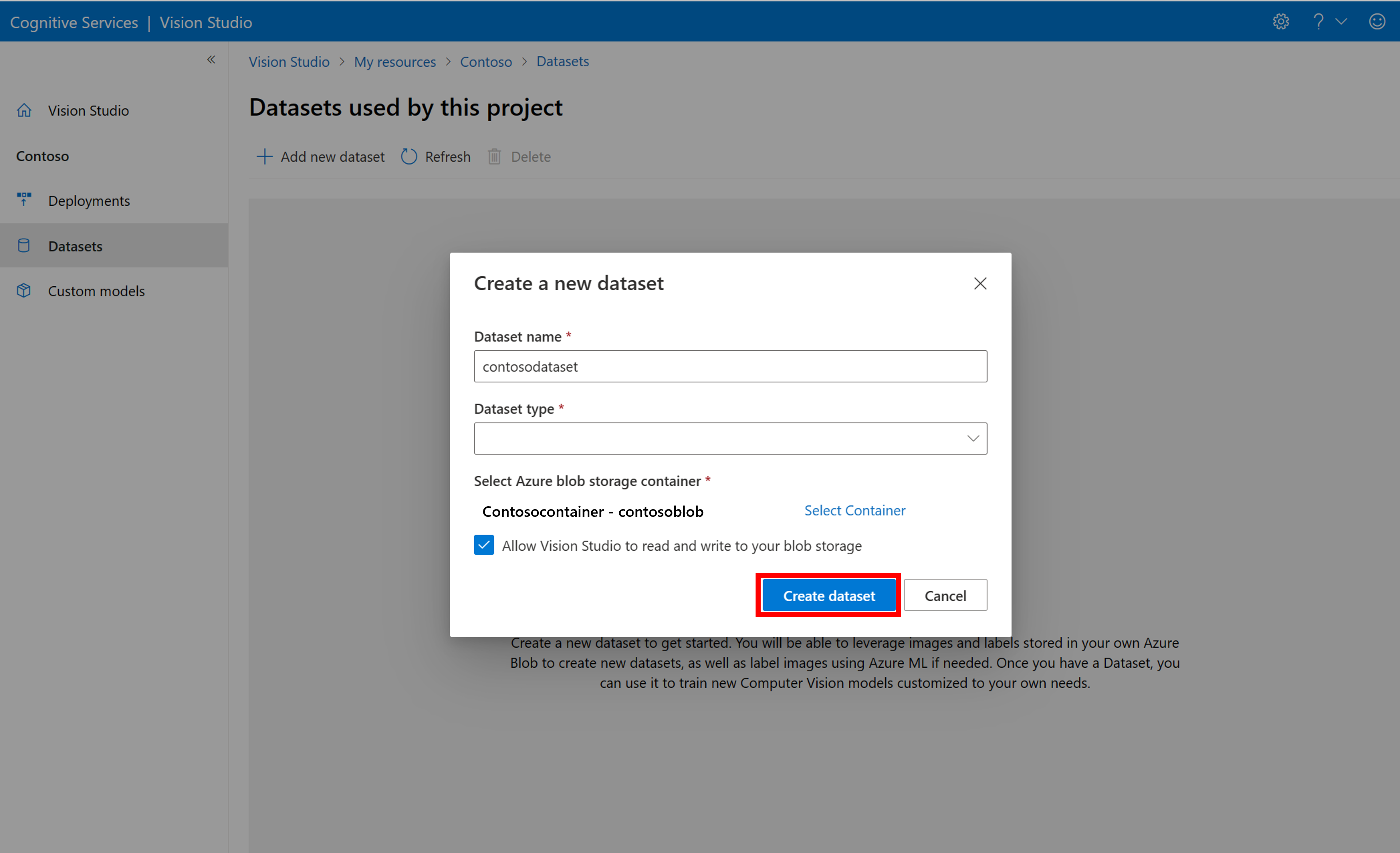
次に、トレーニング画像を保存した Azure Blob Storage アカウントからコンテナーを選択します。 このチェック ボックスをオンにすると、Vision Studio が BLOB ストレージ コンテナーの読み取りと書き込みを行うことができます。 これは、ラベル付きデータをインポートするために必要な手順です。 データセットを作成します。
Azure Machine Learning データのラベル付けプロジェクトを作成する
ラベル付け情報を伝えるには COCO ファイルが必要です。 COCO ファイルを生成するための簡単な方法は、データ ラベル付けワークフローに含まれる Azure Machine Learning プロジェクトを作成することです。
データセットの詳細ページで、[Add a new Data Labeling project] (新しいデータ ラベル付けプロジェクトの追加) を選択します。 名前を付けて、[新しいワークスペースの作成] を選択します。 それにより、新しい Azure portal タブが開き、Azure Machine Learning プロジェクトを作成できます。
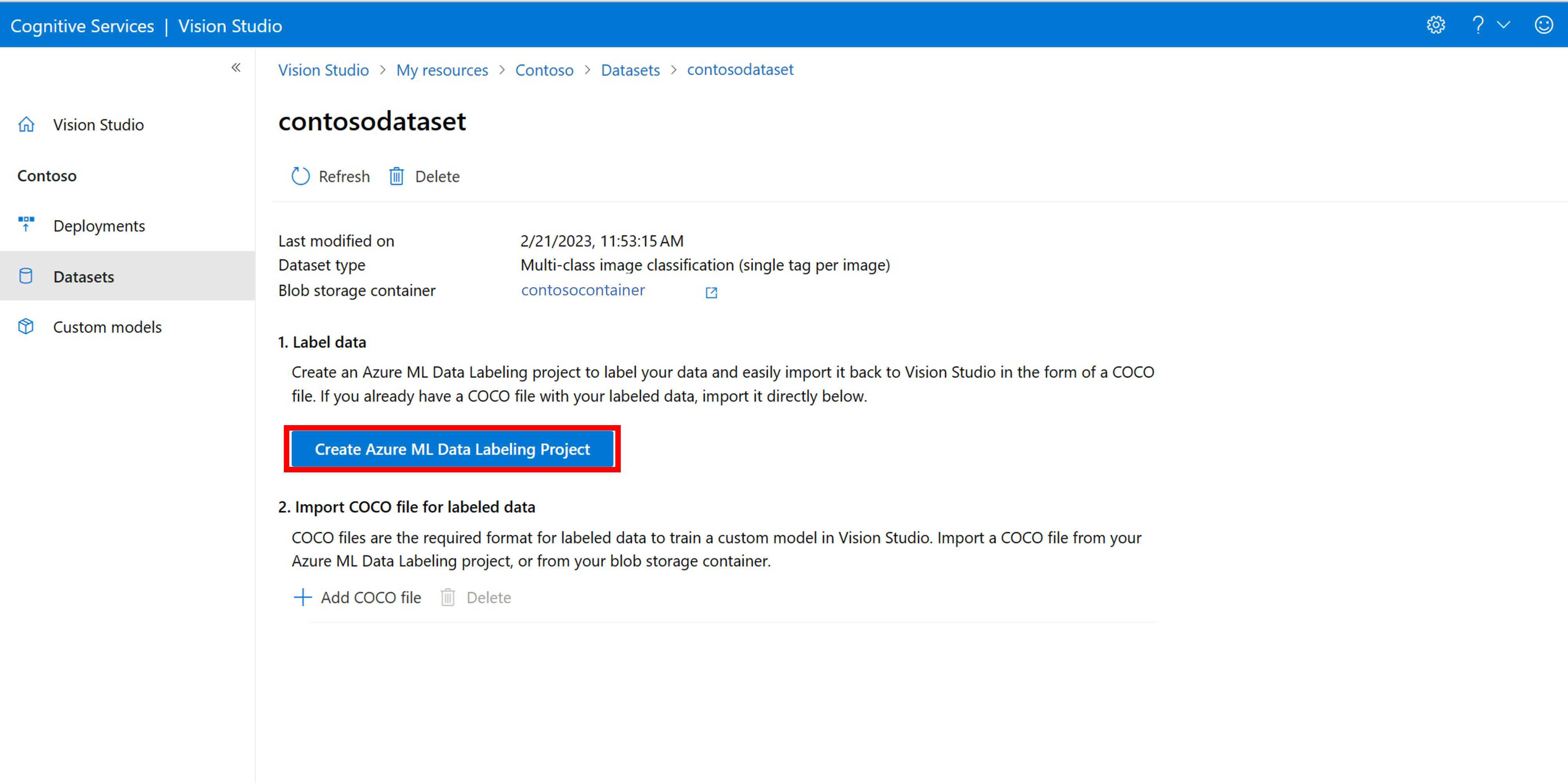
Azure Machine Learning プロジェクトが作成されたら、[Vision Studio] タブに戻り、[ワークスペース] でそれを選択します。 選択すると、Azure Machine Learning ポータルが新しいブラウザー タブで開きます。
ラベルを作成する
ラベル付けを開始するには、[Please add label classes] (ラベル クラスを追加してください) プロンプトに従ってラベル クラスを追加します。
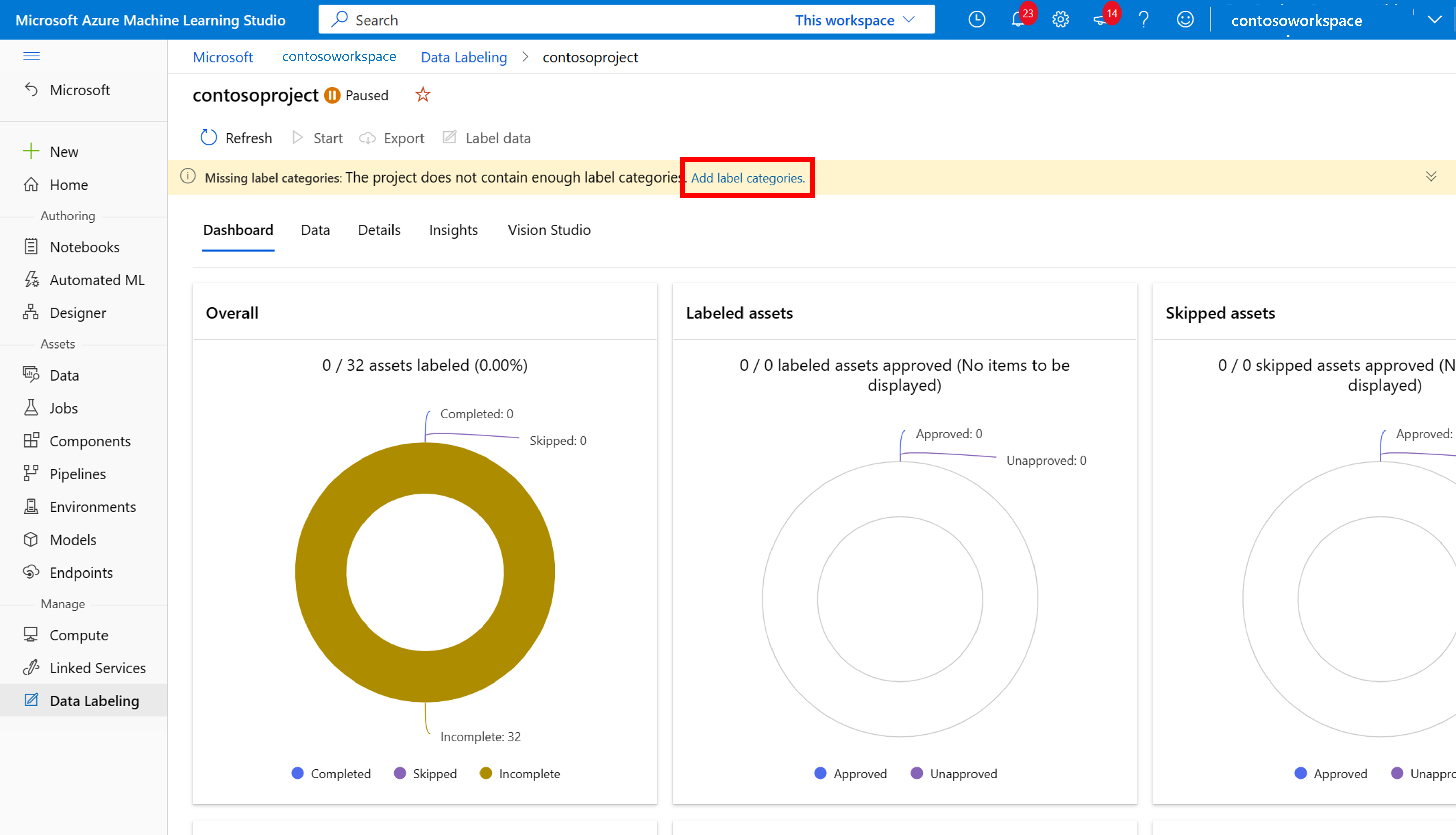
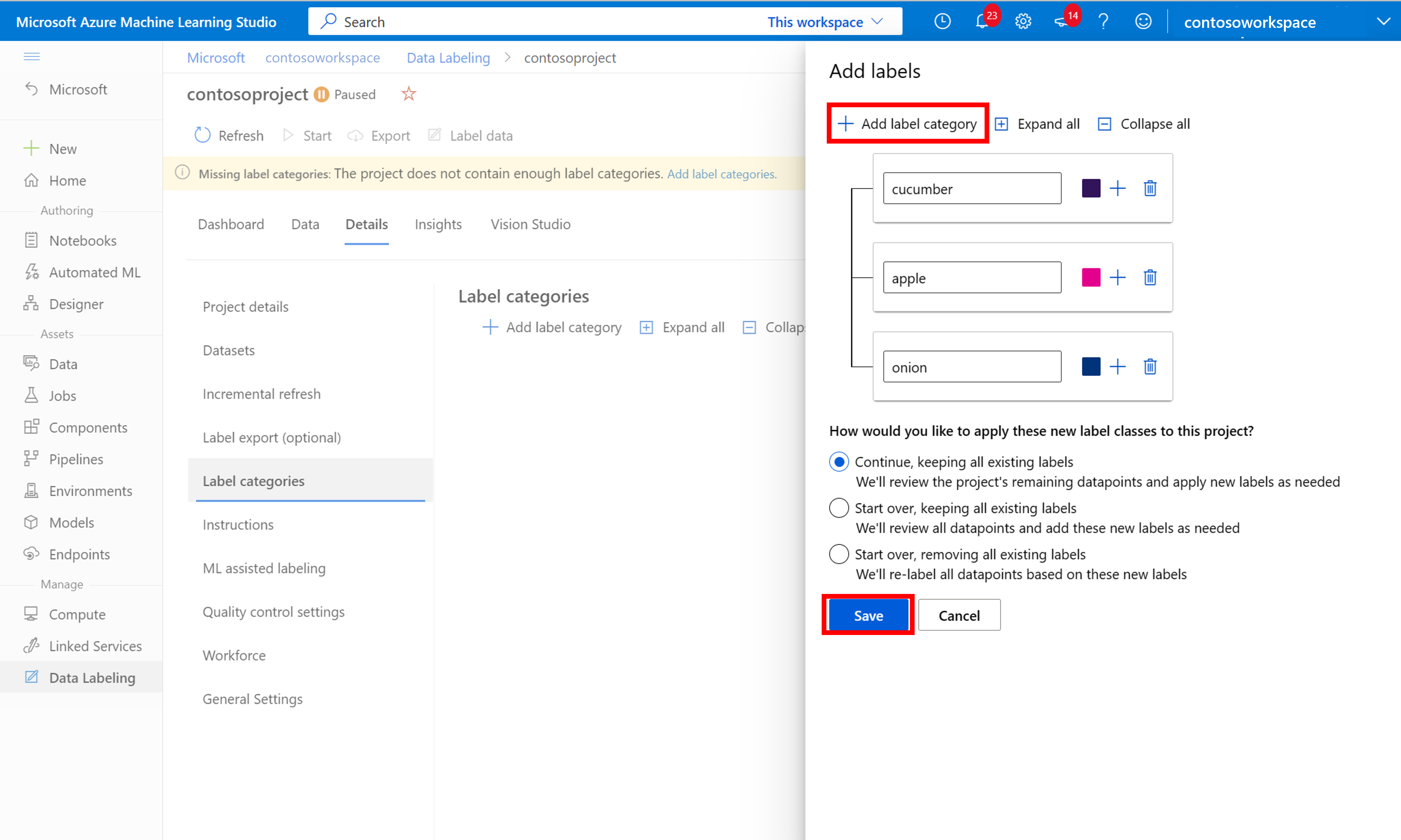
すべてのクラス ラベルを追加したら、それらを保存し、プロジェクトで [開始] を選択して、上部にある [ラベル データ] を選択します。
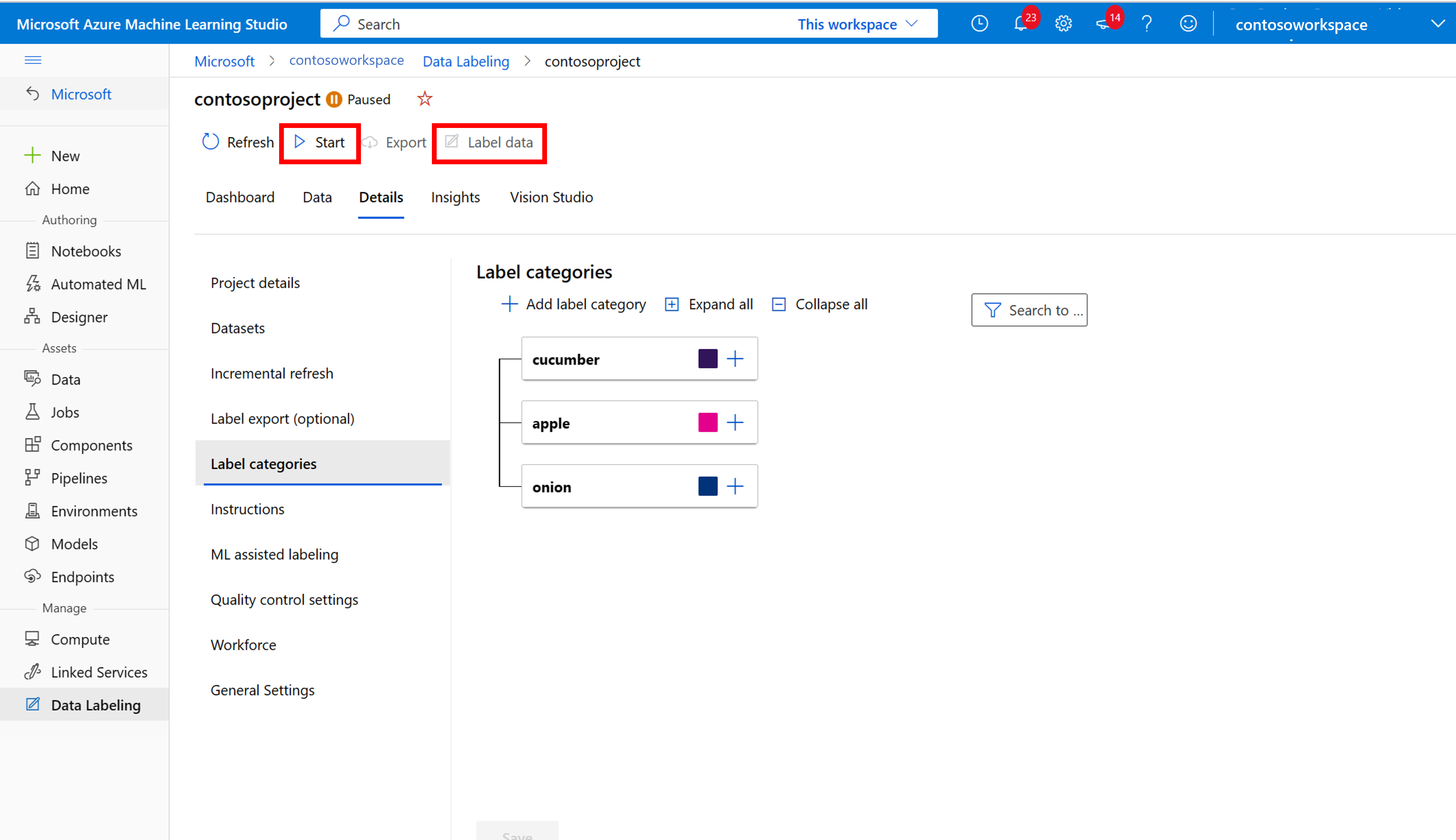
トレーニング データに手動でラベルを付ける
[ラベル付けの開始] を選択し、プロンプトに従ってすべての画像にラベルを付けます。 完了したら、ブラウザーの [Vision Studio] タブに戻ります。
次に、[ADD COCO file] (COCO ファイルの追加) を選択し、[Import COCO file from an Azure ML Data Labeling project] (Azure ML Data Labeling プロジェクトからの COCO ファイルのインポート) を選択します。 これにより、ラベル付きデータが Azure Machine Learning からインポートされます。
これで、作成した COCO ファイルが、このプロジェクトにリンクさせた Azure Storage コンテナーに格納されます。 これでファイルをモデルのカスタマイズ ワークフローにインポートできるようになります。 ドロップダウン リストから選択します。 COCO ファイルがデータセットにインポートされたら、データセットを使用してモデルをトレーニングできます。
Note
インポートする既製の COCO ファイルがある場合は、[データセット] タブに移動し、[このプロジェクトへの COCO ファイルの追加] を選択します。 BLOB ストレージ アカウントから特定の COCO ファイルを選択して追加するか、Azure Machine Learning ラベル付けプロジェクトからインポートすることができます。
現在、Microsoft は、Vision Studio で開始すると、大規模なデータセットで COCO ファイルのインポートが失敗する問題に対処しています。 大規模なデータセットを使用してトレーニングするには、代わりに REST API を使用することをお勧めします。
![[COCO ファイルのインポート] ダイアログ ボックスのスクリーンショット。](../media/customization/import-coco.png)
COCO ファイルについて
COCO ファイルは以下の"images"、"annotations"および "categories"のように特定の必須フィールド を持つ JSON ファイルです。 サンプルの COCO ファイル は次のようになります:
{
"images": [
{
"id": 1,
"width": 500,
"height": 828,
"file_name": "0.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/0.jpg"
},
{
"id": 2,
"width": 754,
"height": 832,
"file_name": "1.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/1.jpg"
},
...
],
"annotations": [
{
"id": 1,
"category_id": 7,
"image_id": 1,
"area": 0.407,
"bbox": [
0.02663142641129032,
0.40691584277841153,
0.9524163571731749,
0.42766634515266866
]
},
{
"id": 2,
"category_id": 9,
"image_id": 2,
"area": 0.27,
"bbox": [
0.11803319477782331,
0.41586723392402375,
0.7765206955096307,
0.3483334397217212
]
},
...
],
"categories": [
{
"id": 1,
"name": "vegall original mixed vegetables"
},
{
"id": 2,
"name": "Amy's organic soups lentil vegetable"
},
{
"id": 3,
"name": "Arrowhead 8oz"
},
...
]
}
COCO ファイル フィールドリファレンス
独自の COCO ファイルを最初から生成する場合は、すべての必須フィールドに正しい詳細が入力されていることを確認します。 次の表では、COCO ファイルの各フィールドについて説明します:
「イメージ」
| キー | Type | 説明 | 必須 |
|---|---|---|---|
id |
整数 | 1 から始まる一意のイメージ ID | はい |
width |
整数 (integer) | 画像の幅 (ピクセル単位) | はい |
height |
整数 (integer) | 画像の高さ (ピクセル単位) | はい |
file_name |
string | イメージの一意の名前 | はい |
absolute_url または coco_url |
string | BLOB コンテナー内の BLOB への絶対 URI としてのイメージ パス。 Vision リソースには、注釈ファイルと参照されているすべてのイメージ ファイルを読み取るアクセス許可が必要です。 | はい |
absolute_url の 値は、BLOB コンテナーのプロパティにあります。
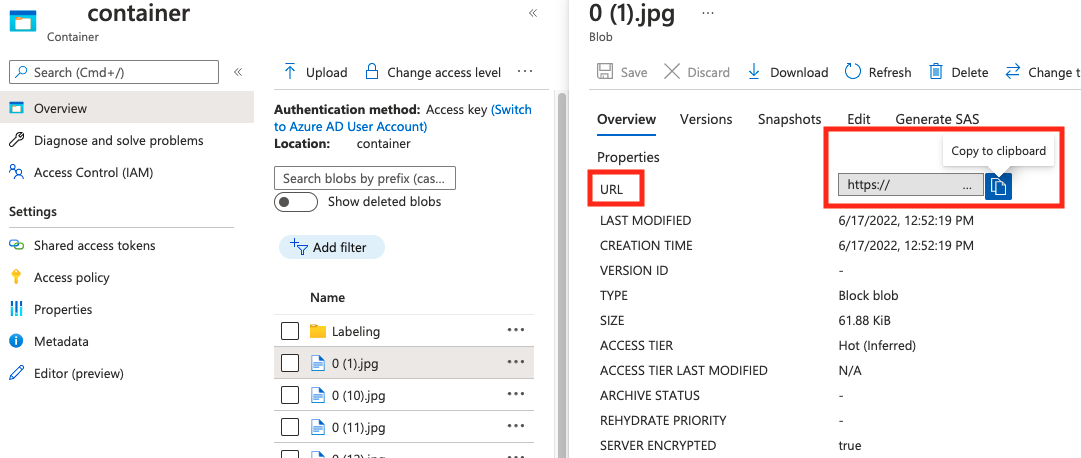
「注釈」
| キー | Type | 説明 | 必須 |
|---|---|---|---|
id |
整数 | 注釈の ID | はい |
category_id |
整数 (integer) | categories セクションで定義されているカテゴリの ID |
はい |
image_id |
整数 (integer) | イメージの ID | はい |
area |
整数 (integer) | '幅' x '高さ' の値 (の 3 番目と 4 番目のbboxの値) |
いいえ |
bbox |
リスト[float] | 境界ボックスの相対座標 (0 から 1)、'左'、'上'、'幅'、'高さ' の順 | はい |
「カテゴリ」
| キー | Type | 説明 | 必須 |
|---|---|---|---|
id |
整数 | 各カテゴリの一意の ID (ラベル クラス)。 これらはannotations セクションに存在する 必要があります。 |
はい |
name |
string | カテゴリの名前 (ラベル クラス) | はい |
COCO ファイルの確認
COCO ファイルの形式を確認するには、Microsoft の Python サンプル コードを使用できます。
カスタム モデルをトレーニングする
COCO ファイルを使用してモデルのトレーニングを開始するには、[カスタム モデル] タブに移動し、[Add a new model] (新しいモデルの追加) を選択します。 モデルの名前を入力し、モデルの種類として Image classification または Object detection を選択します。
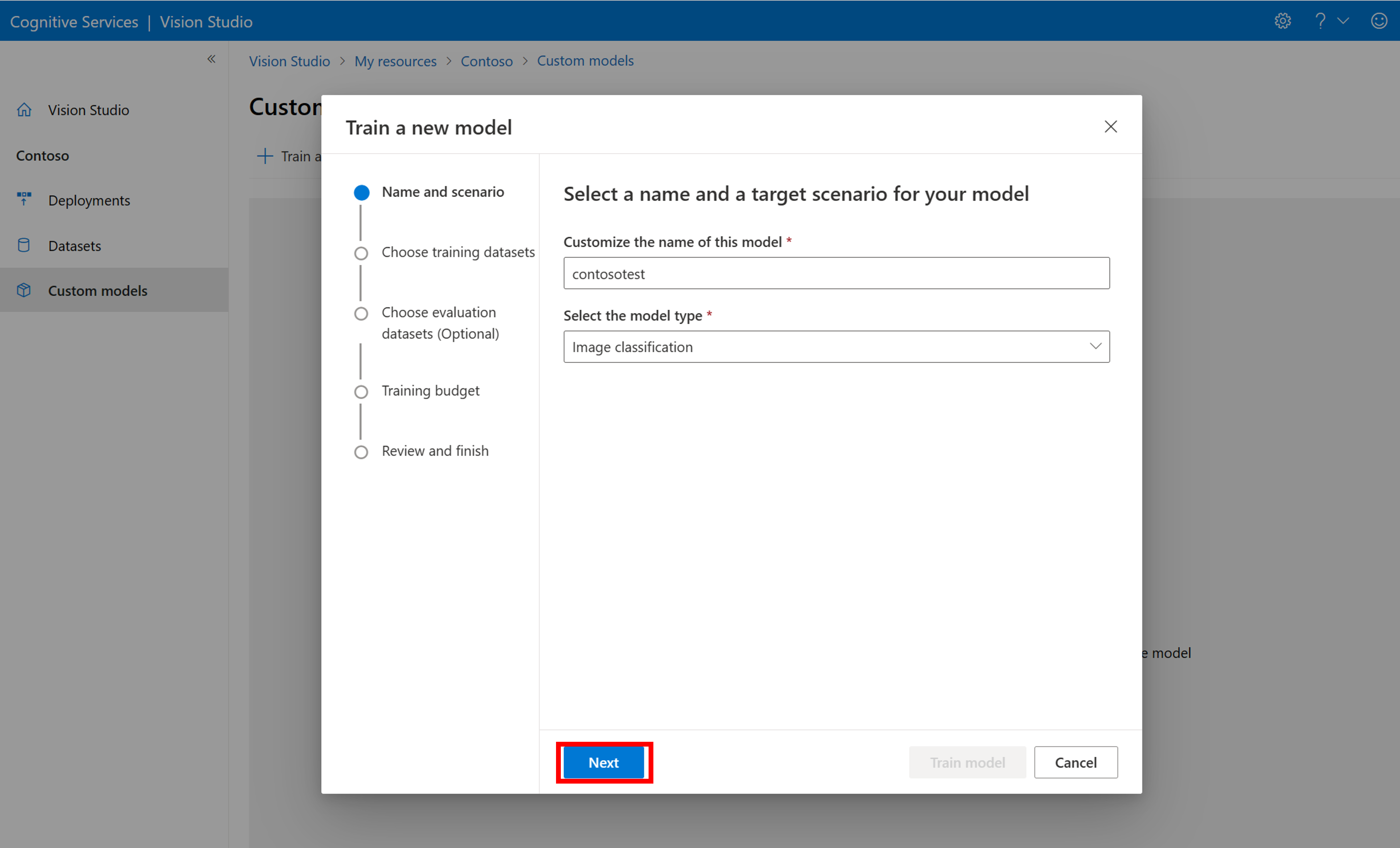
データセットを選択します。これは現在、ラベル付け情報を含む COCO ファイルに関連付けられています。
次に、時間予算を選択し、モデルをトレーニングします。 小さな例では、1 hour の予算を使用できます。
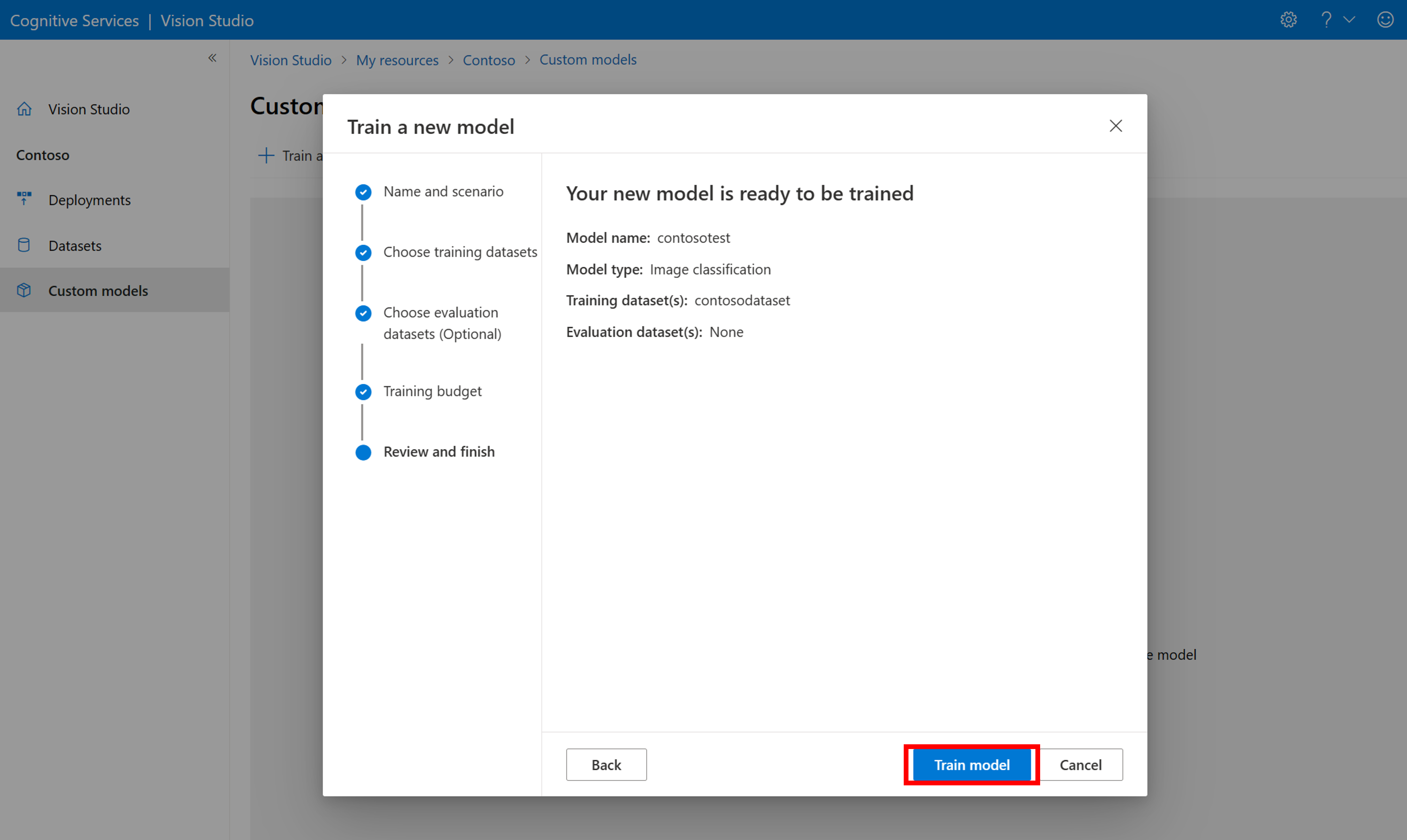
トレーニングの完了までに少し時間がかかる場合があります。 Image Analysis 4.0 モデルは、小さなトレーニング データ セットのみでも正確ですが、以前のモデルよりトレーニングに時間がかかります。
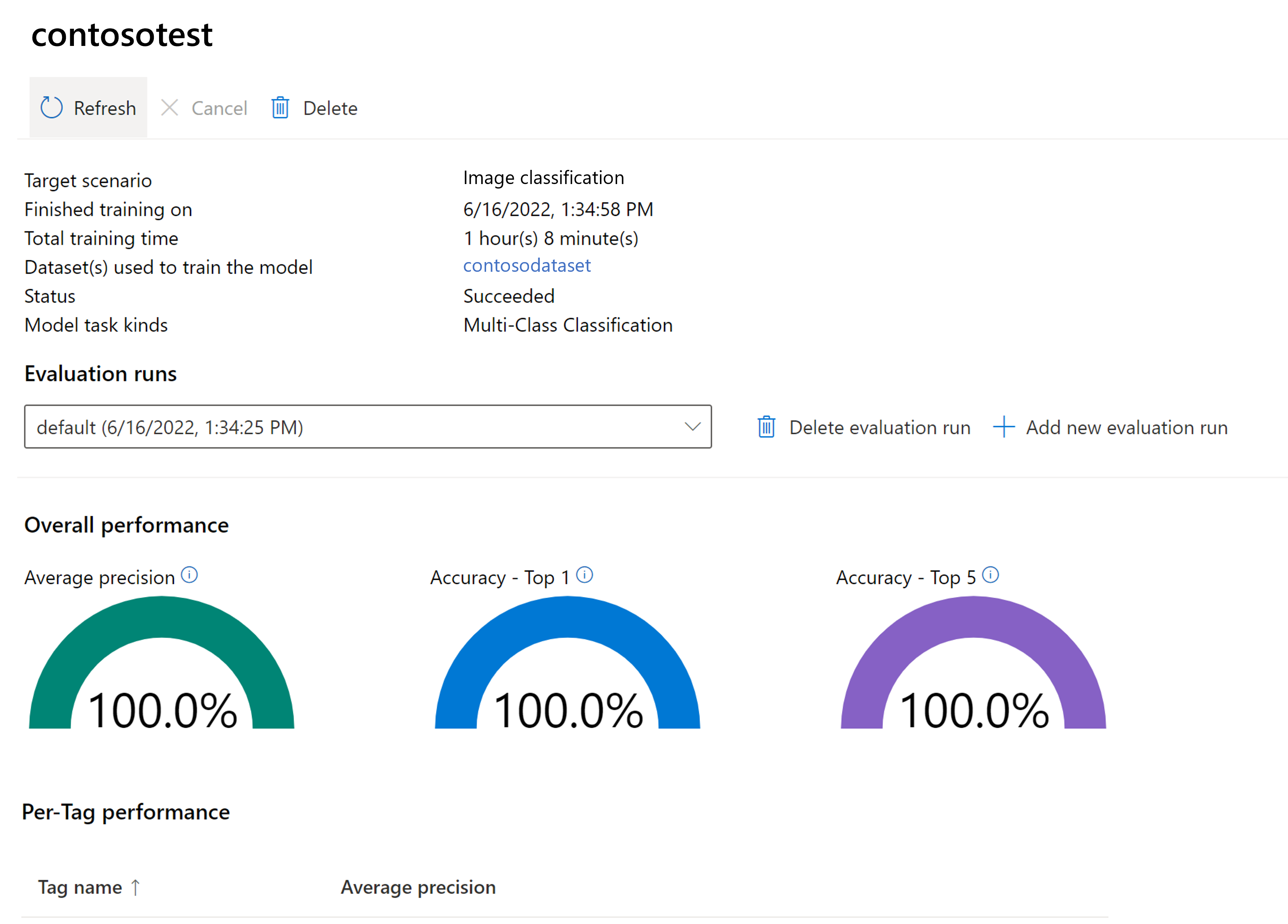
トレーニング済みモデルを評価する
トレーニングが完了したら、モデルのパフォーマンス評価を表示できます。 次のメトリックが使用されます。
- 画像分類: 平均精度、正確性上位 1、正確性上位 5
- 物体検出: 平均値平均精度 @ 30、平均値平均精度 @ 50、平均値平均精度 @ 75
モデルのトレーニング時に評価セットを指定しないと、報告されるパフォーマンスはトレーニング セットの一部に基づいて推定されます。 モデルのパフォーマンスを確実に推定するために、評価データセット (上記と同じプロセスを使用) を使用することを強くお勧めします。
Vision Studio でカスタム モデルをテストする
カスタム モデルを構築したら、モデル評価画面の [試してみる] ボタンを選択してテストできます。
![モデル評価画面で [試してみる] ボタンがアウトライン表示されているスクリーンショット。](../media/customization/custom-try-it-out.png)
これにより、[画像から一般的なタグを抽出する] ページに移動します。 ドロップダウン メニューからカスタム モデルを選択し、テスト画像をアップロードします。
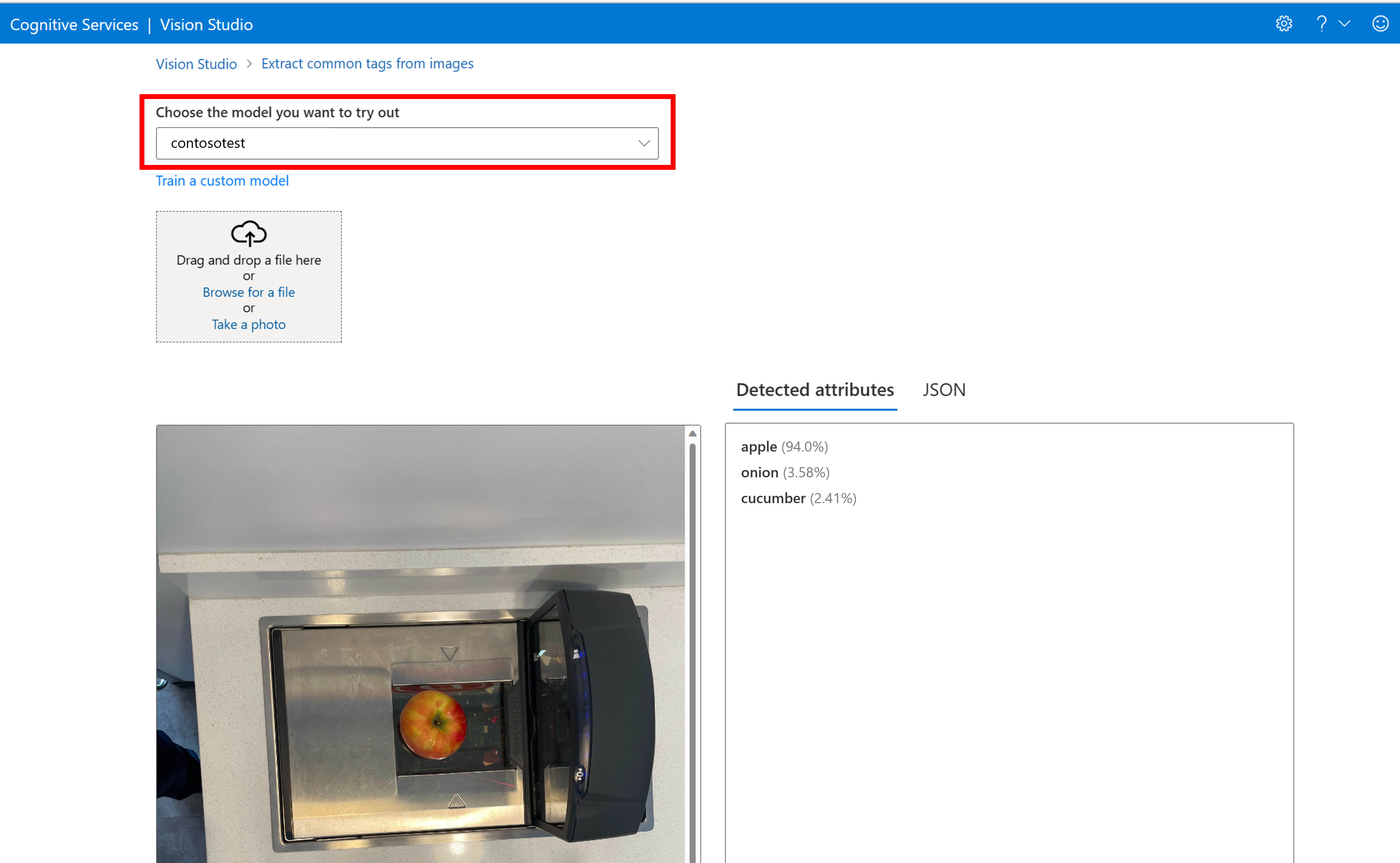
予測結果が右側の列に表示されます。
関連するコンテンツ
このガイドでは、Image Analysis を使用してカスタム画像分類モデルを作成し、トレーニングしました。 次に、Analyze Image 4.0 API の詳細を確認し、REST を使用してアプリケーションからカスタム モデルを呼び出すことができます。