Text Analytics for Health を使用する方法
重要
Text Analytics for Health は、"現状のまま"、"保証なしで" 提供される機能です。 Text Analytics for Health は、医療デバイス、臨床サポート、診断ツール、または他のテクノロジ (病気や他の状況の診断、治療、軽減、取り扱い、防止での使用が意図されているもの) として使用することを意図されたり、使用できるようにされているものではなく、そのような目的でのこの機能の使用に対して、マイクロソフトからはライセンスや権利は付与されません。 この機能は、専門的な医療のアドバイスや医学的意見、診断、治療、または医療専門家による医学的判断に代わるものとして実装またはデプロイするために設計されたり、それを意図されたりしたものではなく、そのようには使用しないでください。 お客様は、Text Analytics for Health の使用に関するすべての責任を持ちます。 お客様は UMLS Metathesaurus 使用許諾契約書付録または将来の同等のリンクに対して設定された条項に基づいて、使用する予定のすべてのソース ボキャブラリを個別にライセンスする必要があります。 お客様は、地理的または他の適用される制限を含め、これらのライセンス条項に準拠する責任を負います。
Text Analytics for Health でテキスト内の健康の社会的決定要因 (SDOH) と民族性に関する言及を抽出できるようになりました。 この機能は、すべての考えられる SDOH をカバーしているわけではなく、SDOH または民族性に基づく推論を導き出すことはありません (たとえば、薬物の使用情報は表面化しますが、薬物の乱用が推論されることはありません)。 Text Analytics for Health の出力を活用した、個人またはリソース割り当てに影響を与えるすべての決定 (課金、人事、治療管理に関連するものを含みますが、これらに限定されません) は、モデルの発見結果のみに基づいてではなく、人間の監視のもとで行われる必要があります。 SDOH と民族性の抽出機能の目的は、プロバイダーが健康アウトカムを向上させるのを支援することです。プロバイダーの健康アウトカムの向上を支援する目的を超えて、SDOH データのユーザーや消費者、または患者集団に関する否定的な推論を導き出すために使用するべきではありません。
Text Analytics for Health を使うと、医師のメモ、退院要約、臨床ドキュメント、電子健康記録などの非構造化テキストから関連する医療情報を抽出して、ラベルを付けることができます。 このサービスでは、固有表現認識、関係抽出、エンティティ リンク設定、アサーション検出が実行されて、入力テキストから分析情報が明らかにされます。 返される信頼度スコアについては、透過性のためのメモに関する記事をご覧ください。
ヒント
コードを一切書かずにこの機能をテストしたい場合は、Language Studio を使用してください。
サービスを呼び出すには 2 つの方法があります。
- Docker コンテナー (同期)
- Web ベースの API とクライアント ライブラリの使用 (非同期)
開発オプション
Text Analytics for Health を使うには、分析のために未加工の非構造化テキストを送信して、アプリケーションで API 出力を処理します。 分析はそのままの状態で行われ、データに使用されるモデルに対して追加のカスタマイズは行われません。 Text Analytics for Health には、次の 2 つの使用方法があります。
| 開発オプション | 説明 |
|---|---|
| Language Studio | Language Studio は Web ベースのプラットフォームであり、Azure アカウントがなければテキストの例で、サインアップしたら独自のデータで、エンティティ リンクを試すことができます。 詳しくは、Language Studio の Web サイトまたは Language Studio のクイックスタートに関する記事をご覧ください。 |
| REST API またはクライアント ライブラリ (Azure SDK) | さまざまな言語で使用できる REST API、またはクライアント ライブラリを使用して、Text Analytics for Health をお使いのアプリケーションに統合します。 詳細については、Text Analytics for health に関するクイックスタートを参照してください。 |
| Docker コンテナー | 利用できる Docker コンテナーを使って、この機能をオンプレミスに展開します。 これらの Docker コンテナーを使用すると、コンプライアンス、セキュリティ、またはその他の運用上の理由により、データにいっそう近いところにサービスを持ってくることができます。 |
入力言語
Text Analytics for health では、現在プレビュー段階にある複数の言語に加えて、英語がサポートされています。 Text Analytics for health の言語サポートに関する記事で詳しく説明されているように、ホステッド API を使うか、コンテナーに API をデプロイすることができます。
データの送信
API 要求を送信するには、言語リソースのエンドポイントとキーが必要です。
Note
言語リソースのキーとエンドポイントは、Azure portal で確認できます。 それらは、リソースの [Key and endpoint](キーとエンドポイント) ページの [リソース管理] にあります。
要求が受信されると分析が実行されます。 REST API またはクライアント ライブラリを使って要求を送信すると、結果は非同期的に返されます。 Docker コンテナーを使っている場合は、同期的に返されます。
この機能を非同期的に使うと、API の結果は、応答で示される要求取り込み時刻から 24 時間利用できます。 この時間が経過すると、結果は消去され、取得できなくなります。
高速ヘルスケア相互運用性リソース (FHIR) 要求の送信
高速ヘルスケア相互運用性リソース (FHIR) は、Health Level Seven International (HL7) という組織によって開発された医療業界の通信標準です。 この標準では、電子医療データを交換するためのデータ形式 (リソース) と API 構造が定義されています。 FHIR の構造を使って結果を受け取るには、API 要求本文で FHIR バージョンを送信する必要があります。
| パラメーター名 | Type | 値 |
|---|---|---|
| fhirVersion | string | 4.0.1 |
機能からの結果の取得
API 要求と、Text Analytics for Health に送信するデータに応じて、次のように取得されます。
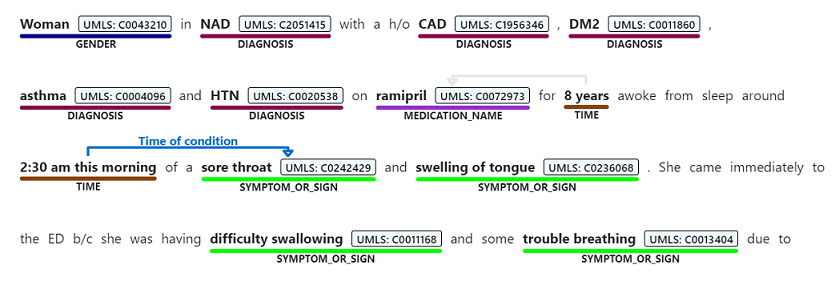
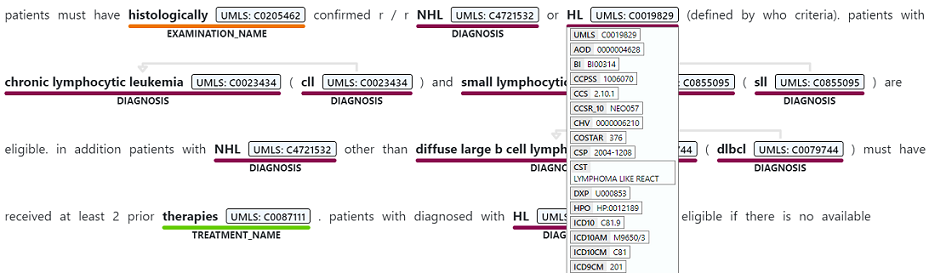
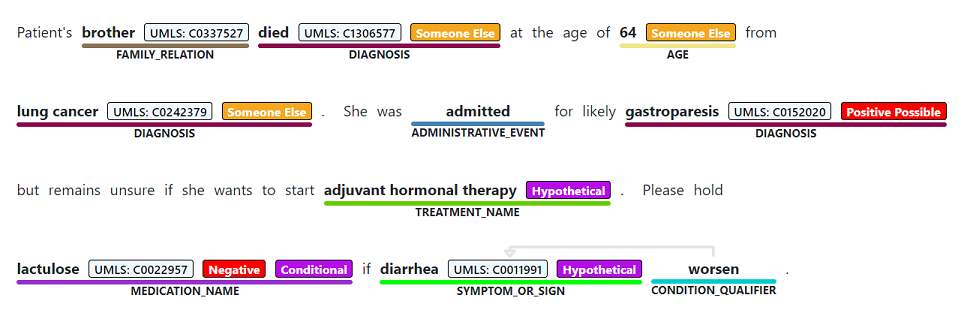
固有表現認識は、診断、薬剤名、症状や兆候、年齢など、サポートされているエンティティの種類のいずれかに関連付けられている非構造化テキストから言及されている単語やフレーズのセマンティック抽出を実行するために使われます。

サービスとデータの制限
分単位および秒単位で送信できる要求のサイズと数については、サービスの制限に関する記事を参照してください。