この記事では、コンテナ化されたアプリケーションを Azure に大規模にデプロイして運用するために使用できるマネージド Kubernetes サービスである Azure Kubernetes Service (AKS) の主要な概念について説明します。
Important
2025 年 11 月 30 日から、Azure Kubernetes Service (AKS) は、Azure Linux 2.0 のセキュリティ更新プログラムをサポートまたは提供しなくなりました。 Azure Linux 2.0 ノード イメージは、 202512.06.0 リリースでフリーズします。 2026 年 3 月 31 日以降、ノード イメージは削除され、ノード プールをスケーリングできなくなります。 ノード プールをサポートされている Kubernetes バージョンにアップグレードするか、osSku AzureLinux3 に移行して、サポートされている Azure Linux バージョンに移行します。 詳細については、 廃止に関する GitHub の問題 と Azure 更新プログラムの提供終了に関するお知らせを参照してください。 お知らせや更新情報を常に把握するには、 AKS のリリース ノートに従ってください。
Kubernetes とは
Kubernetes は、コンテナー化されたアプリケーションのデプロイ、スケーリング、管理を自動化するための、オープンソースのコンテナー オーケストレーション プラットフォームです。 詳細については、公式の Kubernetes のドキュメントを参照してください。
AKS とは
AKS は、Kubernetes を使用するコンテナー化されたアプリケーションのデプロイ、管理、スケーリングを簡素化するマネージド Kubernetes サービスです。 詳細については、「Azure Kubernetes Service (AKS) とは」を参照してください。
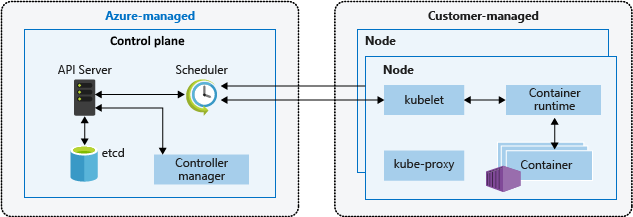
クラスターのコンポーネント
AKS クラスターは、次の 2 つの主要コンポーネントに分割されています。
- コントロール プレーン: コントロール プレーンは、Kubernetes の主要サービスと、アプリケーション ワークロードのオーケストレーションを提供します。
- ノード: ノードは、お使いのアプリケーションを実行する基になる仮想マシン (VM) です。
注
AKS マネージド コンポーネントには、ラベル kubernetes.azure.com/managedby: aksがあります。
AKS は、プレフィックス aks-managedを使用して Helm リリースを管理します。 これらのリリースのリビジョンが大きくなり続けるのは予想されることであり、安全です。
コントロール プレーン
Azure マネージド コントロール プレーンは、クラスターの管理に役立ついくつかのコンポーネントで構成されています。
| コンポーネント | 説明 |
|---|---|
kube-apiserver |
API サーバー (kube-apiserver) は、Kubernetes API を公開して、クラスターの内外からクラスターへの要求を有効にします。 |
etcd |
高可用性キー値ストア etcd は、Kubernetes クラスターと構成の状態を維持するのに役立ちます。 |
kube-scheduler |
スケジューラ (kube スケジューラ) は、スケジュールの決定に役立ちます。 ノードが割り当てられていない新しいポッドを監視し、実行するノードを選択します。 |
kube-controller-manager |
コントローラー マネージャー (kube-controller-manager) は、ノードがダウンしたときに検知して応答するといったコントローラー プロセスを実行します。 |
cloud-controller-manager |
クラウド コントローラー マネージャー (cloud-controller-manager) には、クラウド プロバイダー固有のコントローラーを実行するためのクラウド固有の制御ロジックが組み込まれています。 |
ノード
各 AKS クラスターには少なくとも 1 つのノードがあります。これは、Kubernetes ノード コンポーネントを実行する Azure VM です。 以下のコンポーネントが各ノードで実行されます。
| コンポーネント | 説明 |
|---|---|
kubelet |
kubelet は、コンテナーが確実にポッド内で実行されるようにします。 |
kube-proxy |
kube-proxy は、ノード上にネットワーク規則を保持するネットワーク プロキシです。 |
container runtime |
container runtime は、コンテナーの実行とライフサイクルを管理します。 |
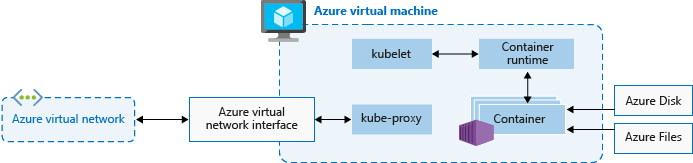
ノード構成
ノードに対して次の設定を構成します。
VM のサイズとイメージ
ノードの Azure VM サイズ は、CPU、メモリ、サイズ、および使用可能なストレージの種類 (高パフォーマンスのソリッド ステート ドライブや通常のハード ディスク ドライブなど) を定義します。 選択する VM サイズは、ワークロードの要件と、各ノードで実行する予定のポッドの数によって異なります。 2025 年 5 月以降、既定の VM SKU とサイズは、デプロイ中にパラメーターが空白のままになっている場合、使用可能な容量とクォータに基づいて AKS によって動的に選択されます。 詳しくは、Azure Kubernetes Service (AKS) でサポートされている VM サイズに関する記事をご覧ください。
AKS では、クラスターのノードの VM イメージは、Ubuntu Linux、Azure Linux、または Windows Server 2022 に基づいています。 AKS クラスターを作成したり、ノード数をスケールアウトしたりすると、Azure プラットフォームによって、要求された数の VM が作成され構成されます。 エージェント ノードは標準 VM として課金されます。 Azure の予約を含め、VM サイズの割引が自動的に適用されます。
OS ディスク
既定の OS ディスクサイズ設定は、既定の OS ディスク サイズが指定されていない場合にのみ、新しいクラスターまたはノード プールで使用されます。 この動作は、マネージド OS ディスクとエフェメラル OS ディスクの両方に適用されます。 詳細については、「既定の OS ディスクのサイズ設定」を参照してください。
リソース予約
AKS では、ノード リソースを使用して、クラスターの一部としてノードを機能させることができます。 このような使い方では、ノードの合計リソースと AKS での割り当て可能リソースが一致しなくなることがあります。 ノードのパフォーマンスと機能を維持するために、AKS では各ノード上で 2 つのタイプのリソース (CPU とメモリ) を予約します。 詳しくは、AKS でのリソース予約に関する記事を参照してください。
オペレーティングシステム (OS)
AKS では、Ubuntu と Azure Linux の 2 つの Linux ディストリビューションがサポートされています。 Ubuntu は、AKS の既定の Linux ディストリビューションです。 Windows ノード プールは、AKS の既定のチャネルとして Long Term Servicing Channel (LTSC) を使用する AKS でもサポートされます。 既定の OS バージョンの詳細については、 ノード イメージに関するドキュメントを参照してください。
コンテナー ランタイム
コンテナー ランタイムは、ノードでコンテナーを実行し、コンテナー イメージを管理するソフトウェアです。 ランタイムは、Linux または Windows 上でコンテナーを実行するためのシステム呼び出しまたは OS 固有の機能を抽象化するのに役立ちます。 Linux ノード プールの場合、 コンテナー化 は Kubernetes バージョン 1.19 以降で使用されます。 Windows Server 2019 および 2022 ノード プールの場合、 コンテナー 化は一般公開されており、Kubernetes バージョン 1.23 以降では唯一のランタイム オプションです。
ポッド
"ポッド" は、同じネットワークとストレージ リソースを共有する 1 つ以上のコンテナーのグループであり、コンテナーを実行する方法を示す仕様です。 通常、ポッドにはコンテナーとの 1 対 1 のマッピングがありますが、複数のコンテナーを 1 つのポッドで実行することもできます。
ノード プール
AKS では、同じ構成のノードは "ノード プール" にグループ化されます。 これらのノード プールには、お使いのアプリケーションを実行する基になる仮想マシン スケール セットと仮想マシン (VM) が含まれています。
AKS クラスターを作成するときは、ノードの初期数とそのサイズとバージョンを定義し、 システム ノード プールを作成します。 システム ノード プールは、CoreDNS (coredns) や konnectivity (konnectivity-agent) など、重要なシステム ポッドをホストする主な目的を果たします。
コンピューティングまたは記憶域の要件が異なるアプリケーションをサポートするには、ユーザー ノード プールを作成します。 ユーザー ノード プールは、アプリケーション ポッドをホストするという主要な目的を果たします。
詳細については、AKS でのノード プールの作成に関する記事と AKS でのノード プールの管理に関する記事を参照してください。
ノード リソース グループ
Azure リソース グループ内に AKS クラスターを作成すると、AKS リソース プロバイダーにより "ノード リソース グループ" と呼ばれる 2 つ目のリソース グループが自動的に作成されます。 このリソース グループには、VM、仮想マシン スケール セット、ストレージなど、クラスターに関連付けられているすべてのインフラストラクチャ リソースが含まれます。
詳細については、次のリソースを参照してください。
- AKS と一緒にリソース グループが 2 つ作成されるのはなぜでしょうか?
- AKS ノード リソース グループに独自の名前を指定できますか?
- AKS ノード リソース グループ内のリソースのタグや他のプロパティを変更できますか?
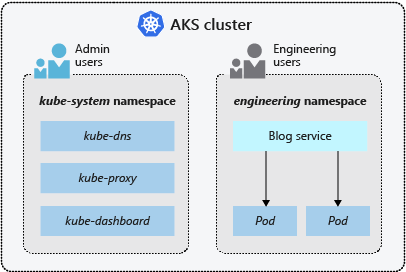
名前空間
AKS クラスターを分割し、リソースへのアクセス権の作成、表示、管理を制限するために、ポッドやデプロイなどの Kubernetes リソースは、論理的に 1 つの "名前空間" にグループ化されます。
AKS クラスターでは、以下の名前空間が既定で作成されます。
| 名前空間 | 説明 |
|---|---|
default |
default 名前空間を使用すると、新しい名前空間を作成せずにクラスター リソースの使用を開始できます。 |
kube-node-lease |
kube-node-lease 名前空間を使用すると、ノードがその可用性をコントロール プレーンに通信できるようになります。 |
kube-public |
通常、kube-public 名前空間は使用されませんが、任意のユーザーがクラスター全体でリソースを表示できるように使用できます。 |
kube-system |
kube-system 名前空間は、coredns、konnectivity-agent、metrics-server などのクラスター リソースを管理するために Kubernetes によって使用されます。 独自のアプリケーションをこの名前空間にデプロイすることはお勧めしません。 この名前空間に独自のアプリケーションをデプロイする必要があるまれなケースについては、 FAQ を参照してください。 |
クラスター モード
AKS では、自動モードまたは標準モードでクラスターを作成できます。 AKS Automatic は、よりフル マネージドのエクスペリエンスを提供します。 ノード、スケーリング、セキュリティ、その他の構成済み設定など、クラスター構成を管理できます。 AKS Standard では、ノード プールの管理機能、スケーリング、その他の設定など、クラスター構成をより詳細に制御できます。
詳細については、「AKS の Automatic と Standard の機能比較」を参照してください。
価格レベル
AKS には、クラスター管理用の 3 つの価格レベル (Free、Standard、Premium) が用意されています。 選択した価格レベルによって、クラスターの管理に使用できる機能が決まります。
詳細については、AKS クラスター管理のための価格レベルに関するページをご覧ください。
サポートされている Kubernetes のバージョン
詳細については、「AKS でサポートされる Kubernetes のバージョン」を参照してください。
関連コンテンツ
AKS の中心概念の詳細については、以下のリソースを参照してください。