リアルタイムの推論のためのオンライン エンドポイントとデプロイ
適用対象: Azure CLI ml extension v2 (現行)Python SDK azure-ai-ml v2 (現行)
Azure CLI ml extension v2 (現行)Python SDK azure-ai-ml v2 (現行)
Azure Machine Learning では、"オンライン エンドポイント" にデプロイされたモデルを使って、データに対してリアルタイムの推論を実行できます。 推論とは、機械学習モデルに新しい入力データを適用して出力を生成するプロセスです。 通常、これらの出力は "予測" と呼ばれますが、推論を使うと、分類やクラスタリングなどの他の機械学習タスク用の出力を生成できます。
オンライン エンドポイント
オンライン エンドポイントを使うと、HTTP プロトコルの下で予測を返すことができるモデルが Web サーバーにデプロイされます。 オンライン エンドポイントを使用して、同期型低遅延要求のリアルタイム推論用のモデルを運用化します。 次の場合に使用することをお勧めします。
- 低遅延の要件がある
- モデルが比較的短時間で要求に応答できる
- モデルの入力が要求の HTTP ペイロードに適合している
- 要求の数に関してスケールアップする必要がある
エンドポイントを定義するには、以下を指定する必要があります。
- エンドポイント名: この名前は、Azure リージョン内で一意である必要があります。 名前付けルールの詳細については、エンドポイントの制限に関する記事を参照してください。
- 認証モード: エンドポイントに対して、キーベースの認証モード、Azure Machine Learning トークンベースの認証モード、またはMicrosoft Entra トークンベースの認証 (プレビュー) の中から選ぶことができます。 認証の詳細については、オンライン エンドポイントの認証に関する記事を参照してください。
Azure Machine Learning は、ターンキー方式での機械学習モデルのデプロイにマネージド オンライン エンドポイントを使うことができるため便利です。 これは、Azure Machine Learning でオンライン エンドポイントを使うための "お勧め" の方法です。 マネージド オンライン エンドポイントは、スケーラブルでフル マネージドの方法で Azure の強力な CPU および GPU マシンと動作します。 また、これらのエンドポイントを使うと、モデルの提供、スケーリング、セキュリティ保護、監視が行われ、基になるインフラストラクチャの設定と管理のオーバーヘッドがなくなります。 マネージド オンライン エンドポイントを定義する方法については、「エンドポイントを定義する」を参照してください。
ACI または AKS(v1) 経由のマネージド オンライン エンドポイントを選ぶ理由
マネージド オンライン エンドポイントを使うのは、Azure Machine Learning でオンライン エンドポイントを使うための "お勧め" の方法です。 次の表は、Azure Machine Learning SDK/CLI v1 ソリューション (ACI と AKS(v1)) と比較した、マネージド オンライン エンドポイントの主な属性を示しています。
| 属性 | マネージド オンライン エンドポイント (v2) | ACI または AKS(v1) |
|---|---|---|
| ネットワークのセキュリティと分離 | クイックトグルを使った受信/送信制御が簡単 | 仮想ネットワークがサポートされていないか、複雑な手動構成が必要 |
| 管理されたサービス | - フル マネージドのコンピューティングのプロビジョニングとスケーリング - データ流出防止のためのネットワーク構成 - ホスト OS のアップグレード、インプレース更新の制御されたロールアウト |
- スケーリングは v1 限定 - ネットワーク構成またはアップグレードはユーザーによる管理が必要 |
| エンドポイントとデプロイの概念 | エンドポイントとデプロイの区別があるため、モデルの安全なロールアウトなど、複雑なシナリオに対応可能 | エンドポイントの概念なし |
| 診断および監視 | - Docker と Visual Studio Code でローカル エンドポイントのデバッグが可能 - デプロイ間で比較するための、グラフやクエリを使った高度なメトリックとログ分析 - コストの内訳はデプロイ レベルまで可能 |
ローカル デバッグが複雑 |
| スケーラビリティ | 無制限でエラスティックな自動スケーリング | - ACI が非スケーラブル - AKS (v1) はクラスター内スケールのみをサポート。スケーラビリティ構成が必要 |
| エンタープライズ対応 | プライベート リンク、カスタマー マネージド キー、Microsoft Entra ID、クォータ管理、課金の統合、SLA | サポートされていません |
| 高度な ML 機能 | - モデル データ収集 - モデルの監視 - チャンピオン チャレンジャー モデル、安全なロールアウト、トラフィック ミラーリング - 責任ある AI の拡張性 |
サポートされていません |
上記以外では、モデルのデプロイやエンドポイントの提供に Kubernetes を利用しており、インフラストラクチャ要件の管理に慣れている場合は、"Kubernetes オンライン エンドポイント" を使うことができます。 これらのエンドポイントでは、CPU や GPU を使って、完全に構成および管理された Kubernetes クラスターでどこでもモデルのデプロイやオンライン エンドポイントの提供を行うことができます。
AKS(v2) 経由のマネージド オンライン エンドポイントを選ぶ理由
マネージド オンライン エンドポイントを使うと、デプロイ プロセスを効率化し、Kubernetes オンライン エンドポイントに対して次の利点を得ることができます。
マネージド インフラストラクチャ
- コンピューティングを自動的にプロビジョニングし、モデルをホストします (VM の種類とスケールの設定のみ指定する必要があります)
- 基になるホスト OS イメージを自動的に更新しパッチを適用する
- システム障害が発生した場合にノードの自動回復を行います
監視とログ
- Azure Monitor とのネイティブ統合を使用して、モデルの可用性、パフォーマンス、および SLA を監視します。
- ログと、Azure Log Analytics とのネイティブ統合を使用して、デプロイをデバッグします。

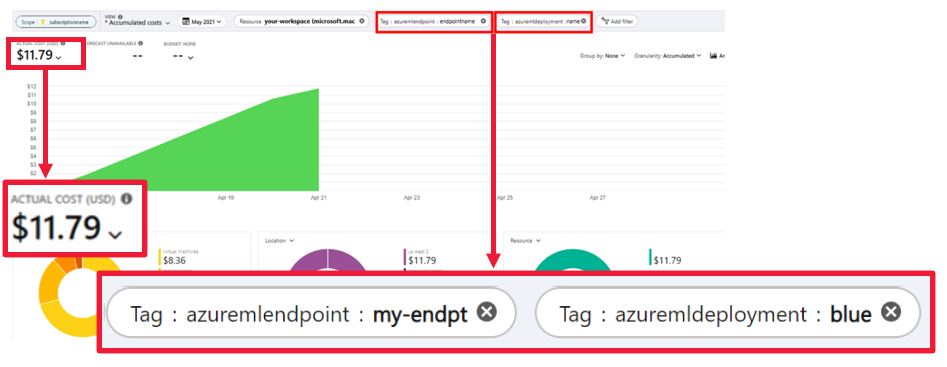
コストを表示する
- マネージド オンライン エンドポイントを使用すると、エンドポイントとデプロイのレベルでコストを監視できます。
注意
マネージド オンライン エンドポイントは、Azure Machine Learning コンピューティングに基づいています。 マネージド オンライン エンドポイントを使用する場合は、コンピューティングとネットワークの料金を支払います。 追加料金は発生しません。 価格の詳細については、Azure の料金計算ツールに関するページを参照してください。
Azure Machine Learning 仮想ネットワークを使ってマネージド オンライン エンドポイントからの送信トラフィックをセキュリティで保護する場合は、マネージド仮想ネットワークで使われている Azure プライベート リンクと FQDN 送信規則について課金されます。 詳細については、マネージド仮想ネットワークの価格に関する記事を参照してください。


マネージド オンライン エンドポイントと Kubernetes オンライン エンドポイント
次の表は、マネージド オンライン エンドポイントトと Kubernetes オンライン エンドポイントの主な違いを示しています。
| マネージド オンライン エンドポイント | Kubernetes オンライン エンドポイント (AKS(v2)) | |
|---|---|---|
| 推奨されるユーザー | マネージド モデル デプロイおよび拡張された MLOps エクスペリエンスを必要とするユーザー | Kubernetes を使用し、インフラストラクチャの要件を自己管理できるユーザー |
| ノード プロビジョニング | マネージド コンピューティングのプロビジョニング、更新、削除 | ユーザーの責任での対応 |
| ノード メンテナンス | マネージド ホスト OS イメージの更新、およびセキュリティ強化 | ユーザーの責任での対応 |
| クラスターのサイズ設定 (スケーリング) | マネージド 手動および自動スケーリング、追加のノード プロビジョニングをサポート | 手動と自動スケーリング、固定クラスター境界内のレプリカ数のスケーリングをサポート |
| コンピューティングの種類 | サービスによって管理 | カスタマー マネージド Kubernetes クラスター (Kubernetes) |
| 管理対象 ID | サポートされています | サポートされています |
| 仮想ネットワーク (VNET) | マネージド ネットワーク分離を介してサポート | ユーザーの責任での対応 |
| 追加設定なしの監視およびログ | Azure Monitor と Log Analytics を利用 (エンドポイントとデプロイの主要なメトリックとログ テーブルを含む) | ユーザーの責任での対応 |
| Application Insights のログ (レガシ) | サポートされています | サポートされています |
| コストを表示する | エンドポイントまたはデプロイ レベルに関する詳細 | クラスター レベル |
| 適用されるコスト | デプロイに割り当てられた VM | クラスターに割り当てられた VM |
| ミラー化されたトラフィック | サポートされています | サポートされていない |
| コードなしのデプロイ | サポートされている (MLflow と Triton の各モデル) | サポートされている (MLflow と Triton の各モデル) |
オンライン デプロイ
デプロイは、実際の推論を行うモデルをホストするのに必要な一連のリソースとコンピューティングです。 1 つのエンドポイントに、異なる構成を持つ複数のデプロイを含めることができます。 このセットアップを使うと、デプロイに提示されている "実装の詳細" から、エンドポイントによって提示されている "インターフェイスを切り離す" ことができます。 オンライン エンドポイントには、エンドポイント内の特定のデプロイに要求を転送できるルーティング メカニズムがあります。
次の図は、"blue" と "green" の 2 つのデプロイを持つオンライン エンドポイントを示しています。 Blue デプロイでは、CPU SKU を持つ VM が使用され、モデルのバージョン 1 が実行されます。 green デプロイでは、GPU SKU を持つ VM が使用され、モデルのバージョン 2 が実行されます。 エンドポイントは着信トラフィックの 90% を blue デプロイにルーティングするように構成されていますが、残りの 10% は green デプロイが受け取ります。

モデルをデプロイするには、次が必要です。
- モデル ファイル (または、ワークスペースに既に登録されているモデルの名前とバージョン)。
- スコアリング スクリプト、つまり、特定の入力要求でモデルを実行するコード。 スコアリング スクリプトは、デプロイされた Web サービスに送信されたデータを受け取り、それをモデルに渡します。 その後、スクリプトはモデルを実行して、その応答をクライアントに返します。 スコアリング スクリプトはモデルに固有のものであり、モデルが入力として期待し、出力として返すデータを理解する必要があります。
- モデルが実行される環境。 この環境には、Conda 依存関係がある Docker イメージか、または Dockerfile のいずれかを使用できます。
- インスタンスの種類とスケーリング キャパシティを指定するための設定。
デプロイの主な属性
次の表は、デプロイの主な属性について説明しています。
| 属性 | 内容 |
|---|---|
| 名前 | デプロイの名前。 |
| エンドポイント名 | デプロイを作成するエンドポイントの名前。 |
| Model1 | デプロイに使用するモデル。 この値は、ワークスペース内の既存のバージョン管理されたモデルへの参照またはインライン モデルの仕様のいずれかです。 モデルへのパスを追跡および指定する方法の詳細については、「AZUREML_MODEL_DIR に関するモデル パスを特定する」を参照してください。 |
| コード パス | モデルのスコアリングに使用されるすべての Python ソース コードが格納されている、ローカル開発環境上のディレクトリへのパス。 入れ子になったディレクトリとパッケージを使用できます。 |
| スコアリング スクリプト | ソース コード ディレクトリ内のスコアリング ファイルへの相対パス。 この Python コードには、init() 関数と run() 関数が含まれている必要があります。 init() 関数は、モデルの作成または更新後に呼び出されます (たとえば、モデルをメモリにキャッシュするために使用できます)。 run() 関数は、実際のスコアリングおよび予測を実行するために、エンドポイントが呼び出されるたびに呼び出されます。 |
| Environment1 | モデルとコードをホスティングする環境。 この値は、ワークスペース内の既存のバージョン管理された環境への参照、またはインライン環境仕様のいずれかになります。 注: Microsoft は、既知のセキュリティ脆弱性に対して、定期的にベース イメージにパッチを適用しています。 パッチが適用されているイメージを使うには、エンドポイントを再デプロイする必要があります。 独自のイメージを指定する場合は、その更新も行う必要があります。 詳細については、「イメージの修正」を参照してください。 |
| インスタンスの種類 | デプロイに使用する VM サイズ。 サポートされているサイズの一覧については、マネージド オンライン エンドポイント SKU の一覧に関するページを参照してください。 |
| インスタンス数 | デプロイに使用するインスタンスの数。 想定されるワークロードに基づく値を指定します。 高可用性を実現するために、この値を少なくとも 3 に設定することをお勧めします。 アップグレードを実行するために 20% 余分に予約されています。 詳細については、「デプロイのための仮想マシン クォータの割り当て」を参照してください。 |
1 モデルと環境に関する注意事項:
- デプロイの背後にあるインスタンスがセキュリティ パッチやその他の回復操作を実行すると、(環境で定義されている) モデルとコンテナー イメージは、デプロイによりいつでも再び参照できます。 Azure Container Registry で登録済みのモデルまたはコンテナー イメージをデプロイに使用し、モデルまたはコンテナー イメージを削除した場合、再イメージ化が行われると、これらの資産に依存するデプロイが失敗する可能性があります。 モデルまたはコンテナー イメージを削除した場合は、依存するデプロイが、代替モデルまたはコンテナー イメージで再作成または更新されていることを確認します。
- 環境で参照されるコンテナー レジストリは、エンドポイント ID に Microsoft Entra 認証と Azure RBAC を介してアクセスする権限がある場合にのみ、プライベートにすることができます。 同じ理由から、Azure Container Registry 以外のプライベート Docker レジストリはサポートされていません。
CLI、SDK、スタジオ、ARM テンプレートを使ってオンライン エンドポイントをデプロイする方法については、オンライン エンドポイントを使った ML モデルのデプロイに関する記事を参照してください。
AZUREML_MODEL_DIR に関するモデル パスを特定する
Azure Machine Learning にモデルをデプロイする場合、デプロイ構成の一部として、デプロイするモデルの場所を指定する必要があります。 Azure Machine Learning では、モデルへのパスは AZUREML_MODEL_DIR 環境変数で追跡されます。 AZUREML_MODEL_DIR に関してモデル パスを特定することで、マシンにローカルに保存されている 1 つ以上のモデルをデプロイしたり、Azure Machine Learning ワークスペースに登録されているモデルをデプロイしたりできます。
説明のために、単一のモデルをデプロイする場合と、ローカルに保存された複数のモデルをデプロイする場合の最初の 2 つのケースについて、次のローカル フォルダー構造を参照します。

デプロイで単一のローカル モデルを使用する
ローカル マシンにある単一のモデルをデプロイで使用するには、デプロイ YAML で path から model を指定します。 パス /Downloads/multi-models-sample/models/model_1/v1/sample_m1.pkl を持つデプロイ YAML の例を次に示します。
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model:
path: /Downloads/multi-models-sample/models/model_1/v1/sample_m1.pkl
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment:
conda_file: ../../model-1/environment/conda.yml
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest
instance_type: Standard_DS3_v2
instance_count: 1
デプロイを作成すると、環境変数 AZUREML_MODEL_DIR は、モデルが格納されている Azure 内の格納場所 (storage location) をポイントするようになります。 たとえば、/var/azureml-app/azureml-models/81b3c48bbf62360c7edbbe9b280b9025/1 にはモデル sample_m1.pkl が含まれます。
スコアリング スクリプト (score.py) 内で、init() 関数でモデル (この例では sample_m1.pkl) を読み込むことができます。
def init():
model_path = os.path.join(str(os.getenv("AZUREML_MODEL_DIR")), "sample_m1.pkl")
model = joblib.load(model_path)
デプロイで複数のローカル モデルを使用する
Azure CLI、Python SDK、その他のクライアント ツールでは、配置定義で 1 回のデプロイあたり 1 つのモデルのみを指定できますが、すべてのモデルをファイルまたはサブディレクトリとして含むモデル フォルダーを登録することで、1 回のデプロイで複数のモデルを引き続き使用できます。
先ほどのフォルダー構造の例では、models フォルダーに複数のモデルがあることがわかります。 デプロイ YAML では、models フォルダーへのパスを次のように指定できます。
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model:
path: /Downloads/multi-models-sample/models/
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment:
conda_file: ../../model-1/environment/conda.yml
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest
instance_type: Standard_DS3_v2
instance_count: 1
デプロイを作成すると、環境変数 AZUREML_MODEL_DIR は、モデルが格納されている Azure 内の格納場所 (storage location) をポイントするようになります。 たとえば、/var/azureml-app/azureml-models/81b3c48bbf62360c7edbbe9b280b9025/1 にはモデルとファイル構造が含まれます。
この例では、AZUREML_MODEL_DIR フォルダーの内容は次のようになります。

スコアリング スクリプト (score.py) 内で、init() 関数でモデルを読み込むことができます。 sample_m1.pkl モデルを読み込むコードを次に示します。
def init():
model_path = os.path.join(str(os.getenv("AZUREML_MODEL_DIR")), "models","model_1","v1", "sample_m1.pkl ")
model = joblib.load(model_path)
1 つのデプロイに複数のモデルをデプロイする方法の例については、1 つのデプロイへの複数のモデルのデプロイ (CLI の例) と 1 つのデプロイへの複数のモデルのデプロイ (SDK の例) に関する記事を参照してください。
ヒント
登録するファイルが 1500 を超える場合は、モデルの登録時にファイルまたはサブディレクトリを .tar.gz として圧縮することを検討してください。 モデルを使用するには、スコアリング スクリプトから init() 関数のファイルまたはサブディレクトリを圧縮解除します。 または、モデルを登録するときに、azureml.unpack プロパティを True に設定すると、ファイルやサブディレクトリが自動圧縮解除されます。 この場合、圧縮解除は初期化ステージで 1 回行われます。
Azure Machine Learning ワークスペースに登録されたモデルをデプロイで使用する
Azure Machine Learning ワークスペースに登録されている 1 つ以上のモデルをデプロイで使用するには、デプロイ YAML に登録されているモデルの名前を指定します。 たとえば、次のデプロイ YAML 構成で登録された model の名前を azureml:local-multimodel:3 と指定します。
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model: azureml:local-multimodel:3
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment:
conda_file: ../../model-1/environment/conda.yml
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest
instance_type: Standard_DS3_v2
instance_count: 1
この例では、local-multimodel:3 に Azure Machine Learning スタジオの [モデル] タブから表示できる次のモデルの成果物が含まれることを考慮してください。

デプロイを作成すると、環境変数 AZUREML_MODEL_DIR は、モデルが格納されている Azure 内の格納場所 (storage location) をポイントするようになります。 たとえば、/var/azureml-app/azureml-models/local-multimodel/3 にはモデルとファイル構造が含まれます。 AZUREML_MODEL_DIR は、モデル成果物のルートを含むフォルダーを指します。
この例に基づき、AZUREML_MODEL_DIR フォルダーの内容は次のようになります。

スコアリング スクリプト (score.py) 内で、init() 関数でモデルを読み込むことができます。 たとえば、次の diabetes.sav モデルを読み込みます。
def init():
model_path = os.path.join(str(os.getenv("AZUREML_MODEL_DIR"), "models", "diabetes", "1", "diabetes.sav")
model = joblib.load(model_path)
デプロイのための仮想マシン クォータの割り当て
マネージド オンライン エンドポイントの場合、Azure Machine Learning では、一部の VM SKU でアップグレードを実行するためにコンピューティング リソースの 20% が予約されます。 デプロイ内のそれらの VM SKU に対して特定の数のインスタンスを要求する場合は、使用可能な ceil(1.2 * number of instances requested for deployment) * number of cores for the VM SKU のクォータを確保して、エラーが発生しないようにする必要があります。 たとえば、デプロイで Standard_DS3_v2 VM (4 コアを搭載) の 10 個のインスタンスを要求する場合は、使用可能な 48 コア (12 instances * 4 cores) のクォータが必要です。 この追加のクォータは、OS のアップグレードや VM の復旧などのシステムによって開始される操作用に予約されており、そのような操作が実行されない限りコストは発生しません。
追加のクォータ予約から除外される特定の VM SKU があります。 完全な一覧を表示するには、マネージド オンライン エンドポイント SKU の一覧を参照してください。
使用状況を確認してクォータの増加を要求するには、「Azure portal で使用状況とクォータを表示する」を参照してください。 マネージド オンライン エンドポイントの実行コストを表示するには、「マネージド オンライン エンドポイントのコストを表示する」を参照してください。
Azure Machine Learning には、すべてのユーザーがクォータにアクセスして限られた時間のテストを実行できる、共有クォータ プールが用意されています。 スタジオを使用して (モデル カタログから) Llama モデルをマネージド オンライン エンドポイントにデプロイする場合、Azure Machine Learning では、この共有クォータに短時間アクセスできます。
ただし、Llama-2-70b または Llama-2-70b-chat モデルをデプロイするには、共有クォータを使用してデプロイする前に Enterprise Agreement サブスクリプションが必要です。 オンライン エンドポイントのデプロイに共有クォータを使用する方法の詳細については、「スタジオを使用して基礎モデルをデプロイする方法」を参照してください。
Azure Machine Learning のリソースのクォータと制限の詳細については、「Azure Machine Learning を使用するリソースのクォータと制限の管理と引き上げ」を参照してください。
プログラマーと非プログラマーのデプロイ
Azure Machine Learning は、"コードなしのデプロイ"、"ローコード デプロイ"、"Bring Your Own Certificate (BYOC) デプロイ" のオプションを提供しており、プログラマーと非プログラマーのいずれに対しても同様に、オンライン エンドポイントへのモデル デプロイをサポートしています。
- コードなしのデプロイでは、一般的なフレームワーク (scikit-learn、TensorFlow、PyTorch、ONNX など) に対する推論を、MLflow や Triton を使って追加設定なしで行うことができます。
- ローコード デプロイでは、デプロイに対して、機械学習モデルと併せて最小限のコードを指定できます。
- BYOC デプロイでは、任意のコンテナーを仮想的に使って、オンライン エンドポイントを実行できます。 自動スケーリング、GitOps、デバッグ、安全なロールアウトなど、Azure Machine Learning プラットフォームのあらゆる機能を使って、MLOps パイプラインを管理できます。
次の表は、オンライン デプロイのオプションに関する主な側面を示しています。
| コードなし | ローコード | BYOC | |
|---|---|---|---|
| まとめ | scikit-learn、TensorFlow、PyTorch、ONNX などの一般的なフレームワークに対して MLflow や Triton を使って追加設定なしで行うことができる推論を使います。 詳細については、「MLflow モデルのオンライン エンドポイントへのデプロイ」を参照してください。 | 一般的なフレームワークには、安全で公開済みのキュレーションされたイメージを使います。脆弱性に対処するために、2 週間ごとに更新プログラムが実行されます。 ユーザーは、スコアリング スクリプトや Python の依存関係を指定します。 詳細については、「Azure Machine Learning のキュレーションされた環境」を参照してください。 | カスタム イメージに対する Azure Machine Learning のサポートを使って、完全なスタックを指定します。 詳細については、「カスタム コンテナーを使用してモデルをオンライン エンドポイントにデプロイする」を参照してください。 |
| カスタム基本イメージ | 対応していません。キュレーションされた環境では、デプロイを簡単に行うことができます。 | 対応している場合と対応していない場合があります。キュレーションされたイメージも、カスタマイズしたイメージも使うことができます。 | 対応しています。コンテナーの ACR でビルドまたはプッシュできる、アクセス可能なコンテナー イメージの場所 (docker.io、Azure Container Registry (ACR)、Microsoft Container Registry (MCR) など) または Dockerfile を使います。 |
| カスタムの依存関係 | 対応していません。キュレーションされた環境では、デプロイを簡単に行うことができます。 | 対応しています。モデルが実行されている Azure Machine Learning 環境を使います (Conda 依存関係を持つ Docker イメージ、または dockerfile)。 | 対応しています。これは、コンテナー イメージに含まれます。 |
| カスタム コード | 対応していません。簡単にデプロイできるように、スコアリング スクリプトが自動生成されます。 | 対応しています。スコアリング スクリプトをお使いください。 | 対応しています。これは、コンテナー イメージに含まれます。 |
Note
AutoML を実行すると、ユーザーに対してスコアリング スクリプトと依存関係が自動的に作成されるため、追加のコードを作成しなくても任意の AutoML モデルをデプロイできます (コードなしのデプロイの場合)。または、自動生成されたスクリプトをビジネス ニーズに合わせて変更することができます (ローコード デプロイの場合)。AutoML モデルを使ってデプロイする方法については、オンライン エンドポイントを使った AutoML モデルのデプロイに関する記事を参照してください。
オンライン エンドポイントのデバッグ
Azure にデプロイする前に、コードと構成を検証およびデバッグするために、エンドポイントをローカルでテスト実行することを "強くお勧めします"。 Azure CLI と Python SDK ではローカルのエンドポイントとデプロイがサポートされていますが、Azure Machine Learning スタジオと ARM テンプレートではサポートされていません。
Azure Machine Learning には、オンライン エンドポイントをローカルでデバッグする方法や、コンテナー ログを使ってデバッグする方法など、さまざまな方法が用意されています。
- Azure Machine Learning 推論 HTTP サーバーを使用したローカル デバッグ
- ローカル エンドポイントを使用したローカル デバッグ
- ローカル エンドポイントと Visual Studio Code を使用したローカル デバッグ
- コンテナー ログを使用したデバッグ
Azure Machine Learning 推論 HTTP サーバーを使用したローカル デバッグ
Azure Machine Learning 推論 HTTP サーバーを使うと、スコアリング スクリプトをローカルでデバッグできます。 この HTTP サーバーは、スコアリング関数を HTTP エンドポイントとして公開し、Flask サーバー コードと依存関係を単一のパッケージにラップしている Python パッケージです。 これは、Azure Machine Learning でモデルをデプロイする際に使用する推論用の事前構築済み Docker イメージに含まれています。 このパッケージのみを使用すると、運用環境用にローカルにモデルをデプロイできます。また、ローカル開発環境でスコアリング (エントリ) スクリプトを簡単に検証することもできます。 スコアリング スクリプトに問題がある場合、サーバーからエラーとそのエラーが発生した場所が返されます。 Visual Studio Code を使って、Azure Machine Learning 推論 HTTP サーバーでデバッグすることもできます。
ヒント
Azure Machine Learning 推論 HTTP サーバー Python パッケージを使用して、Docker エンジンなしでスコアリング スクリプトをローカルでデバッグできます。 推論サーバーを使用したデバッグは、ローカル エンドポイントにデプロイする前にスコアリング スクリプトをデバッグするのに役立ちます。これにより、デプロイ コンテナーの構成の影響を受けることなくデバッグできます。
HTTP サーバーを使ったデバッグの詳細については、「Azure Machine Learning 推論 HTTP サーバーを使用したスコアリング スクリプトのデバッグ (プレビュー)」を参照してください。
ローカル エンドポイントを使用したローカル デバッグ
ローカル デバッグの場合は、ローカル デプロイが必要です。つまり、ローカル Docker 環境にデプロイされているモデルです。 このローカル デプロイは、クラウドにデプロイする前のテストやデバッグに使うことができます。 ローカルにデプロイするには、Docker エンジンをインストールして実行する必要があります。 その後、Azure Machine Learning で、Azure Machine Learning イメージを模倣したローカル Docker イメージが作成されます。 Azure Machine Learning では、ユーザーに代わって、ローカルでデプロイを構築して実行し、迅速な反復処理用にイメージをキャッシュします。
ヒント
通常、Docker エンジンは、コンピューターの起動時に起動します。 起動しない場合は、Docker エンジンをトラブルシューティングします。 Docker Desktop などのクライアント側ツールを使用し、コンテナーで起こることをデバッグできます。
通常、ローカル デバッグの手順は次のとおりです。
- ローカル デプロイが成功したかどうかの確認
- 推論に向けたローカル エンドポイントの呼び出し
- 呼び出し操作の出力のログの確認
Note
ローカル エンドポイントには、次の制限があります。
ローカル デバッグの詳細については、「ローカル エンドポイントを使用してデプロイとデバッグをローカルで行う」を参照してください。
ローカル エンドポイントと Visual Studio Code を使用したローカル デバッグ (プレビュー)
重要
現在、この機能はパブリック プレビュー段階にあります。 このプレビュー バージョンはサービス レベル アグリーメントなしで提供されており、運用環境のワークロードに使用することは推奨されません。 特定の機能はサポート対象ではなく、機能が制限されることがあります。
詳しくは、Microsoft Azure プレビューの追加使用条件に関するページをご覧ください。
ローカル デバッグと同様に、まず Docker エンジンをインストールして実行してから、ローカル Docker 環境にモデルをデプロイする必要があります。 ローカル デプロイを実行すると、Azure Machine Learning のローカル エンドポイントでは、Docker と Visual Studio Code の開発コンテナーを使ったローカルのデバッグ環境の構築と構成が行われます。 開発コンテナーでは、Docker コンテナー内から、対話型デバッグなど、Visual Studio Code の機能を利用できます。
VS Code でのオンライン エンドポイントの対話型デバッグの詳細については、「Visual Studio Code を使用してオンライン エンドポイントをローカルでデバッグする」を参照してください。
コンテナー ログを使ったデバッグ
デプロイでは、モデルがデプロイされている VM に直接アクセスすることはできません。 ただし、VM で実行されている一部のコンテナーからログを取得することはできます。 ログを取得できるコンテナーには、次の 2 種類があります。
- 推論サーバー: ログには、(推論サーバーからの) コンソール ログが含まれます。これには、スコアリング スクリプト (
score.pyコード) からの出力/ログ記録関数の出力が含まれます。 - ストレージ初期化子: ログには、コードとモデル データがコンテナーに正常にダウンロードされたかどうかに関する情報が含まれます。 推論サーバー コンテナーの実行が開始される前に、コンテナーが実行されます。
コンテナー ログを使ったデバッグの詳細については、「コンテナー ログを取得する」を参照してください。
オンライン デプロイへのトラフィック ルーティングとミラーリング
1 つのオンライン エンドポイントに複数のデプロイを含めることができることを思い出してください。 エンドポイントで受信トラフィック (または要求) を受け取ると、ネイティブの blue/green デプロイ戦略で使われているように、トラフィックの割合を各デプロイにルーティングできます。 また、あるデプロイから別のデプロイへのトラフィックをミラーリング (またはコピー) することもできます。これは、トラフィック ミラーリングまたはシャドウイングともいいます。
blue/green デプロイのトラフィック ルーティング
blue/green デプロイは、新しいデプロイ (green デプロイ) を完全にロールアウトする前に、小さなサブセットのユーザーまたは要求にロールアウトできるデプロイ戦略です。 エンドポイントでは、負荷分散を実装して、特定の割合のトラフィックを各デプロイに割り当てることができます。すべてのデプロイに対して、合計最大 100% が割り当てられます。
ヒント
要求では、azureml-model-deployment の HTTP ヘッダーを含めることによって、構成されたトラフィックの負荷分散をバイパスできます。 ヘッダーの値を、要求のルーティング先のデプロイの名前に設定します。
次の図は、blue デプロイと green デプロイの間のトラフィックの割り当てに対する Azure Machine Learning スタジオでの設定を示しています。

このトラフィック割り当てでは、次の図に示すように、トラフィックがルーティングされます。トラフィックの 10% が green デプロイに、トラフィックの 90% が blue デプロイに送信されます。
オンライン デプロイへのトラフィック ミラーリング
エンドポイントでは、あるデプロイから別のデプロイへのトラフィックをミラーリング (またはコピー) することもできます。 トラフィック ミラーリング (シャドウ テストともいいます) は、顧客が既存のデプロイから受け取る結果に影響を与えることなく、実稼働トラフィックで新しいデプロイをテストする場合に便利です。 たとえば、blue/green デプロイを実装しており、トラフィックの 100% が blue デプロイにルーティングされ、10% が green デプロイに "ミラーリング" されている場合、green デプロイにミラーリングされたトラフィックの結果はクライアントに返されませんが、メトリックとログが記録されます。

トラフィック ミラーリングを使う方法については、オンライン エンドポイントの安全なロールアウトに関する記事を参照してください。
Azure Machine Learning でのオンライン エンドポイントのその他の機能
認証と暗号化
- 認証: キーと Azure Machine Learning トークン
- マネージド ID: ユーザー割り当ておよびシステム割り当て
- エンドポイント呼び出しのための既定の SSL
自動スケール
自動スケールでは、アプリケーションの負荷を処理するために適切な量のリソースが自動的に実行されます。 マネージド エンドポイントは、Azure Monitor 自動スケーリング機能との統合によって、自動スケールをサポートします。 メトリックベースのスケーリング (たとえば、CPU 使用率 >70%)、スケジュールに基づくスケーリング (たとえば、営業時間のピーク時のルールのスケーリング)、またはその組み合わせを構成できます。

自動スケーリングを構成する方法については、オンライン エンドポイントの自動スケーリング方法に関する記事を参照してください。
マネージド ネットワーク分離
機械学習モデルをマネージド オンライン エンドポイントにデプロイするときに、プライベート エンドポイントを使ってオンライン エンドポイントとの通信をセキュリティ保護できます。
ワークスペースやその他のサービスでの受信スコアリング要求と送信通信のセキュリティを個別に構成できます。 受信通信では、Azure Machine Learning ワークスペースのプライベート エンドポイントが使用されます。 送信通信では、ワークスペースのマネージド仮想ネットワーク用に作成されたプライベート エンドポイントが使用されます。
詳細については、マネージド オンライン エンドポイントによるネットワーク分離に関するページを参照してください。
オンライン エンドポイントとデプロイの監視
Azure Machine Learning エンドポイントの監視は、Azure Monitor との統合を行うと可能になります。 この統合を行うと、グラフでのメトリックの表示、アラートの構成、ログ テーブルからのクエリの実行を行うことができると同時に、Application Insights を使ってユーザー コンテナーからイベントを分析することができます。
メトリック: Azure Monitor を使って、要求の待機時間など、さまざまなエンドポイント メトリックを追跡して、デプロイまたは状態レベルにドリルダウンします。 また、CPU や GPU の使用率など、デプロイ レベルのメトリックを追跡し、インスタンス レベルにドリルダウンすることもできます。 Azure Monitor では、グラフ内のこれらのメトリックを追跡し、ダッシュボードとアラートを設定して、さらに分析を行うことができます。
ログ: Kusto クエリ構文を使ってログに対してクエリを実行できる Log Analytics ワークスペースにメトリックを送信します。 ストレージ アカウントや Event Hubs にメトリックを送信して、さらに処理を行うこともできます。 また、オンライン エンドポイント関連のイベント、トラフィック、コンテナー ログに専用のログ テーブルを使うことができます。 Kusto クエリを使うと、複数のテーブルが結合された複雑な分析を行うことができます。
Application Insights: キュレーションされた環境には Application Insights との統合が含まれています。これは、オンライン デプロイを作成するときに有効または無効にすることができます。 組み込みのメトリックとログは Application insights に送信され、ライブ メトリック、トランザクション検索、エラー、パフォーマンスなどの組み込み機能を使って、さらに分析を行うことができます。
監視の詳細については、「オンライン エンドポイントを監視する」を参照してください。
オンライン デプロイでのシークレットの挿入 (プレビュー)
オンライン デプロイのコンテキストでのシークレットの挿入は、シークレット ストアからシークレット (API キーなど) を取得し、オンライン デプロイ内で実行されているユーザー コンテナーにそれを挿入するプロセスです。 シークレットは、最終的には環境変数を介してアクセスできるようになります。これにより、スコアリング スクリプトを実行する推論サーバー、または BYOC (Bring Your Own Container) デプロイ アプローチを使ってユーザーが導入する推論スタックで、安全な方法で使用できます。
シークレットを挿入する方法は 2 つあります。 マネージド ID を使用してシークレットを自分で挿入するか、シークレット挿入機能を使用することができます。 シークレットを挿入する方法の詳細については、「オンライン エンドポイントでのシークレットの挿入 (プレビュー)」を参照してください。
次のステップ
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示