チュートリアル:電話番号のカスタム アナライザーを作成する
検索ソリューションで、文字列に複雑なパターンや特殊文字を含まれていると、そのパターンの意味のある部分が既定のアナライザーによって取り除かれたり、誤って解釈されたりするため、その文字列の扱いが難しくなります。そしてユーザーが期待した情報を見つけられないと、これが検索エクスペリエンスの低下につながることになります。 電話番号は、分析しにくい文字列の典型的な例です。 さまざまな形式があり、既定のアナライザーで無視される特殊文字が含まれています。
このチュートリアルでは、電話番号を例に挙げながら、パターン化されたデータの問題を細かく見ていきます。その後、カスタム アナライザーを使用して、その問題を解決する方法について説明します。 ここで説明するアプローチは、電話番号にそのまま使用することも、URL、電子メール、郵便番号、日付など、同じ特性を持つ (パターン化され、特殊文字を含む) フィールドに合わせて調整することもできます。
このチュートリアルでは、REST クライアントと Azure AI 検索 REST API を使用して、次の操作を行います。
- 問題を把握する
- 電話番号を処理するための初期カスタム アナライザーを開発する
- カスタム アナライザーをテストする
- カスタム アナライザーの設計を繰り返し、結果をさらに改善する
前提条件
このチュートリアルには、次のサービスとツールが必要です。
Azure AI 検索. 現在のサブスクリプションで、既存の Azure AI 検索サービスを見つけるか、または作成します。 このクイック スタート用には、無料のサービスを使用できます。
ファイルのダウンロード
このチュートリアルのソース コードは、Azure-Samples/azure-search-rest-samples GitHub リポジトリにある custom-analyzer.rest ファイルです。
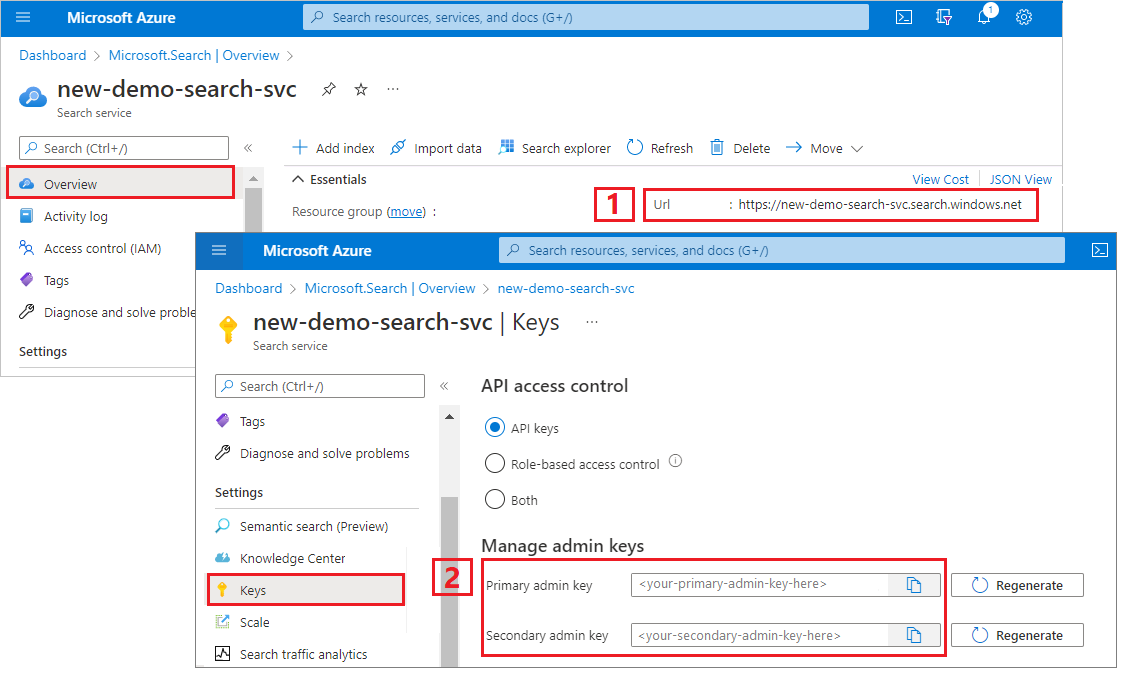
キーと URL をコピーする
このチュートリアルの REST 呼び出しには、検索サービス エンドポイントと管理 API キーが必要です。 これらの値は Azure portal から取得できます。
Azure portal にサインインし、[概要] ページに移動して URL をコピーします。 たとえば、エンドポイントは
https://mydemo.search.windows.netのようになります。[設定]>[キー] で管理者キーをコピーします。 管理者キーは、オブジェクトの追加、変更、削除で使用します。 2 つの交換可能な管理者キーがあります。 どちらかをコピーします。
有効な API キーにより、要求を送信するアプリケーションとそれを処理する検索サービスとの間で、要求ごとに信頼が確立されます。
初期インデックスを作成する
Visual Studio Code で新しいテキスト ファイルを開きます。
前の手順で収集した検索エンドポイントと API キーに変数を設定します。
@baseUrl = PUT-YOUR-SEARCH-SERVICE-URL-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HERE.restファイル拡張子でファイルを保存します。次の例を貼り付けて、
idとphone_numberの 2 つのフィールドを含むphone-numbers-indexという小さなインデックスを作成します。 まだアナライザーを定義していないので、standard.luceneアナライザーが既定で使用されます。### Create a new index POST {{baseUrl}}/indexes?api-version=2024-07-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "name": "phone-numbers-index", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "searchable": true, "filterable": false, "facetable": false, "sortable": true }, { "name": "phone_number", "type": "Edm.String", "sortable": false, "searchable": true, "filterable": false, "facetable": false } ] }[要求の送信] をクリックします。
HTTP/1.1 201 Created応答が返され、その応答本文にはインデックス スキーマの JSON 表現が含まれているはずです。さまざまな電話番号形式を含むドキュメントを使用して、インデックスにデータを読み込みます。 これがテスト データです。
### Load documents POST {{baseUrl}}/indexes/phone-numbers-index/docs/index?api-version=2024-07-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "value": [ { "@search.action": "upload", "id": "1", "phone_number": "425-555-0100" }, { "@search.action": "upload", "id": "2", "phone_number": "(321) 555-0199" }, { "@search.action": "upload", "id": "3", "phone_number": "+1 425-555-0100" }, { "@search.action": "upload", "id": "4", "phone_number": "+1 (321) 555-0199" }, { "@search.action": "upload", "id": "5", "phone_number": "4255550100" }, { "@search.action": "upload", "id": "6", "phone_number": "13215550199" }, { "@search.action": "upload", "id": "7", "phone_number": "425 555 0100" }, { "@search.action": "upload", "id": "8", "phone_number": "321.555.0199" } ] }ユーザーが入力する可能性のあるクエリと似たものをいくつか試してみましょう。
(425) 555-0100の検索に使用される形式はさまざまですが、それでも結果が返されることをユーザーは期待します。 まず、(425) 555-0100を検索します。### Search for a phone number GET {{baseUrl}}/indexes/phone-numbers-index/docs/search?api-version=2024-07-01&search=(425) 555-0100 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}}クエリでは、期待される 4 つの結果のうち 3 つが返されますが、予期しない結果も 2 つ返されます。
{ "value": [ { "@search.score": 0.05634898, "phone_number": "+1 425-555-0100" }, { "@search.score": 0.05634898, "phone_number": "425 555 0100" }, { "@search.score": 0.05634898, "phone_number": "425-555-0100" }, { "@search.score": 0.020766128, "phone_number": "(321) 555-0199" }, { "@search.score": 0.020766128, "phone_number": "+1 (321) 555-0199" } ] }次は書式が設定されていない
4255550100を試してみましょう。### Search for a phone number GET {{baseUrl}}/indexes/phone-numbers-index/docs/search?api-version=2024-07-01&search=4255550100 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}}結果は先ほどよりも悪く、正しい一致は 4 つあるのですが、そのうち 1 つしか返されません。
{ "value": [ { "@search.score": 0.6015292, "phone_number": "4255550100" } ] }
多くの人がこれらの結果に戸惑うことでしょう。 次のセクションでは、このような結果になる理由を深く掘り下げます。
アナライザーのしくみを確認する
これらの検索結果を理解するには、アナライザーの動作を理解する必要があります。 そこから、Analyze API を使用して既定のアナライザーをテストし、ニーズを満たすアナライザーを設計するための基盤を提供することができます。
アナライザーは、クエリ文字列内のテキストとインデックス付きドキュメントを処理するフル テキスト検索エンジンのコンポーネントです。 シナリオに応じて、さまざまなアナライザーがさまざまな方法でテキストを操作します。 このシナリオでは、電話番号に特化したアナライザーを作成する必要があります。
アナライザーは次の 3 つのコンポーネントから成ります。
- 文字フィルター: 入力テキスト内の個々の文字を削除または置換します。
- トークナイザー: 入力テキストをトークンに分割します。これらのトークンが、検索インデックスにおけるキーになります。
- トークン フィルター: トークナイザーによって生成されたトークンを処理します。
次の図では、文をトークン化するために、この 3 つのコンポーネントがどのように連携しているかを確認できます。

その後、高速なフルテキスト検索を可能にする転置インデックスにこれらのトークンが格納されます。 フルテキスト検索は、字句解析中に抽出された一意の語句すべてを、それが出現するドキュメントへと、転置インデックスによってマッピングすることで実現されます。 次の図では例を確認できます。

すべての検索は、転置インデックスに格納された語句の検索に帰結します。 ユーザーからクエリが送信されると、次の処理が行われます。
- クエリが解析されて、検索語が解析されます。
- 転置インデックスがスキャンされて、一致する語句を含んだドキュメントが検出されます。
- 最後に、取得されたドキュメントがスコアリング アルゴリズムによってランク付けされます。
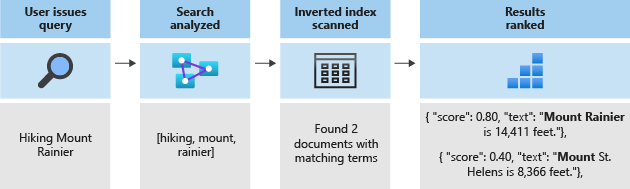
検索語が転置インデックス内の語句と一致しなかった場合、結果は返されません。 クエリの機構について詳しくは、フルテキスト検索に関する記事を参照してください。
注意
部分的な語句のクエリは、この規則の重要な例外です。 これらのクエリ (プレフィックス クエリ、ワイルドカード クエリ、正規表現クエリ) では、通常の語句クエリとは異なり、字句解析プロセスがバイパスされます。 部分的な語句は、小文字化のみが適用されて、インデックス内の語句と比較されます。 これらの種類のクエリをサポートするようにアナライザーが構成されていなかった場合、往々にして予期しない結果となります。一致する語句がインデックスに存在しないためです。
Analyze API を使用してアナライザーをテストする
Azure AI 検索には、Analyze API が用意されています。Analyze API を使用してアナライザーをテストし、そのテキスト処理の動作を理解することができます。
Analyze API は、次の要求を使用して呼び出します。
POST {{baseUrl}}/indexes/phone-numbers-index/analyze?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"text": "(425) 555-0100",
"analyzer": "standard.lucene"
}
この API は、指定したアナライザーを使用して、テキストから抽出されたトークンを返します。 標準の Lucene アナライザーによって、電話番号が 3 つの独立したトークンに分割されます。
{
"tokens": [
{
"token": "425",
"startOffset": 1,
"endOffset": 4,
"position": 0
},
{
"token": "555",
"startOffset": 6,
"endOffset": 9,
"position": 1
},
{
"token": "0100",
"startOffset": 10,
"endOffset": 14,
"position": 2
}
]
}
反対に、区切りなしで書式設定された電話番号 4255550100 は単一のトークンにトークン化されています。
{
"text": "4255550100",
"analyzer": "standard.lucene"
}
応答:
{
"tokens": [
{
"token": "4255550100",
"startOffset": 0,
"endOffset": 10,
"position": 0
}
]
}
インデックスが作成されたドキュメントと検索語の両方が分析されることに注意してください。 前の手順の検索結果を振り返ってみると、このような結果が返された理由が見えてきます。
1 つ目のクエリで、予期しない電話番号が返されたのは、そのトークンの 1 つ (555) が、検索した語句の 1 つと一致したためです。 2 つ目のクエリで、数値が 1 つしか返されなかったのは、それが 4255550100 と一致するトークンを含む唯一のレコードであったためです。
カスタム アナライザーを構築する
現状の結果について理解したら、カスタム アナライザーを作成して、トークン化のロジックを改善しましょう。
目標は、インデックスされた文字列やクエリの書式に関係なく、電話番号に対する直感的な検索を実現することです。 この結果を得るには、文字フィルター、トークナイザー、トークン フィルターを指定します。
文字フィルター
文字フィルターは、トークナイザーに取り込まれる前のテキストを処理する目的で使用されます。 文字フィルターの一般的な用途として、HTML 要素をフィルターで除去したり、特殊文字を置換したりすることが挙げられます。
電話番号に関しては、空白と特殊文字を除去する必要があります。電話番号の形式によっては、同じ特殊文字や空白が含まれていない場合もあるためです。
"charFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.MappingCharFilter",
"name": "phone_char_mapping",
"mappings": [
"-=>",
"(=>",
")=>",
"+=>",
".=>",
"\\u0020=>"
]
}
]
フィルターによって、-、(、)、+、. と、空白が入力から削除されます。
| input | 出力 |
|---|---|
(321) 555-0199 |
3215550199 |
321.555.0199 |
3215550199 |
Tokenizer
トークナイザーは、テキストをトークンに分割すると共に、その過程で一部の文字 (句読点など) を破棄します。 多くの場合、文を個々の単語に分割するのがトークン化の目標です。
このシナリオでは、電話番号を 1 つの語句としてキャプチャしたいので、キーワード トークナイザー keyword_v2 を使用します。 この問題を解決する方法は他にもあることに注意してください。 以降の「別のアプローチ」のセクションを参照してください。
キーワード トークナイザーは常に、1 つの語句として与えられる場合と同じテキストを出力します。
| 入力 | 出力 |
|---|---|
The dog swims. |
[The dog swims.] |
3215550199 |
[3215550199] |
トークン フィルター
トークン フィルターは、トークナイザによって生成されたトークンを除外したり加工したりします。 トークン フィルターの一般的な用途の 1 つは、lowercase トークン フィルターを使用して、すべての文字を小文字化することです。 また、the、and、is などのストップワードをフィルターで除去する用途にも使用されます。
このシナリオではどちらのフィルターも使用しませんが、電話番号の部分検索に対応できるよう、nGram トークン フィルターを使用します。
"tokenFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.NGramTokenFilterV2",
"name": "custom_ngram_filter",
"minGram": 3,
"maxGram": 20
}
]
NGramTokenFilterV2
nGram_v2 トークン フィルターは、minGram と maxGram パラメーターに基づいて、特定のサイズの n-gram にトークンを分割します。
電話番号のアナライザーの場合、minGram は 3 に設定します。ユーザーが検索に使用すると考えられる部分文字列の最小文字数が 3 であるためです。 maxGram は、内線番号を含んでいてもすべての電話番号が単一の n-gram に収まるよう、20 に設定します。
残念ながら n-gram には、ある程度の擬陽性が返されるという副作用があります。 これは、後の手順で、n-gram トークン フィルターを含まないアナライザーを検索用に別途構築することで修正します。
| input | 出力 |
|---|---|
[12345] |
[123, 1234, 12345, 234, 2345, 345] |
[3215550199] |
[321, 3215, 32155, 321555, 3215550, 32155501, 321555019, 3215550199, 215, 2155, 21555, 215550, ... ] |
アナライザー
文字フィルター、トークナイザー、トークン フィルターが揃ったら、アナライザーを定義する準備は完了です。
"analyzers": [
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer",
"tokenizer": "keyword_v2",
"tokenFilters": [
"custom_ngram_filter"
],
"charFilters": [
"phone_char_mapping"
]
}
]
次の表は、Analyze API からの入力と、それに対応するカスタム アナライザーからの出力を示しています。
| input | 出力 |
|---|---|
12345 |
[123, 1234, 12345, 234, 2345, 345] |
(321) 555-0199 |
[321, 3215, 32155, 321555, 3215550, 32155501, 321555019, 3215550199, 215, 2155, 21555, 215550, ... ] |
出力列のすべてのトークンがインデックスに存在します。 電話番号は、これらの用語のいずれかがクエリに含まれている場合に返されます。
新しいアナライザーを使用して再構築する
現在のインデックスを削除します。
### Delete the index DELETE {{baseUrl}}/indexes/phone-numbers-index?api-version=2024-07-01 HTTP/1.1 api-key: {{apiKey}}新しいアナライザーを使用してインデックスを再作成します。 このインデックス スキーマにより、カスタム アナライザーの定義が追加され、電話番号フィールドにカスタム アナライザーの割り当てが追加されます。
### Create a new index POST {{baseUrl}}/indexes?api-version=2024-07-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "name": "phone-numbers-index-2", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "searchable": true, "filterable": false, "facetable": false, "sortable": true }, { "name": "phone_number", "type": "Edm.String", "sortable": false, "searchable": true, "filterable": false, "facetable": false, "analyzer": "phone_analyzer" } ], "analyzers": [ { "@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer", "name": "phone_analyzer", "tokenizer": "keyword_v2", "tokenFilters": [ "custom_ngram_filter" ], "charFilters": [ "phone_char_mapping" ] } ], "charFilters": [ { "@odata.type": "#Microsoft.Azure.Search.MappingCharFilter", "name": "phone_char_mapping", "mappings": [ "-=>", "(=>", ")=>", "+=>", ".=>", "\\u0020=>" ] } ], "tokenFilters": [ { "@odata.type": "#Microsoft.Azure.Search.NGramTokenFilterV2", "name": "custom_ngram_filter", "minGram": 3, "maxGram": 20 } ] }
カスタム アナライザーをテストする
インデックスを再作成したら、次の要求を使用して、アナライザーをテストすることができます。
POST {{baseUrl}}/indexes/tutorial-first-analyzer/analyze?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"text": "+1 (321) 555-0199",
"analyzer": "phone_analyzer"
}
これで、電話番号から生成されたトークンのコレクションが表示されるはずです。
{
"tokens": [
{
"token": "132",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
{
"token": "1321",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
{
"token": "13215",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
...
...
...
]
}
擬陽性が処理されるようにカスタム アナライザーを修正する
カスタム アナライザーを使用して、インデックスに対していくつかのサンプル クエリを実行してみると、再現率が向上して、一致するすべての電話番号が返されるようになったことに気付くでしょう。 ただし、n-gram トークン フィルターが原因で、ある程度の擬陽性の結果も返されます。 これは、n-gram トークン フィルターではよくある副作用です。
擬陽性を避けるために、ここでは、クエリ用のアナライザーを別途作成します。 このアナライザーは、custom_ngram_filter が省略される点を除いて、前のアナライザーと同じです。
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer_search",
"tokenizer": "custom_tokenizer_phone",
"tokenFilters": [],
"charFilters": [
"phone_char_mapping"
]
}
インデックスの定義では、indexAnalyzer と searchAnalyzer の両方を指定することになります。
{
"name": "phone_number",
"type": "Edm.String",
"sortable": false,
"searchable": true,
"filterable": false,
"facetable": false,
"indexAnalyzer": "phone_analyzer",
"searchAnalyzer": "phone_analyzer_search"
}
このように変更すれば準備は完了です。 次の手順を実行します。
インデックスを削除します。
新しいカスタム アナライザー (
phone_analyzer-search) を追加し、そのアナライザーをphone-numberフィールドのsearchAnalyzerプロパティに割り当てた後、インデックスを再作成します。モデルを再度読み込みます。
クエリを再テストして、検索が期待どおりに動作することを確認します。 サンプル ファイルを使用している場合、この手順により、
phone-number-index-3という名前の 3 番目のインデックスが作成されます。
別のアプローチ
前のセクションで説明したアナライザーは、検索の柔軟性を最大限に高めるように設計されています。 しかしその代償として、重要ではない可能性のある語句が多数インデックスに格納されています。
次の例は、トークン化においては効率的だが、欠点もある代替アナライザーを示しています。
14255550100 を入力した場合、アナライザーでは電話番号を論理的にチャンクすることはできません。 たとえば、国番号 (1) と市外局番 (425) を分離できません。 ユーザーが国番号を含めずに検索した場合、この不一致が原因で、電話番号が返されない可能性があります。
"analyzers": [
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer_shingles",
"tokenizer": "custom_tokenizer_phone",
"tokenFilters": [
"custom_shingle_filter"
]
}
],
"tokenizers": [
{
"@odata.type": "#Microsoft.Azure.Search.StandardTokenizerV2",
"name": "custom_tokenizer_phone",
"maxTokenLength": 4
}
],
"tokenFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.ShingleTokenFilter",
"name": "custom_shingle_filter",
"minShingleSize": 2,
"maxShingleSize": 6,
"tokenSeparator": ""
}
]
次の例を見るとわかるように、電話番号は、ユーザーが一般に検索するであろうチャンクに分割されます。
| input | 出力 |
|---|---|
(321) 555-0199 |
[321, 555, 0199, 321555, 5550199, 3215550199] |
要件によっては、これが問題へのより効率的なアプローチとなる可能性があります。
重要なポイント
このチュートリアルでは、カスタム アナライザーを作成してテストするプロセスを紹介しました。 インデックスを作成してデータのインデックスを作成し、そのインデックスに対してクエリを実行して、返される検索結果を確認しました。 そこから Analyze API を使用して、実行中の字句解析プロセスを見てきました。
このチュートリアルで定義したアナライザーは、電話番号を検索するための簡単なソリューションとなっていますが、同じプロセスを使用すれば、同様の特性を持つあらゆるシナリオを対象としたカスタム アナライザーを構築することができます。
リソースをクリーンアップする
所有するサブスクリプションを使用している場合は、プロジェクトの終了時に、不要になったリソースを削除することをお勧めします。 リソースを実行したままにすると、お金がかかる場合があります。 リソースは個別に削除することも、リソース グループを削除してリソースのセット全体を削除することもできます。
ポータルの左側のナビゲーション ウィンドウにある [すべてのリソース] または [リソース グループ] リンクを使って、リソースを検索および管理できます。
次のステップ
カスタム アナライザーの作成方法がわかったら、高度な検索環境を構築するために用意されているさまざまなフィルター、トークナイザー、アナライザーを見てみましょう。