NFS Azure ファイル共有のパフォーマンスを向上させる
この記事では、ネットワーク ファイル システム (NFS) の Azure ファイル共有のパフォーマンスを向上させる方法について説明します。
適用対象
| ファイル共有の種類 | SMB | NFS |
|---|---|---|
| Standard ファイル共有 (GPv2)、LRS/ZRS | ||
| Standard ファイル共有 (GPv2)、GRS/GZRS | ||
| Premium ファイル共有 (FileStorage)、LRS/ZRS |
先行読み取りサイズを増やして読み取りスループットを向上させる
Linux の read_ahead_kb カーネル パラメーターは、シーケンシャル読み取り操作中に "先行読み取り" またはプリフェッチする必要があるデータの量を表します。 Linux カーネル バージョン 5.4 より前では、先行読み取り値が、マウントされたファイル システムの rsize の 15 倍 (読み取りバッファー サイズのクライアント側マウント オプション) に相当するように設定されます。 これにより、先行読み取り値が十分に高く設定され、ほとんどの場合にクライアントのシーケンシャル読み取りスループットが向上します。
ただし、Linux カーネル バージョン 5.4 以降の Linux NFS クライアントでは、既定の read_ahead_kb 値である 128 KiB を使います。 このような小さな値を使うと、大きなファイルでは読み取りスループットの量が減る場合があります。 より大きな先行読み取り値を含む Linux リリースから 128 KiB の既定値を含む Linux リリースにアップグレードするお客様は、シーケンシャル読み取りパフォーマンスの低下が発生する場合があります。
Linux カーネル 5.4 以降については、パフォーマンス向上のために、read_ahead_kb を常に 15 MiB に設定しておくことをお勧めします。
この値を変更するには、Linux カーネル デバイス マネージャーである udev にルールを追加して、先行読み取りサイズを設定します。 次の手順のようにします。
テキスト エディターで、次のテキストを入力し、保存して、/etc/udev/rules.d/99-nfs.rules ファイルを作成します。
SUBSYSTEM=="bdi" \ , ACTION=="add" \ , PROGRAM="/usr/bin/awk -v bdi=$kernel 'BEGIN{ret=1} {if ($4 == bdi) {ret=0}} END{exit ret}' /proc/fs/nfsfs/volumes" \ , ATTR{read_ahead_kb}="15360"コンソールで、udevadm コマンドをスーパーユーザーとして実行し、ルール ファイルとその他のデータベースを再読み込みして、udev ルールを適用します。 udev で新しいファイルが認識されるために必要なのは、このコマンドを 1 回実行することのみです。
sudo udevadm control --reload
Nconnect
Nconnect は、クライアント側の Linux マウント オプションです。このオプションでは、ユーザーがクライアントと NFSv4.1 用の Azure Premium ファイル共有サービスの間でより多くの伝送制御プロトコル (TCP) 接続を使用できるようになることで、パフォーマンスが大幅に向上します。
nconnect の利点
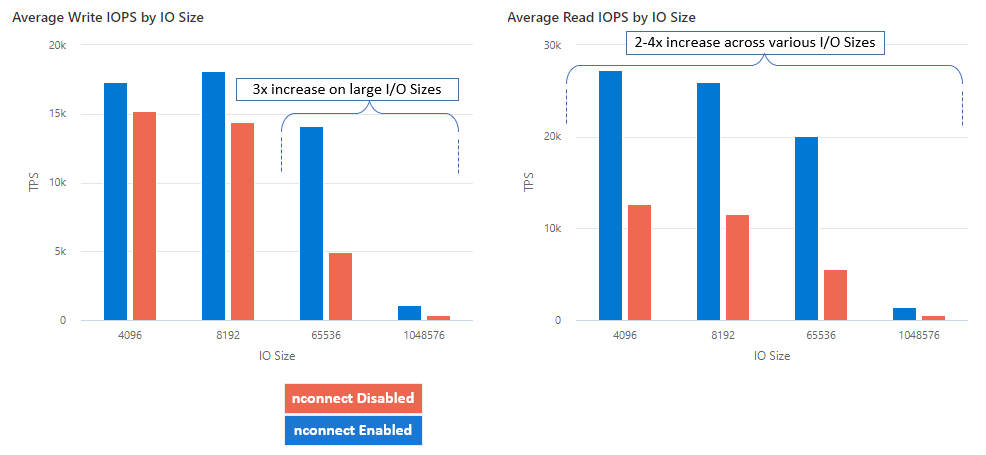
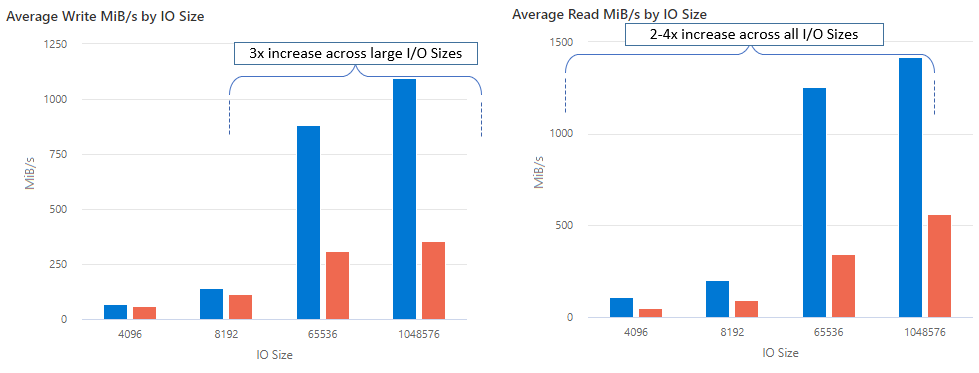
nconnect を使用すると、より少ないクライアント マシンを使用して大規模にパフォーマンスを向上させ、総保有コスト (TCO) を削減できます。 Nconnect は、単一または複数のクライアントを使用して、1 つまたは複数の NIC で複数の TCP チャネルを使用することで、パフォーマンスを向上させます。 nconnect を使用しない場合、Premium Azure ファイル共有の最大プロビジョニング サイズによって提供される帯域幅スケール制限 (10 GiB/秒) を実現するには、約 20 台のクライアント マシンが必要です。 nconnect を使用すると、クライアントを 6 から 7 個のみ使用してこれらの制限を達成できると同時に、コンピューティング コストを 70% 近く削減しながら、1 秒あたりの I/O 操作回数 (IOPS) とスループットを大幅に向上させることができます。 次のテーブルを参照してください。
| メトリック (操作) | I/O サイズ | パフォーマンス改善 |
|---|---|---|
| IOPS (書き込み) | 64K、1024K | 3x |
| IOPS (読み取り) | すべての I/O サイズ | 2 - 4 倍 |
| スループット (書き込み) | 64K、1024K | 3x |
| スループット (読み取り) | すべての I/O サイズ | 2 - 4 倍 |
必須コンポーネント
- 最新の Linux ディストリビューションでは、
nconnectが完全にサポートされています。 古い Linux ディストリビューションの場合は、Linux カーネルのバージョンが 5.3 以降であることを確認してください。 - マウントごとの構成は、プライベート エンドポイント経由でストレージ アカウントごとに 1 つのファイル共有が使用される場合にのみサポートされます。
nconnect のパフォーマンスへの影響
Linux クライアント上の NFS Azure ファイル共有で nconnect マウント オプションを大規模に使用すると、次のパフォーマンスの結果が得られます。 これらの結果の達成方法の詳細については、「パフォーマンス テストの構成」を参照してください。
nconnect に関する推奨事項
nconnect から最適な結果を得るには、これらの推奨事項に従います。
nconnect=4 を設定します
Azure Files では nconnect を最大設定である 16 に設定することがサポートされていますが、最適な設定である nconnect=4 を使用してマウント オプションを構成することをお勧めします。 現在、nconnect の Azure Files 実装では、4 つを超えるチャネルの利益はありません。 実際、1 つのクライアントから 1 つの Azure ファイル共有に対してチャネルが 4 つを超えると、TCP ネットワークの飽和が原因でパフォーマンスに悪影響を及ぼす可能性があります。
仮想マシンのサイズを慎重に設定する
ワークロードの要件に応じて、予想されるネットワーク帯域幅によって制限されないように、クライアント仮想マシン (VM) のサイズを正しく設定することが重要です。 予想されるネットワーク スループットを実現するために複数の NIC が必要になることはありません。 Azure Files で汎用 VM を使用するのが一般的ですが、ワークロードのニーズとリージョンの可用性に応じて、さまざまな種類の VM を使用できます。 詳しくは、Azure VM セレクターに関する記事をご覧ください。
キューの深さを 64 以下に保つ
キューの深さは、ストレージ リソースがサービスを提供できる未処理の I/O 要求の数です。 それ以上のパフォーマンス向上は見込まれないため、最適なキューの深さを 64 を超えて設定することはお勧めしません。 詳細については、「キューの深さ」を参照してください。
Nconnect のマウントごとの構成
ワークロードで、1 つのクライアントとは異なる nconnect 設定を持つ 1 つ以上のストレージ アカウントがある複数の共有をマウントする必要がある場合、パブリック エンドポイント経由でマウントするときにこれらの設定が保持されることを保証することはできません。 マウントごとの構成は、シナリオ 1 で説明されているように、プライベート エンドポイント経由でストレージ アカウントごとに 1 つの Azure ファイル共有が使用される場合にのみサポートされます。
シナリオ 1: 複数のストレージ アカウントを持つプライベート エンドポイントを介した nconnect のマウントごとの構成 (サポート対象)
- StorageAccount.file.core.windows.net = 10.10.10.10
- StorageAccount2.file.core.windows.net = 10.10.10.11
Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare1 nconnect=4Mount StorageAccount2.file.core.windows.net:/StorageAccount2/FileShare1
シナリオ 2: パブリック エンドポイントを介した nconnect のマウントごとの構成 (サポート対象外)
- StorageAccount.file.core.windows.net = 52.239.238.8
- StorageAccount2.file.core.windows.net = 52.239.238.7
Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare1 nconnect=4Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare2Mount StorageAccount2.file.core.windows.net:/StorageAccount2/FileShare1
Note
ストレージ アカウントが別の IP アドレスに解決された場合でも、パブリック エンドポイントは静的アドレスではないので、そのアドレスが保持されることを保証することはできません。
シナリオ 3: 1 つのストレージ アカウントで複数の共有を持つプライベート エンドポイントを介した nconnect のマウントごとの構成 (サポート対象外)
- StorageAccount.file.core.windows.net = 10.10.10.10
Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare1 nconnect=4Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare2Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare3
パフォーマンス テストの構成
この記事で概説されている結果を達成および測定するために、次のリソースとベンチマーク ツールを使用しました。
- 単一クライアント: 単一 NIC を使用した Azure VM (DSv4-Series)
- OS: Linux (Ubuntu 20.40)
- NFS ストレージ: Azure Files Premium ファイル共有 (30 TiB をプロビジョニング済み、
nconnect=4の設定)
| [サイズ] | vCPU | [メモリ] | 一時ストレージ (SSD) | 最大データ ディスク数 | 最大 NIC 数 | 予想されるネットワーク帯域幅 |
|---|---|---|---|---|---|---|
| Standard_D16_v4 | 16 | 64 GiB | リモート ストレージのみ | 32 | 8 | 12,500 Mbps |
ベンチマーク ツールとテスト
ベンチマークとストレス/ハードウェア検証の両方に使用される、無償かつオープンソースのディスク I/O ツールである Flexible I/O Tester (FIO) を使用しました。 FIO をインストールするには、FIO README ファイルの「Binary Packages」セクションに従って、任意のプラットフォームにインストールします。
これらのテストはランダムな I/O アクセス パターンに焦点を当てていますが、シーケンシャル I/O を使用するときも同様の結果が得られます。
高い IOPS: 100% 読み取り
I/O サイズ 4k - ランダム読み取り - キューの深さ 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=4k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
I/O サイズ 8k - ランダム読み取り - キューの深さ 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=8k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
高スループット: 100% 読み取り
I/O サイズ 64k - ランダム読み取り - キューの深さ 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=64k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
I/O サイズ 1024k - 100% ランダム読み取り - キューの深さ 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=1024k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
高い IOPS: 100% 書き込み
I/O サイズ 4k - 100% ランダム書き込み - キューの深さ 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=4k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
I/O サイズ 8k - 100% ランダム書き込み - キューの深さ 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=8k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
高スループット: 100% 書き込み
I/O サイズ 64k - 100% ランダム書き込み - キューの深さ 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=64k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
I/O サイズ 1024k - 100% ランダム書き込み - キューの深さ 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=1024k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
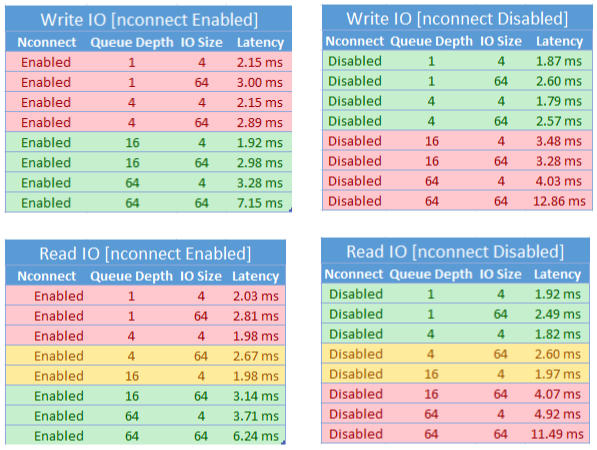
nconnect のパフォーマンスに関する考慮事項
nconnect マウント オプションを使用する場合は、次の特性を持つワークロードを厳密に評価する必要があります。
- シングル スレッドであるか、低いキューの深さ (16 未満) を使用する、待機時間の影響を受けやすい書き込みワークロード
- シングル スレッドであるか、小さい I/O サイズと組み合わせて低いキューの深さを使用する、待機時間の影響を受けやすい読み取りワークロード
すべてのワークロードで、高スケールの IOPS やスループット パフォーマンスが必要なわけではありません。 小規模なワークロードの場合、nconnect は意味をなさない可能性があります。 次の表を使って、nconnect が自分のワークロードに役立つかどうかを判断します。 緑色で強調表示されているシナリオは推奨されていますが、赤で強調表示されているシナリオは推奨されていません。 黄色で強調表示されているのは中立的なシナリオです。
関連項目
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示