Repeatable Read Isolation Level
In my last two posts, I showed how queries running at read committed isolation level may generate unexpected results in the presence of concurrent updates. Many but not all of these results can be avoided by running at repeatable read isolation level. In this post, I'll explore how concurrent updates may affect queries running at repeatable read.
Unlike a read committed scan, a repeatable read scan retains locks on every row it touches until the end of the transaction. Even rows that do not qualify for the query result remain locked. These locks ensure that the rows touched by the query cannot be updated or deleted by a concurrent session until the current transaction completes (whether it is committed or rolled back). These locks do not protect rows that have not yet been scanned from updates or deletes and do not prevent the insertion of new rows amid the rows that are already locked. The following graphic illustrates this point:
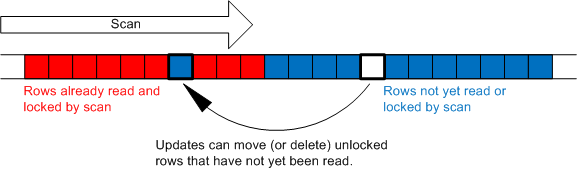
Note that the capability to insert new "phantom" rows between locked rows that have already been scanned is the principle difference between the repeatable read and serializable isolation levels. A serializable scan acquires a key range lock which prevents the insertion of any new rows anywhere within the range (as well as the update or deletion of any existing rows within the range).
In the remainder of this post, I'll give a couple of examples of how we can get unexpected results even while running queries at repeatable read isolation level. These examples are similar to the ones from my previous two posts.
Row Movement
First, let's see how we can move a row and cause a repeatable read scan to miss it. As with all of the other example in this series of posts, we'll need two sessions. Begin by creating this simple table:
create table t (a int primary key, b int)
insert t values (1, 1)
insert t values (2, 2)
insert t values (3, 3)
Next, in session 1 lock the second row:
begin tran
update t set b = 2 where a = 2
Now, in session 2 run a repeatable read scan of the table:
select * from t with (repeatableread)
This scan reads the first row then blocks waiting for session 1 to release the lock it holds on the second row. While the scan is blocked, in session 1 let's move the third row to the beginning of the table before committing the transaction and releasing the exclusive lock blocking session 2:
update t set a = 0 where a = 3
commit tran
As we expect, session 2 completely misses the third row and returns just two rows:
a b c
----------- ----------- -----------
1 1 1
2 2 2
Note that if we change the experiment so that session 1 tries to touch the first row in the table, it will cause a deadlock with session 2 which holds a lock on this row.
Phantom Rows
Let's also take a look at how phantom rows can cause unexpected results. This experiment is similar to the nested loops join experiment from my previous post. Begin by creating two tables:
create table t1 (a1 int primary key, b1 int)
insert t1 values (1, 9)
insert t1 values (2, 9)create table t2 (a2 int primary key, b2 int)
Now, in session 1 lock the second row of table t1:
begin tran
update t1 set a1 = 2 where a1 = 2
Next, in session 2 run the following outer join at repeatable read isolation level:
set transaction isolation level repeatable read
select * from t1 left outer join t2 on b1 = a2
The query plan for this join uses a nested loops join:
|--Nested Loops(Left Outer Join, WHERE:([t1].[b1]=[t2].[a2]))
|--Clustered Index Scan(OBJECT:([t1].[PK__t1]))
|--Clustered Index Scan(OBJECT:([t2].[PK__t2]))
This plan scans the first row from t1, tries to join it with t2, finds there are no matching rows, and outputs a null extended row. It then blocks waiting for session 1 to release the lock on the second row of t1. Finally, in session 1, insert a new row into t2 and release the lock:
insert t2 values (9, 0)
commit tran
Here is the output from the outer join:
a1 b1 a2 b2
----------- ----------- ----------- -----------
1 9 NULL NULL
2 9 9 0
Notice that we have both a null extended and a joined row for the same join key!
Summary
As I pointed out at the conclusion of my previous post, I want to emphasize that the above results are not incorrect but rather are a side effect of running at a reduced isolation level. SQL Server guarantees that the committed data is consistent at all times.
CLARIFICATION 8/26/2008: The above examples work as I originally described if they are executed in tempdb. However, the SELECT statements in session 2 may not block as described if the examples are executed in other databases due to an optimization where SQL Server avoids acquiring read committed locks when it knows that no data has changed on a page. If you encounter this problem, either run these examples in tempdb or change the UPDATE statements in session 1 so that they actually change the data in the updated row. For instance, for the first example try "update t set b = 12 where a = 2".
Comments
Anonymous
May 15, 2007
The comment has been removedAnonymous
April 11, 2010
Great post, very illustrative. You said that : "These locks do not protect rows that have not yet been scanned from updates or deletes and do not prevent the insertion of new rows amid the rows that are already locked." does this apply to the Serializable level as well? I mean if transaction 1 that runs in Serializable level hasn't yet scanned a row,can another transaction 2 modify that row, or insert a row in a range that has yet to be scanned by T1? Or does Serializable locks rows ahead? ThanksAnonymous
April 22, 2010
A serializable scan acquires key-range locks as it goes. Thus, while rows cannot be inserted into a region of the index that has already been scanned, rows can be inserted, updated, or deleted in the range that has not yet been scanned. You may find the following Books Online page helpful: http://msdn.microsoft.com/en-us/library/ms191272.aspx HTH CraigAnonymous
May 28, 2010
The comment has been removedAnonymous
June 03, 2010
The statement that you reference from Books Online is slightly confusing. Basically, singleton fetches (i.e., equality lookups on unique indexes) need only take key locks while all other seeks and scans take key-range locks. This is true for select, delete, and update statements. The update statement in your question above uses a range scan due to the BETWEEN clause and, thus, uses key-range locks with the result that concurrent inserts in the range between 'A' and 'C' will block. You may find the following post helpful: blogs.msdn.com/.../range-locks.aspx. HTH CraigAnonymous
September 21, 2010
Craig, you mentioned that "singleton fetches (i.e., equality lookups on unique indexes) need only take key locks while all other seeks and scans take key-range locks". Is this true for the serializable isolation level only, or all isolation levels? I'm seeing some unexpected key-range locks in a read committed transaction, which is why I ask. And we're not doing any cascading updates/deletes in that transaction. Thanks, Sam BendayanAnonymous
September 22, 2010
My statement above refers specifically to serializable isolation. However, there are some scenarios where SQL Server will take serializable key-range locks even when a statement or transaction is run at a lower isolation level. These scenarios include cascading actions (which I gather does not apply in your case), materialized view maintenance, and query notifications. HTH CraigAnonymous
September 28, 2010
Hi again.Do the isolation levels affect the INSERT, UPDATE, and DELETE behaviour or are they only valid for SELECTS? thanksAnonymous
September 30, 2010
The transaction isolation level will not affect the insert, update, or delete operator itself as these operators always take X locks and hold them for the duration of the transaction. However, the seek and/or scan operators below an insert, update, or delete operator are affected by the transaction isolation level. HTH CraigAnonymous
September 30, 2010
When you say the "seek and/or scan operators BELOW an insert, update, or delete operator" you are reffering to the "select * from t2 where t2.a = t1.b " part of the "update t1 set t1.b = t1.b where exists (select * from t2 where t2.a = t1.b)" query ? which appears at another one of your great blog posts<a href="blogs.msdn.com/.../read-committed-and-updates.aspx">Read Committed and Updates</a>Anonymous
October 06, 2010
Actually the plan for the query you mention includes scans of both t1 and t2. Both of these scans are affected by the isolation level. Only the update itself is not affected by the isolation level. HTH CraigAnonymous
October 27, 2010
Hey, Nice post. What do you mean by "Even rows that do not qualify for the query result remain locked"? And also, could you show an example of Phantom rows using an insert statement? Thanks! G.Anonymous
November 04, 2010
My statement "even rows that do not qualify for the query result remain locked" refers to rows that are returned by a scan but are not retured by the query. For example, if a query includes a join, rows that are returned by a scan but are not returned by the join still remain locked. I'm not sure I understand your question regarding phantom rows. In the "Phantom Rows" section of the post, the example shows a row (9,0) inserted into table t2. This row is a phantom for the outer join run in session 2. The join initially does not see the row but later does see it. HTH CraigAnonymous
November 04, 2010
"if a query includes a join, rows that are returned by a scan but are not returned by the join still remain locked" you mean using page level locking which locks also rows not qualified but live in the same page as a qualified row? what is the difference between the scan and a query? aren't only the qualified rows touched?Anonymous
November 08, 2010
Actually, my statement is independent of the lock granularity (row, page, etc.). If a scan returns a row to the query processor, the storage engine will acquire and hold a lock to ensure that the row is not updated or deleted until the end of the current transaction. This lock (which could be a row, page, or even a table lock) will be held even if the row is subsequently "rejected" by the query processor (e.g., due to a filter or join operator). HTH CraigAnonymous
November 08, 2010
Great explanation! you should write a book!Anonymous
November 09, 2010
Hi Craig, It's very nice article on Repeatable Read Isolation Level.I have little confusion in this.i tried your example insted of update t set a = 0 where a = 3 commit tran i tried update t set b = 0 where a = 3 commit tran at that time it was giving 3 rows. why is it show will you please clear my doubt ? Is it holds lock on table on the besis of primary/unique key constraint? GJOAnonymous
November 09, 2010
Table t has an index on column a only. The repeatable read scan of t in session 2 uses this index. Updating column a of the third row from 3 to 0, moves the row from the end of the index to the beginning of the index. Since the scan is already underway, it misses this row and returns only two rows. Updating column b does not move the row since there is no index on this column. Since the row does not move, the scan finds it and returns all three rows. HTH CraigAnonymous
November 10, 2010
thanks CraigAnonymous
April 16, 2011
Hi Craig, I have a question based on your following answer at 04-23-2010 5:39 AM : "A serializable scan acquires key-range locks as it goes. Thus, while rows cannot be inserted into a region of the index that has already been scanned, rows can be inserted, updated, or deleted in the range that has not yet been scanned." Hasn't the query optimizer decided before the query is run which rows to lock so they are locked 'ahead' (which would also not trigger lock escalation) and thus not having to acquire key-range locks as it 'goes'? Are other isolation levels eg RR acquiring row locks as they go? what is the query optimizers' role then? thank you againAnonymous
September 30, 2011
Great Article!Anonymous
January 14, 2014
Thanks for this, very informative. I stumbled upon this method whilst looking at some legacy code. We have experienced missing values (potential phantom rows. also Deadlocks Is it best to just perform data reader and data adapter writes to enable concurrency behaviour?Anonymous
January 17, 2014
@Liam. My apologies, but I'm not sure I understand your question. With respect to concurrency, the behavior of SQL Server depends only on the isolation levels you use and does not depend on the type of client (though the client may determine the isolation level). The only guaranteed way to avoid the anomaly that I describe above is to run at the serializable isolation level. @nik_ath. My apologies for never answering your question. I don't know whether you are still reading, but just in case, the answer is that the query optimizer has no role in deciding which locks to take (except to adjust isolation levels and/or lock duration for some scenarios). Based on the isolation level and lock hints, the storage engine acquires locks as rows are retrieved. Nothing is locked ahead of time though a page or table lock may lock rows that have not been accessed as a side effect. The storage engine also determines when to perform lock escalation based on how many and which other locks have already been acquired. HTH CraigAnonymous
February 04, 2014
Thank you so much for this post! I could not believe that writers actually block readers, and readers don't get a read-consistent picture of the data as of the time they started reading, in any enterprise level database engine in 2014 (given that the enterprise db engine world has had this tech since at least as early as 1988, if not earlier), so I tried some of these experiments myself. Which proved you right, to my horror and amazement. I further discovered that "isolation levels" (like "nolock" or "readuncommitted") that allow writers not to block readers cause readers to retrieve uncommitted data! Which might yet be rolled back! I guess there are some special use cases where that's desirable, but that seems terribly dangerous to me, in general. Anyway, I still just couldn't quite believe it, so I thought maybe it had to do with the default database settings (which are notorious, even among long standing enterprise db engines, for producing various ridiculous behaviours), so I went looking and uncovered alter database set read_committed_snapshot on ..which appears to cause the database to behave a lot more like I would expect it to. Although I would be very interested in seeing what holes you manage to poke in it?