テストの実行
PERIL を使用してプロジェクトのエクスポージャとリスクを分析する
Dr. James McCaffrey
コードは MSDN コード ギャラリーからダウンロードできます。
オンラインでのコードの参照
目次
メタリスク
リスクの識別
リスク分析
まとめ
すべてのソフトウェア プロジェクトはリスクに直面しています。リスクはイベントです。発生することもあれば、発生しないこともあり、発生した場合は何らかの損失を与えます。リスクとソフトウェア テストの関係は単純です。通常はソフトウェア システムを徹底的にテストすることが難しいので、リスク分析を行い、最も大きな損失を与える可能性のある問題を明らかにします。この情報を利用して、テスト作業に優先順位を付けることができます。今月のコラムでは、ソフトウェア プロジェクトに関連するリスクを識別および分析するために使用できる実用的な手法をご紹介します。では、始めましょう。
何らかの ASP.NET の Web ベース アプリケーションを開発しているという架空の状況を想像してください。図 1 は、ソフトウェアのリスク分析に関連する重要な考え方と問題の一部を示しています。リスク分析のプロセス全体には、リスクの識別、各リスクが発生する確率の見積もり、各リスクに関連する損失の特定、尤度と損失情報を組み合わせたリスク エクスポージャと呼ばれる値の算出が含まれます。
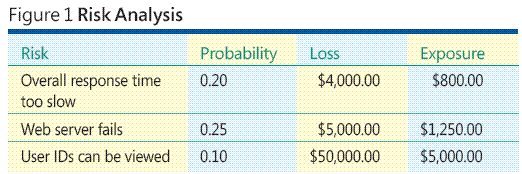
図 1 のサンプル データによれば、"User IDs can be viewed" (ユーザー ID が表示可能) のエクスポージャが最も高くなっています。他の条件が同じであるとした場合、このリスクのテストを最優先にして、リスクが現実のものにならないようにする必要があります。しかし、リスクを識別するには、どうすればよいでしょうか。リスクの確率と損失を見積もるには、どうすればよいでしょうか。リスクの確率と損失を見積もることができなくても、リスク分析を実行できるのでしょうか。
リスク分析の用語を正式に標準化する取り組みが続けられていますが、実際には各問題領域でそれぞれ固有の用語が使用されることが多いようです。ここでは、"リスク分析" という用語を、リスクの確率 (尤度) にリスクの損失を乗算してリスク エクスポージャを計算する、または、ソフトウェア プロジェクトのリスクを識別、分析、および管理するプロセス全体という意味で使用します。
リスク分析はソフトウェア開発のきわめて重要な部分ですが、私の経験から言って、ソフトウェア テスト コミュニティではリスク分析手法の多くがあまり知られていないようです。Web を検索すると、ソフトウェアのリスク分析に関する参照が数万件も見つかります。ただし、こうした参照のほとんどは、リスク分析の概要に関する説明が示され、実用的な手法が紹介されていないか、または、特定のリスク分析手法が 1 つだけ示され、リスク分析の枠組み全体に手法を応用する方法が説明されていないかのどちらかです。ここでは、リスク分析の概要と、実際のソフトウェア開発環境ですぐに使用できる便利な手法の両方をご紹介します。
以降のセクションでは、最初にすべてのソフトウェア プロジェクトに共通する 2 つのメタリスクについて説明します。次に、ソフトウェア プロジェクトに関連する固有のリスクを識別する 3 つの方法と、リスクを分析するための 3 つの方法を示します。具体的には、PERIL (Project Exposure using Ranked Impact and Likelihood (優先順位を付けた影響と尤度を使用したプロジェクトのエクスポージャ)) というユニークな新しいリスク分析手法をご紹介します。この手法は、特にソフトウェア開発環境で役に立ちます。最後に、リスク管理について簡単に説明します。ここで紹介する手法を読者の皆さんのソフトウェアのテスト、開発、および管理ツール キットに加えていただき、非常に役に立つと評価していただければさいわいです。
メタリスク
ソフトウェア プロジェクトのリスク分析には 2 つの特殊な種類があり、筆者はそれらを "時間のメタリスク分析" と "コストのメタリスク分析" と呼んでいます。普通のプロジェクト管理では、"プロジェクト管理の 3 つの制約"、"プロジェクト管理のトライアングル" などと呼ばれる概念を定義します。これは、ほとんどのプロジェクトにはコスト、スケジュール、およびスコープという 3 つの制限要素があるという考え方です。"コスト" はプロジェクトにかけられる資金、"スケジュール" はプロジェクトの完了までの期間、そして "スコープ" はプロジェクトで要求される一連の機能とその品質です。
プロジェクトの 3 つの制約には、さまざまな別名があります。たとえば、コストは予算や資金とも言い換えられます。スケジュールは、一般的に時間や期間と呼ばれます。スコープは、機能、品質、さらには機能/品質と表されることもあります。この最後の機能/品質と呼ばれる制約は、2 つの異なる制約と見なすことができる点に注意してください (また、実際にそう見なされることがよくあります)。
重要なことは、制約のいずれか 1 つが変わると、残りの 2 つの制約の一方または両方とも変わる可能性があるということです。たとえば、ソフトウェア アプリケーションを開発していて、突然プロジェクトを当初の予定よりも短い期間で完了させる必要が出てくると、もっと資金を費やす (追加リソースを購入する、プロジェクトの一部を外部委託するなど)、機能を減らす、または品質を落とすことになるでしょう。また、プロジェクトの予算が削減されたら、プロジェクトが完了するまでの期間を延ばす、機能を削る、またはプロジェクトの品質を落とすことになるでしょう。ソフトウェア テストの目的はシステムの品質を改善することなので、プロジェクト管理のトライアングル パラダイムを使用した場合、ソフトウェア プロジェクトの最高レベルのリスクは、プロジェクトが予定どおりに終わらないことと、プロジェクトが予算を超過することの 2 つになります。
ソフトウェア プロジェクトのスケジュールとコストのリスク全体を見積もる比較的簡単で効率的な方法があります。それでは、時間またはスケジュールのメタリスクを見てみましょう (予算またはコストのリスクもまったく同じ方法で分析できます)。大まかなメタリスク分析の最初の手順として、プロジェクト全体を小さな、管理しやすい単位のアクティビティに分割します。
たとえば、小さな Web アプリケーション プロジェクトに取り組んでいて、プロジェクトを 30 営業日以内に完了させる必要があるとします。プロジェクトに関連するすべてのアクティビティの一覧表を作成することから、メタリスク分析を開始します。ここでは、図 2 に示した作業分解図 (WBS) と呼ばれるものを作成することが、最も一般的なアプローチです。プロジェクト全体から成る最上層レベルのタスクを作成します。次に、そのタスクをいくつか (通常は 3 ~ 7 つぐらい) の小さなサブタスクに分割します。各サブタスクをさらに小さなサブタスクに分解し、環境に適した粒度になるまでこの作業を繰り返します。
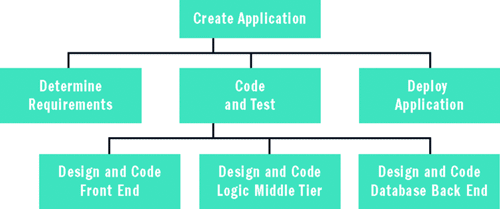
図 2 作業分解図
最下層レベルのリーフ ノードのタスクはワーク パッケージと呼ばれることがあります。タスクの分解方法と WBS の粒度は、さまざまな要素によって決まります。たとえば、アジャイル開発環境では、単純な 2 階層の作業分解図で十分だと判断するかもしれません。また、従来のソフトウェア開発ライフサイクルの方法論を使用した、非常に大きな、複雑なソフトウェア プロジェクトに取り組んでいる場合は、ワーク パッケージの数が数万になることもあります。
小規模な WBS は手動でも作成できますし、Microsoft Office Excel などの一般的な生産性向上ツールや Microsoft Office Project などの高度なツールを使用しても作成できます。WBS には、順序、時間、およびコストに関する情報は含まれません。つまり、WBS はやるべきことを示しているだけで、その順序や、各タスクにかかる時間およびコストを示しているわけではありません。作業分解図を作成したら、次は、ワーク パッケージを使用して、プレシデンス ダイアグラムと呼ばれるものを作成します。

図 3 プレシデンス ダイアグラム
プレシデンス ダイアグラムでは、順序情報が追加されます。図 3 のダイアグラムは、Requirements (要件) のタスクが終了したら、Database Back End (データベースのバック エンド) のタスクを開始し、それが終了したら Middle-Tier (中間層) のタスクと Front-End (フロント エンド) のタスクの両方を開始できることを示しています。この最後の 2 つのタスクは、プレシデンス ダイアグラムによると、平行して実行できます。最後に、Middle-Tier (中間層) のタスクと Front-End (フロント エンド) のタスクの両方が終了したら、Deploy Application (アプリケーションの展開) タスクを開始できます。
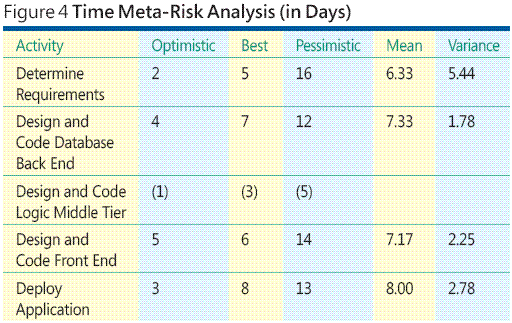
順序情報を持つプレシデンス ダイアグラムを作成したら、時間のメタリスク分析の次の手順として、各ワーク パッケージの所要時間を見積もります。各時間を単一のデータ ポイントとして見積もることもできますが、Optimistic (楽観的)、Best (最確)、および Pessimistic (悲観的) という 3 つの見積もりを提示した方がより効果的です。
ところで、そうした見積もりはどのように算出するのでしょうか。時間とコストの見積もりの算出は、ソフトウェア プロジェクトのメタリスク分析で最も難しい部分です。アクティビティの時間とコストを見積もる方法はたくさんあります。過去の経験、知識に基づく推測、高度な数学モデルなどを使用できます。使用する手法は、個々の状況によって異なります。どの手法を使用したとしても、一連の小さなアクティビティの時間とコストを見積もる方が、1 つの大きなアクティビティの時間とコストを見積もるよりもはるかに簡単です。図 4 の表に、時間のメタリスク分析の例を示します。
通常、楽観的、最確、および悲観的という時間データの分析には、ベータ分布と呼ばれる単純な数学的分布を使用します。ベータ分布の平均は次のように計算します。
(optimistic + (4 * best-guess) + pessimistic) / 6
したがって、Deploy Application (アプリケーションの展開) タスクの場合、終了までの時間の見積もりの Mean (平均) は、次のようになります。
mean = (3 + 4*8 + 13) / 6
= 48 / 6
= 8.0 days.
ベータ分布の平均は、1、4、および 1 を重みとした加重平均であることに注意してください。そのため、ベータ分布の分散は次の式で求められます。
((pessimistic - optimistic)/6)²
したがって、Deploy Application (アプリケーションの展開) タスクの場合、Variance (分散) は次のように計算します。
variance = ((13 - 3) / 6)²
= (10/6)²
= (1.6667)²
= 2.78 days²
プロジェクト全体の標準偏差は、アクティビティの分散の和の平方根です。そのため、この例では計算式は次のようになります。
std. deviation = sqrt(5.44 + 1.78 + 2.25 + 2.78)
= sqrt(12.25)
= 3.50 days
これらの計算で、Design and Code Logic Middle-Tier (設計とコードの論理中間層) アクティビティのデータを使用していないことに注意してください。Logic Middle-Tier (論理中間層) のアクティビティは Database Back-End (データベース バック エンド) のアクティビティと平行して実行することができ、平行する両方のアクティビティが終了するまで Front-End (フロント エンド) のアクティビティを開始できないため、期間が短い Logic Middle-Tier (論理中間層) のアクティビティはプロジェクト完了までの全時間に明示的な影響を与えません。
このタイプの分析はクリティカル パス方式 (CPM) と呼ばれる、標準的なプロジェクト管理手法です。スケジュールの平均と分散のデータを計算したら、プロジェクト全体が完了するまでの期間が 30 日間を超える確率を次のように計算します。
z = (30.00 - 28.83) / 3.50 = 0.33
p(0.33) = 0.6293
p(late) = 1.0000 - 0.6293 = 0.3707
まず、z 値と呼ばれる値を計算します。この値は、プロジェクトが完了するまでの予定の時間 (この場合は 30 日) から見積もった完了までの時間 (28.83 日) を引いて、全タスクの標準偏差 (3.50 日) で除算した値に等しくなります。次に、その z 値 (0.33) を使用し、標準正規分布表から対応する p 値を求めるか、Excel の NORMSDIST 関数を使用します (0.6293)。最後に、1.0000 からその p 値を引いて、プロジェクトがスケジュールを超過する確率を求めます。
ここで片側分析を行ったのは、予定より長引くかどうかだけが心配で、短くなる分には問題がないからです。この例のデータでは、Web アプリケーションの完成まで 30 日間を超える確率は 0.3707 (およそ 40%) で、かなり危険な状況です。少し考えれば、この結果に納得できます。計画した 26 日間という開発スケジュールはプロジェクトの期限の 30 日間に非常に近く、スケジュールの分散を考慮する十分な余地がありません。
当然ながら、メタリスクの結果は入力データ (この場合は時間の見積もり) に非常に忠実です。入力した見積もりが間違っていれば、どれだけ統計分析を行っても、意味のある結果は得られません。プロジェクトが予算を超過するメタリスクの確率も、先ほど説明したスケジュールと同じ手法を使用して計算できます。プロジェクトがスケジュールを超過する確率がわかり、遅れることによる金銭的損失を見積もることができる場合は、そのメタリスクのリスク エクスポージャを計算できます。
場合によっては、ソフトウェア システムを作成する契約を結んでいて、その契約書に遅延に対する多額の違約金が明確に記載されていることがあります。たとえば、契約書に納品の遅延に対して $10,000.00 の違約金を支払うと記載されているとします。その場合のメタリスクのエクスポージャは、$10,000.00 * 0.3707 = $3,707 になります。また、遅延したソフトウェア プロジェクトのコストを見積もるのは非常に難しく、"非常に高い" ということしかわからない場合もあります。
しかし、リスク エクスポージャを計算できなくても、時間のメタリスク分析を行うことで、役立つ情報が得られます。図 4 のデータを見ると、Determine Requirements (要件の決定) タスクのスケジュールの Variance (分散) が最も大きいことがわかります。そのため、プロジェクトの早い段階でリソースを追加するだけで、タスクの分散を減らすことができ、その結果、スケジュールを超過する確率が減ります。
リスクの識別
時間とコストのメタリスクの場合は、タスクを小さなサブリスクに繰り返し分解することで、(簡単ではありませんが) ある程度順を追ってリスク イベントを特定できますが、一般的なケースのリスクの識別作業はあまり機械的ではありません。ソフトウェアの開発とテスト環境では、リスクの識別に、主に 3 つのアプローチがあります。分類法ベース、シナリオ ベース、および仕様ベースです。
分類法とは、単なる分類表のことです。次の例について考えてみましょう。飛行機で旅行に行くため、毎回旅行前に使用している一般的な覚え書きを使用するとします。覚え書きには、"身分証明書を持ったか"、"フライトは予定どおりか確認したか" などの文や質問が記載されています。
この数年、多くの人や組織がソフトウェアのリスク分類法を作成してきました。その 1 つに、ソフトウェア プロジェクトのリスク分野で著名な、先駆的な研究者である Barry Boehm 氏によって作成されたものがあります。1989 年に、Boehm 氏はソフトウェアのトップ 10 リスク分類法を定め、その一覧を 1995 に更新しました。1995 年版のソフトウェアのトップ 10 リスク分類法の一覧をここに示します。
- 人員不足
- スケジュール、予算、工程
- 市販ソフトウェア、外部コンポーネント
- 要件の不一致
- ユーザー インターフェイスの不一致
- アーキテクチャ、パフォーマンス、品質
- 要件の変更
- レガシ ソフトウェア
- 外部で実行されるタスク
- コンピュータ サイエンスの濫用
Boehm 氏のトップ 10 リスクの一覧では、すぐにリスクを識別できないことは明らかだと思います。この分類法は、皆さんのソフトウェア プロジェクトに当てはまるリスクについて検討するための出発点を提供しているだけです。たとえば、最初のリスク "人員不足" については、スタッフに関連するさまざまなリスクが考えられます。単純に、アプリケーションやシステムを作成するのに十分な数のエンジニアがいないのかもしれません。プロジェクトのスケジュールの途中で重要なエンジニアがプロジェクトから抜けてしまうのかもしれません。または、エンジニアリング スタッフにプロジェクトに必要な技術的スキルがないのかもしれません。これらはほんの一例にすぎません。
おそらく、10 番目の "コンピュータ サイエンスの濫用" を除いて、このトップ 10 リスクのカテゴリは慣れ親しんだ項目だと思います。この 10 番目は、ある程度すべてに当てはまるカテゴリで、テクニカル分析、費用便益分析、プロトタイプ作成などに関連するタスクを対象にしています。
よく使用されている別のソフトウェアのリスク分類法に、SEI (Software Engineering Institute) によって作成された一覧があります。SEI は、米国に 36 ある連邦政府が資金提供している研究開発センターの 1 つです。こうした研究センターは、公的資金を受けているにもかかわらず、製品やサービスを販売している、かなり風変わりなハイブリッド組織です。SEI のソフトウェアのリスク分類法は 1993 年に作成され、約 200 個の質問で構成されています。たとえば、1 番目の質問は、"要件は安定しているか。安定していない場合は、システムのどこ (品質、機能、スケジュール、統合、設計、テスト) に影響があるか" です。16 番目の質問は、"アルゴリズムと設計の実現性をどのように (プロトタイプ作成、モデル化、分析、シミュレーション) して判断するか" です。この分類法については、ドキュメントの付録に記載されている「SEI のリスク分類法」を参照してください。
シナリオ ベースのソフトウェアのリスクの識別では、さまざまな役割を担った場合について想像し、それらの役割に合わせてシナリオを作成して、各シナリオで問題が発生する可能性のあるものを識別します。先ほどの飛行機旅行の例では、旅行の手順を頭の中で追ってみます。たとえば、"まず、空港まで運転し、駐車します。次に、航空会社のカウンタでチェックインします" と考えたとします。このシナリオの工程では、道路工事や事故による遅れ、駐車場が空いていない、身分証明書を忘れたなど、さまざまなリスクが見えてきます。
ソフトウェア プロジェクト環境の場合、シナリオ ベースのリスクの識別に使用する一般的な役割には、ユーザー、開発者、テスト担当者、営業担当者、ソフトウェア アーキテクト、およびプロジェクト管理者があります。ユーザーのシナリオでは、"まず、アプリケーションをインストールします。次に、アプリケーションを起動します" のようになります。多くの場合、リスクの識別シナリオはテスト ケースに直接対応します。
シナリオ ベースのリスクの識別の役割は、必ずしも人間である必要はありません。ソフトウェア モジュールやサブシステムでもかまいません。たとえば、暗号化と暗号化解除を行う C# オブジェクトがあるとします。そのオブジェクトを役割として考え、"まず、何らかの入力を受け取り、自分をインスタンス化します。次に、何らかの入力を受け取り、それを暗号化メソッドに渡します" などのシナリオを作成します。分類法ベースの識別と比べて、シナリオ ベースのソフトウェアのリスクの識別はあまり研究されていません。「Risk Identification Patterns for Software Projects (ソフトウェア プロジェクトのリスクの識別パターン)」という研究論文は、この分野の概要を適切に示していて、リスクの識別に対する興味深い、理論的なパターン ベースのアプローチを提案しています。
分類法ベースとシナリオ ベースのリスクの識別方法のほかに、第 3 のアプローチとして仕様ベースの方法があります。このアプローチでは、製品またはシステムの仕様書の各機能と工程を詳しく調べ、問題が発生する可能性のあるものを識別します。飛行機旅行の例では、旅行代理店が作成した詳細な旅行計画を注意深く調べます。Web アプリケーションの仕様書の 1 つに、外部の委託業者を使用してアプリケーションのさまざまなヘルプ ファイルを作成する予定であることが記載されているとします。プロジェクトが外部に依存すると、リスクの一覧が長くなることがあります。委託業者が予定どおりに納品できないことも考えられます。委託業者の作業品質が主観的な基準に満たないことも考えられます。
リスクの識別方法には、それぞれ長所と短所があり、単一の最適な方法はありません。リスク分類法は、ソフトウェア プロジェクトのリスクを識別する工程を開始するための優れた方法です。分類法に記載されている各質問や文の検証を行うだけという意味では、多少機械的な方法から始めることができると言えます。また、分類法は、別の人に別の分類法の質問を割り当てることで、複数の人にリスクの識別工程を割り振ることができます。欠点としては、リスクの識別に分類法を使用すると、非常に時間がかかることが挙げられます。また、分類法は、その性質上、汎用的なため、ソフトウェア システム固有のリスクを発見する努力をしない限り、そうした固有のリスクを識別できません。
分類法ベースのリスクの識別と比較して、シナリオ ベースのアプローチの利点は、あまり汎用的でなく、最初から範囲が限定されることです。その一方で、シナリオ ベースのリスクの識別は科学というよりは芸術に近く、重要なシナリオを見逃してしまうことがあります。通常、仕様ベースのリスクの識別は最も汎用性がなく、最も具体的なアプローチです。しかし、仕様ベースのアプローチでは、仕様書に忠実な結果しか得られません。3 つのアプローチを組み合わせて使用することで、ソフトウェアのリスクを正確に識別できる可能性が高くなります。
リスク分析
リスク分析とは、リスク イベントの確率 (または尤度) とイベントが発生した場合の金銭的損失 (または悪影響) を組み合わせて、リスクどうしの比較と優先順位付けに使用できる値を導き出す工程です。ここでは、2 つの古いリスク分析のアプローチ (期待値の手法とカテゴリの手法) と PERIL という新しいアプローチを示します。まずは、期待値の手法について説明します。
図 5 の例をご覧ください。4 つのリスク イベントを識別したとします。それらに Risk A、Risk B、Risk C、および Risk D と名前を付けます。各リスク イベントに確率を割り当てます。確率はイベントが発生する確率を示す 0.00 (起こりえない場合を表す) ~ 1.00 (確実に起こる場合を表す) の数値です。次に、各リスク イベントに金銭的損失の値 (各リスク イベントが発生した場合にかかるコスト) を割り当てます。各リスク イベントのリスクの確率とリスクの損失を単純に乗算して、リスク エクポージャを求めます。
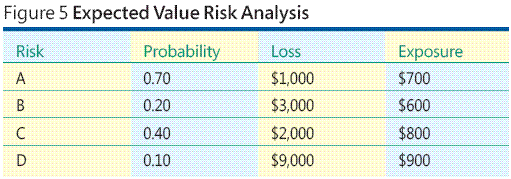
この方法を使用すると、リスク エクポージャは期待値の 1 形式になります。当然ながら、期待値によるアプローチにはいくつかの大きな問題があります。たとえば、リスクの確率を見積もるには、どうすればよいでしょうか。リスクの損失を見積もるには、どうすればよいでしょうか。状況によっては、見積もりの根拠となる良い過去のデータや経験があるかもしれませんが、通常、ソフトウェアの作成時にそうしたデータなどがあるのはまれです。経験上、リスク分析に対する期待値によるアプローチはソフトウェア開発環境に適さないことがよくあります。
多くのソフトウェア開発環境では、リスク イベントの確率や関連する損失を見積もることは難しく、ときには不可能なことさえあるため、一般的な代替手段として、リスクの確率とリスクの損失の代わりにカテゴリ尺度を使用します。これが、カテゴリの手法です。例を使うとわかりやすくなります。A、B、C、D の 4 つのリスクを識別したとします。今度は、各リスクの確率と損失を推測する代わりに、図 6 の上部に示したようなリスク エクポージャのカテゴリ表を生成します。
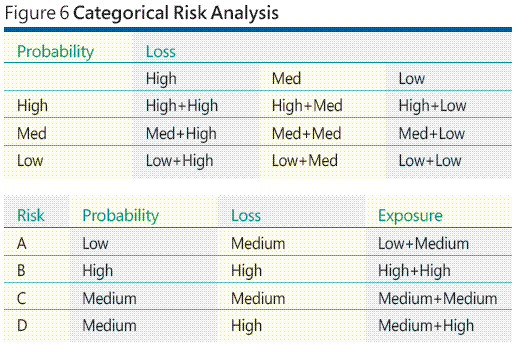
ご覧のとおり、全部で 9 つのリスク エクポージャのカテゴリがあります。リスクの確率に、Low (低)、Medium (中)、および High (高) の 3 つのカテゴリがあります。損失にも、Low (低)、Medium (中)、および High (高) の 3 つのカテゴリがあります。確率カテゴリと損失カテゴリのクロス積を計算すると、Low-Low (低損失の低確率) から High-High (高損失の高確率) までの 9 つのリスク エクポージャのカテゴリが生成されます。次に、先ほどの 4 つのリスク イベントにそれぞれ、Low (低)、Medium (中)、または High (高) の確率を、次に Low (低)、Medium (中)、または High (高) の損失を割り当て、9 段階のリスク エクポージャを生成します。これは、多くの場合、0.05 などの正確な数値の代わりに "Low (低)" という確率値を割り当てる方が合理的であるという考え方です。
図 6 の下部の表にある架空のデータからは、Risk B のエクスポージャが最も高く、エクスポージャが最も低い Risk A よりも、注意やリソース (テストを含む) を注ぐ必要があることがわかります。カテゴリによるリスク分析のアプローチでは、特定が困難または不可能な確率と損失情報を割り当てるという問題がある程度緩和されますが、この手法には新たな問題があります。
確率と損失の両方に対して 3 つのカテゴリを任意に使用していることに注意してください。これは、非常に大雑把なアプローチです。そこで、リスク分析を改善するために、確率と損失の両方の要素に対して Very Low (超低)、Low (低)、Medium (中)、High (高)、および Very High (超高) の 5 つのカテゴリを使用することにします。そうすると、(Very Low (超低) + Very Low (超低)) から (Very High (超高) + Very High (超高)) まで、全部で 25 のリスク エクポージャのカテゴリができます。これらの 25 のエクポージャの値の順位付けや比較を行うには、どうしたらよいでしょうか。(Very Low (超低) + High (高)) エクポージャと (High (高) + Medium (中)) エクスポージャを比較するには、どうしたらよいでしょうか。カテゴリの手法を使用したリスク エクスポージャのデータを複数の人が評価している場合、エクスポージャのデータを同じように解釈するでしょうか。
純粋なカテゴリによるリスク分析のアプローチに関連する問題に対処するために、数年前に、筆者は PERIL (Project Exposure using Ranked Impact and Likelihood (優先順位を付けた影響と尤度を使用したプロジェクトのエクスポージャ)) という手法を開発しました。この考え方の重要な部分は、カテゴリによるアプローチ同様にカテゴリを使用しますが、そのカテゴリを定量的尺度に変換することで、期待値によるアプローチのように簡単に組み合わせて数値のエクポージャ メトリックスを作成できることです。
例を示します。A、B、C、D の 4 つのリスクを識別したとします。ここで、各リスクの確率と損失に意味のある数値を割り当てることが現実的ではないと判断したとします。さらに、その環境では、リスクの尤度を Very Low (超低)、Low (低)、Medium (中)、High (高)、および Very High (超高) の 5 つのカテゴリに分けることが適していると判断したとします。次に、損失または影響を Very Low (超低)、Low (低)、High (高)、および Very High (超高) の 4 段階の尺度に分類します。PERIL の手法では、順位重心と呼ばれる単純な数学的構造を使用して、カテゴリ データを定量的尺度にマッピングします。マッピング手法については、例を見ていただくのが最もわかりやすいでしょう。尤度尺度の 5 つのカテゴリに対する 5 つの順位重心のマッピングを図 7 に示します。
同様に、影響の 4 つのカテゴリのマッピングを図 8 に示すように計算します。ここで、各リスクの尤度と影響の重心値を乗算して、リスク エクポージャを計算します。たとえば、図 9 を見てください。Risk D は、尤度が High (高) (0.25667 にマッピング) で、影響が Low (低) (0.14583 にマッピング) なので、エクスポージャは 0.25667 * 0.14583 = 0.03743 となります。このデータでは、Risk C のエクスポージャが明らかに一番高いため、そのリスクが発生しないようにする方法と発生した場合の代替計画の作成を検討します。
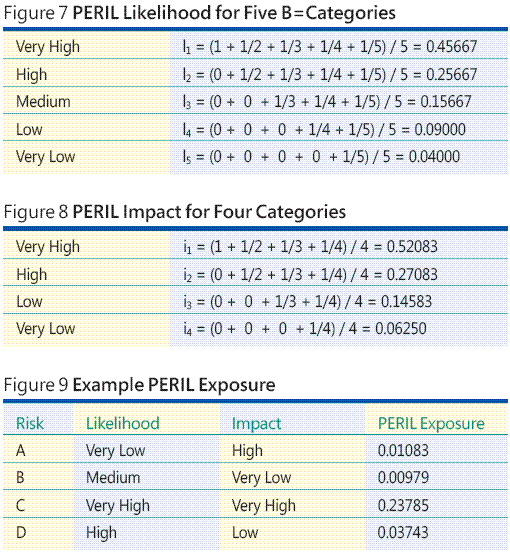
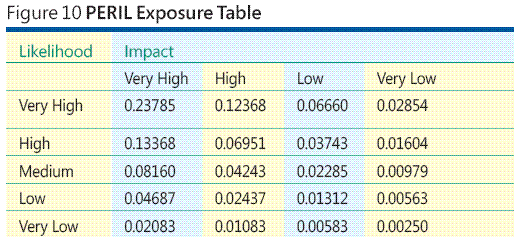
各リスクのエクスポージャを個別に計算する代わりに、図 10 に示すように、5 つの尤度レベルと 4 つの影響レベルの PERIL エクスポージャの完全な参照テーブルを作成すると、PERIL エクスポージャの値をそのテーブルから簡単に読み取ることができます。PERIL の手法は、尤度と影響のカテゴリがいくつあっても使用できます。
順位重心は、順位 (1 番、2 番、3 番など) を数値 (0.61111、0.27778、0.11111 など) にマッピングします。順位重心の値は、(丸めエラーはありますが) 合計すると 1.0 になるという意味で、正規化されています。シグマ記号で表すと、カテゴリ数が N のときに k 番目のカテゴリに対応する数値は次のようになります。
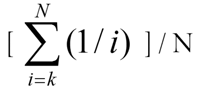
カテゴリと数値の数学的なマッピングは他にもたくさんありますが、リスク分析などに使用される順位のマッピングには順位重心の使用が非常に適しているという研究があります。順位重心の詳細な議論はこのコラムの範囲外ですが、簡単に説明します。リスク イベントの尤度のカテゴリが High (高) と Low (低) の 2 つだけだとします。おそらく、尤度が High (高) のリスク イベントが発生する確率は 0.5 よりも大きく、尤度が Low (低) のリスク イベントが発生する確率は 0.5 よりも小さいでしょう。その他の情報が何もない場合、尤度が High (高) のイベントは、0.5 と 1.0 の中間で、0.75 と等しいと仮定できます。同様に、尤度が Low (低) のイベントは、0.0 と 0.5 の中間の 0.25 と仮定できます。0.75 と 0.25 の 2 つの値は、図 11 に示すように、カテゴリ数 N = 2 の場合の順位重心です。
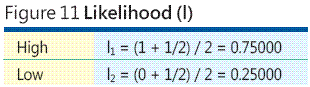
PERIL を使用しているときは、確率と損失ではなく、尤度と影響という用語を使用していることに注意してください。PERIL の尤度と影響は、相対的な、正規化された値です。PERIL の尤度値は、一連の確率と同じように、合計すると 1.0 になりますが、PERIL の尤度値は確率ではないことを強調しておきます。同様に、PERIL の影響値は相互に比較した場合にのみ意味があり、金銭的損失の値ではありません。
リスク エクスポージャを特定するための 3 つの手法 (期待値、カテゴリ、および PERIL) には、長所と短所があります。リスク イベントの確率と各イベントに関連する金銭的損失を見積もることができる確固たる過去のデータがある場合は、通常、期待値の手法が一番適したアプローチです。しかし、ソフトウェアの開発とテスト環境では、確率と損失の意味のある見積もりを作成するのに十分なデータがあることはまれです。
逆に、過去のリスク データがほとんどない場合は、カテゴリの手法を使用して、リスクの確率と関連するリスクの損失に対して 2 つか 3 つのカテゴリを作成する方法が、合理的なアプローチです。リスク イベントの尤度と関連するリスクの影響 (金銭的損失でも、勤労意欲への影響などの非金銭的損失でもかまいません) を大まかに 5 つのカテゴリに分類できる状況では、一般的に PERIL の手法が最適な選択肢となります。
実際の環境でどのリスク分析手法を使用することにしても、結果の解釈は慎重に行う必要があります。リスク分析では、ほとんどの場合、入力する見積もりのばらつきが非常に大きいことを覚えておいてください。つまり、リスク分析によって得られるものは、ソフトウェアのテスト作業に優先順位を付けるためのガイドラインであって、規則ではありません。
リスクに関するリソース
リスクの詳細については、MSDN Magazine の以下のコラムを参照してください。
| 「テストの実行: MAGIQ を使用した競合分析」 |
| 「テストの実行: 階層分析法」 |
まとめ
リスク分析のプロセス全体で、このコラムで説明しなかった部分の 1 つに、リスク管理があります。リスク管理には、リスク データの入力および格納するシステムの構築、ソフトウェア プロジェクトの進捗に沿ったリスク情報の監視などのアクティビティが伴います。リスク管理システムは、電子メールに基づいた簡単なシステムから、Excel のスプレッドシートに基づいた手軽なアプローチや、Microsoft Team Foundation Server システムでのリスク項目の使用に基づいた高度なアプローチまでさまざまです。
リスク関連の作業を管理する方法に関係なく、リスク分析は継続的、反復的なプロセスであることを理解しておくことが重要です。ソフトウェア開発プロジェクトは非常に動的なアクティビティなので、リスク データと結果をプロジェクトの進展に合わせて更新する必要があります。
常識的に考えると、ソフトウェアのリスク分析はすべてのソフトウェア プロジェクトに必要です。プロジェクトは開発者 1 人で 1 週間で終わる小さな作業から、数百人、ときには数千人の開発者で何年もかかる大きなプロジェクトまでさまざまですが、何らかのリスク分析は必要です。しかし、特に中小規模のソフトウェア プロジェクトでは、リスク分析が行われないことがよくあるという結果が多くの調査研究により示されています。
これには理由がいくつか考えられます。リスク分析があまり行われない理由の 1 つは、コーディングに必要なスキルや能力とほぼ正反対の技術や能力が必要だからだと思います。そのことについて説明しましょう。ソフトウェア開発のほとんどのアクティビティはクローズド システムに基づいて比較的明確に定義されていて、目標が小さく、通常は、すぐにフィードバックが返ってきます。たとえば、開発者として何らかのコードを記述している場合は、コードをコンパイルして実行すると、即座にフィードバックを得ることができます。コードが期待どおりに実行されれば、通常は、一定の満足感が得られます。ソフトウェアのリスク分析の実行は、かなり異なる種類のアクティビティです。コーディングの際に得られるようなフィードバックや満足感はまったく得られません。
要するに、ソフトウェアのリスク分析は、コーディングとはかなり異なっています。このコラムを通じて、リスク分析を実行することの重要性を理解していただき、ここで紹介した便利な手法がより優れた、信頼性の高いソフトウェアの作成に役立つことを願っています。
ご意見やご質問は、James (testrun@microsoft.com) まで英語でお送りください。
Dr. James McCaffrey は Volt Information Sciences, Inc. に勤務し、ワシントン州レドモンドにあるマイクロソフト本社で働くソフトウェア エンジニアの技術トレーニングを管理しています。これまでに、Internet Explorer、MSN サーチなどの複数のマイクロソフト製品にも携わってきました。また、『.NET Test Automation:A Problem-Solution Approach』(Apress、2006 年) の著者でもあります。James の連絡先は jmccaffrey@volt.com または v-jammc@microsoft.com です。