CLR 徹底解剖
.NET アプリケーションのメモリ使用量の監査
Subramanian Ramaswamy および Vance Morrison
目次
メモリ使用量が速度に影響するケース
対処方法
タスク マネージャ
共有メモリと非共有メモリ
アプリケーションのサイズ
VADump: メモリ使用量を詳細に表示するツール
.NET ガベージ コレクタ
PerfMon
まとめ
パフォーマンスの最適化の目的はただ 1 つ、コンピュータ プログラムの実行速度を向上させることです。現代のコンピュータ ハードウェアでは命令の実行は低コストですが、命令オペランドのフェッチは高コストです。そのため、メモリ使用量はアプリケーションの実行速度に直接影響を及ぼす可能性があり、最適化すべき重要なメトリックとなっています。この記事では、.NET プログラムを対象に、メモリの最適化の基本について説明します。まず、メモリ アクセスがボトルネックとなるケースと、最適化に役立つケースを紹介します。次に、典型的な .NET プログラムにおけるメモリの使用方法の一般的な分類について説明します。そして最後に、.NET アプリケーションのメモリ消費量を測定し、削減するためのツールと戦略を紹介します。
メモリ使用量が速度に影響するケース
メモリ消費量が問題となる最初のケースは、大量のデータを処理する、CPU 使用量の多いアプリケーションです。標準的な PC では、命令を 0.5 ナノ秒未満で実行できます。ただし、この速度は、メモリからオペランドをフェッチするのに要する時間の影響を受けます。現代のプロセッサには、ハードウェアのコストを最適化するためのキャッシュ階層があります。一次 (L1) キャッシュは最速ですが、比較的容量の少ないメモリです。階層内の次のキャッシュは二次キャッシュです。その次はメイン メモリ (RAM) で、最後がハード ディスク ドライブです。図 1 に、標準的な PC のメモリ階層に含まれるさまざまなパーツのアクセス時間とサイズを示します。階層の奥にあるメモリほどアクセス時間 (とサイズ) は桁違いに増え (ハード ドライブのアクセス時間は RAM の 10,000 倍)、コスト (バイトあたり) は少なくなります。
| 図 1 サイズとアクセス時間 (非ローカル ストレージ) |
| L1 キャッシュ | L2 キャッシュ | メモリ (RAM) | ディスク | |
| サイズ | 64 KB | 512 KB | 2,000 MB | 100,000 MB |
| アクセス時間 | 0.4 ナノ秒 | 4 ナノ秒 | 40 ナノ秒 | 4,000,000 ナノ秒 |
ホット データ パスで容量の大きいメモリにアクセスする場合、低速のメモリから頻繁にオペランドをフェッチしなければなりません。低速のメモリは桁違いに速度が遅いため、二次キャッシュ ミスが何度か生じると、パフォーマンスに大きな影響を及ぼす可能性があります。
次のケースに進みましょう。アプリケーションのコールド起動時には、(一部の) メモリ消費量が問題になります。図 1 に示すとおり、ハード ディスク アクセスはメイン メモリ アクセスよりもはるかに時間がかかります。オペレーティング システムは、ディスクのデータをメイン メモリにキャッシュすることでこの時間の短縮を試みます。2 回目の起動 (ウォーム起動) 時にアプリケーションの速度が上がるのは、このためです (データが高速のメモリにキャッシュされている)。初回起動 (コールド起動) 時にはキャッシュがまだ行われていないため、データをディスクからフェッチする必要があります。これを高速化する唯一の方法は、ディスクから読み込まれるデータの量を少なくすることです。コールド起動に影響するのは、ディスクからフェッチされるメモリ (プログラムの命令など) だけです。つまり、プログラム自体が初期化したメモリ (ヒープおよびスタックのすべてのデータを含む) は、コールド起動に影響しません。
最後のケースに進みます。アプリケーションの切り替え時にもメモリ消費量が問題となります。たとえば、ユーザーがある程度サイズの大きい (50 MB 超) アプリケーションを使用中に、他のさまざまなアプリケーションに切り替えると、最初のアプリケーションの物理メモリが奪われていきます。最初のアプリケーションに戻るときに、奪われたこれらのページをディスクからフェッチし直す必要があり、アプリケーションの実行速度が大きく低下します。これはコールド起動のケースと似ていますが、プログラムの命令だけではなくすべてのメモリ (最初のアプリケーションによって初期化されたメモリも含む) に影響があるという点が異なります。サーバーでは数多くの無関係のプログラムが同時に、そして継続的に実行されるので、絶えずアプリケーションの切り替えが行われます。つまり、サーバーにはほぼ常にメモリの問題が存在することになります。
対処方法
コードを魔法のように並べ替えて、高速のキャッシュですべてのメモリ要求を満たすことができれば、プログラムの実行速度は大幅に高まるはずです。実際には、これを実現できるのは特殊な状況に限られます。通常はプログラムのアルゴリズムがメモリ アクセスの順序を指示するからです。より現実的な手法は、使用されるメモリの量を最小限に抑えることです。そうすれば、高速のキャッシュへの負荷が減り、プログラムの実行速度が上がります。頻繁にアクセスされる "ホットな" 部分が CPU キャッシュに収まりきらない (一般的にはそれが数 MB を超えるような) データ構造の場合、ホット データのメモリ サイズを 30% 抑えることにより、通常は CPU 速度が 10% 向上します。
メモリは 3 とおりの方法で減らすことができます。まず、実行するコードの量を抑えます (これはコールド起動に役立ちます)。この方法は、そもそも何らかの要素の計算が効率的に行われていないというわかりやすいケースで使用できます。次に、処理するデータの量を抑えます。これは最初の方法と似ていますが、関連するデータ構造に適用されます。最後に (おそらくこれが最も一般的な方法です)、データ構造を別の方法でエンコードし、縮小します。つまり、アクセス頻度の高い (小さな) 要素をアクセス頻度の低い (大きな) 要素から物理的に切り離します。
これらの手法を用いると、通常はデータ表現や実装する多数のコード サイトを変更する必要があります。そのため、これらの変更は開発サイクルの初期に行った方がはるかに簡単です。だからこそ、早期にメモリについて検討するようにしてください。
タスク マネージャ
アプリケーションのメモリ消費量を減らすには、まず現在の使用量を把握する必要があります。そこで、Windows に組み込まれているタスク マネージャ アプリケーションを使用します。
ほとんどのユーザーは、タスク マネージャを使い慣れているはずです。タスク マネージャを起動するには、[ファイル名を指定して実行] コマンド ウィンドウ (Windows キーを押しながら R キーを押す) で「taskmgr」と入力するか、Ctrl キーと Alt キーを押しながら Del キーを押し、[タスク マネージャの起動] をクリックします。[プロセス] タブに、システムで現在実行されているすべてのプロセスに関する情報が表示されます。[PID]、[メモリ - ワーキング セット]、および [メモリ - プライベート ワーキング セット] 列が表示されていない場合は、[表示]、[列の選択] の順にクリックし、表示されるオプションを使用してこれらの列を追加します。
共有メモリと非共有メモリ
ワーキング セットは、プロセスによって現在使用されている物理メモリです。ただし、オペレーティング システムは最適化を行って、すべてのメモリのコストが均等に高くなるのを防ぎます。プロセスが使用するメモリの大部分には、読み取り専用データ (実行する実際の命令など) が保持されます。このデータは読み取り専用なので、これを必要とするすべてのプロセスが共有できます。すべてのプロセスが共有の読み取り専用オペレーティング システム コードをフル活用するため、すべてのプロセスの相当量のワーキング セットが共有されます。したがって、ワーキング セットの合計では、プロセスによって使用されるメモリの実際のコストがかなり多く見積もられる傾向にあります。
オペレーティング システムは非共有 (プライベート) メモリも追跡します。プロセスによって使用されるあらゆる読み取り/書き込みメモリが対象です。プライベート ワーキング セットの場合はプロセスによって使用されるメモリの実際のコストは低く見積もられますが (そのしくみについては、VADump ツールのトピックを参照してください)、こちらの方が最適化に適したメトリックです。共有メモリを最適化する場合とは異なり、プライベート メモリが増すとコンピュータに対する総メモリ負荷が減るからです。
さらに、メモリの総量とプライベート メモリの容量のいずれにも、プロセスによって使用されるある重要なメモリ (ファイル システム キャッシュ) は算入されません。ハード ディスク アクセスはコストが非常に高いため、ファイルのデータがメモリに直接マップされていない場合でも、オペレーティング システムによってキャッシュされます。このメモリを使用すると、システムに対するメモリ負荷が高まります。このメモリは、どちらのワーキング セット メトリックにも含まれません (オペレーティング システムによって所有されます)。ファイル アクセスに関してできることはあまりないので (プログラムでファイルが必要な場合、それを回避することはできません)、最適化できないコストと考えることができます。
アプリケーションのサイズ
アプリケーションは、そのメモリ使用量に応じて、小規模なアプリケーション、中規模のアプリケーション、および大規模なアプリケーションに分類できます。小規模なアプリケーションの場合、ワーキング セットのサイズは 20 MB 以下で、プライベート ワーキング セットのサイズは 5 MB 未満です。中規模のアプリケーションの場合、ワーキング セットのサイズは約 50 MB で、プライベート ワーキング セットのサイズは約 20 MB です。大規模なアプリケーションの場合は、通常、ワーキング セットのサイズは 100 MB を超え、プライベート ワーキング セットのサイズも 50 MB を超えます。アプリケーションの規模が大きくなればなるほど、アプリケーションのメモリ使用量を最適化する価値も高まります。
簡単かつ迅速にメモリ使用量を監視し、リークの有無をチェックするには、アプリケーションに対しスニフ テストを行います。アプリケーションをしばらくの間実行し、そのワーキング セットの使用量を監視してください。ワーキング セットが制限なく増加する場合は、メモリ リークなどの問題が発生している可能性があります。
VADump: メモリ使用量を詳細に表示するツール
タスク マネージャで表示できるのは、アプリケーションのメモリ使用量の概要だけです。より詳細な情報を確認するには、VADump というツールが必要です (「パフォーマンス リソース」のリンクを参照してください)。このツールを起動するには、コマンド プロンプトで、VADump がインストールされているディレクトリで「VADump –sop ProcessID」と入力します。このツールは、DLL レベルの細かさで 1 つのプロセス内のメモリの内訳を出力します。一般的なダンプを図 2 に示します。

図 2 メモ帳で開いた VADump の出力
ダンプを確認する際は、まずワーキング セットの合計を見ます。この数値はタスク マネージャの数値と同じであるはずです。この数値は、8 つのカテゴリに分類されます。その中で最も興味深いカテゴリは、次の 3 つです。
- Code/StaticData (コード/静的データ)。プロセスによって読み込まれた DLL を表します。
- Heap (ヒープ)。使用されているネイティブのヒープ メモリを表します (GC ヒープ メモリではありません)。
- Other Data (その他のデータ)。OS の VirtualAlloc 関数を使用して割り当てられたメモリを表します。マネージ コードの場合、これにはガベージ コレクション ヒープ全体が含まれるため、重要です。
パフォーマンス リソース
CLR Perf チームのブログ (疑わしい DLL の読み込みを調べる際の手順):
VS プロファイラ チームのブログ:
.NET アプリケーションのパフォーマンスとスケーラビリティを高める:
msdn.microsoft.com/library/ms998530
Windows のパフォーマンスに関するブログ: Xperf を使用した調査:
Vance Morrison のブログ:
Rico Mariani のブログ:
Lutz Roeder の .NET Reflector (コードの検査用ツール):
CLR 徹底解剖 - メモリの問題を調べる:
msdn.microsoft.com/magazine/cc163528
概要の表の後ろに、DLL によって使用されているメモリがさらに細かく分類され、各 DLL が使用するページの数 (1 ページは通常 4 KB) が示されます。そのため、読み込まれたすべてのコードのメモリ コストを確認できます。
図 2 には、"Grand Total Working Set (ワーキング セットの合計)" という行があります。その最初の列には、ワーキング セットの合計が KB 単位およびページ単位で示されています。列 2 (Private (プライベート))、3 (Shareable (共有可能))、および 4 (Shared (共有済み)) の値 (KB 単位) の合計が Total Working Set (ワーキング セットの合計) 列の値になります。列 2 の Private (プライベート) の値 (KB 単位) は、タスク マネージャでのプライベート ワーキング セットの値に相当します。一方、列 1 の値は、タスク マネージャでのワーキング セットの合計に相当します。したがって、VADump を使用すると、共有可能なワーキング セットと共有されているワーキング セットを含め、プライベート ワーキング セットとワーキング セットの合計を区別することができます。タスク マネージャを使用した場合よりも、使用状況を詳細に把握可能です。
規模の大きな .NET アプリケーションとは、通常は、多数のコードを実行するか、大量のデータを使用するアプリケーションのことをいいます。
この場合、多数の DLL が読み込まれ、Code/StaticData (コード/静的データ) の値がワーキング セットの合計の大部分を占める傾向にあることがわかります。マネージ アプリケーションの場合、このデータは GC ヒープに含まれるため、Other Data (その他のデータ) として示されます。その結果、Other Data (その他のデータ) の値がワーキング セットの大部分を占めることになります。
図 2 の下部には、モジュールのワーキング セットがページ単位で示されており、アプリケーションのワーキング セットに関与しているモジュールと、各モジュールによるワーキング セットの消費量がわかります。そのため、DLL のプライベート ワーキング セット、共有されているワーキング セット、および共有可能なワーキング セットの観点から、特定の DLL がどの程度のワーキング セットに関与しているのかを簡単に特定できます。このビューからは、DLL の読み込みを省くことができるかどうかや、アプリケーションのワーキング セットからプライベート ワーキング セットを何バイト削ることができるかが明確にわかります。
読み込む必要のない DLL を特定したら (たとえば、DLL は特定の実行で使用されない場合にも読み込まれることがあります)、その DLL が読み込まれる理由を明らかにし、不要な読み込みを省く方法を探します。疑わしい DLL の読み込みを調べる手順については、「CLR and Framework Perf Blog (CLR と Framework Perf に関するブログ)」を参照してください。
VADump の出力に示されるヒープ データは、アンマネージ ヒープ (.NET GC で管理されないメモリ) のデータです。GC で必要に応じてクリーンアップを行ってメモリの大部分を管理できるように、この数値が大きくならないよう注意してください。
Other Data (その他のデータ) カテゴリは、VADump がその他の方法で分類できないプリミティブ OS メモリ割り当て関数 (VirtualAlloc) の呼び出しを表しています。.NET アプリケーションの場合、Other Data (その他のデータ) の中で最も重要なコンポーネントは、通常、すべてのユーザー定義オブジェクトを保持するガベージ コレクション ヒープです。
.NET ガベージ コレクタ
.NET ランタイムは自動メモリ管理をサポートしています。.NET ランタイムは、マネージ プログラムによって行われたすべてのメモリ割り当てを追跡し、GC を定期的に呼び出します。GC は、使用されていないメモリを検出し、新しい割り当ての際に再利用します。ガベージ コレクタが行う重要な最適化は、ヒープ全体を毎回検索せずに、ヒープを 3 つの世代 (0、1、および 2) に分割するという処理です。
世代 0 はこの中で最も小さく、完了するまでに通常はわずか 0.1 ミリ秒しかかかりませんが、クリーンアップされるのは前回の GC 後に行われた (明らかに使用されていない) 割り当てだけです。世代のサイズは L2 キャッシュのサイズよりも小さいのが理想的です。世代 1 の GC では、前の GC で残った割り当てを処理します。これには世代 0 の GC よりも時間がかかり、約 1 ミリ秒を要します。世代 1 の GC 1 回につき世代 0 の GC 10 回という割合が理想的です。
世代 2 の GC ではすべてのオブジェクトが処理されます。したがって、かなり長い時間がかかる可能性があります。たとえば 20 MB のヒープの場合は、160 ミリ秒程度かかることがあります。これはかなりの時間です。この時間は、ヒープのサイズにほぼ比例して増加します (概算で 1 MB あたり 8 ミリ秒)。実際のコストは、残っているメモリの量、残っているメモリ内の GC ポインタの数、およびヒープの断片化の具合に応じて変わります。世代 2 の GC 1 回につき世代 1 の GC 10 回という割合が理想的です。
全体として見ると、.NET GC ヒープは、世代 2 コレクションに対応するトラフのあるのこぎりの歯に似ています (図 3 を参照)。通常の世代 2 のヒープ対トラフの比率は約 1.6 です。この比率は、ヒープのサイズとは無関係です (ただし、断片化していない場合)。断片化している場合は、この数値は大きく変わる可能性があります。
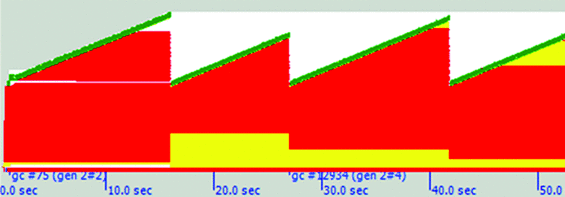
図 3 GC ヒープののこぎり歯状の波形
Perfmon
VADump を使用すると、プロセスによるメモリ使用量の第 1 レベルの分類が可能です。ただし、使用中の GC メモリを正確に確認できず (Other Data (その他のデータ) カテゴリには、GC ヒープ以外のメモリも含まれるため)、GC の世代の比率が適正かどうかもわかりません。そこで、Windows PerfMon アプリケーションを使用する必要があります。PerfMon を起動するには、[ファイル名を指定して実行] コマンド ウィンドウで「PerfMon」と入力します。すると、図 4 のようなウィンドウが開きます。PerfMon ではさまざまなパフォーマンス データを収集できますが、ここでは GC ヒープを監視する場合の使用方法に重点を置いて説明します。
.gif)
図 4 PerfMon の起動時の画面
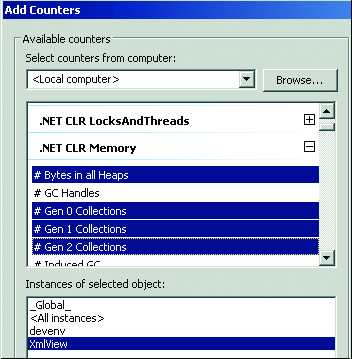
図 5 PerfMon で監視するカウンタを選択する
PerfMon が起動したら、GC に関する情報が表示されるように構成する必要があります。そのためにはまず、左側のペインでツリー コントロールの [パフォーマンス モニタ] 項目をクリックします。すると、右側のペインにパフォーマンス カウンタのデータが表示されます。ここでは、新しいカウンタを追加するために + 記号をクリックします。次に、図 5 に示すように、監視するカウンタとプロセスを選択します。
いくつかのカウンタを選択すると、ランタイムを使用しているすべてのアプリケーションの名前に気が付くはずです。監視するアプリケーションを自由に選ぶことができます。また、[すべてのインスタンス] というインスタンスもあります。これを選択すると、表示されているすべてのインスタンスのデータを監視できます。ただし、データは個別に表示されます。さらに、[_Global_] というインスタンスもあります。これは、異なるインスタンスのデータを集計する場合に選択します。
PerfMon を使用してアプリケーションを監視しているときに別のアプリケーションを起動した場合、そのアプリケーションを追加するには、+ 記号をクリックし、新しいアプリケーションのカウンタを追加します (新しいインスタンスを追加するだけでかまいません。他のインスタンスは PerfMon に引き続き表示されます)。
また、既定ではデータはグラフィックで表示されますが、数値で表示した方が便利です。データを数値で表示するには、レポートの種類のツール バーをクリックします (図 6 を参照)。あるテストでは、合計 8.6 MB のプライベート ワーキング セットのうち、7.3 MB を GC ヒープが占めており、約 11% の時間が GC に費やされたことが判明しました。GC に要する時間はアプリケーションの合計時間の 10% 未満が適正なので、このテストのアプリケーションはボーダーライン上にあることになります。さらに、PerfMon には世代 0、世代 1、および世代 2 コレクションの回数も表示されます。世代 0 コレクションの回数は世代 1 コレクションの 10 倍以上、そして世代 1 コレクションの回数は世代 2 コレクションの 10 倍以上になるのが理想的です。
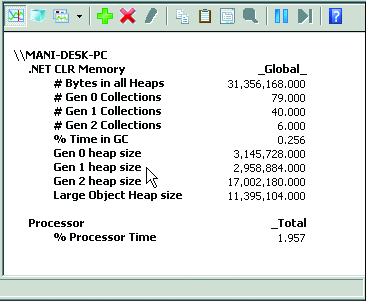
図 6 PerfMon レポートの表示
まとめ
メモリの問題は、デバッグが難しいことで知られています。メモリに注意する必要があるほどアプリケーションの規模が大きい場合は、開発の初期段階からメモリ使用量を抑制することが重要です。そのためには、まずアプリケーションのメモリの分類を理解してから、アプリケーションのメモリ使用量を監視します。さらに、メモリ消費量に与える影響が最も大きい DLL はどれか、世代 2 の GC がこれほど頻繁に行われているのはなぜか、このメモリ割り当ては本当に必要か、といった事柄を確認して、改善できる要素を特定してください。それに応じて、メモリ使用量を最適化します。この記事から皆さんに 1 つだけ教訓を学んでもらうとすれば、それは、開発サイクルの初期にメモリの問題に費やした時間は後で元が取れるので、メモリについて早期から検討することがきわめて重要だ、ということです。
ご意見やご質問は clrinout@microsoft.com までお送りください。
Subramanian Ramaswamy は、マイクロソフトで CLR パフォーマンスのプログラム マネージャを務めています。彼は、ジョージア工科大学で電気およびコンピュータ エンジニアリングの博士号を取得しています。
Vance Morrison は、マイクロソフトで CLR パフォーマンスのパートナー アーキテクトおよびグループ マネージャを務めています。彼は .NET 中間言語 (IL) の設計を推進したほか、.NET に当初から携わっています。