May 2009
Volume 24 Number 05
Data Services - ADO.NET Data Services を使用してオンプレミスまたはクラウドのデータにアクセスする
Elisa Flasko | May 2009
コードは MSDN コード ギャラリーからダウンロードできます。
オンラインでのコードの参照
この記事は、Windows Azure と ASP.NET MVC のプレリリース版に基づいています。
この記事では、次の内容について説明します。
|
この記事では、次のテクノロジを使用しています。 Windows Azure、ASP.NET MVC |
目次
アプリケーション
ADO.NET Data Services のクライアント ライブラリを通じてオンプレミス データ サービスを利用する
データを照会する
作成、更新、および削除する
Azure Table データ サービスを利用する
Azure Table データ モデル
ADO.NET Data Services のクライアント ライブラリ
クライアントでモデルを定義する
テーブルを作成する
データを照会する
作成、更新、および削除する
まとめ
Web サービスは、長年にわたって注目を集めていますが、最近話題になっているデータ サービスとはどのようなものか疑問に思う読者もいるでしょう。Web アプリケーションのアーキテクチャは Rich Internet Applications (RIA) などの人気と共に変化および成熟してきたので、インターフェイスや書式設定を除いた生データを、それらを利用するサービスやアプリケーションに公開することの価値に対する認識が高まっています。データ サービスとは、RESTful インターフェイスを使用したシンプルなデータ中心のサービスです。このサービスにより、アプリケーションで利用する純粋なデータが公開されます。そのようなサービスは、企業イントラネットやインターネットを経由し、一貫性のあるインターフェイスを通して、Web クライアントで使用されるデータを公開します。ADO.NET Data Services のサーバー ライブラリを使用して、データ サービスを組織内で構築およびホストし、1 つのサービスとしてデータを安全に公開することができます。また、Windows Azure Table などのホストされたさまざまなサービスでデータ サービスを利用できるようにすることも可能です。Windows Azure は、Microsoft クラウド プラットフォームの基盤です。"クラウド用のオペレーティング システム" として、Windows Azure は、拡張性と可用性の高いサービスの記述に不可欠な構成要素を提供します。Azure の主要な部分の 1 つである Windows Azure Table を使用すると、ユーザーはクラウド内のデータを保持したり、データ サービスとして格納されるデータを公開したりできます。
データ サービスがホストされている場所に関係なく、ADO.NET Data Services フレームワークでは、一連の Microsoft 開発プラットフォーム (.NET、Silverlight、ASP.NET AJAX など) 用に構築されたクライアント ライブラリのセットを提供します。クライアント ライブラリを使用すると、これらのサービスをアプリケーションで簡単に利用できるようになります。
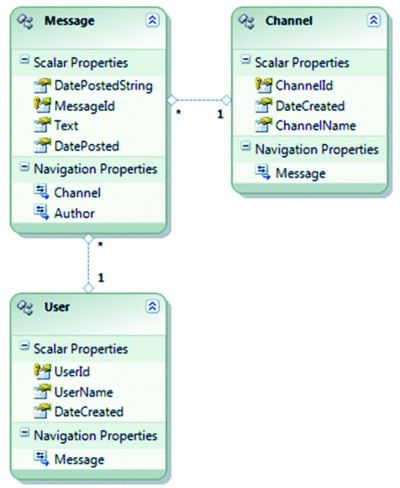
図 1 マイクロブロギング データ サービスで公開されるエンティティ データ モデル
アプリケーション
この記事では、ASP.NET Model View Controller (MVC) (リリース候補) を使用して簡単なマイクロブロギング アプリケーションを構築し、そのようなサービス ベースのアプリケーションを構築する一般的ないくつかのシナリオについて詳しく説明します。MVC の知識がある方を対象としているため、ここでは MVC については詳しく説明しません。ASP.NET MVC の詳細については、ASP.NET MVC のサイトを参照してください。比較のために、同じ基本アプリケーションの 2 つのバージョン (オンプレミス データ サービスを利用するアプリケーションと Azure Table データ サービスを利用するアプリケーション) を取り上げます。両方のバージョンのコードは、付属のダウンロード コードに含まれています。
マイクロブロギング アプリケーションを使用すると、ユーザーは特定のチャネルへのメッセージの投稿、チャネルの新規作成、および興味のあるチャネルのメッセージの表示を行うことができます。このアプリケーション用のデータ サービスで公開されたモデルは、3 種類のエンティティ (メッセージ、チャネル、およびユーザー) で構成されます。これらのエンティティは、データベースに対して主に一対一でマッピングされます。ここで注意しなければならないのは、オンプレミス データ ソースの場合は、このモデルにエンティティ間のリレーションシップの最上位の概念が含まれるという点です。メッセージは、個々のユーザーによって特定のチャネルに投稿されます (図 1 を参照)。
ADO.NET Data Services のクライアント ライブラリを通じてオンプレミス データ サービスを利用する
まずは、ASP.NET MVC と共にインストールされた Visual Studio テンプレートを使用して、新しい ASP.NET MVC Web アプリケーションを作成してみましょう。
クライアントでモデルを表すクラスを定義する方法は主に 2 つあります。まずは単純にモデルを定義する方法です。この場合、サービスで公開されるエンティティを表す、クライアントで使用される POCO (Plain Old CLR Object) クラスを定義します。この記事では、Windows Azure Table を利用するアプリケーションを開発する場合にこの方法を使用します。もう 1 つは、Visual Studio のサービス参照の追加ウィザードを使用して必要なクラスを生成する方法です。Windows Communication Foundation (WCF) サービスで [サービス参照の追加] を使用する場合と同じように、プロジェクトを右クリックして、[サービス参照の追加] をクリックするだけです。[サービス参照の追加] ダイアログ ボックスで、[アドレス] にサービスのエントリ ポイントの URI を入力し、[OK] をクリックします。これで、データ サービス定義に基づいて関連クラスが生成され、プロジェクトに追加されます。
図 2 に示されているように、サービス参照の追加ウィザードによって、各エンティティ (チャネル、メッセージ、およびユーザー) のクラスと、サービス全体を表すクラス (microblogEntities) が生成されます。microblogEntities クラスは、DataServiceContext を継承し、データ サービスへのアクセスの開始点として使用されます。
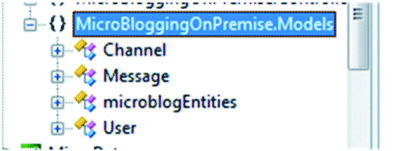
図 2 マイクロブロギング モデルを表すクラス
データを照会する
これで、アプリケーションがデータ サービスにアクセスするように設定されました。続いて、アプリケーションの残りの部分の開発を開始します。ホーム ページ上で、このアプリケーションは、利用可能なチャネルの一覧を提供し、ユーザーがチャネルを選択すると、本日投稿されたメッセージが表示されるようにします。また、ユーザーはチャネルを作成者でフィルタ処理することもできます。ホーム ページを作成するには、インデックス ビューにマッピングされる ActionResult をホーム コントローラに作成する必要があります (ホーム コントローラとインデックス ビューは、既定で MVC テンプレートに作成されます)。ホーム ページ上では、利用可能なすべてのチャネルの一覧をデータ サービスから取得し、本日投稿されたメッセージについてサービスに照会して、ユーザーの入力を基にフィルタ処理する必要があります (図 3 を参照)。
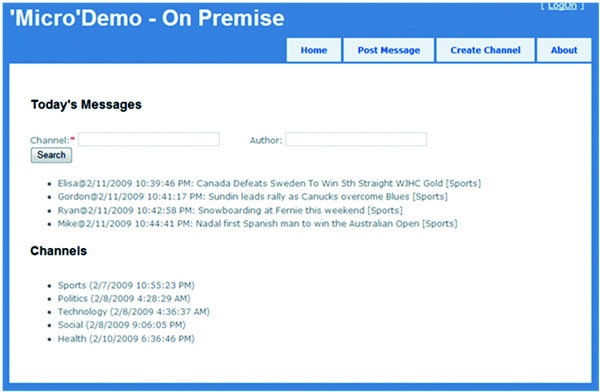
図 3 サイトのホーム ページ
ADO.NET Data Service のクライアント ライブラリでは、図 4 に示すように、統合言語クエリ (LINQ) を使用して簡単にデータを照会できます。
ホーム ページ コントローラの Index アクションは、ブラウザからホーム ページへのアクセスがあった場合に MVC アプリケーションによって呼び出され、Index.aspx ビューを表示するために使用されるデータを返します。図 4 では、Index アクション内で、次のように DataServiceContext microblogEntities の新しいインスタンスを作成しています。
microblogEntities svc = new microblogEntities(new Uri("http://localhost:50396/MicroData.svc"));
図 4 LINQ を使用して .NET オブジェクトとしてデータにアクセスする
public ActionResult Index(string channel, string author) { microblogEntities svc = new microblogEntities(new Uri("http://localhost:50396/MicroData.svc")); ViewData["channels"] = svc.Channels; int y = DateTime.Now.Year; int mm = DateTime.Now.Month; int d = DateTime.Now.Day; var q = from m in svc.Messages.Expand("Author").Expand("Channel") where m.Channel.ChannelName == channel && (m.DatePosted.Year == y && m.DatePosted.Month == mm && m.DatePosted.Day == d) select m; if (!string.IsNullOrEmpty(author)) { q = from m in q where m.Author.UserName == author select m; } ViewData["msg"] = q; return View(); }
これは、サービスをヒットさせたい場合に使用するオブジェクトです。データ サービスに対して実行される最初のクエリは、利用可能なすべてのチャネルにアクセスします。2 つ目の LINQ クエリは、ユーザーがページをヒットしたときに要求されたチャネル内のメッセージをすべて取得し、名前が指定されている場合は作成者でフィルタ処理します。提供されているサンプル コードでは、テキスト ボックスにチャネル名 (および必要に応じて作成者名) を入力して [View] をクリックすると、メッセージが表示されます。また、クエリには ChannelName が必要である点にも注意してください。作成者名だけでは検索が実行されません。ここでは、ページが表示された場合に実行される上記の 2 つのクエリを ViewData に配置して、結果を取得します。
次に、ホーム ページのビュー Index.aspx で、クエリを実際に列挙して、この時点でストアに対して効果的にクエリを実行し、ページに結果を出力します (図 5 を参照)。
図 5 ホーム ページ ビュー (オンプレミス サービス)
<h2>Today's Messages</h2> <form action="./"> Channel:<span style="color: #FF0000">*</span> <input type="text" name="channel" /> Author: <input type="text" name="author" /><br /> <input type="submit" value="Search" /> </form> <ul> <!-- Execute query placed in ViewData["msg"] - enumerates over results and prints resulting message data to the screen --> <% foreach (var m in (Ienumerable <MicroBloggingOnPremise.Models.Message>) ViewData["msg"]) { %> <li><%=m.Author.UserName%>@<%=m.DatePosted %>: <%=m.Text%> [<%=m.Channel.ChannelName %>]</li> <%} %> </ul> <h2>Channels</h2> <ul> <!-- Execute query placed in ViewData["channels"] - enumerates over results and prints resulting channel data to the screen --> <% foreach (var channel in (IEnumerable<MicroBloggingOnPremise.Models.Channel>) ViewData["channels"]) { %> <li><%=channel.ChannelName %> (<%=channel.DateCreated %>)</li> <% } %> </ul>
作成、更新、および削除する
ADO.NET Data Service のクライアント ライブラリを使用してデータ サービスに新しいエンティティ インスタンスを作成するために、エンティティ セットを表す .NET オブジェクトのインスタンスを作成し、使用する DataServiceContext インスタンスでエンティティ セットの AddTo… メソッドを呼び出して、新しいオブジェクトとそのオブジェクトの追加先となるエンティティ セットを渡します。
たとえば、図 6 で、ホーム ページ コントローラの PostMessage アクションを見てみましょう。このアクションは、[Send] ボタンをクリックしてメッセージを投稿しようとすると呼び出されます。
図 6 (オンプレミス) 新しいメッセージを作成してデータ ストアにプッシュする
[AcceptVerbs("POST")] public ActionResult PostMessage(string channel, string author, string msg) { microblogEntities svc = new microblogEntities(new Uri("http://localhost:50396/MicroData.svc")); Channel chan = (from c in svc.Channels where c.ChannelName == channel select c).FirstOrDefault(); if (chan == null) throw new ArgumentException("Invalid channel"); User u = (from auth in svc.Users where auth.UserName == author select auth).FirstOrDefault(); if (u == null) //throw new ArgumentException("Invalid Author"); { //To simplify this example we will create a new user, //if the user was null when we queried. //It is possible that another client creates //the same UserName //before we call SaveChanges() //and we end up with 2 Users with the same name var user = new User(); user.UserName = author; user.DateCreated = DateTime.UtcNow; svc.AddToUsers(user); u = user; } var m = new Message(); m.DatePosted = DateTime.UtcNow; m.Text = msg; svc.AddToMessages(m); svc.SetLink(m, "Channel", chan); svc.SetLink(m, "Author", u); try { svc.SaveChanges(); } catch (Exception e) { throw (e); } return this.RedirectToAction("Index"); }
このメソッドは、フォーム ポストに使用するため、AcceptVerbs("POST") 属性で修飾されます。ここでも、サービスへのエントリ ポイントとして、まず新しい DataServiceContext のインスタンスを作成し、指定されたチャネルを照会して、そのチャネルが存在することを確認します。チャネルが存在しない場合は、例外をスローします。それ以外の場合は、ユーザーが入力したデータを渡す新しいメッセージを作成します。メッセージが作成されたら、新しい Message オブジェクトである m を渡す svc.AddToMessages(m); を呼び出すことで、新しいオブジェクトが追加されるというコンテキストを指定する必要があります。また、この新しいメッセージに付加されるリレーションシップを表すリンクを、指定されたチャネルにメッセージを関連付ける case svc.SetLink(m, "Channel", chan); と指定された作成者にメッセージを関連付ける svc.SetLink(m, "Author", u); で設定します。最後に、svc.SaveChanges(); を呼び出して、サービスの変更内容をデータベースにプッシュします。
新しいインスタンスを作成するのではなく、既存のインスタンスを変更する場合は、更新するオブジェクトを最初に照会し、必要な変更を行います。次に、AddToMessages の代わりに UpdateObject メソッドを呼び出して、次回 SaveChanges() を呼び出すときにそのオブジェクトの更新を送信する必要があるというコンテキストを指定します。同様に、インスタンスを削除する場合は、オブジェクトが追加されたときに Delete メソッドを呼び出して、そのオブジェクトを削除するというコンテキストを指定します。
この例、およびこの記事のこれまでの説明では、クライアント上での 1 つの操作が、サービスに送信される 1 回の HTTP 要求にマッピングされる処理について見てきました。多くのシナリオでは、クライアントで複数の操作をグループとしてまとめて、1 回の HTTP 要求でそれらをサービスに送信できるようにすると便利な場合もあります。これにより、サービスへのラウンド トリップの数が減り、操作のセットに対するアトミック性の論理スコープが有効になります。ADO.NET Data Service のクライアント ライブラリでは、Insert、Update、および Delete 操作のグループを 1 回の HTTP 要求でサービスに送信する処理をサポートします。そのためには、SaveChanges() メソッドを呼び出し、SaveChangesOptions.Batch を唯一のパラメータとして渡します。このパラメータ値は、すべての保留中の変更を 1 回の HTTP 要求にまとめてサービスに送信するように、クライアントに指示します。変更を 1 つのバッチとして送信した場合、すべての変更が正常に適用されるか、または変更がすべて適用されないかのどちらかです。
Azure Table データ サービスを利用する
Windows Azure Table を使用して .NET アプリケーションを開発する場合、データへのアクセスは ADO.NET Data Services のクライアント ライブラリを使用して行われます。ここでは、上で使用したのと同じシンプルなアプリケーションの開発について説明しますが、今回は Azure Table に格納されているデータにアクセスして、それらを操作します。この記事の残りの部分では、Windows Azure Storage アカウントが設定済みで利用できる状態になっているものとします。Windows Azure Table の詳細については、Azure Services Platform デベロッパー センターを参照してください。
Azure Table データ モデル
アプリケーションを使用して作業を行う前に、最適なパフォーマンスを得るための Azure Table データ モデルに関するいくつかの注意点があります。アプリケーションでは、ストレージ アカウント内に多数のテーブルを作成するように選択できます。各テーブルには一連のエンティティ (行) が格納され、各エンティティには一連のプロパティ (列) が格納されます。各エンティティには最大 255 個のプロパティを、<Name, TypedValue> のペアとして格納できます。また、各エンティティは、組み合わせて一意の ID を構成する 2 つのキー プロパティを使用して識別されます。最初のキー プロパティは、パーティション分割を有効にしてスケーラビリティを強化する PartitionKey (文字列型) です。もう 1 つは、パーティション内のエンティティを一意に識別する RowKey (文字列型) です。この 2 つのキー プロパティを除く、残りのプロパティ用の固定スキーマはありません。つまり、アプリケーションでは、維持する必要のあるすべてのスキーマを適用します。
ローカル データベース ストレージと比較した場合、Windows Azure Table に対する開発時における重要な違いの 1 つは、パーティション分割に関する項目です。Azure Table では、アプリケーションはパーティションの粒度を制御するため、アプリケーションのパフォーマンスとスケーラビリティの両方にとってパーティション分割が非常に重要になります。つまり、テーブルではパーティション キー値が同じエンティティをクラスタ化する (エンティティの局所性) ため、PartitionKey プロパティの選択が非常に重要であり、パフォーマンスに影響を及ぼします。最適な PartitionKey を選択するには、アプリケーションで使用される大部分 (またはすべて) のクエリに共通するキーを選択してください。また、パフォーマンスとスケーラビリティは、アプリケーションで使用されるパーティションの数 (PartitionKey の値の数) の影響も同様に受ける可能性があります。パーティションの数が多いほど、サーバーでは負荷をノード間で適切に分散できます。
ADO.NET Data Services のクライアント ライブラリ
次に、ASP.NET Mode View Controller (MVC) を使用して同じマイクロブロギング アプリケーションを構築します。ここでは、Windows Azure Table に格納されているデータを利用するアプリケーションを構築する場合に一般的に発生するいくつかの問題点について詳しく説明します。
オンプレミス データベースと同様に、このアプリケーションには、モデル内の 3 つのエンティティが必要です。このエンティティを Messages テーブル、Channels テーブル、Users テーブルという 3 つのテーブルに変換します。これらのテーブルはすべてストレージ アカウントに設定されます。
アプリケーション全体にわたって、Windows Azure SDK に付属する StorageClient サンプルを利用します。StorageClient サンプルは、Windows Azure BLOB ストレージ サービス、キュー サービス、およびテーブル ストレージ サービスにアクセスするために使用できるライブラリを実装します。ここでは、このライブラリを使用してテーブル ストレージ サービスにアクセスします。Windows Azure SDK は、既に説明した Azure Services Platform デベロッパー センターからダウンロードできます。
まずは、ASP.NET MVC と共にインストールされた Visual Studio テンプレートを使用して新しい ASP.NET MVC Web アプリケーションを作成し、Windows Azure SDK の StorageClient プロジェクトをソリューションに追加します。
クライアントでモデルを定義する
アプリケーション構築の最初の手順では、サービスで公開されるエンティティを表すためにクライアントで使用されるクラスを定義します。Azure Table には固定スキーマがないため、オンプレミス サービスの場合のように、サービス参照の追加ウィザードを使用できません。ただし、既に説明したように、独自の POCO クラスを作成できます。Azure Table はサーバー側でスキーマを適用しないので、これらのクラスはアプリケーションのスキーマを定義する際に効果的に使用されます。ここでは、サービスで公開される EntityTypes に合わせて Message クラス、Channel クラス、および User クラスを定義します。まずは、クラスの定義先の Models フォルダに新しいコード ファイル MicroData.cs を追加します。これらのクラスは、MicroBloggingAzure.Models 名前空間で定義されます。
図 7 の Message クラスを見ると、Azure Table で必要な PartitionKey と RowKey の両方を定義していることがわかります。これらのプロパティは Windows Azure Table に固有であるため、オンプレミス サービスの場合とは異なります。キー決定のベスト プラクティスはリレーショナル ストレージとクラウド ストレージでは推奨されないことに注意してください。サンプル アプリケーションでは、各データ ソースに最適なキー決定を使用しており、2 つのプロパティを無理に対応付けようとはしていません。PartitionKey と RowKey は、単純に文字列型として定義され、名前付け規則 (つまり、それぞれを PartitionKey および RowKey という名前にする規則) を使用して識別されます。このアプリケーションの場合、PartitionKey はメッセージ投稿先のチャネルの名前、"@"、およびメッセージが投稿された日付 (形式は "yyyy-mm-dd") で構成されます。RowKey は、メッセージが投稿された日付の文字列表現です。この PartitionKey は、特定のチャネルに最近投稿されたメッセージをアプリケーションが効率的に取得できるように選択されました。最初は、チャネルへのアクセスが行われると本日の投稿のみを表示するように選択しました。しかし、アプリケーションが広く使用されるようになり 1 日に何千件もの投稿が来るようになった場合は、このキーを簡単に変更して (たとえば、時刻要素 ("時間" など) を追加することにより)、さらに細かくパーティションを分割できます。同様に、予想したほどアプリケーションの使用頻度が高くない場合は、PartitionKey を変更して日単位ではなく月単位でパーティションを分割できます。次に、DataServiceKey 属性をクラスに追加して、2 つのキー プロパティを一意に識別されている DataServiceKey と見なしました。また、Message クラスでは、必須キーの一部であるメッセージの情報を格納するその他のいくつかのプロパティを定義します。メッセージ エンティティに関連付けられているすべてのプロパティは Azure Table に格納されます。User クラスと Channel クラスは、Message クラスと同じ原則に従って作成されます。
図 7 メッセージ エンティティの定義
[DataServiceKey("PartitionKey", "RowKey")] public class Message { // ParitionKey is channel name [+ day] public string PartitionKey { get; set; } // Date/Time when the message was created public string RowKey { get; set; } public string Text { get; set; } public string Author { get; set; } public string Channel { get; set; } public DateTime DatePosted { get; set; } public int Rating { get; set; } public Message() { } public Message(string channel, string author, string text) { this.Text = text; this.Author = author; this.Channel = channel; this.DatePosted = DateTime.UtcNow; this.PartitionKey = MakeKey(this.Channel, this.DatePosted); this.RowKey = System.Xml.XmlConvert.ToString( this.DatePosted); } public static string MakeKey(string channel, DateTime dt) { return channel + "@" + dt.ToString("yyyy-MM-dd"); } }
テーブルを作成する
エンティティ クラスが定義されたら、実際にアプリケーションの開発を開始することができます。ただし、次に示すように、最初に Azure Table アカウントのアクセス情報を Web.config に追加する必要があります。
<appSettings> <add key="TableStorageEndpoint" value="http://table.core.windows.net/"/> <add key="AccountName" value="<MyAccountName>"/> <add key="AccountSharedKey" value="<MyAccountSharedKey-Provided when you register for Azure Tables>"/> </appSettings>
Azure Table に対する開発を行うときにアカウント情報を渡す方法はこれ以外にもありますが、この方法を使用すると、Azure SDK で自動的にアカウント設定を選択し、データ ソースへの接続を処理することができます。
多くの場合、Windows Azure Table に対して記述されたアプリケーションでは、アプリケーションに必要なテーブルの作成が、プログラムを使用してアプリケーション内で行われます。これは、オンプレミス データ ストアで通常行う処理とは少し異なります。オンプレミス データ ストアでは、テーブルがデータベース内で個別に作成され、アプリケーションは単にそれらのテーブルを操作します。
プログラムを使用して必要なテーブルを作成する 1 つの方法として、Tables という名前のマスタ テーブルに単純に新しいエンティティを作成します。ストレージ アカウントに作成するすべてのテーブルは、マスタ テーブル内の (アカウントの登録時に定義済みの) エンティティとして表される必要があります。ただし、このアプリケーションでは、アプリケーションの初期化時に、必要なテーブルがストレージ アカウントに存在することを確認して、存在しない場合は新しく作成する StorageClient を使用します。
アプリケーション内でプログラムを使用してテーブルを作成することにより、データ ソース内のモデルに対する更新を反映するプロセスを簡略化します。たとえば、今後、ユーザーがチャネルをサブスクライブする機能を追加し、モデルにサブスクリプション エンティティを追加する場合は、アプリケーションの次回の起動時に、関連付けられているテーブルがデータ ストアに自動的に追加されます。また、この選択により、別の Azure Table アカウント用にアプリケーションが配布される場合、すべてのユーザーは、自分のアカウントのアクセス情報を入力する必要があります。これで、アプリケーションの実行時にテーブルが正しく設定され、使用できるようになります。
Azure Table に既存のデータがある場合、または Azure でテーブルを制御できない場合は、テーブル作成の手順をスキップして、既存のテーブルに対して単純にプログラミングを行うことができます。
アプリケーションでテーブルを確認して作成するために、StorageClient ライブラリの一部である TableStorage.CreateTablesFromModel() メソッドを次のように使用します。
protected void Application_Start() { RegisterRoutes(RouteTable.Routes); //MVC Routing Rules TableStorage.CreateTablesFromModel (typeof(Models.MicroData)); }
データを照会する
Azure Table のアカウントにアクセスするようにアプリケーションを設定すると、アプリケーションのその他の部分は、オンプレミス サービスにアクセスする場合と同様に機能します。オンプレミス サービスの場合と同様に、ADO.NET Data Service のクライアント ライブラリを使用するので、簡単にデータを .NET オブジェクトとして操作し、LINQ を使用してデータを照会できます (図 8 を参照)。
図 8 LINQ を使用して .NET オブジェクトとしてデータにアクセスする
public ActionResult Index(string channel, string author) { var svc = new Models.MicroData(); ViewData["channels"] = svc.Channels; var q = from m in svc.Messages where m.PartitionKey == Models.Message. MakeKey(channel, DateTime.UtcNow) select m; if (!string.IsNullOrEmpty(author)) { q = from m in q where m.Author == author select m; } ViewData["msg"] = q; return View(); }
図 8 では、ホーム ページ コントローラの Index アクションを使用しています。このアクション内では、サービスへのアクセスに使用するオブジェクトである DataServiceContext の新しいインスタンスを作成し (MicroData は TableStorageDataServiceContext を継承します)、データ サービスに対して実行されるクエリを記述します。次に、利用可能なすべてのチャネルの一覧をデータ サービスから取得し、本日投稿されたすべてのメッセージを取得する LINQ クエリを記述して、ユーザーの入力 (チャネル、および指定されている場合は作成者) を基にフィルタ処理します。ここでは、ページが表示された場合に実行される上記の 2 つのクエリを ViewData に配置して、結果を取得します。この手順は、オンプレミス データ ソースにアクセスした場合と同様です。新しい DataServiceContext インスタンスを作成し、モデルに対して単純な LINQ クエリを使用して照会を行います。
ホーム ページのビュー (図 9 の Index.aspx) で、クエリを列挙して、ストアに対してクエリを実行し、ページに結果を出力します。
図 9 ホーム ページ ビュー
<h2>Today's Messages</h2> <form action="./"> Channel:<span style="color: #FF0000">*</span> <input type="text" name="channel" /><br /> Author: <input type="text" name="author" /><br /> <input type="submit" value="View" /> </form> <ul> <!-- Execute query placed in ViewData["msg"] - enumerates over results and prints resulting message data to the screen --> <% foreach (var m in (IEnumerable<MicroBloggingAzure.Models.Message>) ViewData["msg"]) { %> <li><%=m.Author%>@<%=m.DatePosted %>: <%=m.Text%> [<%=m.Channel %>] </li> <%} %> </ul> <h2>Channels</h2> <ul> <!-- Execute query placed in ViewData["channels"] - enumerates over Results and prints resulting channel data to the screen --> <% foreach (var channel in (IEnumerable<MicroBloggingAzure.Models.Channel>) ViewData["channels"]) { %> <li><%=channel.PartitionKey %> (<%=channel.DateCreated %>)</li> <% } %> </ul>
作成、更新、および削除する
オンプレミス ストアの場合と同様に、ADO.NET Data Service のクライアント ライブラリを使用してテーブル サービスに新しいエンティティ インスタンスを作成するには、エンティティ セットを表す .NET オブジェクトの新しいインスタンスを作成し、AddObject() を呼び出します。
図 10 では、ホーム ページ コントローラの PostMessage アクションを使用しています。
図 10 新しいメッセージを作成してデータ ストアにプッシュする
[AcceptVerbs("POST")] public ActionResult PostMessage(string channel, string author, string msg) { var svc = new Models.MicroData(); var q = from c in svc.Channels where c.PartitionKey == channel select c; if (q.FirstOrDefault() == null) throw new ArgumentException("Invalid channel"); User u = (from auth in svc.Users where auth.UserName == author select auth).FirstOrDefault(); if (u == null) //throw new ArgumentException("Invalid Author"); { var user = new User(); user.UserName = author; user.DateCreated = DateTime.UtcNow; user.PartitionKey = user.UserName; user.RowKey = string.Empty; svc.AddObject("Users", user); u = user; } var m = new Models.Message(channel, author, msg); svc.AddObject("Messages", m); svc.SaveChanges(); return this.RedirectToAction("Index"); }
データ サービスの照会の場合と同様に、エントリ ポイントとして新しい DataServiceContext のインスタンスを作成し、指定されたチャネルを照会して、そのチャネルが存在することを確認します。チャネルが見つからない場合は、例外をスローします。新しいメッセージを作成して、ユーザー入力を渡します。メッセージが作成されたら、追加先の EntitySet の名前である "Messages" および新しい Message オブジェクトである m を渡す svc.AddObject("Messages", m); を呼び出すことで、新しいオブジェクトが追加されるというコンテキストを指定します。最後に、svc.SaveChanges(); を呼び出して、テーブル サービスに変更内容をプッシュします。
この場合、注意が必要な相違点がいくつかあります。まず、Azure Table には固定スキーマがない点です。つまり、厳密に型指定されたデータを使用できないため、オンプレミス ストアの場合に使用した、型指定された AddTo…() メソッドではなく、型指定のない AddObject() を DataServiceContext インスタンスで呼び出して、新しいオブジェクトと追加先のエンティティ セットを渡す必要があります。ここで注意しなければならないのは、オンプレミスのシナリオでは、より汎用的な AddObject() メソッドを使用できるという点です。ただし、今回の例では、厳密に型指定されたメソッドを使用して、コンパイル時のチェックなどを利用します。
2 つ目の違いは、固定スキーマがないことに起因する部分もありますが、最上位のリレーションシップの概念がないという点です。オンプレミス データ ソースと比較した場合の Azure Table のデータの構成方法の違いにより、初めてこの点に気付くと思います。PostMessage アクションでは、新しいオブジェクトにリンクを設定していないことがわかります。つまり、リレーションシップ情報はプロパティとして直接エンティティに格納されます。
新しいインスタンスを作成するのではなく、既存のインスタンスを変更する場合は、更新するオブジェクトを最初に照会し、必要な変更を行います。最後に、オンプレミス データ サービスの場合と同様に、AddObject の代わりに UpdateObject メソッドを呼び出して、次回 SaveChanges() を呼び出すときにそのオブジェクトの更新を送信する必要があるというコンテキストを指定します。同様に、Azure Table サービスとオンプレミス サービスのどちらにアクセスする場合でも、インスタンスを削除するために Delete メソッドを呼び出して、そのオブジェクトを削除するというコンテキストを指定するという方法は同じです。
まとめ
これらの 2 つの例をまとめてみると、オンプレミス サービスに対する開発と Azure Table サービスに対する開発との切り替えが簡単であり、同じ単純な ADO.NET Data Services のクライアント ライブラリを使用するだけで済むことがわかります。それぞれのデータ ソースの管理を担当している場合は、習得に要する時間がさらに少なくて済み、リレーショナル ストレージ モデルと構造化の度合いがより低い Azure Table モデルとの間における思考の転換、および Azure Table の PartitionKey と RowKey のモデルへの対応にほとんどの時間が費やされます。これらのサービスに対するアプリケーション開発に重点を置く場合は、一方のサービスに対する開発のためのスキルを、もう一方のデータ サービスに対する開発に応用できます。
Elisa Flasko は、マイクロソフトのデータ プログラマビリティ チームのプログラム マネージャであり、ADO.NET テクノロジ、XML テクノロジ、SQL Server 接続テクノロジなどを担当しています。blogs.msdn.com/elisaj で彼女のブログをご覧いただけます。