SQL Server 2012 での空間ポイントデータクエリのチューニング (ja-JP)
SQL Server 2012 での空間ポイントデータクエリのチューニング
執筆者: Ed Katibah, Milan Stojic, Michael Rys, Nicholas Dritsas
テクニカルレビュアー: Chuck Heinzelman
紹介
空間ポイントデータクエリでは、パフォーマンスを向上し、アプリケーションの全般的なスループットを上げるための特別なチューニング必要とします。SQL Server 2012 では、その目標達成をアシストするためのいくつかのキーとなる新機能と改善点を取り入れています。
以下に、それらを達成する方法について、いくつかのキーのベストプラクティスと提案を説明します。
主キーのクラスター化インデックス最適化
空間列にインデックスを作成するには、テーブルに主キーが作成されている必要があります。SQL Azure では、各テーブルがクラスター化された主キーを持つという要求によって、この要求を拡張しています。
空間インデックスの基本
1 つのインデックスを含む空間クエリの実行は 2 つの部分 (プライマリフィルタ (空間インデックスのルックアップ) とセカンダリフィルタ (オリジナルの述語)) から成ります。例えば、"STDistance() < x" のようなクエリで SQL Server は、
- セルの候補セットの特定をします。
- 空間インデックスによってインデックスのシークを実行します。 ( プライマリフィルタ )
- 実際の空間オブジェクトを得るための基底となるテーブルと候補となる値を結合します。
- 空間操作の働きにより、明らかに偽であるものをフィルタします。 ( セカンダリフィルタ )
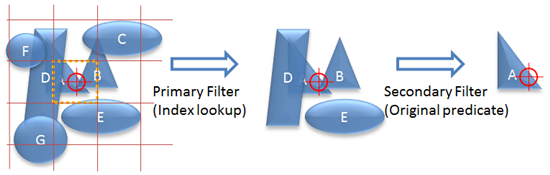
セカンダリフィルタは、STIntersects(@x)=1 の代わりに Filter(@x)=1 の操作をすることで無効にすることができます。クエリパフォーマンスは良くなるはずですが、明らかに偽であるものが入る可能性があります。もし空間クエリが大きすぎないのであれば、HHHH 空間インデックスについて Geography データ型を利用した場合、100-200m あたりが許容範囲になるでしょう。
STDistance(@x) < @range は、Filter(@x.BufferWithTolerance(@range,1,1)) = 1 で置き換えられます。
もし、いくつかの明らかな偽を返すことがオプションではないなら、基底テーブルの IO パフォーマンスは今まで通り最適化出来ます。
全ての空間インデックスは、IO を最小限に抑えるために既に最適化されています。セルは、空間的に近いセルが互いに物理的に近くあるために、特定のパターンに配置されます。以下の画像は、使用される (SQL Server ではヒルベルト空間充填曲線が使用されます ) セルパターンを示しています。

したがって、空間インデックスを介したインデックスシークの読み取りパターンは次のようになるかもしれません。

しかしながら、基底テーブルへの結合のときは、実際の空間オブジェクトを得るために必要とされる、( 基底テーブルの ) クラスター化インデックスシークの IO パターンは次のようになるかもしれません。

この IO パターンは、ディスクからより多くのページを読み取ることになり、空間クエリのパフォーマンスへ大きな影響を与えます。
したがって、クラスター化インデックスシークのためのより良いIOパフォーマンスを得るには、主キーが空間インデックスのセルのパターンと互いに関係性を持つ必要があります。これは、クラスター化インデックスにポイント調整コンポーネントを追加することによって達成されるはずです。
私たちのサンプルデータについて、ポイント列を含むオリジナルのテーブルがどのように特定されるかが、ここにあります。
CREATE TABLE [dbo].[Points] (
[id] [int] NOT NULL,
[type] [int] NOT NULL,
[geo] [geography] NULL,
PRIMARY KEY CLUSTERED (
[id] ASC,
[type] ASC
)
);
空間インデックスは基底テーブルの行へアクセスするために主キーを参照します。基本的なポイント座標の個々の縦座標を組み入れた主キー上に、クラスター化インデックスを作成することによって、クエリパフォーマンスは度々相当に高められるはずです。このテクニックでは、主キーを"空間的に"整列させることで、結果として、空間インデックスによって要求される、基底テーブルデータの行を取り出すために必要とされるディスクシーク量の最小化を可能にします。
時々、個別のポイント座標は、ポイントの列 ( 空間オブジェクト ) に対応する基底テーブル内に独自の列として見つかるはずです。このようなケースでは、個別のポイント縦座標はクラスター化された主キーの DDL で直接参照されるはずです。こうでないケースでは、テーブルスキーマは、基本的なポイント座標の個別の縦座標から成る 2 つの自動的に生成された固定の列を含むために拡張されるはずです。
新しいポイント座標列が、クラスター化された主キーに参照される最初の 2 列に違いないということに注意することが重要です。Geometry 座標では x、y オーダーでしょうし、Geography データでは経度、緯度になるでしょう。
サンプルデータテーブルでは、空間メソッドを使う新しい 2 つの保存される計算列と、それらの 2 列でクラスター化された主キーインデックスを再定義するようにスキーマを展開することが必要です。( 個々の座標を展開するために、ビルトインされたメソッドである Lat と Long を使うことに注目してください。)
CREATE TABLE [dbo].[Points](
[id] [int] NOT NULL,
[type] [int] NOT NULL,
[geog] [geography] NOT NULL,
[geo_lat] AS ([geog].[Lat]) PERSISTED NOT NULL, -- *
[geo_lon] AS ([geog].[Long]) PERSISTED NOT NULL, -- *
PRIMARY KEY CLUSTERED
(
[geo_lat] ASC,
[geo_lon] ASC,
[id] ASC,
[type] ASC
));
* 主キーとして利用するための NOT NULL
ノート: クラスター化キーの最初の列として空間オブジェクトのための x, y / 緯度、経度 座標の永続性は、キーへ 16 バイト追加し、全ての非クラスター化インデックスがテーブルへ追加されるのと同様に、空間インデックス自身もベースとなるテーブルの両方に複製されます。クラスター化インデックスキーの標準的なガイドとしては、出来る限り小さく保つことです。これは、空間インデックスのパフォーマンスを改善する可能性があるにもかかわらず、ユーザーはネガティブな結果をもたらす可能性に気づいておくべきです。
空間インデックスの最適化
既定の空間インデックスは、一般的な空間ワークロードに基づいた、全て MEDIUM にセットされたグリッドを伝統的に推奨しています。これはオリジナルのインデックス定義でした。
CREATE SPATIAL INDEX [table_geog_sidx]
ON [dbo].[table]([geog])
USING GEOGRAPHY_GRID
WITH (GRIDS =(LEVEL_1 = MEDIUM,
LEVEL_2 = MEDIUM,
LEVEL_3 = MEDIUM,
LEVEL_4 = MEDIUM),
CELLS_PER_OBJECT = 16;
空間クエリパフォーマンスは、特定の空間図形や分布のための既定の設定とは異なる空間インデックスオプションを選択することにより、たびたび大幅にに改善できます。座標データの場合は、全てではありませんが、ほとんど場合において、全てのグリッドレベルを HIGH に設定した空間インデックスは他の構成を上回ります。座標データに対応して以来、CELLS_PER_OBJECT 設定は無関係であり、影響なしに (1-8192) の任意の値に設定できます。ここでは、空間インデックスを座標のための最適な設定のグリッドレベルへと再構成しました。全て HIGH にしています。
CREATE SPATIAL INDEX [table_geog_sidx]
ON [dbo].[table]([geog])
USING GEOGRAPHY_GRID
WITH (GRIDS =(LEVEL_1 = HIGH,
LEVEL_2 = HIGH,
LEVEL_3 = HIGH,
LEVEL_4 = HIGH),
CELLS_PER_OBJECT = 16;
geography データ型を使用する場合に、球体地球モデルを利用することの考慮
SQL Azure か SQL Server 2012 を使っている場合、空間の正確さに対する要求度合によっては回転楕円体モデルの利用が必要とされないことがあり、空間座標システムの土台とするための基礎として球体モデルを利用することによって計算が単純になるため、クエリのパフォーマンスが追加で得られる可能性があります。さらに、STDistance()、STLength()、ShortestLineTo() メソッドは、楕円体上よりも球体上で速く実行されるように最適化されます。
SQL Server 2012 や SQL Azure では、単位球面のための新しい仕組みである sys.spatial_reference_systems ビューがあります。この新しいビューは空間参照 ID (SRID) = 104001 を持ち、単位球面がリストされます。
単位球面を利用する場合の出力の、既定の測量単位はラジアンです。メートル法での長さや面積のような実世界の値で計測するために、以下のように希望に応じて出力された球面半径の結果に単純に掛けるようにします。
- 距離の計測 ( 長さ、距離、バッファー距離 ) : 長さ * ( 球面半径 )
- 面積の計測 : 面積 * ( 球面半径 ) * ( 球面半径 )
サンプルデータの場合、オリジナルの座標系は世界測地系 1984 (WGS84: World Geodetic Reference System of 1984) として指定されました。SQL Server と SQL Azure では、これは空間参照 ID (SRID) 4326 として定義されます。これは geography データ型とともに利用するための ほとんど共通の座標系です。(GPS レシーバーがそうであるように、商用の空間データのほとんどはこれらの座標系を利用します。) WGS84 を参照する多くの Web マッピングプログラム (Bing Maps, Google Maps, etc.)では、球面の空間参照座標系 ("Spherical Mercator") を基礎として、半径を 6,378,137 メートルとして扱います。
サンプル空間テーブル内の単位球形参照システムへの各座標オブジェクトの SRID を更新するために、以下の T-SQL を利用できます。(STSrid メソッドを利用していることに注目してください )
UPDATE Points
SET geog.STSrid = 104001
パフォーマンステスト
これらのチューニングの推奨事項をテストするため、顧客のニーズに基づいたシナリオはそれらのデータに沿って利用されました。クエリのスコープのアイディアを提供するために、以下のストアドプロシージャを例として示します。
/****** Object: StoredProcedure [dbo].[TEST] Script Date: 12/13/2011 3:14:50 PM ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
ALTER PROCEDURE [dbo].[TEST]
AS
BEGIN
-- SET NOCOUNT ON added to prevent extra result sets from
-- interfering with SELECT statements.
--set statistics time on
--set statistics IO on
SET NOCOUNT ON;
DECLARE @Location geography,
@continent integer
SELECT @Location = CI.city_center_coordinates,
@continent = CO.continent_id
FROM dbo.geo2_city AS CI
INNER JOIN dbo.geo2_country AS CO ON CO.country_id = CI.country_id
WHERE CI.city_id = 9395
AND CI.rec_status > -1
AND CO.rec_status > -1
SET @location = geography::Point(@location.Lat, @location.Long, 4326)
SELECT GI.geo_id, GI.geo_info.STDistance(@Location)
FROM db_core.dbo.geo_informations2 AS GI with(nolock,
INDEX(SIndx_geography_informations2))
INNER JOIN dbo.product_hotels (nolock) AS PH
ON (PH.hotel_id = GI.geo_id)
WHERE GI.geo_type = 7
AND PH.rec_status = 1
AND PH.region_id = 2
AND GI.geo_info.STDistance(@Location) < 10000
END
話を分かりやすくするため、以下に示す最適化前の T-SQLにて、ストアドプロシージャで使われているコアの空間クエリに注目します。( SQL Server 空間メソッドはハイライトされています ) 。これは、上にある黄色でマークされた T-SQL を指します。
SELECT p.geo_id, p.geo_info.STDistance(@Location)
FROM Points AS p WITH(nolock,
INDEX(SIndx_geography_informations)) –- original, non-optimized index
WHERE GI.geo_info.STDistance(@Location) < 10000 -– 10KM (10,000 meters)
座標系のシステムが SRID=4326 から SRID=104001 へ変更された場合、座標系のシステム単位の変更に対応し、新たに最適化された空間インデックスが利用されることを確実にするために、下に示すクエリへ書き直す必要がありました。
SELECT GI.geo_id, GI.geo_info.STDistance(@Location) * 6378137
FROM Points_UnitSphere AS GI WITH(nolock,
INDEX(geo_info_HHHH_sidx)) –- optimized index
WHERE GI.geo_info.STDistance(@Location) * 6378137 < 10000 – 10KM
WHERE 文の中で乗算するような追加は、クエリプランで空間インデックスが無視される原因になります。 ( 実際、この方式で書かれた場合、クエリコンパイラーは空間インデックスヒントの利用について問題を訴えます。 ) この問題を軽減するために、クエリは以下のように書き換えることができます。
SELECT p.id, p.info.STDistance(@Location) * 6378137
FROM Points_UnitSphere AS p WITH(nolock,
INDEX(geo_info_HHHH_sidx))
WHERE GI.geo_info.STDistance(@Location) < 10000/6378137 -- 10KM
結論
空間ポイントデータのパフォーマンスを改善する可能性のあるテクニックを簡単にまとめると
- ポイントデータのために、"全て HIGH" のマニュアルグリッド空間インデックスを作成する
- セカンダリフィルターをの適用を避けるためにフィルター操作を利用する、もしくは
- ポイント座標コンポーネントを利用するポイントテーブル上で、クラスター化された主キーを作成する
- Geography データ型で、楕円体モデルの代わりに球形地球モデルを利用する
- クエリパフォーマンスを向上させるために spatial_windows_max_cells クエリヒントを使う
最適化の前に、SELECT と WHERE 条件文に SQL Server の STDistance メソッド を使った場合は、平均して 30ms のパフォーマンスを返しました。
( ポイントのクラスター化された主キーがある新しいテーブル、新しいポイントインデックス、そして球形に最適化されたメソッドを利用するという ) 最適化の後、SELECT と WHERE 条件文に SQL Server の STDistance メソッド を使った場合は、平均して18ms のパフォーマンスを返しました。
種別 |
平均(*) 実行時間 (ms) |
オリジナルの空間クエリ |
30 |
最適化された空間クエリ |
18 |
* 各クエリを 1000 回実行した平均時間