この記事では、ファイル システム、回復性の種類、およびサイズの選択など、ワークロードのパフォーマンスと容量のニーズを満たすように クラスターのボリュームを計画する方法に関するガイダンスを提供します。
Note
記憶域スペース ダイレクトでは、一般的に使用するファイル サーバーはサポートされていません。 記憶域スペース ダイレクトでファイル サーバーまたはその他の汎用サービスを実行する必要がある場合は、仮想マシンで構成します。
レビュー:ボリュームとは
ボリュームは、Hyper-V仮想マシン用の VHD または VHDX ファイルなど、ワークロードに必要なファイルを配置する場所です。 ボリュームは記憶域プール内のドライブを組み合わせて、Azure LocalとWindows Serverの背後にあるソフトウェア定義ストレージ テクノロジである 記憶域スペース ダイレクト のフォールト トレランス、スケーラビリティ、およびパフォーマンスの利点を導入します。
Note
"ボリューム" という用語は、クラスター共有ボリューム (CSV) や ReFS などの他の組み込みのWindows機能によって提供される機能を含め、ボリュームとその下の仮想ディスクを共同で指します。 これらの実装レベルの違いを理解することは、記憶域スペース ダイレクトを正常に計画してデプロイするために必要ではありません。

すべてのボリュームは、クラスター内のすべてのサーバーから同時にアクセスできます。 作成されると、すべてのサーバーの C:\ClusterStorage\ に表示されます。

作成するボリュームの数の選択
作成するボリュームの数は、プールのサイズとサポートされる最大ボリューム サイズによって異なります。ノードあたり最小 1 ボリュームです。 この構成により、クラスターはボリューム "所有権" (1 つのサーバーが各ボリュームのメタデータ オーケストレーションを処理) をサーバー間で均等に分散できます。
クラスターあたりのボリュームの総数を 64 ボリュームに制限することをお勧めします。
ファイル システムの選択
記憶域スペース ダイレクトには、新しい Resilient File System (ReFS) を使用することをお勧めします。 ReFS は、仮想化用に構築された主要なファイル システムであり、大幅なパフォーマンスの向上や、データ破損に対する組み込みの保護など、さまざまな利点があります。 Windows Server バージョン 1709 以降のデータ重複除去を含め、ほぼすべての主要な NTFS 機能をサポートしています。 詳細については、ReFS の機能の比較表を参照してください。
ReFS がまだサポートしていない機能をワークロードで必要な場合は、代わりに NTFS を使用できます。
Tip
異なるファイル システムを持つ複数のボリュームを同じクラスター内に共存させることができます。
回復性の種類の選択
記憶域スペース ダイレクトのボリュームは、ドライブやサーバーの障害などのハードウェアの問題から保護し、ソフトウェア更新プログラムなどのサーバー メンテナンス全体で継続的な可用性を実現するための回復性を提供します。
Note
選択できる回復性の種類は、使用するドライブの種類に依存しません。
2 台のサーバーを使用
クラスター内に 2 つのサーバーがある場合、双方向ミラーリングを使用するか、入れ子になった回復性を使用することができます。
双方向ミラーリングでは、すべてのデータのコピーが 2 つ保持され、各サーバーのドライブに 1 つのコピーが保持されます。 そのストレージの効率性は 50% です。1 TB のデータを書き込むには、記憶域プールに少なくとも 2 TB の物理記憶領域容量が必要です。 双方向ミラーリングでは、一度に 1 つのハードウェア障害 (1 台のサーバーまたはドライブ) に安全に対応できます。
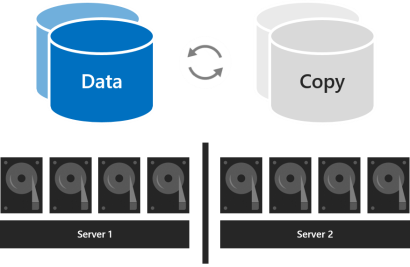
入れ子の回復性では、双方向ミラーリングを使用してサーバー間のデータ回復性が提供され、双方向ミラーリングまたはミラー加速パリティを使用してサーバー内の回復性が強化されます。 入れ子にすると、1 台のサーバーが再起動中または使用できなくなった場合でも、データの回復性が得られます。 そのストレージの効率性は、入れ子になった双方向ミラーリングでは 25%、入れ子になったミラー加速パリティでは約 35% から 40% です。 入れ子の回復性では、一度に 2 つのハードウェア障害 (2 台のドライブ、または 1 台のサーバーと残りのサーバーの 1 台のドライブ) に安全に対応できます。 このようにデータの回復性が強化されているため、2 台のサーバー クラスターの運用環境デプロイでは、入れ子の回復性を使用することをお勧めします。 詳細については、「ネスト化されたレジリエンシー」を参照してください。

3 台のサーバーを使用
3 台のサーバーを使用する場合、フォールト トレランスとパフォーマンスを向上させるためには、3 方向ミラーリングを使用する必要があります。 3 方向ミラーリングでは、すべてのデータのコピーが 3 つ保持され、各サーバーのドライブに 1 つのコピーが保持されます。 そのストレージの効率性は 33.3% です。1 TB のデータを書き込むには、記憶域プールに少なくとも 3 TB の物理記憶領域容量が必要です。 3 方向ミラーリングでは、一度に 2 台以上のハードウェア (ドライブまたはサーバー) に問題が発生した場合でも、安全に対応できます。 2 つのノードが使用できなくなった場合、ディスクの 2/3 が使用できず、仮想ディスクにアクセスできなくなるため、記憶域プールはクォーラムを失います。 ただし、ノードがダウンし、別のノード上の 1 つ以上のディスクに障害が発生しても、仮想ディスクはオンラインのままになります。 たとえば、突然別のドライブまたはサーバーに障害が発生したときに 1 つのサーバーを再起動する場合、すべてのデータは安全で継続的にアクセスできます。

4 台以上のサーバーを使用
4 台以上のサーバーを使用する場合は、各ボリュームに対して、3 方向ミラーリングを使用するか、デュアル パリティ ("イレイジャー コーディング" と呼ばれることも多い) を使用するか、ミラー加速パリティを使用して両方を混在させるかを選択できます。
デュアル パリティでは、3 方向ミラーリングと同じフォールト トレランスが提供されますが、ストレージの効率性が向上します。 4 台のサーバーを使用する場合、そのストレージの効率性は 50.0% です。2 TB のデータを格納するには、記憶域プールに 4 TB の物理記憶領域容量が必要です。 これにより、7 台のサーバーではストレージの効率性が 66.7% まで向上し、最大で 80.0% までストレージの効率性が向上します。 トレードオフは、パリティ エンコードで多くのコンピューティング処理が必要になり、そのパフォーマンスが制限される可能性があることです。

どの耐障害性タイプを使用するかは、環境のパフォーマンスと容量の要件によって異なります。 次の表は、各耐障害性の種類のパフォーマンスとストレージ効率をまとめたものです。
| 回復性の種類 | 容量効率 | Speed |
|---|---|---|
| Mirror |

3 方向ミラー: 33% 双方向ミラー: 50% |

最高のパフォーマンス |
| ミラーアクセラレータパリティ |

ミラーとパリティの比率によって異なる |

ミラーに比べて非常に低速だが、デュアル パリティと比べて速度は最大 2 倍 大規模なシーケンシャル書き込みと読み取りに最適 |
| Dual-parity |

4 サーバー: 50% 16 台のサーバー: 最大 80% |

書き込み時の I/O 待機時間と CPU 使用率が最大 大規模なシーケンシャル書き込みと読み取りに最適 |
パフォーマンスが最も重要な場合
厳密な待機時間の要件があるワークロードや、SQL Server データベースやパフォーマンスに依存する仮想マシンなど、多数のランダム IOPS が混在する必要があるワークロード Hyper-Vは、パフォーマンスを最大化するためにミラーリングを使用するボリュームで実行する必要があります。
Tip
ミラーリングは、他のどの回復性の種類よりも高速です。 ほぼすべてのパフォーマンス例でミラーリングを使用しています。
容量が最も重要な場合
データ ウェアハウスや "コールド" ストレージなど、書き込み頻度の低いワークロードは、ストレージの効率性を最大化するために、デュアル パリティを使用するボリューム上で実行する必要があります。 スケールアウト ファイル サーバー(SoFS)、仮想デスクトップ インフラストラクチャ (VDI)、または高速ドリフトでランダムな I/O トラフィックを大量に生成しない、あるいは最高のパフォーマンスを必要としないものなど、その他の特定のワークロードについても、お客様の判断でデュアル パリティを使用できます。 パリティを使用すると、ミラーリングと比較して、特に書き込み時に CPU 使用率と IO 待機時間が必然的に増加します。
データが一括で書き込まれる場合
アーカイブやバックアップのターゲットなど、大規模なシーケンシャル パスで書き込みを行うワークロードには、もう 1 つのオプションがあります。1 つのボリュームでミラーリングとデュアル パリティを混在させることができます。 書き込みは、最初はミラー化された部分で処理され、その後パリティ部分に徐々に移動します。 これにより、多くのコンピューティング処理を要するパリティ エンコードをより長時間にわたって実行できるようになるため、大量の書き込みが発生したときに、インジェストが高速化され、リソース使用率が低下します。 各部分のサイズを設定するときは、一度に発生する書き込みの量 (毎日 1 回のバックアップなど) がミラー部分に適切に収まるように考慮してください。 たとえば、1 日に 1 回 100 GB を取り込む場合は、150 GB から 200 GB にはミラーリングを使用し、残りはデュアル パリティを使用することを検討してください。
結果として得られるストレージの効率性は、選択した比率によって異なります。
Tip
データ インジェストの途中で書き込みパフォーマンスが急激に低下した場合は、ミラー部分が十分に大きくないか、ミラー加速パリティがそのユース ケースに適していないことを示している可能性があります。 たとえば、書き込みパフォーマンスが 400 MB/秒から 40 MB/秒に低下した場合は、ミラー部分を拡張するか、3 方向ミラーに切り替えることを検討してください。
NVMe、SSD、および HDD を使用するデプロイについて
2 種類のドライブを使用するデプロイでは、高速ドライブがキャッシュを提供する一方で、低速ドライブは容量を提供します。 これは自動的に行われます。詳細については、「記憶域スペース ダイレクト のキャッシュの理解」を参照してください。 このようなデプロイでは、最終的にすべてのボリュームが同じ種類のドライブ (容量ドライブ) に存在します。
3 種類のドライブすべてを使用するデプロイでは、最速のドライブ (NVMe) のみがキャッシュを提供し、2 種類のドライブ (SSD と HDD) は容量を提供することになります。 ボリュームごとに、それをすべて SSD 階層に配置するか、HDD 階層に配置するか、その 2 つにまたがって配置するかを選択できます。
Important
SSD レベルを使用して、パフォーマンスが最も高いワークロードをオール フラッシュに配置することをお勧めします。
ボリュームのサイズの選択
Azure Localでは、各ボリュームのサイズを 64 TB に制限することをお勧めします。
Tip
ファイル サーバーのワークロードに共通することですが、ボリューム シャドウ コピー サービス (VSS) および Volsnap ソフトウェア プロバイダーに依存するバックアップ ソリューションを使用する場合は、ボリュームのサイズを 10 TB に制限すると、パフォーマンスと信頼性が向上します。 新しいHyper-V RCT API や ReFS ブロックの複製やネイティブ SQL バックアップ API を使用するバックアップ ソリューションは、最大 32 TB 以上のパフォーマンスを発揮します。
Footprint
ボリュームのサイズは、それが格納できるデータの量である使用可能な容量を指します。 これは、New-Volume コマンドレットの -Size パラメーターによって提供され、Get-Volume コマンドレットの実行時に Size プロパティに表示されます。
サイズは、ボリュームの フットプリントとは異なり、記憶域プールで占有される物理記憶域の合計容量です。 占有領域は、その回復性の種類によって異なります。 たとえば、3 方向ミラーリングを使用するボリュームの場合、それらのサイズの 3 倍の占有領域になります。
ボリュームの占有領域が記憶域プール内に収まっている必要があります。

容量を予約する
記憶域プールに未割り当て容量を残しておくと、ドライブの障害後に、ボリュームに "インプレース" 修復のための領域が用意され、データの安全性とパフォーマンスが向上します。 十分な容量がある場合は、障害が発生したドライブを交換する前でも、即座のインプレースの並行修復により、ボリュームを完全な回復性まで復元できます。 これは自動的に行われます。
サーバーごとに 1 台の容量ドライブ (最大 4 台のドライブ) に相当するものを予約することをお勧めします。 お客様の判断でさらに予約することもできますが、この最小限の推奨事項により、どのドライブで障害が発生した場合でも、即座のインプレースの並行修復が成功することが確実になります。

たとえば、2 台のサーバーがあり、1 TB の容量ドライブを使用している場合は、プールの 2 x 1 = 2 TB を予約として確保します。 3 台のサーバーと 1 TB の容量ドライブがある場合は、3 × 1 = 3 TB を予約として確保します。 4 台以上のサーバーと 1 TB の容量ドライブがある場合は、4 x 1 = 4 TB を予約として確保します。
Note
3 種類すべて (NVMe + SSD + HDD) のドライブがあるクラスターでは、サーバーごとに 1 つの SSD と 1 つの HDD (それぞれ最大 4 台のドライブ) に相当するものを予約することをお勧めします。
例:容量計画
1 つの 4 サーバー クラスターについて考えてみます。 各サーバーに、いくつかのキャッシュ ドライブと容量用の 16 台の 2 TB ドライブがあります。
4 servers x 16 drives each x 2 TB each = 128 TB
記憶域プール内のこの 128 TB から、4 台のドライブ (8 TB) を確保して、障害発生後に急いでドライブを交換することなく、インプレース修復が行われるようにします。 これにより、ボリュームを作成できるプールに 120 TB の物理記憶領域容量が残ります。
128 TB – (4 x 2 TB) = 120 TB
非常にアクティブなHyper-V仮想マシンをホストするためにデプロイが必要ですが、保持する必要がある古いファイルやバックアップなど、コールド ストレージも多数あるとします。 4 台のサーバーがあるので、4 つのボリュームを作成します。
最初の 2 つのボリューム ( Volume1 と Volume2) に仮想マシンを配置しましょう。 ファイル システムとして ReFS を選択し (より高速な作成とチェックポイントのため)、回復性のために 3 方向ミラーリングを選択してパフォーマンスを最大化します。 他の 2 つのボリューム ( ボリューム 3 とボリューム 4) にコールド ストレージを配置しましょう。 ファイル システムとして NTFS を選択し (データ重複除去のため)、回復性のためにデュアル パリティを選択して容量を最大化します。
すべてのボリュームを同じサイズにする必要はありませんが、わかりやすくするために、たとえば、それらをすべて 12 TB にします。
Volume1 と Volume2 はそれぞれ、12 TB x 33.3% の効率 = 36 TB の物理ストレージ容量を占有します。
Volume3 と Volume4 はそれぞれ、12 TB x 50.0% の効率 = 24 TB の物理ストレージ容量を占有します。
36 TB + 36 TB + 24 TB + 24 TB = 120 TB
4 つのボリュームは、このプールで使用可能な物理記憶領域容量に正確に収まります。 Perfect!

Tip
すべてのボリュームをすぐに作成する必要はありません。 いつでもボリュームを拡張したり、後で新しいボリュームを作成したりすることができます。
わかりやすくするために、この例ではすべて10 進 (10 進法) 単位を使用しています。つまり、1 TB は 1,000,000,000,000 バイトです。 ただし、Windowsのストレージ数量はバイナリ (base-2) 単位で表示されます。 たとえば、各 2 TB ドライブは、Windowsでは 1.82 TiB として表示されます。 同様に、128 TB 記憶域プールは 116.41 TiB と表示されます。 これは想定されています。
Usage
ボリュームの作成を参照してください。
次のステップ
詳細については、以下も参照してください。