クラスターにグラフィックス処理装置 (GPU) を含め、クラスター化された VM で実行されているワークロードに GPU アクセラレーションを提供できます。 GPU アクセラレーションは、1 つ以上の物理 GPU を VM 割り当てることができる Discrete Device Assignment (DDA) または GPU パーティショニングによって提供できます。 クラスター化された VM では、GPU アクセラレーションと、フェールオーバーによる高可用性などのクラスタリング機能を利用できます。
この記事では、クラスター化された VM で GPU を使用して、個別のデバイス割り当てを使用してワークロードに GPU アクセラレーションを提供する方法について説明します。 この記事では、クラスターの準備、クラスター VM への GPU の割り当て、Windows Admin Center と PowerShell を使用してその VM をフェールオーバーする方法について説明します。
Tip
現在、DDA によって提供される GPU を使用した仮想マシン (VM) のライブ マイグレーションはサポートされていませんが、障害が発生した場合は、VM を自動的に再起動して GPU リソースを使用できる場所に配置できます。 クラスター化された VM でライブ マイグレーションを使用する場合 GPU パーティション分割の使用を検討してください。 GPU パーティション分割を使用すると、GPU 全体ではなく GPU の一部を共有できます。 GPU パーティションを使用するタイミングとライブ マイグレーションのサポートの詳細については、仮想 マシンへの GPU のパーティション分割と割り当てに関するページを参照してください。
Prerequisites
クラスター化された VM を備えた GPU の使用を開始する前に、考慮すべき要件と事項がいくつかあります。
Azure Local 2311.2 以降が必要です。
Azure Local 2311.2 以降で GPU を管理する方法については、「 Azure Local 用の GPU を準備する」を参照してください。
- Windows Server 2025 以降を実行する Windows Server フェールオーバー クラスターが必要です。
フェールオーバー クラスタリングと Hyper-V に関する知識が必要です。
クラスター内のすべてのサーバーに、同じメーカー、同じモデルの GPU をインストールする必要があります。
GPU 製造元の指示を確認し、それに従い、クラスター内の各サーバーに必要なドライバーとソフトウェアをインストールします。
ハードウェア ベンダーによっては、GPU ライセンス要件の構成も必要な場合があります。
Windows Admin Center がインストールされているマシンが必要です。 このマシンは、クラスター ノードの 1 つである場合があります。
GPU を割り当てる VM を作成します。 「Discrete Device Assignment を使用したグラフィック デバイスのデプロイ」の指示に従って、キャッシュ動作、停止アクション、およびメモリ マップ I/O (MMIO) プロパティを設定し、VM を DDA 用に準備します。
各サーバーにセキュリティ対策ドライバーをインストールし、GPU を無効にしたうえで、ホストからマウント解除して、各サーバーの GPU を準備します。 このプロセスの詳細については、「Discrete Device Assignment を使用したグラフィックス デバイスのデプロイ」を参照してください。
クラスター内で GPU デバイスを準備するには、「個別のデバイスの割り当てを使用したデバイスのデプロイの計画」に記載されている手順を実行します
VM で十分な MMIO スペースがデバイスに割り当てられていることを確認します。 詳細については、 MMIO スペースを参照してください。
GPU を割り当てる VM を作成します。 「Discrete Device Assignment を使用したグラフィック デバイスのデプロイ」の指示に従って、キャッシュ動作、停止アクション、およびメモリ マップ I/O (MMIO) プロパティを設定し、VM を DDA 用に準備します。
各サーバーにセキュリティ対策ドライバーをインストールし、GPU を無効にしたうえで、ホストからマウント解除して、各サーバーの GPU を準備します。 このプロセスの詳細については、「Discrete Device Assignment を使用したグラフィックス デバイスのデプロイ」を参照してください。
Note
GPU をサポートする Azure ローカル ソリューションがシステムでサポートされている必要があります。 オプションを参照するには、 Azure ローカル カタログにアクセスします。
クラスターを準備する
前提条件が満たされたら、クラスター化された VM で GPU を使用するようにクラスターを準備できます。
クラスターを準備するには、VM への割り当てに使用できる GPU が含まれているリソース プールを作成する必要があります。 クラスターはこのプールを使用して、GPU リソース プールに割り当てられている起動または移動された VM の VM 配置を決定します。
Windows Admin Center を使用して、クラスター化された VM を備えた GPU を使用するようにクラスターを準備するには、次の手順に従います。
クラスターを準備し、GPU リソース プールに VM を割り当てるには、次のようにします。
Windows Admin Center を起動し、 GPU 拡張機能が既にインストールされていることを確認します。
上部のドロップダウン メニューから [クラスター マネージャー ] を選択し、クラスターに接続します。
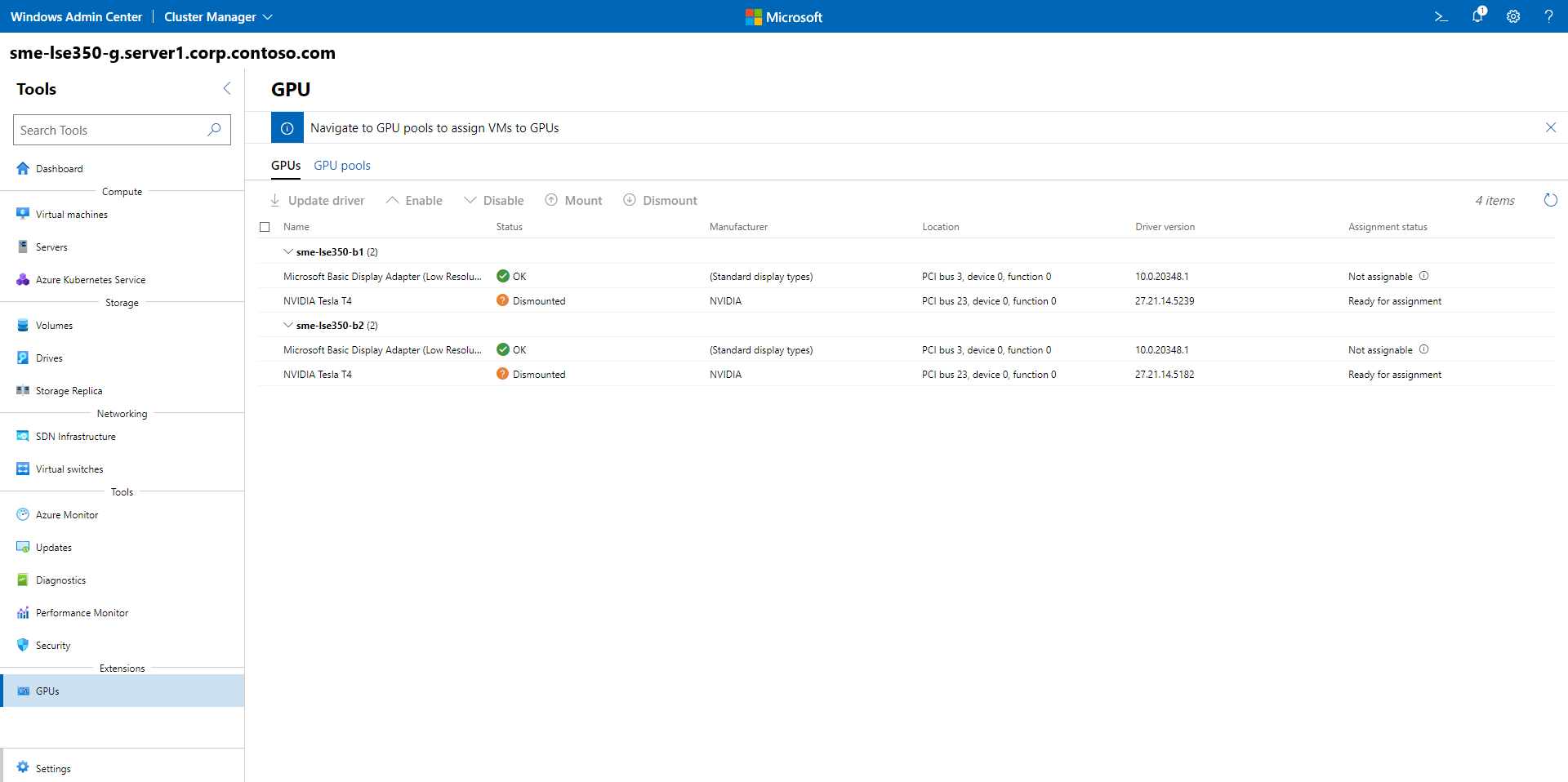
[設定] メニューの [拡張機能>GPU] を選択します。
[ ツール ] メニューの [ 拡張機能] で、GPU を 選択してツールを開きます。
ツールのメイン ページで、[ GPU プール ] タブを選択し、[ GPU プールの作成] を選択します。
![Windows Admin Center の [GPU プールの作成] ページのスクリーンショット。](media/use-gpu-with-clustered-vm/create-gpu-pool.png)
[新しい GPU プール] ページで、次の項目を指定し、[保存] を選択します。
- サーバー 名
- GPU プール 名
- プールに追加する GPU
![サーバー、プール名、および GPU を指定する、Windows Admin Center の [新しい GPU プール] ページのスクリーンショット。](media/use-gpu-with-clustered-vm/new-gpu-pool.png)
プロセスが完了すると、新しい GPU プールの名前とホスト サーバーを示す成功プロンプトが表示されます。

![Windows Admin Center の [GPU プールの作成] ページのスクリーンショット。](media/use-gpu-with-clustered-vm/create-gpu-pool.png#lightbox)
![サーバー、プール名、および GPU を指定する、Windows Admin Center の [新しい GPU プール] ページのスクリーンショット。](media/use-gpu-with-clustered-vm/new-gpu-pool.png#lightbox)
GPU リソース プールへの VM の割り当て
これで、VM を GPU リソース プールに割り当てることができます。 クラスター化された GPU リソース プールに 1 つ以上の VM を割り当てたり、クラスター化された GPU リソース プールから VM を削除したりできます。
Windows Admin Center を使用して既存の VM を GPU リソース プールに割り当てるには、次の手順に従います。
Note
また、VM 内のアプリで、それらに割り当てられている GPU を利用できるように、VM 内に GPU 製造元からのドライバーをインストールする必要もあります。
[GPU プールへの仮想マシンの割り当て] ページで、次を指定してから [割り当て] を選択します。
- サーバー 名
- GPU プール 名
- GPU プールから GPU を割り当てる仮想マシン。
また、メモリ マップ I/O (MMIO) 空間の詳細設定値を定義して、単一の GPU のリソース要件を決定することもできます。
![GPU プールの GPU に VM を割り当てる、Windows Admin Center の [GPU プールへの VM の割り当て] ページのスクリーンショット。](media/use-gpu-with-clustered-vm/assign-vm-to-gpu-pool.png)
プロセスが完了すると、GPU リソース プールから VM に GPU が正常に割り当てられたことを示す確認プロンプトが表示され、[ 割り当てられた VM] に表示されます。
![GPU が VM に割り当てられたことを示す成功プロンプトと、[割り当て済み VM] に表示されている VM のスクリーンショット。](media/use-gpu-with-clustered-vm/gpu-assigned-to-vm-confirmed.png)
![GPU プールの GPU に VM を割り当てる、Windows Admin Center の [GPU プールへの VM の割り当て] ページのスクリーンショット。](media/use-gpu-with-clustered-vm/assign-vm-to-gpu-pool.png#lightbox)
![GPU が VM に割り当てられたことを示す成功プロンプトと、[割り当て済み VM] に表示されている VM のスクリーンショット。](media/use-gpu-with-clustered-vm/gpu-assigned-to-vm-confirmed.png#lightbox)
GPU リソース プールから VM の割り当てを解除するには、次のようにします。
[ GPU プール ] タブで、割り当てを解除する GPU を選択し、[VM の 割り当て解除] を選択します。
[GPU プールからの VM の割り当て解除] ページの [仮想マシン] リスト ボックスで、VM の名前を指定し、[割り当て解除] を選択します。
![割り当てを解除する VM を示す、[GPU プールからの VM の割り当て解除] ページのスクリーンショット。](media/use-gpu-with-clustered-vm/unassign-vm-from-gpu-pool.png)
プロセスが完了すると、VM が GPU プールから割り当てられていないことを示す成功プロンプトが表示され、[ 割り当て] の状態 で GPU に [使用可能 (未割り当て)] と表示されます。
![割り当てを解除する VM を示す、[GPU プールからの VM の割り当て解除] ページのスクリーンショット。](media/use-gpu-with-clustered-vm/unassign-vm-from-gpu-pool.png#lightbox)
VM を起動すると、クラスターは、このクラスター全体のプールから利用可能な GPU リソースを持つサーバーに VM が配置されるようにします。 さらにクラスターによって、DDA を介して GPU が VM に割り当てられます。これにより、VM 内のワークロードから GPU にアクセスできるようになります。
割り当てられた GPU による VM のフェールオーバー
GPU ワークロードをフェールオーバーするクラスターの機能をテストするには、割り当てられた GPU で VM が実行されているサーバーでドレイン操作を実行します。 サーバーでドレイン操作を実行すると、作成したプール内の使用可能なリソースが別のサーバーにある限り、クラスターはクラスター内の別のサーバーで VM を再起動します。
サーバーをドレインするには、「フェールオーバー クラスターのメンテナンス手順」の手順に従います。 作成したプール内の別のサーバーに使用可能な GPU リソースが十分ある限り、クラスターはクラスター内の別のサーバー上で VM を再起動します。
GPU ワークロードをフェールオーバーするクラスターの機能をテストするには、割り当てられた GPU で VM が実行されているサーバーでドレイン操作を実行します。 サーバーでドレイン操作を実行すると、作成したプール内の使用可能なリソースが別のサーバーにある限り、クラスターはクラスター内の別のサーバーで VM を再起動します。
サーバーをドレインするには、「フェールオーバー クラスターのメンテナンス手順」の手順に従います。 作成したプール内の別のサーバーに使用可能な GPU リソースが十分ある限り、クラスターはクラスター内の別のサーバー上で VM を再起動します。
関連コンテンツ
クラスター化された VM を備えた GPU の使用の詳細については、次を参照してください。
VM と GPU パーティション分割で GPU を使用する方法について詳しくは、次をご覧ください。