多変量異常検出モデルをトレーニングする
重要
2023 年 9 月 20 日以降は、新しい Anomaly Detector リソースを作成できなくなります。 Anomaly Detector サービスは、2026 年 10 月 1 日に廃止されます。
多変量異常検出をすばやくテストするには、コード サンプルをお試しください。 Jupyter Notebook の実行方法の詳細については、Jupyter Notebook のインストールと実行に関する記事を参照してください。
API の概要
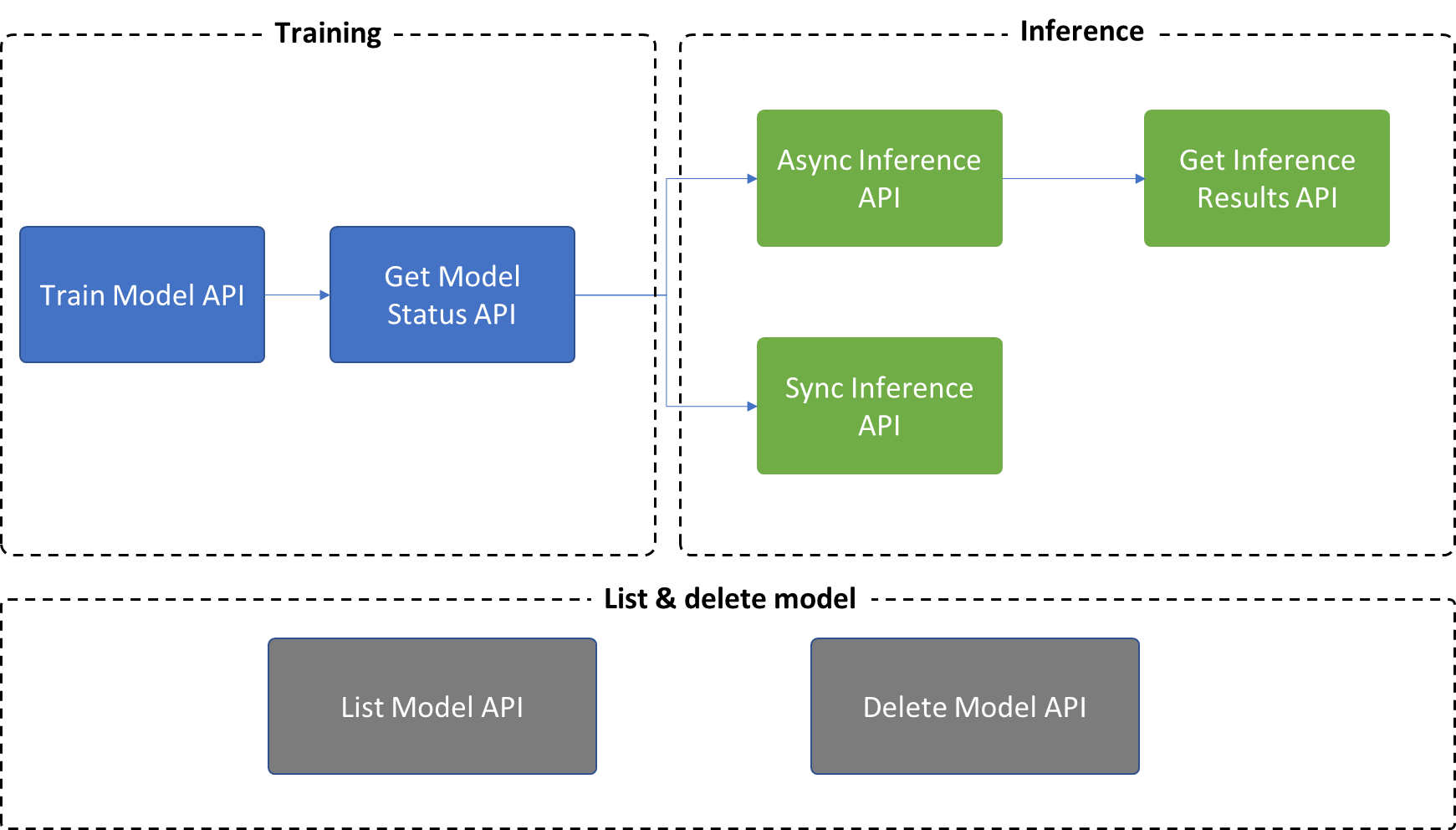
多変量異常検出には、次の 7 つの API が用意されています。
- トレーニング:
Train Model APIを使用してモデルを作成およびトレーニングし、Get Model Status APIを使用 して状態とモデルのメタデータを取得します。 - 推論:
Async Inference APIを使用して非同期推論プロセスをトリガーし、Get Inference results APIを使用してデータのバッチで検出結果を取得します。Sync Inference APIを使用して、毎回 1 つのタイムスタンプで検出をトリガーすることもできます。
- その他の操作:
List Model APIとDelete Model APIは、モデル管理用の多変量異常検出モデルでサポートされています。
| API 名 | 方法 | Path | 説明 |
|---|---|---|---|
| モデルのトレーニング | POST | {endpoint}/anomalydetector/v1.1/multivariate/models |
モデルを作成してトレーニングする |
| モデルの状態の取得 | GET | {endpoint}anomalydetector/v1.1/multivariate/models/{modelId} |
modelId を使用してモデルの状態とモデル メタデータを取得します |
| バッチ推論 | POST | {endpoint}/anomalydetector/v1.1/multivariate/models/{modelId}: detect-batch |
バッチ シナリオで動作する modelId を使用して非同期推論をトリガーします |
| バッチ推論の結果を取得する | GET | {endpoint}/anomalydetector/v1.1/multivariate/detect-batch/{resultId} |
resultId を使用してバッチ推論の結果を取得します |
| ストリーミング推論 | POST | {endpoint}/anomalydetector/v1.1/multivariate/models/{modelId}: detect-last |
ストリーミング シナリオで動作する modelId を使用して同期推論をトリガーします |
| モデルの一覧表示 | GET | {endpoint}/anomalydetector/v1.1/multivariate/models |
すべてのモデルを一覧表示します |
| モデルの削除 | DELET | {endpoint}/anomalydetector/v1.1/multivariate/models/{modelId} |
modelId を使用してモデルを削除します |
モデルをトレーニングする
このプロセスでは、前に作成した次の情報を使用します。
- Anomaly Detector リソースのキー
- Anomaly Detector リソースのエンドポイント
- Anomaly Detector リソースの BLOB URL
トレーニング データ サイズに関しては、タイムスタンプの最大数が 1000000 個で、推奨される最小数が 5000 個です。
Request
多変量異常検出モデルをトレーニングするためのサンプル要求の本文を次に示します。
{
"slidingWindow": 200,
"alignPolicy": {
"alignMode": "Outer",
"fillNAMethod": "Linear",
"paddingValue": 0
},
"dataSource": "{{dataSource}}", //Example: https://mvaddataset.blob.core.windows.net/sample-onetable/sample_data_5_3000.csv
"dataSchema": "OneTable",
"startTime": "2021-01-01T00:00:00Z",
"endTime": "2021-01-02T09:19:00Z",
"displayName": "SampleRequest"
}
必須のパラメーター
API 要求のトレーニングと推論には、次の 3 つのパラメーターが必要です。
- dataSource: これは、Azure Blob Storage にあるフォルダーまたは CSV ファイルにリンクされた BLOB URL です。
- dataSchema: これは、使用しているスキーマ (
OneTableまたはMultiTable) を示します。 - startTime: トレーニングまたは推論に使用されるデータの開始時刻。 データに実際にある最も早いタイムスタンプより前である場合は、その実際にある最も早いタイムスタンプが開始ポイントとして使用されます。
- endTime: トレーニングまたは推論に使用されるデータの終了時刻。この値は、
startTime以降である必要があります。endTimeがデータに実際にある最も遅いタイムスタンプよりも後である場合は、その実際にある最も遅いタイムスタンプが終了ポイントとして使用されます。endTimeがstartTimeに等しい場合は、ストリーミングのシナリオでよく使用される、1 つのデータ ポイントの推論を意味します。
省略可能なパラメーター
トレーニング API のその他のパラメーターは省略可能です。
slidingWindow: 異常を特定するために使用されるデータポイントの数。 28 から 2,880 の整数値です。 既定値は、300 です。
slidingWindowがモデル トレーニングのkである場合、有効な結果を得るには、推論時にソース ファイルから少なくともkポイントにアクセスできる必要があります。多変量の異常検出では、データ ポイントのセグメントを取得し、次のデータ ポイントが異常かどうかを判断します。 セグメントの長さは
slidingWindowです。slidingWindow値を選択する場合は、次の 2 つの点にご注意ください。- データのプロパティ: 周期的であり、サンプリング レートであるかどうか。 データが周期的な場合は、1 から 3 サイクルの長さを
slidingWindowとして設定できます。 分レベルまたは秒レベルのように、データの頻度が高すぎる (細分性が小さい) 場合は、slidingWindowに比較的高い値を設定できます。 - トレーニング/推論時間と潜在的なパフォーマンスへの影響のトレードオフ。
slidingWindowが大きいほど、トレーニング/推論時間が長くなる場合があります。slidingWindowが大きいほど、精度が向上するという保証はありません。slidingWindowが小さい場合、モデルを最適解に収束させるのが困難になる場合があります。 たとえば、slidingWindowに 2 つのポイントしかない場合、異常を検出するのは困難です。
- データのプロパティ: 周期的であり、サンプリング レートであるかどうか。 データが周期的な場合は、1 から 3 サイクルの長さを
alignMode: タイムスタンプに複数の変数 (時系列) を配置する方法。 このパラメーターには、
InnerとOuterという 2 つのオプションがあり、既定値はOuterです。このパラメーターは、変数のタイムスタンプ シーケンス間に不整合がある場合に重要です。 このモデルでは、さらに処理する前に、変数を同じタイムスタンプ シーケンスに配置する必要があります。
Innerの場合、モデルでは、すべての変数に値 (つまり、すべての変数の交点) を持つタイムスタンプに対してのみ、検出結果がレポートされます。Outerの場合、モデルでは、すべての変数に値 (つまり、すべての変数の和集合) を持つタイムスタンプに対してのみ、検出結果がレポートされます。ここでは、さまざまな
alignModel値を説明するために例を示します。"変数-1"
timestamp value 2020-11-01 1 2020-11-02 2 2020-11-04 4 2020-11-05 5 "変数-2"
timestamp value 2020-11-01 1 2020-11-02 2 2020-11-03 3 2020-11-04 4 "2 つの変数の
Inner結合"timestamp Variable-1 変数-2 2020-11-01 1 1 2020-11-02 2 2 2020-11-04 4 4 "2 つの変数の
Outer結合"timestamp Variable-1 変数-2 2020-11-01 1 1 2020-11-02 2 2 2020-11-03 nan3 2020-11-04 4 4 2020-11-05 5 nanfillNAMethod: マージされたテーブルで
nanを埋める方法。 マージされたテーブルに不足値がある場合は、適切に処理する必要があります。 これらを埋めるには、いくつかの方法があります。 オプションはLinear、Previous、Subsequent、Zero、Fixedで、既定値はLinearです。オプション Method Linearnan値を線状補間で埋めるPrevious最後に有効だった値を伝達してギャップを埋める。 例: [1, 2, nan, 3, nan, 4]->[1, 2, 2, 3, 3, 4]Subsequent次に有効な値を使用して、ギャップを埋める。 例: [1, 2, nan, 3, nan, 4]->[1, 2, 3, 3, 4, 4]Zero0 で nan値を埋める。FixedpaddingValueで指定した有効な指定値でnan値を埋める。paddingValue: パディング値は
fillNAMethodがFixedであり、その場合に指定する必要があるときにnanを埋めるために使用されます。 その他の場合は、省略可能です。displayName: これは、モデルを識別するために使用される省略可能なパラメーターです。 たとえば、パラメーター、データ ソース、およびモデルとその入力データに関するその他のメタデータをマークするために使用できます。 既定値は空の文字列です。
Response
応答内で最も重要なのは、Get Model Status API をトリガーするために使用する modelId です。
応答のサンプル:
{
"modelId": "09c01f3e-5558-11ed-bd35-36f8cdfb3365",
"createdTime": "2022-11-01T00:00:00Z",
"lastUpdatedTime": "2022-11-01T00:00:00Z",
"modelInfo": {
"dataSource": "https://mvaddataset.blob.core.windows.net/sample-onetable/sample_data_5_3000.csv",
"dataSchema": "OneTable",
"startTime": "2021-01-01T00:00:00Z",
"endTime": "2021-01-02T09:19:00Z",
"displayName": "SampleRequest",
"slidingWindow": 200,
"alignPolicy": {
"alignMode": "Outer",
"fillNAMethod": "Linear",
"paddingValue": 0.0
},
"status": "CREATED",
"errors": [],
"diagnosticsInfo": {
"modelState": {
"epochIds": [],
"trainLosses": [],
"validationLosses": [],
"latenciesInSeconds": []
},
"variableStates": []
}
}
}
モデルの状態を取得する
上記の API を使用してトレーニングをトリガーし、Get model status API を使用して、モデルが正常にトレーニングされているかどうかを確認できます。
Request
要求本文にコンテンツはありません。必要なのは API パスに modelId を配置することだけです。これは、{{endpoint}}anomalydetector/v1.1/multivariate/models/{{modelId}} の形式になります。
Response
- status: 応答本文の
statusは、CREATED、RUNNING、READY、FAILED というカテゴリによるモデルの状態を示します。 - trainLosses および validationLosses: モデルのパフォーマンスを示す、機械学習の 2 つの概念です。 数値が減少し、最後に 0.2、0.3 のような比較的小さい数値になる場合は、モデルのパフォーマンスがある程度良好であることを意味します。 ただし、それでも推論とラベルとの比較 (存在する場合) を使用して、モデルのパフォーマンスを検証する必要があります。
- epochIds: モデルが、合計 100 エポックのうち、何回のエポックをトレーニング済みであるかを示します。 たとえば、モデルがまだトレーニング状態の場合、
epochIdが[10, 20, 30, 40, 50]であれば、50 回目のトレーニング エポックが完了しているため、半分完了していることを意味します。 - latenciesInSeconds: エポックごとに時間コストが含まれており、10 エポックごとに記録されます。 この例では、10 回目のエポックは約 0.34 秒です。 これは、トレーニングの完了時間を見積もる場合に役立ちます。
- variableStates: は、各変数に関する情報の概要を示します。 これは
filledNARatioにより降順で順位付けされたリストです。 各変数にいくつのデータ ポイントが使用されているかを示し、filledNARatioはいくつのポイントが欠けているかを示します。 通常、できる限りfilledNARatioを小さくする必要があります。 欠落しているデータ ポイントが多すぎると、モデルの精度が低下します。 - errors: データ処理中のエラーは
errorsフィールドに含まれます。
応答のサンプル:
{
"modelId": "09c01f3e-5558-11ed-bd35-36f8cdfb3365",
"createdTime": "2022-11-01T00:00:12Z",
"lastUpdatedTime": "2022-11-01T00:00:12Z",
"modelInfo": {
"dataSource": "https://mvaddataset.blob.core.windows.net/sample-onetable/sample_data_5_3000.csv",
"dataSchema": "OneTable",
"startTime": "2021-01-01T00:00:00Z",
"endTime": "2021-01-02T09:19:00Z",
"displayName": "SampleRequest",
"slidingWindow": 200,
"alignPolicy": {
"alignMode": "Outer",
"fillNAMethod": "Linear",
"paddingValue": 0.0
},
"status": "READY",
"errors": [],
"diagnosticsInfo": {
"modelState": {
"epochIds": [
10,
20,
30,
40,
50,
60,
70,
80,
90,
100
],
"trainLosses": [
0.30325182933699,
0.24335388161919333,
0.22876543213020673,
0.2439815090461211,
0.22489577260884372,
0.22305156764659015,
0.22466289590705524,
0.22133831883018668,
0.2214335961775346,
0.22268397090109912
],
"validationLosses": [
0.29047123109451445,
0.263965221366497,
0.2510373182971068,
0.27116744686858824,
0.2518718700216274,
0.24802495975687047,
0.24790137705176768,
0.24640804830223623,
0.2463938973166726,
0.24831805566344597
],
"latenciesInSeconds": [
2.1662967205047607,
2.0658926963806152,
2.112030029296875,
2.130472183227539,
2.183091640472412,
2.1442034244537354,
2.117824077606201,
2.1345198154449463,
2.0993552207946777,
2.1198465824127197
]
},
"variableStates": [
{
"variable": "series_0",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
},
{
"variable": "series_1",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
},
{
"variable": "series_2",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
},
{
"variable": "series_3",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
},
{
"variable": "series_4",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
}
]
}
}
}
モデルを一覧表示する
要求 URL と要求ヘッダーについては、このページを参照してください。 更新時間順に 10 個のモデルのみが返されていることに注意してください。ただし、要求 URL で $skip と $top のパラメーターを設定することで、他のモデルにアクセスできます。 たとえば、要求 URL が https://{endpoint}/anomalydetector/v1.1/multivariate/models?$skip=10&$top=20 の場合は、最新の 10 個のモデルをスキップし、次の 20 個のモデルが返されます。
応答のサンプルは次のとおりです
{
"models": [
{
"modelId": "09c01f3e-5558-11ed-bd35-36f8cdfb3365",
"createdTime": "2022-10-26T18:00:12Z",
"lastUpdatedTime": "2022-10-26T18:03:53Z",
"modelInfo": {
"dataSource": "https://mvaddataset.blob.core.windows.net/sample-onetable/sample_data_5_3000.csv",
"dataSchema": "OneTable",
"startTime": "2021-01-01T00:00:00Z",
"endTime": "2021-01-02T09:19:00Z",
"displayName": "SampleRequest",
"slidingWindow": 200,
"alignPolicy": {
"alignMode": "Outer",
"fillNAMethod": "Linear",
"paddingValue": 0.0
},
"status": "READY",
"errors": [],
"diagnosticsInfo": {
"modelState": {
"epochIds": [
10,
20,
30,
40,
50,
60,
70,
80,
90,
100
],
"trainLosses": [
0.30325182933699,
0.24335388161919333,
0.22876543213020673,
0.2439815090461211,
0.22489577260884372,
0.22305156764659015,
0.22466289590705524,
0.22133831883018668,
0.2214335961775346,
0.22268397090109912
],
"validationLosses": [
0.29047123109451445,
0.263965221366497,
0.2510373182971068,
0.27116744686858824,
0.2518718700216274,
0.24802495975687047,
0.24790137705176768,
0.24640804830223623,
0.2463938973166726,
0.24831805566344597
],
"latenciesInSeconds": [
2.1662967205047607,
2.0658926963806152,
2.112030029296875,
2.130472183227539,
2.183091640472412,
2.1442034244537354,
2.117824077606201,
2.1345198154449463,
2.0993552207946777,
2.1198465824127197
]
},
"variableStates": [
{
"variable": "series_0",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
},
{
"variable": "series_1",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
},
{
"variable": "series_2",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
},
{
"variable": "series_3",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
},
{
"variable": "series_4",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
}
]
}
}
}
],
"currentCount": 42,
"maxCount": 1000,
"nextLink": ""
}
応答には、models、currentCount、maxCount、nextLink の 4 つのフィールドが含まれています。
- models: これには、作成時刻、最終更新時刻、モデル ID、表示名、変数の数、各モデルの状態が含まれます。
- currentCount: これには、Anomaly Detector リソース内のトレーニング済みの多変量モデルの数が含まれます。
- maxCount: Anomaly Detector リソースでサポートされるモデルの最大数。これは、選択した価格レベルによって区別されます。
- nextLink: この API 応答に一覧表示されるモデルの最大数は 10 であるため、これを追加のモデルをフェッチするために使用できます。