Custom Vision のモデルを改善する方法
このガイドでは、Custom Vision のモデルの品質を向上させる方法について説明します。 分類子またはオブジェクト検出器の品質は、提供するラベル付きデータの量、品質、多様性や、データセット全体のバランスがどれだけとれているかに依存します。 適切なモデルには、そのモデルに送信されるものを代表する、バランスのとれたトレーニング データセットがあります。 このようなモデルを構築するプロセスは反復的です。予想される結果に到達するために、数回のトレーニングが必要になることが一般的です。
より正確なモデルのトレーニングに役立つ一般的なパターンを次に示します。
- 1 回目のトレーニング
- さらに画像を追加し、データのバランスをとる。再トレーニング
- 背景、照明、オブジェクト サイズ、カメラ アングル、スタイルがさまざまな画像を追加する。再トレーニング
- 新しい画像を使用して予測をテストする
- 予測結果に従って、既存のトレーニング データを変更する
オーバーフィットを防ぐ
モデルは、画像に共通するなんらかの特徴をもとに予測を行うよう学習することもあります。 たとえば、リンゴと柑橘類の分類器を作成する場合、手に持ったリンゴと白い皿に乗った柑橘類の画像を使用すると、分類器ではリンゴと柑橘類ではなく、手と皿が過度に重視される可能性があります。
この問題を解決するには、さまざまな角度、背景、オブジェクトのサイズ、グループ、その他のバリエーションを含む画像を用意します。 次のセクションでは、これらの概念について詳しく説明します。
データの数量
トレーニング画像の数は、データセットの最も重要な要素です。 開始点としてラベルごとに少なくとも 50 個の画像を使用することをお勧めします。 画像が少ないほど、オーバー フィットのリスクが高くなり、パフォーマンスの数値は良い品質を示すことがありますが、実際のデータの処理に苦労する可能性があります。
データのバランス
トレーニング データの相対量を考慮することも重要です。 たとえば 1 つのラベルに 500 個の画像を使用し、別のラベルに 50 個の画像を使用すると、不均衡なトレーニング データセットになります。 これにより、あるラベルが他のラベルより、モデルの予測が正確になります。 画像が最も少ないラベルと画像が最も多いラベルの間で少なくとも 1:2 の比率を維持すれば、より優れた結果が得られる可能性があります。 たとえば、画像が最も多いラベルに 500 個の画像がある場合、画像が最も少ないラベルにはトレーニングのために少なくとも 250 個の画像が必要です。
データの多様性
通常の使用中に分類子に送信されるものを代表する画像を使用してください。 そうしないと、モデルは、画像が共通して持つ任意の特性に基づいて予測を行うように学習する可能性があります。 たとえば、リンゴと柑橘類の分類器を作成する場合、手に持ったリンゴと白い皿に乗った柑橘類の画像を使用すると、分類器ではリンゴと柑橘類ではなく、手と皿が過度に重視される可能性があります。

この問題を解決するには、多様な画像を含めて、モデルが十分に汎用化できるようにします。 トレーニング セットをより多様にするために実行できるいくつかの方法を次に示します。
背景: さまざまな背景の前のオブジェクトの画像を提供します。 自然な背景の写真は、分類子により詳細な情報を提供するため、無彩色の背景の写真より優れています。

照明: 特に、予測に使用される画像にさまざまな照明が含まれている場合は、照明が多様な (たとえば、フラッシュで撮られた、露出が高いなど) 画像を提供します。 これはまた、彩度、色相、および輝度が多様な画像を使用するためにも役立ちます。

オブジェクト サイズ: オブジェクトのサイズと数がさまざまに異なる画像を提供します (1 束のバナナや 1 本のバナナのクローズ アップの写真など)。 さまざまなサイズは、分類子がより適切に一般化するのに役立ちます。

カメラ アングル: さまざまなカメラ アングルで撮られた画像を提供します。 また、写真を固定カメラ (監視カメラなど) で撮影しなければならない場合は、オーバーフィット、つまり関連のないオブジェクト (街灯など) が重要な特徴として解釈されないよう、頻出するオブジェクトには、必ず異なるラベルを割り当てるようにしてください。

スタイル: 同じクラスの異なるスタイル (同じ果物の異なる種類など) の画像を提供します。 ただし、スタイルが極端に異なるオブジェクトの画像 (たとえば、ミッキー マウスに対して実物のネズミ) がある場合は、その個別の特徴をより適切に表すために、それらに別のクラスとしてラベルを付けることをお勧めします。

否定画像 (分類子のみ)
画像分類子を使用する場合、分類子をより正確にするために、"否定的サンプル" の追加が必要になることがあります。 否定的サンプルとは、他のどのタグとも一致しない画像です。 これらの画像をアップロードするときには、画像に特殊な 否定用 ラベルを適用します。
描画された境界ボックス外のすべての画像領域が否定と見なされるため、オブジェクト検出器は、否定的サンプルを自動的に処理します。
Note
Custom Vision サービスは、イメージの自動否定処理をいくつかサポートしています。 たとえば、ブドウとバナナを区別する分類子を構築しており、予測のために片方の靴の画像を送信した場合、その分類子はブドウとバナナの両方について、その画像に 0% に近いスコアを付けるはずです。
これに対して、否定画像がトレーニングで使用された画像の変動にすぎない場合は、その大きな類似点のために、モデルがその否定画像をラベル付きのクラスとして分類する可能性があります。 たとえば、オレンジとグレープフルーツを区別する分類子があり、クレメンタインの画像を取り込んだ場合、クレメンタインの多くの特徴がオレンジの特徴と似ているため、その分類子はクレメンタインにオレンジとしてスコアを付ける可能性があります。 否定画像がこれと同じ性質である場合は、1 つ以上の追加のタグ (その他など) を作成し、トレーニング中に否定画像にこのタグのラベルを付けて、モデルがこれらのクラスをより適切に区別できるようにすることをお勧めします。
遮りと切り取り (オブジェクト検出器のみ)
オブジェクト検出器で、切り取られたオブジェクト (画像から部分的に切り取られているオブジェクト)、または遮られたオブジェクト (画像内の別のオブジェクトによって部分的に遮られているオブジェクト) を検出する場合は、そのようなケースに対応するトレーニング画像を含める必要があります。
Note
他のオブジェクトによって遮られているオブジェクトの問題は、モデルのパフォーマンスを評価するためのパラメーターであるオーバーラップのしきい値と混同しないようにする必要があります。 Custom Vision Web サイトの [Overlap Threshold](オーバーラップのしきい値) スライダーは、予測される境界ボックスと、正しいと見なす実際の境界ボックスをどの程度オーバーラップさせる必要があるかを扱います。
追加のトレーニングに予測画像を使用する
予測エンドポイントに画像を送信することによってモデルを使用またはテストすると、Custom Vision Service は、それらの画像を保存します。 それらを使用して、モデルを改善できます。
モデルに送信された画像を表示するには、Custom Vision Web ページを開き、プロジェクトに移動し、 [予測] タブを選択します。既定のビューには、現在のイテレーションのイメージが表示されます。 [Iteration](イテレーション) ドロップ ダウン メニューを使用すると、以前のイテレーションで送信されたイメージを表示できます。
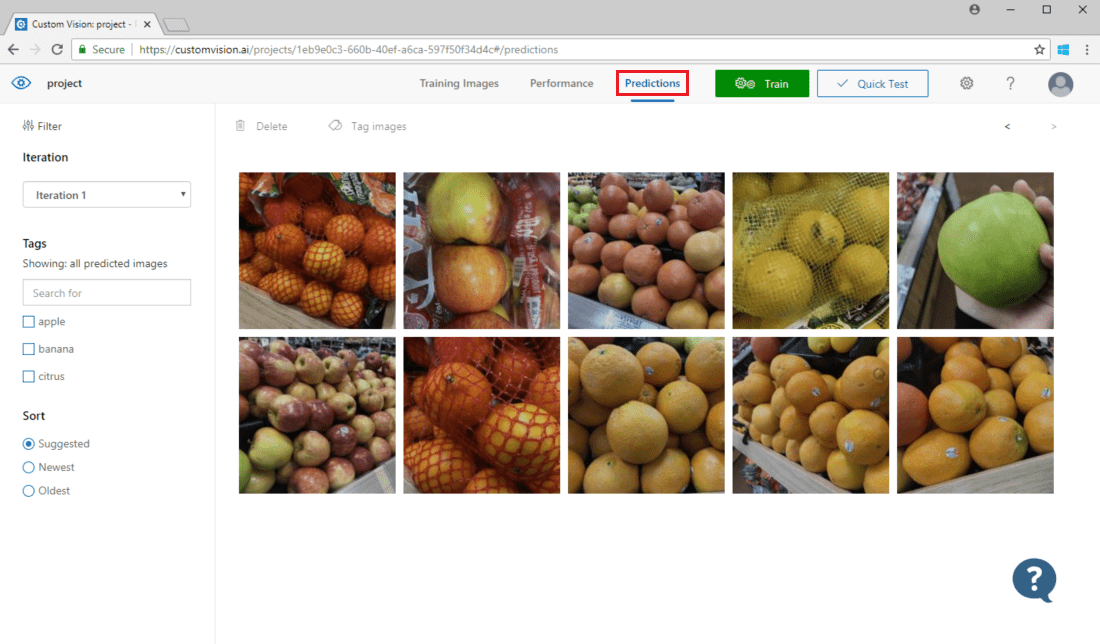
画像にマウス ポインターを合わせ、モデルが予測したタグを表示します。 画像が並べ替えられ、モデルを最も改善できる画像が上部に一覧表示されます。 さまざまな並べ替え方法を使用するには、 [並べ替え] セクションで選択します。
既存のトレーニング データに画像を追加するには、画像を選択し、正しいタグを設定して [保存して閉じる] を選択します。 画像が [予測] から削除され、一連のトレーニング画像に追加されます。 [Training Images] (トレーニング イメージ) タブを選択すると、これを表示できます。
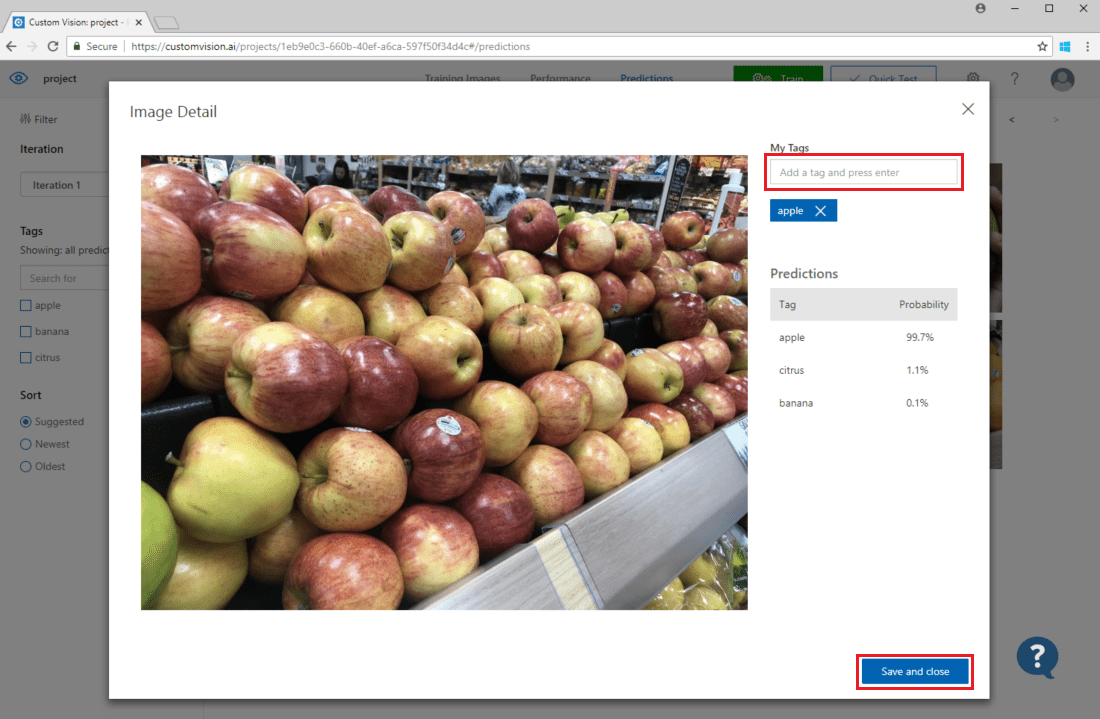
次に、 [トレーニング] ボタンを使用して、モデルを再トレーニングします。
予測を視覚的に検査する
画像の予測を検査するには、 [Training Images](トレーニング イメージ) タブで、 [Iteration](イテレーション) ドロップダウン メニューから以前のトレーニング イテレーションを選択し、 [タグ] セクションで 1 つまたは複数のタグをチェックします。 ビューでは、モデルが特定のタグを正しく予測できなかった各画像の周囲に赤いボックスが表示されているはずです。
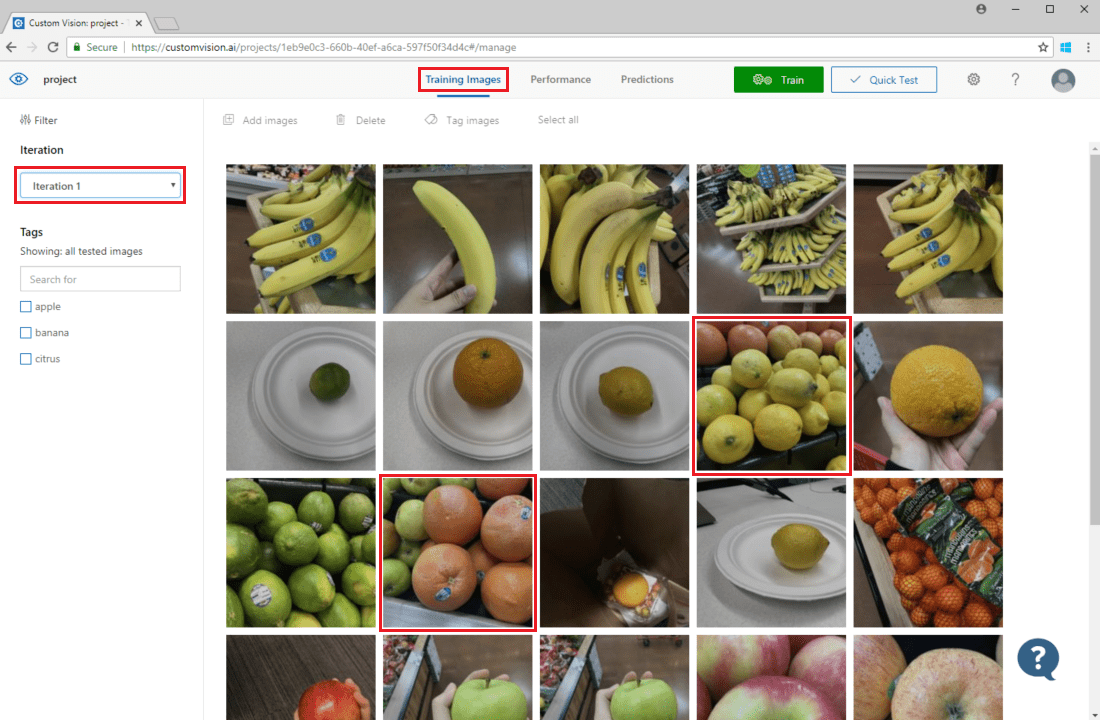
視覚的な検査により、その後でさらにトレーニング データを追加するか、または既存のトレーニング データを変更することによって修正できるパターンを識別できる場合があります。 たとえば、リンゴとライムを区別する分類子によって、すべての緑色のリンゴに誤ってライムとしてラベルが付けられる可能性があります。 この問題は、緑色のリンゴのタグ付きの画像を含むトレーニング データを追加および提供することによって修正できます。
次のステップ
このガイドでは、カスタム画像分類子モデルまたはオブジェクト検出器モデルをより正確にするための技法をいくつか説明しました。 次に、画像を予測 API に送信することによって、それらの画像をプログラムでテストする方法を説明します。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示