Document Intelligence の一般的なドキュメント モデル
重要
Document Intelligence バージョン 2024-02-29-preview、2023-10-31-preview 以降、一般的なドキュメント モデル (事前構築済みドキュメント) は非推奨となりました。 ドキュメントからキーと値のペア、選択マーク、テキスト、テーブル、構造を抽出するには、次のモデルを使用してください。
| 機能 | version | モデル ID |
|---|---|---|
オプションのクエリ文字列パラメータ features=keyValuePairs が有効になっている Layout モデル。 |
• v4:2024-02-29-preview • v3.1:2023-07-31 (GA) |
prebuilt-layout |
| 一般的なドキュメント モデル | • v3.1:2023-07-31 (GA) • v3.0:2022-08-31 (GA) • v2.1 (GA) |
prebuilt-document |
このコンテンツの対象:![]() v3.1 (GA) | 最新バージョン:
v3.1 (GA) | 最新バージョン:![]() v4.0 (プレビュー) | 以前のバージョン:
v4.0 (プレビュー) | 以前のバージョン: ![]() v3.0
v3.0
このコンテンツの適用対象: ![]() v3.0 (GA) | 最新バージョン:
v3.0 (GA) | 最新バージョン: ![]() v4.0 (プレビュー)
v4.0 (プレビュー) ![]() v3.1
v3.1
一般ドキュメント モデルでは、強力な光学式文字認識 (OCR) 機能とディープ ラーニング モデルを組み合わせて、ドキュメントからキーと値のペア、テーブル、および選択マークを抽出します。 一般的なドキュメントは、v3.1 および v3.0 API で入手できます。 詳細については、 参照してこちらの移行ガイドをご覧ください。
一般ドキュメント機能
一般ドキュメント モデルは事前トレーニング済みモデルであり、ラベルやトレーニングは必要ありません。
1 つの API を使用して、ドキュメントからキーと値のペア、選択マーク、テキスト、テーブル、構造が抽出されます。
一般ドキュメント モデルでは、構造化ドキュメント、半構造化ドキュメント、非構造化ドキュメントがサポートされています。
選択マークは、値
:selected:または:unselected:をもつフィールドとして識別されます。
Document Intelligence Studio を使用して処理されたサンプル ドキュメント
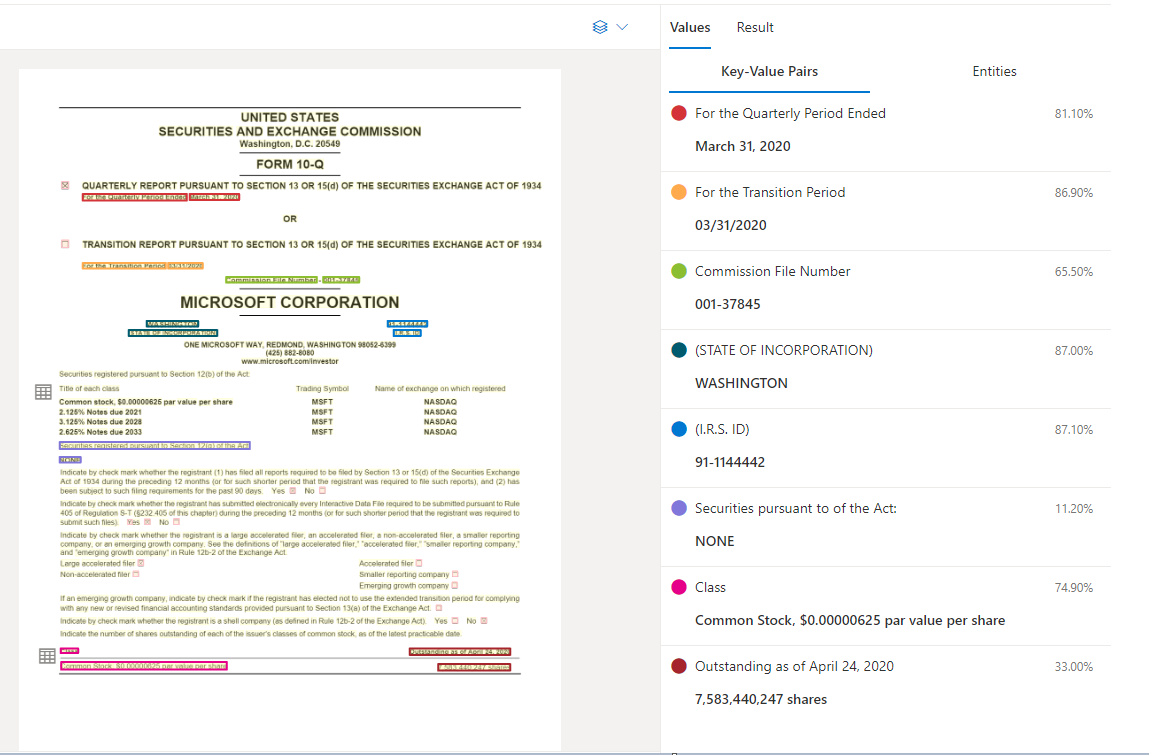
キーと値のペアの抽出
一般ドキュメントの API では、ほとんどの種類のフォームがサポートされており、ドキュメントを解析して、キーと関連する値を抽出します。 これは、ドキュメントから一般的なキーと値のペアを抽出する場合に最適です。 一般ドキュメント モデルは、ラベルなしのカスタム モデルのトレーニングの代わりに使用できます。
開発オプション
ドキュメント インテリジェンス v3.1 では、次のツール、アプリケーション、およびライブラリがサポートされています:
| 機能 | リソース | モデル ID |
|---|---|---|
| 一般的なドキュメント モデル | • ドキュメントインテリジェンススタジオ • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
事前構築済みドキュメント |
ドキュメント インテリジェンス v3.0 では、次のツール、アプリケーション、およびライブラリがサポートされています:
| 機能 | リソース | モデル ID |
|---|---|---|
| 一般的なドキュメント モデル | • ドキュメントインテリジェンススタジオ • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
事前構築済みドキュメント |
入力の要件
サポートされているファイル形式:
モデル PDF 画像: JPEG/JPG、PNG、BMP、TIFF、HEIFMicrosoft Office:
Word (DOCX)、Excel (XLSX)、PowerPoint (PPTX)、HTML読み込み ✔ ✔ ✔ Layout ✔ ✔ ✔ (2024-07-31-preview、2024-02-29-preview、2023-10-31-preview) 一般的なドキュメント ✔ ✔ 事前構築済み ✔ ✔ カスタム抽出 ✔ ✔ カスタム分類 ✔ ✔ ✔ (2024-07-31-preview、2024-02-29-preview) 最適な結果を得るには、ドキュメントごとに 1 つの鮮明な写真または高品質のスキャンを提供してください。
PDF および TIFF の場合、最大 2,000 ページを処理できます (Free レベルのサブスクリプションでは、最初の 2 ページのみが処理されます)。
ドキュメントを分析するためのファイル サイズは、有料 (S0) レベルでは 500 MB、無料 (F0) レベルでは
4MB です。画像のディメンションは、50 ピクセル x 50 ピクセルから 10,000 ピクセル x 10,000 ピクセルの間である必要があります。
PDF がパスワードでロックされている場合は、送信前にロックを解除する必要があります。
抽出するテキストの最小の高さは、1024 x 768 ピクセルのイメージの場合は 12 ピクセルです。 このディメンションは、150 DPI (1 インチあたりのドット数) で約
8ポイントのテキストに相当します。カスタム モデル トレーニングにおけるトレーニング データの最大ページ数は、カスタム テンプレート モデルの場合は 500、カスタム ニューラル モデルの場合は 50,000 です。
カスタム抽出モデル トレーニングにおけるトレーニング データの合計サイズは、テンプレート モデルの場合は 50 MB、ニューラル モデルの場合は
1GB です。カスタム分類モデル トレーニングの場合、トレーニング データの合計サイズは
1GB で、最大 10,000 ページです。 2024-07-31-preview 以降の場合、トレーニング データの合計サイズは2GB で、最大 10,000 ページです。
一般ドキュメント モデルのデータ抽出
Document Intelligence Studio を使用して、フォームやドキュメントからデータを抽出してみてください。
以下のリソースが必要です。
Azure サブスクリプション—無料で作成できます。
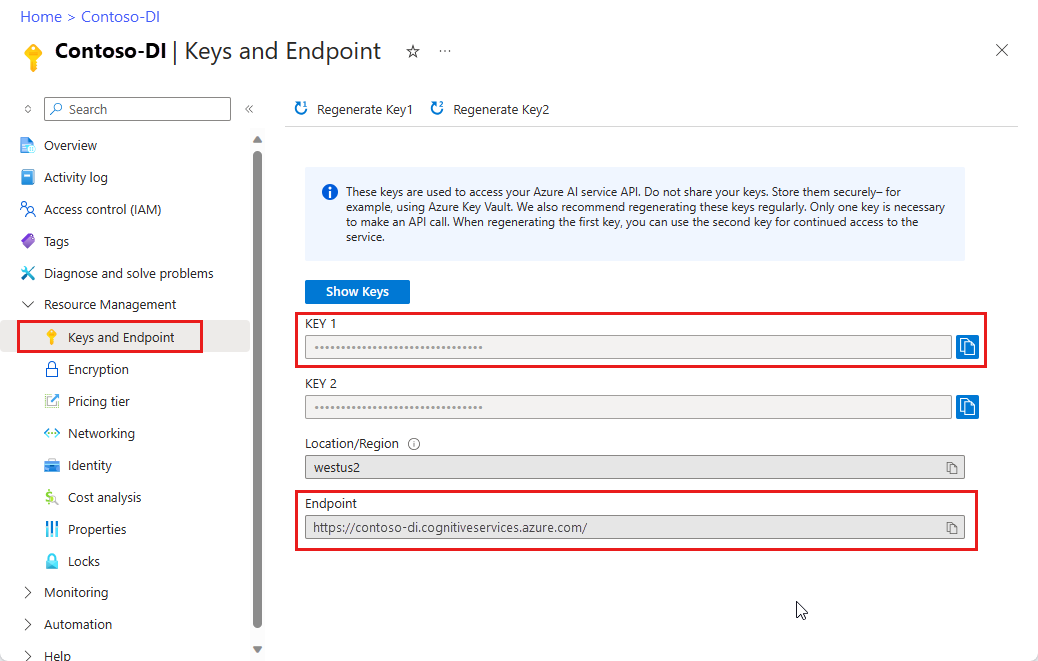
Azure portal の Document Intelligence Studio インスタンス。 Free 価格レベル (
F0) を利用して、サービスを試用できます。 リソースがデプロイされたら、[リソースに移動] を選択してキーとエンドポイントを取得します。
Note
Document Intelligence Studio と一般ドキュメント モデルは、v3.0 API で使用できます。
Document Intelligence Studio ホーム ページで、[一般ドキュメント] を選択します。
サンプル ドキュメントを分析したり、独自のファイルをアップロードしたりできます。
[分析の実行] ボタンを選択し、必要に応じて [分析オプション] を構成します。
![Document Intelligence Studio の [分析の実行] と [分析オプション] ボタンのスクリーンショット。](media/studio/run-analysis-analyze-options.png?view=doc-intel-3.1.0)
キー/値ペア
キーと値のペアは、ラベルまたはキーとそれに関連付けられている応答または値を識別する、ドキュメント内の特定の範囲です。 構造化されたフォームでは、これらのペアは、ラベルと、ユーザーがそのフィールドに入力した値である可能性があります。 非構造化ドキュメントでは、段落内のテキストに基づいて契約が実行された日付である可能性があります。 さまざまなドキュメントの種類、形式、構造に基づいて、識別可能なキーと値を抽出するために、AI モデルがトレーニングされています。
モデルによってキーの存在が検出されても、関連する値がない場合や、省略可能なフィールドの処理では、キーが単独で存在する可能性もあります。 たとえば、一部のインスタンスでは、フォームのミドル ネーム フィールドを空白のままにすることができます。 キーと値のペアは、常に、ドキュメントに含まれるテキストの範囲です。 "顧客" と "ユーザー" など、同じ値が異なる方法で記述されるドキュメントの場合、関連付けられているキーは、(コンテキストに基づき) 顧客またはユーザーのいずれかです。
データの抽出
| Model | テキストの抽出 | キーと値のペア | 選択マーク | テーブル | 共通名 |
|---|---|---|---|---|---|
| 一般ドキュメント | ✓ | ✓ | ✓ | ✓ | ✓* |
✓* - 2023-07-31 (v3.1 GA) 以降の API バージョンでのみ使用できます。
サポートされている言語とロケール
以下を参照として、サポートされている言語の完全なリストについては、言語サポート—ドキュメント解析モデル ページを見てください。
考慮事項
キーはドキュメントから抽出されたテキストの範囲であるため、半構造化ドキュメントの場合、キーの既存のディクショナリにキーをマップすることが必要な場合があります。
キーだけがあって値のないキーと値のペアがあることを想定してください。 たとえば、ユーザーがフォームでメール アドレスを提供しないことを選択したような場合です。
次のステップ
Document Intelligence v3.1 移行ガイドに従って、アプリケーションとワークフローで v3.1 バージョンを使用する方法について説明します。
REST API を調べます。