カスタム モデルを作成する
強調スタイルこのコンテンツの適用対象: ![]() v3.1 (GA) | 最新バージョン:
v3.1 (GA) | 最新バージョン: ![]() v4.0 (プレビュー) | 以前のバージョン:
v4.0 (プレビュー) | 以前のバージョン: ![]() v3.0
v3.0 ![]() v2.1
v2.1
このコンテンツの適用対象: ![]() v3.0 (GA) | 最新バージョン:
v3.0 (GA) | 最新バージョン: ![]() v4.0 (プレビュー)
v4.0 (プレビュー) ![]() v3.1 | 以前のバージョン:
v3.1 | 以前のバージョン: ![]() v2.1
v2.1
このコンテンツの適用対象: ![]() v2.1 | 最新バージョン:
v2.1 | 最新バージョン: ![]() v4.0 (プレビュー)
v4.0 (プレビュー)
重要
api-version=2024-07-31-preview 以降では、モデル作成の動作が変更されています。詳細については、構成済みカスタム モデルに関するページを参照してください。 次の動作は、v3.1 以前のバージョンにのみ適用されます
作成済みモデルは、カスタム モデルのコレクションを取得し、1 つのモデル ID に割り当てることで作成します。 200 個までのトレーニングされたカスタム モデルを 1 つの構成済みモデル ID に割り当てることができます。 作成済みモデルにドキュメントが送信されると、サービスによって分類ステップが実行され、分析のために提示されたフォームを正確に表すカスタム モデルが決定されます。 複数のモデルをトレーニングし、類似したフォームの種類を分析するためにそれらをグループ化する場合に構成済みモデルは役立ちます。 たとえば、作成済みモデルには、サプライ、備品、家具の発注書を分析するようにトレーニングされたカスタム モデルを含めることができます。 適切なモデルを手動で選択する代わりに、作成済みモデルを使用すれば、分析と抽出ごとに適切なカスタム モデルを決定できます。
詳細については、「構成済みカスタム モデル」を参照してください。
この記事では、構成済みカスタム モデルを作成して使用し、フォームとドキュメントを分析する方法について説明します。
前提条件
作業を開始するには、次のリソースが必要です。
Azure サブスクリプション。 無料の Azure サブスクリプションを作成できます。
Document Intelligence インスタンス。 Azure サブスクリプションを入手したら、Azure portal で Document Intelligence リソースを作成して、キーとエンドポイントを取得します。 既存の Document Intelligence リソースがある場合は、そのリソース ページに直接移動します。 Free 価格レベル (F0) を使用してサービスを試用し、後から運用環境用の有料レベルにアップグレードすることができます。
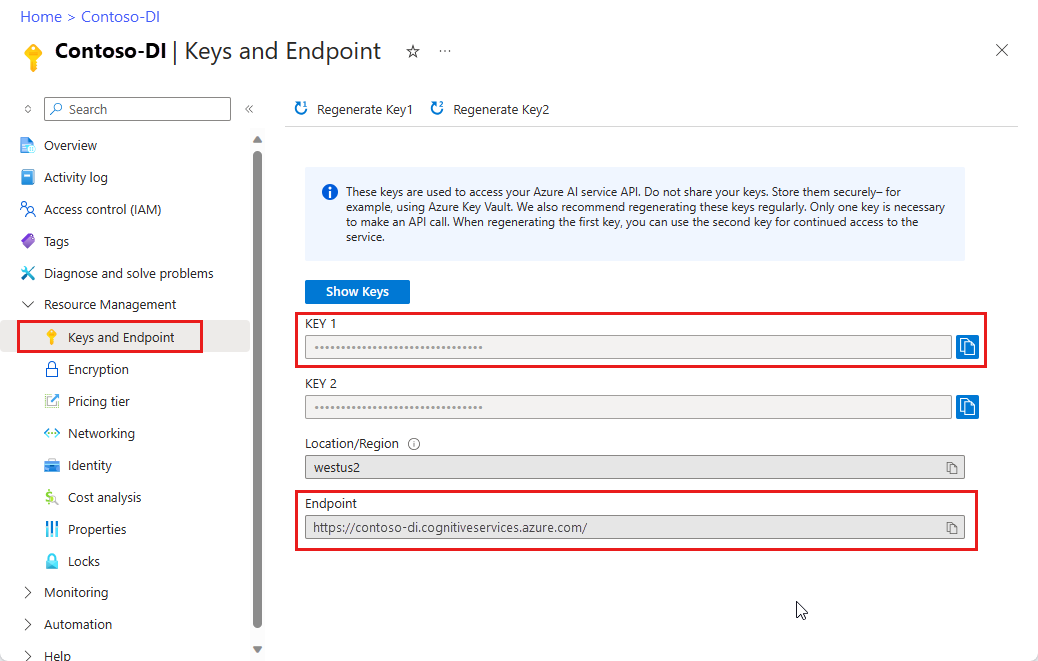
リソースがデプロイされた後、[リソースに移動] を選択します。
Azure portal からキーとエンドポイントの値をコピーし、Microsoft メモ帳などの便利な場所に貼り付けます。 アプリケーションを Document Intelligence API に接続するためのキーとエンドポイントの値が必要です。
ヒント
詳細については、「Document Intelligence リソースを作成する」を参照してください。
- Azure ストレージ アカウント。 Azure Storage アカウントを作成する方法がわからない場合は、Azure portal の Azure Storage に関するクイックスタートを参照してください。 Free 価格レベル (F0) を使用してサービスを試用し、後から運用環境用の有料レベルにアップグレードすることができます。
カスタム モデルを作成する
まず、構成するカスタム モデルのセットが必要です。 Document Intelligence Studio、REST API、またはクライアント ライブラリが使用できます。 手順は次のとおりです。
トレーニング データセットを作成する
カスタム モデルの構築は、トレーニング データセットの確立から始まります。 サンプル データセットには、同じ種類の完成したフォームが少なくとも 5 つ必要です。 異なるファイルの種類 (jpg、png、pdf、tiff) にして、テキストと手書きの両方を含めることができます。 フォームは Document Intelligence の入力要件に従う必要があります。
ヒント
以下のヒントを使って、トレーニングのためにデータ セットをさらに最適化してください。
- 可能であれば、画像ベースのドキュメントではなく、テキストベースの PDF ドキュメントを使用します。 スキャンした PDF は画像として処理されます。
- 入力フォームの場合は、すべてのフィールドに入力されている例を使用します。
- 各フィールドに異なる値が含まれたフォームを使用します。
- フォームの画像の品質が低い場合は、より大きなデータ セット (たとえば 10 から 15 の画像) を使用します。
トレーニング ドキュメントを収集する方法のヒントについては、「トレーニング データ セットの作成」を参照してください。
トレーニング データセットをアップロードする
トレーニング ドキュメントのセットをまとめたら、Azure BLOB ストレージ コンテナーにトレーニング データをアップロードする必要があります。
手動でラベル付けされたデータを使用する場合は、トレーニング ドキュメントに対応する .labels.json ファイルと .ocr.json ファイルをアップロードする必要があります。
カスタム モデルをトレーニングする
ラベル付けされたデータによるモデルのトレーニングでは、ラベル付けされた指定のフォームを使用して、教師あり学習を使って、目的とする値が抽出されます。 ラベル付きデータにより、性能の高いモデルが得られ、複雑なフォームやキーのない値を含んだフォームでも機能するモデルを作成できます。
Document Intelligence では、prebuilt-layout モデル API を使用して、活字または手書きのテキストの要素について予想されるサイズや位置を学習し、テーブルを抽出します。 その後、ユーザーによって指定されたラベルを使用して、ドキュメントに含まれるキーと値の関係およびテーブルを学習します。 新しいモデルをトレーニングする際は、手動でラベル付けされた同じタイプ (同じ構造) のフォームを 5 つ使うことをお勧めします。 その後、必要に応じてラベル付きのデータを追加し、モデルの精度を向上させます。 Document Intelligence を使用すると、教師あり学習機能を使用してキーと値のペアおよびテーブルを抽出するようにモデルをトレーニングできます。
カスタム モデルを作成するには、まずプロジェクトを構成することから始めます。
Studio ホームページで、[カスタム モデル] カードから [新規作成] を選択します。
[➕ プロジェクトの作成] コマンドを使用して、新しいプロジェクト構成ウィザードを開始します。
プロジェクトの詳細を入力し、Azure サブスクリプションとリソース、および自分のデータが含まれている Azure Blob Storage コンテナーを選択します。
設定を確認し、送信して、プロジェクトを作成します。

カスタム モデルを作成しているときに、ドキュメントからデータ コレクションを抽出する必要がある場合があります。 コレクションは、2 つの形式のいずれかで表示されます。 ビジュアル パターンとしてテーブルを使用した場合、
特定のフィールド (列) セットに対する値 (行) の動的または可変の値の数
特定のフィールド (列や行) セットに対する特定の値のコレクション
Document Intelligence Studio のテーブルとしてのラベル付けに関するページを参照してください

作成済みモデルを作成する
Note
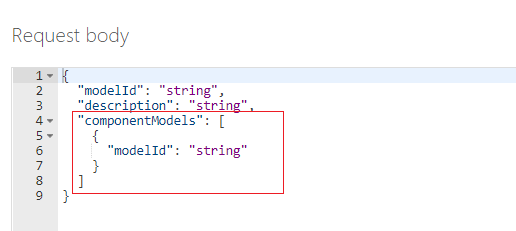
create compose model 操作は、ラベルを "使用して" トレーニングされたカスタム モデルでのみ使用できます。 ラベルのないモデルを作成しようとすると、エラーが発生します。
create compose model 操作では、100 個までのトレーニング済みカスタム モデルを 1 つのモデル ID に割り当てることができます。 作成済みモデルを使用してドキュメントを分析する場合、Document Intelligence では、まず送信されたフォームを分類し、次に最も適合する割り当て済みモデルを選んで、そのモデルに対する結果を返します。 この操作は、受信フォームが複数のテンプレートのいずれかに属している場合に役立ちます。
トレーニング プロセスが正常に完了したら、構成済みモデルの構築を開始できます。 構成済みモデルを作成して使用する手順を次に示します。
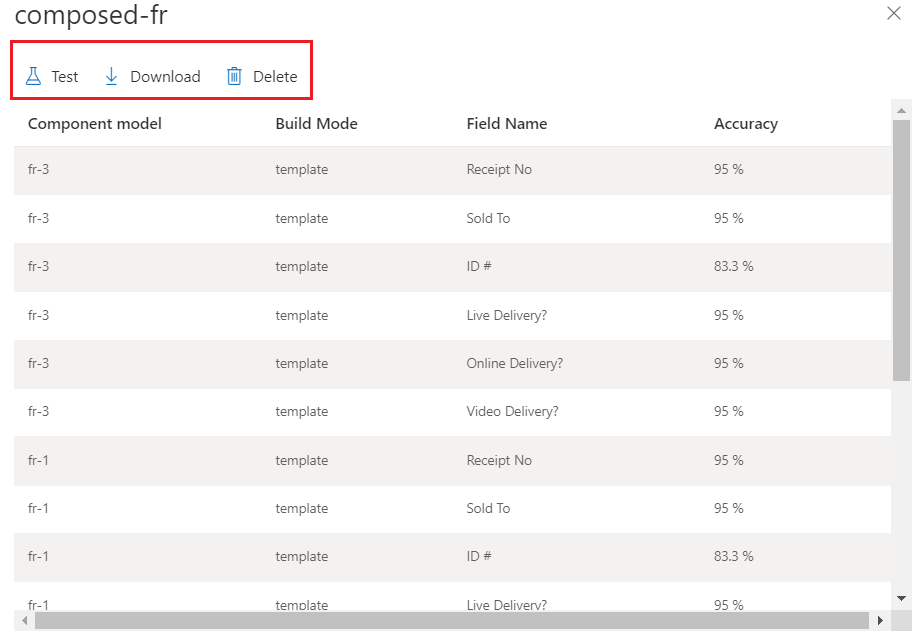
モデルの ID を収集する
Document Intelligence Studio を使用してモデルをトレーニングした場合、モデル ID はプロジェクトの [モデル] メニューの下に表示されます。
![Document Intelligence Studio の [モデル構成] ウィンドウのスクリーンショット。](../media/studio/composed-model.png?view=doc-intel-3.1.0)
カスタム モデルを作成する
カスタム モデル プロジェクトを選択します。
プロジェクトで、メニュー項目から
Modelsを選択します。表示されたモデルの一覧から、構成するモデルを選択します。
左上隅にある [作成] ボタンを選択します。
ポップアップ ウィンドウで、新しく作成するモデルに名前を付け、 [作成] をクリックします。
操作が完了すると、新しく作成されたモデルが一覧に表示されます。
モデルの準備ができたら、Test コマンドを使用してテスト ドキュメントでそのモデルを検証し、結果を確認します。
ドキュメントを分析する
カスタム モデルの Analyze 操作では、Document Intelligence への呼び出しで modelID を指定する必要があります。 構成済みモデル ID をアプリケーションの modelID パラメーターに指定する必要があります。

構成済みモデルを管理する
ライフサイクル全体を通して、次のようにカスタム モデルを管理できます。
- 新しいドキュメントをテストして検証します。
- アプリケーションで使用するモデルをダウンロードします。
- ライフサイクルが完了したら、モデルを削除します。

完了。 カスタム モデルと作成済みモデルを作成し、それらを Document Intelligence プロジェクトとアプリケーションで使用する手順について学習しました。
次のステップ
Document Intelligence クイックスタートのいずれかをお試しください。
Document Intelligence では、高度な機械学習テクノロジを使用して、ドキュメント イメージから情報を検出および抽出し、抽出したデータを構造化 JSON 出力で返します。 Document Intelligence を使用すると、スタンドアロンのカスタム モデルをトレーニングしたり、カスタム モデルを組み合わせて作成済みモデルを作成したりできます。
カスタム モデル。 Document Intelligence のカスタム モデルを使用すると、ビジネスに固有のフォームやドキュメントに含まれるデータの分析と抽出ができます。 カスタム モデルは、特定のデータとユース ケースに合わせてトレーニングされます。
作成済みモデル。 作成済みモデルは、カスタム モデルのコレクションを取得し、目的のフォームの種類を含む 1 つのモデルに割り当てることによって作成されます。 作成済みモデルにドキュメントが送信されると、サービスによって分類ステップが実行され、分析のために提示されたフォームを正確に表すカスタム モデルが決定されます。
この記事では、Document Intelligence サンプル ラベル付けツール、REST API、またはクライアント ライブラリを使用して Document Intelligence のカスタム モデルと作成済みモデルを作成する方法について説明します。
サンプル ラベル付けツール
サンプル ラベル付けツールを使用して、カスタム フォームからデータを抽出してみてください。 以下のリソースが必要です。
Azure サブスクリプション — 無料で作成することができます
Azure portal の Document Intelligence Studio インスタンス。 Free 価格レベル (
F0) を利用して、サービスを試用できます。 リソースがデプロイされたら、[リソースに移動] を選択してキーとエンドポイントを取得します。
Document Intelligence UI で、次の手順を実行します。
- [Use Custom to train a model with labels and get key value pairs](キーと値のペアを取得するためにカスタムを使用してラベルでモデルのトレーニングを行う) を選択してください。
- 次のウィンドウで [New project](新規プロジェクト) を選択します:

モデルを作成する
カスタム モデルと作成済みモデルを構築、トレーニング、使用するための手順は次のとおりです。
- トレーニング データセットを作成する
- トレーニング セットを Azure BLOB ストレージにアップロードする
- カスタム モデルをトレーニングする
- カスタム モデルを作成する
- ドキュメントを分析する
- カスタム モデルを管理する
トレーニング データセットを作成する
カスタム モデルの構築は、トレーニング データセットの確立から始まります。 サンプル データセットには、同じ種類の完成したフォームが少なくとも 5 つ必要です。 異なるファイルの種類 (jpg、png、pdf、tiff) にして、テキストと手書きの両方を含めることができます。 フォームは Document Intelligence の入力要件に従う必要があります。
トレーニング データセットをアップロードする
Azure BLOB ストレージ コンテナーにトレーニング データをアップロードする必要があります。 コンテナーを含む Azure Storage アカウントを作成する方法がわからない場合は、Azure portal の Azure Storage に関するクイックスタートを参照してください。 Free 価格レベル (F0) を使用してサービスを試用し、後から運用環境用の有料レベルにアップグレードすることができます。
カスタム モデルをトレーニングする
ラベル付きデータ セットを使って、モデルをトレーニングします。 ラベル付きデータセットは事前構築済みレイアウト API に依存していますが、特定のラベルやフィールドの場所など、補助的なユーザーの入力が含まれています。 ラベル付きのトレーニング データに対して、同じ種類の少なくとも 5 つの完成したフォームで開始します。
ラベル付けされたデータによるモデルのトレーニングでは、ラベル付けされた指定のフォームを使用して、教師あり学習を使って、目的とする値が抽出されます。 ラベル付きデータにより、性能の高いモデルが得られ、複雑なフォームやキーのない値を含んだフォームでも機能するモデルを作成できます。
Document Intelligence では、Layout API を使用して、活字または手書きのテキストの要素について予想されるサイズや位置が学習され、テーブルが抽出されます。 その後、ユーザーによって指定されたラベルを使用して、ドキュメントに含まれるキーと値の関係およびテーブルを学習します。 新しいモデルをトレーニングする際は、手動でラベル付けされた同じタイプ (同じ構造) のフォームを 5 つ使うことをお勧めします。 必要に応じてラベル付きのデータを追加し、モデルの精度を向上させます。 Document Intelligence を使用すると、教師あり学習機能を使用してキーと値のペアおよびテーブルを抽出するようにモデルをトレーニングできます。
[!VIDEO https://learn.microsoft.com/Shows/Docs-Azure/Azure-Form-Recognizer/player]
作成済みモデルを作成する
Note
[モデルの作成] は、ラベルを使用してトレーニングするカスタム モデルでのみ使用できます。 ラベルのないモデルを作成しようとすると、エラーが発生します。
モデルの構成操作では、最大 200 個のトレーニング済みカスタム モデルを 1 つのモデル ID に割り当てることができます。 作成済みモデル ID で Analyze を呼び出すと、Document Intelligence によって、まず送信されたフォームが分類され、最も適合する割り当て済みモデルが選択され、そのモデルに対する結果が返されます。 この操作は、受信フォームが複数のテンプレートのいずれかに属している場合に役立ちます。
Document Intelligence サンプル ラベル付けツール、REST API、またはクライアント ライブラリを使用し、次の手順に従って、作成済みモデルを設定します。
カスタム モデル ID を収集する
トレーニング プロセスが正常に完了すると、カスタム モデルにモデル ID が割り当てられます。 モデル ID は次のようにして取得できます。
Document Intelligence サンプル ラベル付けツールを使用してモデルをトレーニングすると、モデル ID が [Train Result](トレーニング結果) ウィンドウに表示されます。
![[Train Result]\(トレーニング結果\) ウィンドウのスクリーンショット。](../media/fott-training-results.png?view=doc-intel-3.1.0)

カスタム モデルを作成する
1 つのフォームの種類に対応するカスタム モデルを収集したら、それらをまとめた 1 つのモデルを作成できます。
サンプル ラベル付けツールを使用すると、モデルのトレーニングと、それらを 1 つのモデル ID にまとめる作業をすばやく開始できます。
トレーニングが完了したら、次のようにしてモデルを作成します。
左側のレール メニューで、[モデルの作成] アイコン (マージ矢印) を選択します。
メイン ウィンドウで、1 つのモデル ID に割り当てるモデルを選択します。 矢印アイコンの付いたモデルは、既に作成済みのモデルです。
左上隅にある [作成] ボタンを選択します。
ポップアップ ウィンドウで、新しく作成するモデルに名前を付け、 [作成] をクリックします。
操作が完了すると、新しく作成されたモデルが一覧に表示されます。

カスタムまたは作成済みモデルを使用してドキュメントを分析する
カスタム フォームの Analyze 操作では、Document Intelligence への呼び出しで modelID を指定する必要があります。 modelID パラメーターには、1 つのカスタム モデル ID または作成済みモデル ID を指定できます。
ツールの左ペインのメニューで、
Analyzeアイコン (電球) を選択します。分析するローカル ファイルまたは画像の URL を選択します。
[Run Analysis](分析の実行) ボタンを選択します。
このツールでは、境界ボックスにタグが適用され、各タグの信頼度がパーセント単位でレポートされます。
![Document Intelligence ツールの [analyze-a-custom-form]\(カスタム フォームの分析\) ウィンドウのスクリーンショット。](../media/analyze.png?view=doc-intel-3.1.0)
トレーニング データセットの一部ではなかったフォームを分析して、新しくトレーニングしたモデルをテストします。 レポートされる精度によっては、モデルを改善するために、さらにトレーニングを行う必要が生じる場合があります。 さらにトレーニングを続けて結果を改善することができます。
カスタム モデルを管理する
ライフサイクル全体にわたってカスタム モデルを管理できます。サブスクリプションに属するすべてのカスタム モデルの一覧を表示したり、特定のカスタム モデルに関する情報を取得したり、アカウントからカスタム モデルを削除したりします。
完了。 カスタム モデルと作成済みモデルを作成し、それらを Document Intelligence プロジェクトとアプリケーションで使用する手順について学習しました。
次のステップ
Document Intelligence クライアント ライブラリの詳細については、API リファレンスのドキュメントを参照してください。