サンプル ラベル付けツールを使用してカスタム モデルをトレーニングする
このコンテンツの適用対象: ![]() v2.1。
v2.1。
ヒント
- 強化されたエクスペリエンスと高度なモデル品質のためには、Document Intelligence v3.0 Studio をお試しください。
- v3.0 Studio では、v2.1 ラベル付きデータでトレーニングされたすべてのモデルがサポートされます。
- v2.1 から v3.0 への移行の詳細については、API 移行ガイドを参照してください。
- V3.0 で作業開始するには、REST API または、C#、Java、JavaScript、Python の SDK クイックスタートを "参照" してください。
この記事では、Document Intelligence REST API とサンプル ラベル付けツールを使用して、手動でラベル付けされたデータを使ってカスタム モデルをトレーニングします。
前提条件
このプロジェクトを完了するには、以下のリソースが必要です。
- Azure サブスクリプション - 無料アカウントを作成します
- Azure サブスクリプションを入手したら、Azure portal で Document Intelligence リソースを作成して、キーとエンドポイントを取得します。 デプロイされたら、 [リソースに移動] を選択します。
- アプリケーションを Document Intelligence API に接続するには、作成したリソースのキーとエンドポイントが必要です。 このクイックスタートで後に示すコードに、自分のキーとエンドポイントを貼り付けます。
- Free 価格レベル (
F0) を使用してサービスを試用し、後から運用環境用の有料レベルにアップグレードすることができます。
- 同じ種類の少なくとも 6 つのフォームのセット。 このデータを使用して、モデルのトレーニングとフォームのテストを行います。 このクイックスタートでは、サンプル データセットを使用できます (sample_data.zip をダウンロードして展開します)。 Standard パフォーマンス レベルの Azure Storage アカウントの BLOB ストレージ コンテナーのルートに、トレーニング ファイルをアップロードします。
Document Intelligence リソースを作成する
Azure portal に移動し新しい Document Intelligence リソースを作成します。 [作成] ウィンドウには以下の情報が表示されます。
| プロジェクトの詳細 | 説明 |
|---|---|
| サブスクリプション | アクセスが許可されている Azure サブスクリプションを選択します。 |
| リソース グループ | ご利用のリソースを含んだ Azure リソース グループ。 新しいグループを作成することも、既存のグループに追加することもできます。 |
| リージョン | Azure AI サービス リソースの場所。 別の場所を選択すると待機時間が生じる可能性がありますが、リソースのランタイムの可用性には影響しません。 |
| 名前 | リソースのわかりやすい名前。 わかりやすい名前 (MyNameFaceAPIAccount など) を使用することをお勧めします。 |
| 価格レベル | リソースのコストは、選択した価格レベルと使用量に依存します。 詳細については、「API の価格の詳細」をご覧ください。 |
| [確認および作成] | [確認および作成] ボタンを選択して、Azure portal にリソースをデプロイします。 |
キーとエンドポイントを取得する
Document Intelligence リソースのデプロイが完了したら、ポータルの [すべてのリソース] リストからそれを見つけて選択します。 キーとエンドポイントは、リソースの [キーとエンドポイント] ページの [リソース管理] に配置されます。 これらの両方を一時的な場所に保存してから、先に進んでください。
試してみる
Document Intelligence サンプル ラベル付けツールをオンラインでお試しください。
Document Intelligence サービスを試すには、Azure サブスクリプション (無料で作成) と Document Intelligence リソース エンドポイントおよびキーが必要です。
サンプル ラベル付けツールを設定する
Note
ストレージ データが VNet またはファイアウォールの背後にある場合、Document Intelligence サンプル ラベル付けツールを VNet またはファイアウォールの背後にデプロイし、システム割り当てマネージド ID を作成してアクセスを付与する必要があります。
サンプル ラベル付けツールを実行するには、Docker エンジンを使用します。 次の手順に従って、Docker コンテナーを設定します。 Docker やコンテナーの基礎に関する入門情報については、「Docker overview」(Docker の概要) を参照してください。
ヒント
GitHub のオープンソース プロジェクトの OCR Form Labeling Tool を使用することもできます。 このツールは、React + Redux を使用して作成された TypeScript Web アプリケーションです。 詳細または共同作成については、OCR Form Labeling Tool リポジトリを参照してください。 ツールをオンラインで試すには、Document Intelligence サンプル ラベル付けツールの Web サイトにアクセスします。
まず、ホスト コンピューターに Docker をインストールします。 このガイドでは、ローカル コンピューターをホストとして使用する方法を示します。 Azure で Docker ホスティング サービスを使用する場合は、「サンプル ラベル付けツールのデプロイ」攻略ガイドを参照してください。
ホスト コンピューターは、次のハードウェア要件を満たしている必要があります。
コンテナー 最小値 推奨 サンプル ラベル付けツール 2コア、4 GB のメモリ4コア、8 GB のメモリお使いのオペレーティング システムに該当する手順に従って、マシンに Docker をインストールします。
docker pullコマンドを使用して、サンプル ラベル付けツールのコンテナーを取得します。docker pull mcr.microsoft.com/azure-cognitive-services/custom-form/labeltool:latest-2.1これで、
docker runを使用してコンテナーを実行する準備が整いました。docker run -it -p 3000:80 mcr.microsoft.com/azure-cognitive-services/custom-form/labeltool:latest-2.1 eula=acceptこのコマンドを実行すると、Web ブラウザーからサンプル ラベル付けツールを使用できるようになります。
http://localhost:3000にアクセスします。
Note
Document Intelligence REST API を使用して、ドキュメントにラベルを付けたり、モデルをトレーニングしたりすることもできます。 REST API を使用してトレーニングおよび分析を行うには、REST API と Python によるラベルを使用したトレーニングに関するページを参照してください。
入力データを設定する
まず、すべてのトレーニング ドキュメントが同じ形式であることを確認します。 複数の形式のフォームがある場合は、共通する形式に基づいてサブフォルダーに分類します。 トレーニング時には、API に対してサブフォルダーを指定する必要があります。
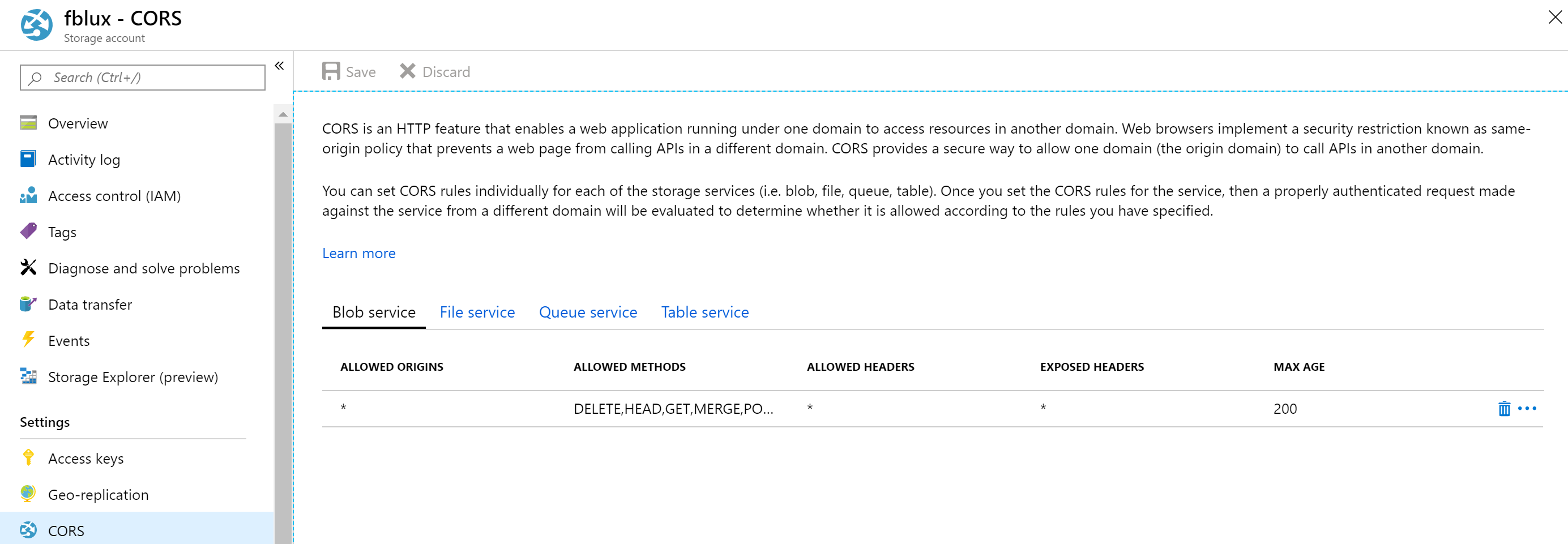
クロスドメイン リソース共有 (CORS) を構成する
ストレージ アカウントで CORS を有効にします。 Azure portal で自分のストレージ アカウントを選択し、左側のペインで [CORS] タブを選択します。 一番下の行に、次の値を入力します。 上部にある [保存] を選択します。
- [許可されたドメイン] = *
- [許可されたメソッド] = [すべて選択]
- [許可されたヘッダー] = *
- [公開されるヘッダー] = *
- [最長有効期間] = 200
サンプル ラベル付けツールに接続する
サンプル ラベル付けツールは、ソース (元のアップロードされたフォーム) とターゲット (作成されたラベルと出力データ) に接続されます。
接続は、複数のプロジェクトにまたがって設定および共有できます。 拡張可能なプロバイダー モデルが使用されるため、新しいソースまたはターゲット プロバイダーを簡単に追加できます。
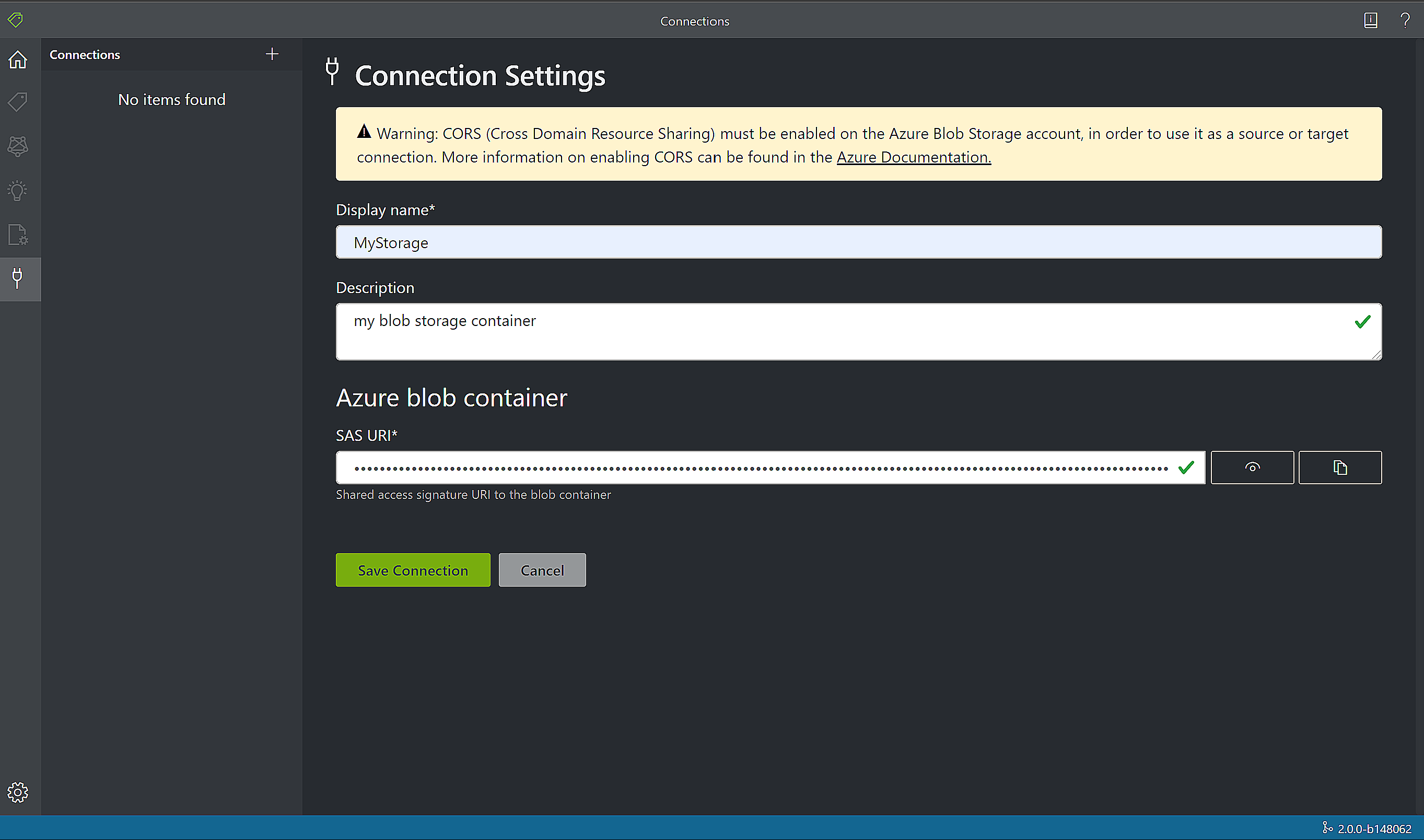
新しい接続を作成するには、左側のナビゲーション バーにある新しい接続 (プラグ) アイコンを選択します。
フィールドに次の値を入力します。
[表示名] - 接続の表示名。
[説明] - プロジェクトの説明。
[SAS URL] - Azure Blob Storage コンテナーの Shared Access Signature (SAS) URL。 カスタム モデルのトレーニング データの SAS URL を取得するには、Azure portal のストレージ リソースに移動し、 [Storage Explorer] タブを選択します。コンテナーに移動して右クリックし、 [Get shared access signature](Shared Access Signature の取得) を選択します。 ストレージ アカウント自体ではなく、コンテナー用の SAS を取得することが重要です。 [読み取り] 、 [書き込み] 、 [削除] 、および [表示] 権限がオンになっていることを確認し、 [作成] をクリックします。 次に、URL セクションの値を一時的な場所にコピーします。 それは次の書式になります
https://<storage account>.blob.core.windows.net/<container name>?<SAS value>。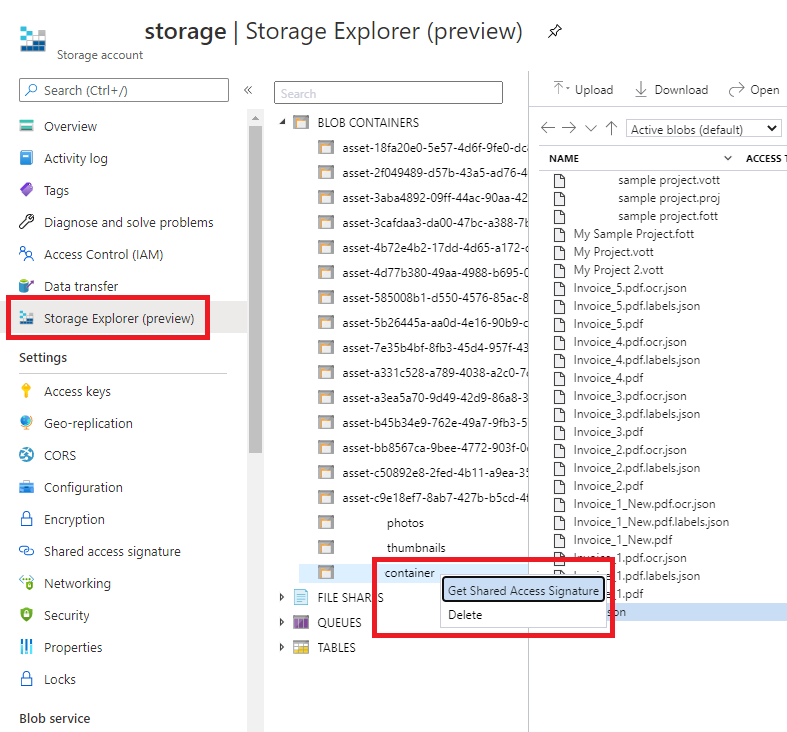
新しいプロジェクトを作成する
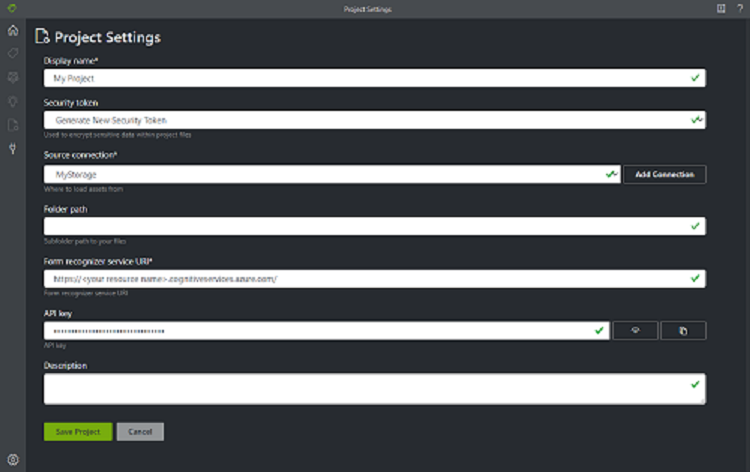
サンプル ラベル付けツールでは、プロジェクトに構成と設定が保存されます。 新しいプロジェクトを作成し、フィールドに次の値を入力します。
- [表示名] - プロジェクトの表示名
- [セキュリティ トークン] - 一部のプロジェクト設定には、キーや他の共有シークレットなどの機密性の高い値を含めることができます。 各プロジェクトでは、機密性の高いプロジェクト設定の暗号化または暗号化解除に使用できるセキュリティ トークンが生成されます。 セキュリティ トークンは、左側のナビゲーション バーの下部にある歯車アイコンを選択すると、[アプリケーション設定] に表示されます。
- [基になる接続] - このプロジェクトに使用する、前の手順で作成した Azure Blob Storage 接続。
- [フォルダー パス] (省略可能) - ソース フォームが BLOB コンテナー上のフォルダーに配置されている場合は、ここにフォルダー名を指定します。
- Document Intelligence サービス URI - Document Intelligence エンドポイントの URL。
- キー - Document Intelligence キー。
- [説明] (省略可能) - プロジェクトの説明
フォームにラベルを付ける
プロジェクトを作成するか開くと、メインのタグ エディター ウィンドウが開きます。 このタグ エディターは、次の 3 つの部分で構成されます。
- サイズ変更可能な v3.0 ペイン。基になる接続にあるフォームのスクロール可能な一覧が表示されます。
- メインのエディター ペイン。ここで、タグを適用できます。
- タグ エディター ペイン。ここで、タグの変更、ロック、並べ替え、削除を行うことができます。
テキストとテーブルを特定する
左側のペインにある [Run Layout on unvisited documents] (未処理ドキュメントでレイアウトを実行) を選択して、各ドキュメントのテキストとテーブルのレイアウト情報を取得します。 ラベル付けツールによって、各テキスト要素の周囲に境界ボックスが描画されます。
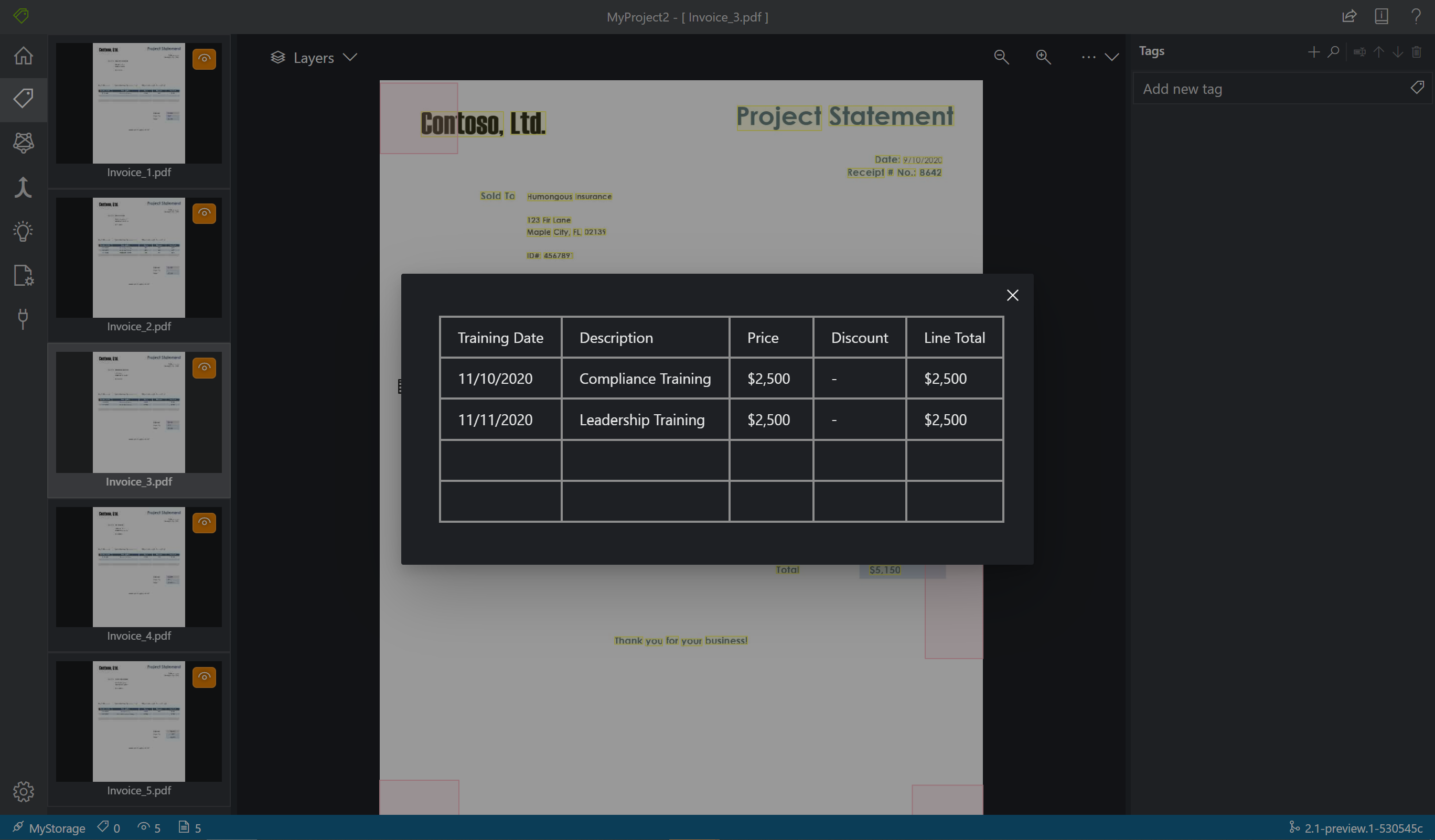
ラベル付けツールでは、どのテーブルが自動的に抽出されたかも示されます。 抽出されたテーブルを確認するには、ドキュメントの左側にあるテーブル/グリッド アイコンを選択します。 このクイックスタートでは、テーブルの内容は自動的に抽出されるため、テーブルの内容に対するラベル付けは行わず、自動抽出を利用します。
v2.1 では、トレーニング ドキュメントに値が入力されていない場合は、値が入る枠を描画できます。 ウィンドウの左上隅にある描画領域を使用して、領域をタグ付け可能にします。
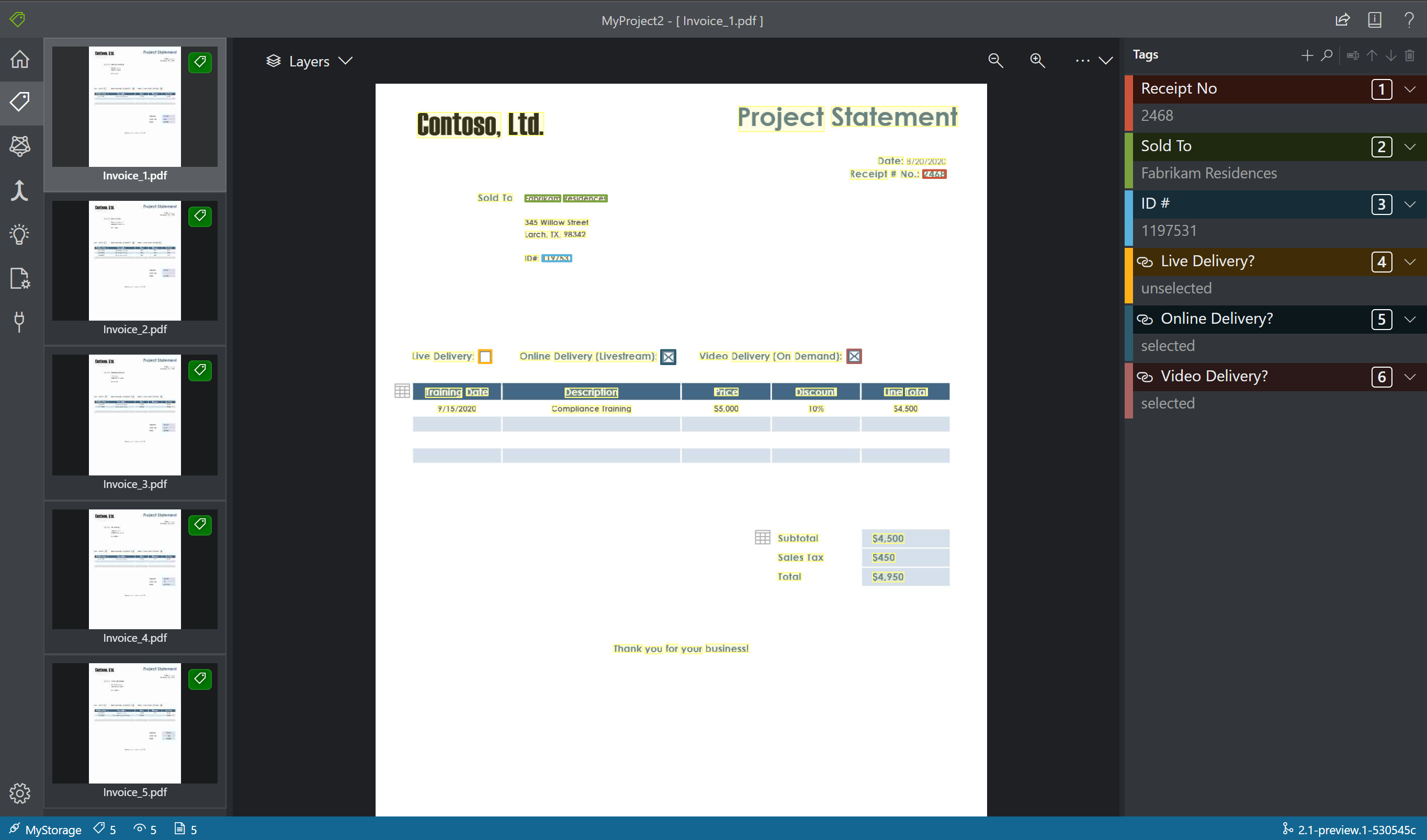
ラベルをテキストに適用する
次に、タグ (ラベル) を作成し、モデルに分析させるテキスト要素に適用します。
- まず、タグ エディター ペインを使用して、識別するタグを作成します。
- + を選択して、新しいタグを作成します。
- タグ名を入力します。
- Enter キーを押して、タグを保存します。
- メインのエディターで、強調表示されたテキスト要素または描画した領域から単語を選択します。
- 適用するタグを選択するか、対応するキーボード キーを押します。 数字キーは、最初の 10 個のタグのホットキーとして割り当てられます。 タグの順序は、タグ エディター ペインの上矢印と下矢印のアイコンを使用して変更できます。
- 上記の手順に従って、少なくとも 5 つのフォームにラベルを付けてください。
ヒント
フォームにラベルを付けるときは、次のヒントに留意してください。
- 適用できるタグは、選択したテキスト要素ごとに 1 つのみです。
- 各タグは、1 ページにつき 1 回のみ適用できます。 同じフォームに同じ値が複数回出現する場合は、インスタンスごとに異なるタグを作成します。 たとえば、"invoice # 1"、"invoice # 2" などとします。
- タグは複数のページにまたがることはできません。
- フォームに表示されるラベル値は、2 つの異なるタグを使用して 2 つの部分に分割しないでください。 たとえば、アドレス フィールドが複数の行にまたがる場合でも、1 つのタグを使用してラベルを付ける必要があります。
- タグが付けられたフィールドには値のみを含めます。キーは含めないでください。
- テーブル データは自動的に検出され、最終的な出力 JSON ファイルに表示されます。 ただし、モデルが一部のテーブル データを検出できない場合は、これらのフィールドに手動でタグを付けることもできます。 テーブル内のセルごとに異なるラベルを使用してタグ付けします。 さまざまな行数を含むテーブルがフォームにある場合は、できるだけ大きなテーブルを含む 1 つ以上のフォームにタグを付けてください。
- + の右にあるボタンを使用して、タグの検索、名前の変更、順序変更、削除を行います。
- タグそのものは削除せずに、適用されているタグを解除するには、タグ付けされた四角形をドキュメント ビューで選択し、Delete キーを押します。
タグの値の型を指定する
それぞれのタグに予期されるデータ型を設定できます。 タグの右側にあるコンテキスト メニューを開いて型を選択します。 この機能により、検出アルゴリズムは、テキスト検出精度の向上につながる仮説を立てることができます。 また、最終的な JSON 出力では、検出された値が確実に標準化された形式で返されます。 値の型に関する情報は、ラベル ファイルと同じパスにある fields.json ファイルに保存されます。
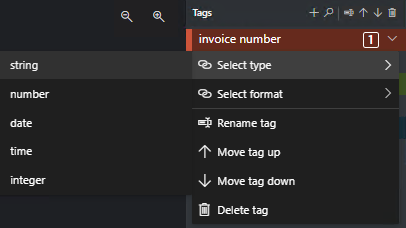
現在、次の値の型とバリエーションがサポートされています。
string- 既定値、
no-whitespaces、alphanumeric
- 既定値、
number- 既定値、
currency - 浮動小数点値として書式設定されます。
- 例: ドキュメント上の 1234.98 は、出力では 1234.98 に書式設定されます。
- 既定値、
date- 既定値、
dmy、mdy、ymd
- 既定値、
timeinteger- 整数値として書式設定されます。
- 例: ドキュメント上の 1234.98 は、出力では 123498 に書式設定されます。
selectionMark
Note
日付の書式設定については、次の規則を参照してください。
日付書式設定を機能させるには、形式 (dmy、mdy、ymd) を指定する必要があります。
, - / . \ は日付区切り記号として使用できます。 空白を区切り記号として使用することはできません。 次に例を示します。
- 01,01,2020
- 01-01-2020
- 2020/01/01
日と月はそれぞれ1桁または 2 桁で記述でき、年は 2 桁または 4 桁で記述できます。
- 1-1-2020
- 1-01-20
日付文字列が8桁の場合、区切り文字はオプションです。
- 01012020
- 01 01 2020
月は、完全な名前または短い名前として記述することもできます。 名前を使用する場合、区切り文字はオプションです。 ただし、この形式は他の形式よりも正確に認識されない場合があります。
- 01/Jan/2020
- 01Jan2020
- 01 Jan 2020
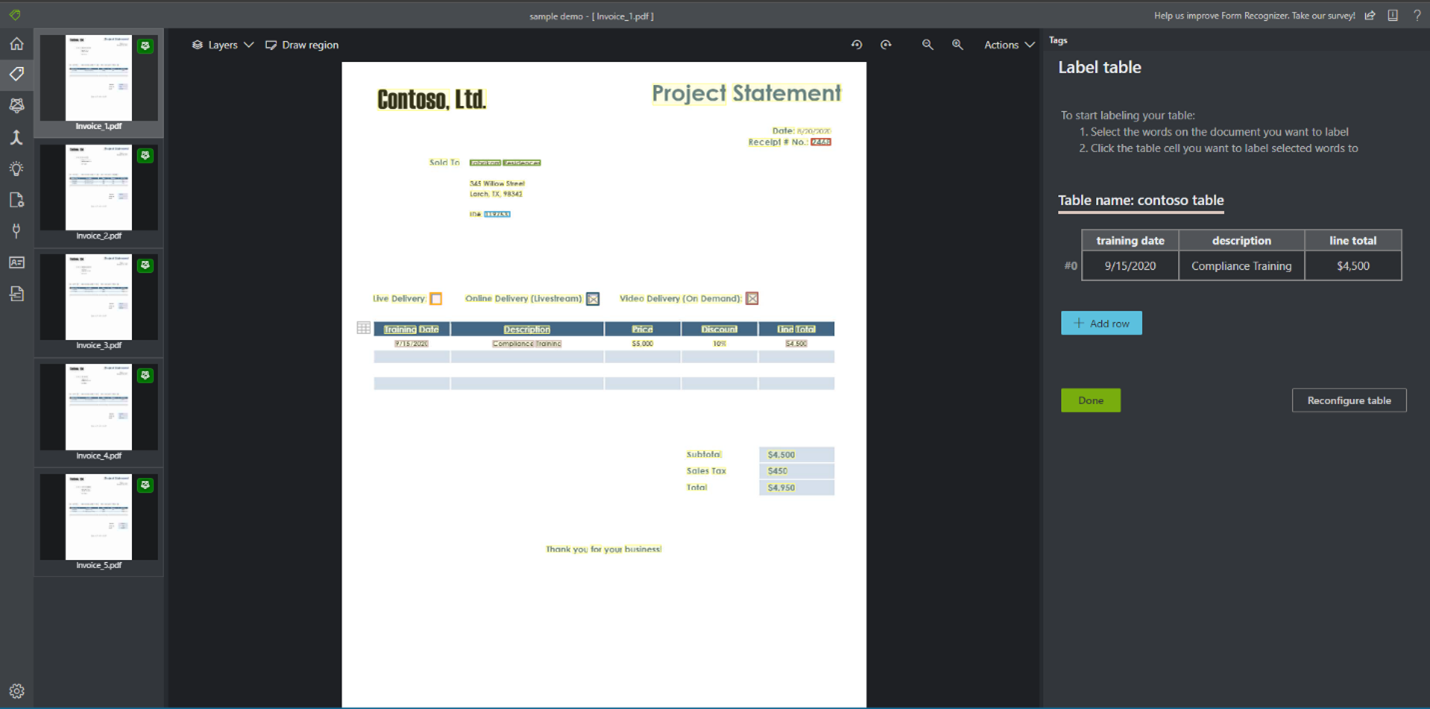
テーブルにラベルを付ける (v2.1 のみ)
場合によって、データは、キーと値のペアではなくテーブルとしてラベル付けした方が役立つことがあります。 この場合は、[Add a new table tag](新しいテーブル タグの追加) を選択してテーブル タグを作成できます。 ドキュメントに応じてテーブルで固定行数と可変行数のどちらを使用するかを指定し、スキーマを定義します。
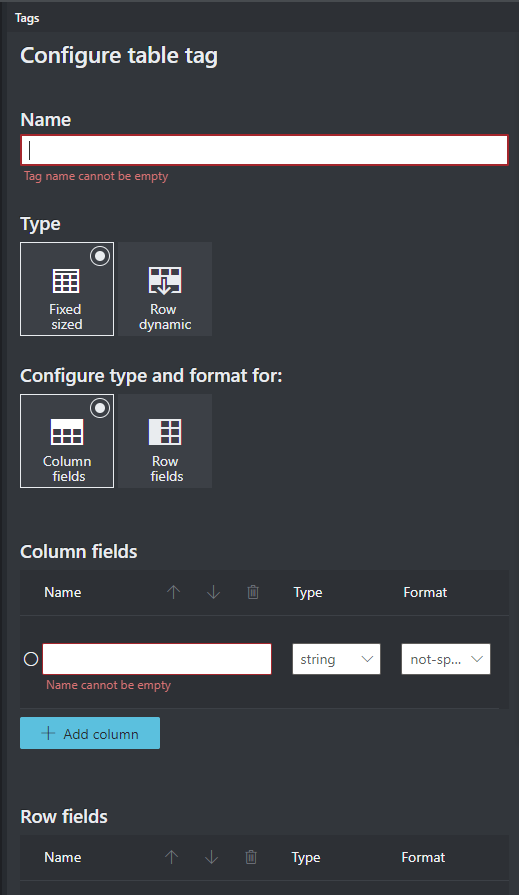
テーブル タグを定義したら、セル値にタグを付けます。
カスタム モデルをトレーニングする
[トレーニング] ページを開くには、左側のペイン上の [トレーニング] アイコンを選択します。 次に、 [Train](トレーニング) ボタンを選択して、モデルのトレーニングを開始します。 トレーニング プロセスが完了すると、次の情報が表示されます。
- [Model ID] - 作成およびトレーニングされたモデルの ID。 トレーニングの呼び出しごとに、独自の ID を持つ新しいモデルが作成されます。 この文字列を安全な場所にコピーしてください。REST API またはクライアント ライブラリ ガイドを使用して予測呼び出しを行う場合に必要になります。
- [Average Accuracy](平均精度) - モデルの平均精度。 さらにフォームを追加してラベルを付け、再度トレーニングを行って新しいモデルを作成することにより、モデルの精度を向上させることができます。 最初は 5 つのフォームにラベルを付け、必要に応じてフォームの数を増やすことをお勧めします。
- タグの一覧と、タグごとの予測精度。
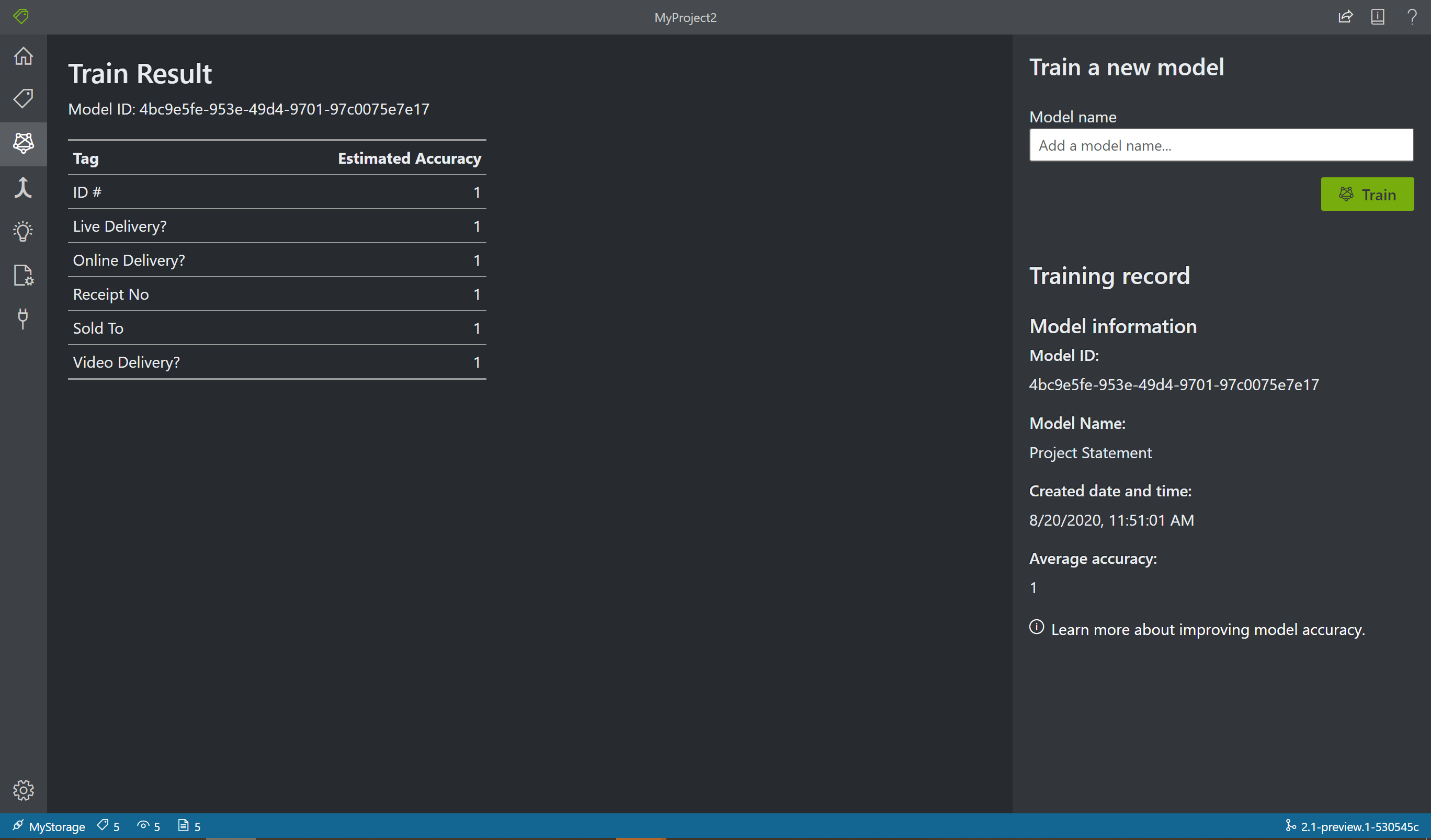
トレーニングが完了したら、 [Average Accuracy](平均精度) の値を確認します。 低い場合は、入力ドキュメントをさらに追加して、ラベル付けの手順を繰り返す必要があります。 既にラベルを付けたドキュメントは、プロジェクト インデックス内に残ります。
ヒント
REST API 呼び出しを使用してトレーニング プロセスを実行することもできます。 これを行う方法については、Python によるラベルを使用したトレーニングに関するページを参照してください。
トレーニング済みのモデルを作成する
モデルの作成では、1 つのモデル ID に最大 200 個のモデルを作成できます。 作成された modelID で Analyze を呼び出すと、Document Intelligence によって、まず送信されたフォームが分類され、最も適合するモデルが選択され、そのモデルに対する結果が返されます。 この操作は、受信フォームが複数のテンプレートのいずれかに属している場合に役立ちます。
- サンプル ラベル付けツールでモデルを作成するには、ナビゲーション バーから [モデルの作成] (結合する矢印) アイコンを選択します。
- 一緒に作成したいモデルを選択します。 矢印アイコンの付いたモデルは、既に作成済みのモデルです。
- [作成] ボタンを選択します。 ポップアップで、新しく作成するモデルに名前を付け、 [作成] をクリックします。
- 操作が完了すると、新しく作成されたモデルが一覧に表示されます。
フォームを分析する
モデルをテストするには、ナビゲーション バーから Analyze アイコンを選択します。 ソースの「ローカル ファイル」を選択します。 ファイルを参照し、テスト フォルダーに展開したサンプル データセットからファイルを選択します。 次に、[分析の実行] ボタンを選択して、フォームのキー/値のペア、テキスト、テーブル予測を取得します。 このツールでは、境界ボックスにタグが適用され、各タグの信頼度がレポートされます。
![[analyze-a-custom-form]\(カスタム フォームの分析\) ウィンドウのスクリーンショット](media/analyze.png?view=doc-intel-2.1.0)
ヒント
REST 呼び出しを使用して Analyze API を実行することもできます。 これを行う方法については、Python によるラベルを使用したトレーニングに関するページを参照してください。
結果を改善する
レポートされる精度によっては、モデルを改善するために、さらにトレーニングを行う必要が生じる場合があります。 予測が完了したら、適用されている各タグの信頼度の値を確認します。 トレーニングの平均精度値が高くても信頼度スコアが低い (または結果が不正確である) 場合は、予測ファイルをトレーニング セットに追加してラベルを付け、再度トレーニングを行います。
分析されたドキュメントがトレーニングで使用されたドキュメントと異なる場合は、レポートされる平均精度、信頼度スコア、および実際の精度に一貫性がなくなる場合があります。 ドキュメントには、人間が見た場合に似ていても AI モデルにとっては異なって見えるものがあることに留意してください。 たとえば、2 つのバリエーションがあるフォームの種類を使ってトレーニングするとします。ここでは、トレーニング セットはバリエーション A 20%、バリエーション B 80% で構成されています。この場合、予測の際にバリエーション A のドキュメントの信頼度スコアが低くなる可能性があります。
プロジェクトを保存して後で再開する
プロジェクトを時を改めて再開したり、別のブラウザーで再開したりするには、プロジェクトのセキュリティ トークンを保存し、後で再入力する必要があります。
プロジェクトの資格情報を取得する
プロジェクトの設定ページ (スライダー アイコン) に移動し、セキュリティ トークンの名前を書き留めます。 次に、アプリケーション設定 (歯車アイコン) に移動します。ここには、現在のブラウザー インスタンスのセキュリティ トークンがすべて表示されます。 プロジェクトのセキュリティ トークンを検索し、その名前とキー値を安全な場所にコピーします。
プロジェクトの資格情報を復元する
プロジェクトを再開する場合は、まず、同じ Blob Storage コンテナーへの接続を作成する必要があります。 これを行うには、手順を繰り返します。 次に、アプリケーション設定ページ (歯車アイコン) に移動し、プロジェクトのセキュリティ トークンがそこにあるかどうかを確認します。 ない場合は、新しいセキュリティ トークンを追加し、前の手順で保存したトークン名とキーをコピーします。 [保存] を選択して設定を保持します。
プロジェクトを再開する
最後に、メイン ページ (家のアイコン) に移動し、 [Open Cloud Project](クラウド プロジェクトを開く) を選択します。 その後、Blob Storage 接続を選択し、プロジェクトの .fott ファイルを選択します。 これにはセキュリティ トークンが含まれているため、アプリケーションによってプロジェクトの設定がすべて読み込まれます。
次のステップ
このクイックスタートでは、Document Intelligence Sample Labeling ツールを使用して、手動でラベル付けされたデータでモデルをトレーニングする方法を学習しました。 トレーニング データにラベルを付ける独自のユーティリティを作成したい場合は、ラベル付けされたデータのトレーニングを扱う REST API を使用してください。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示