チュートリアル: Azure Functions と Python を使用して格納済みドキュメントを処理する
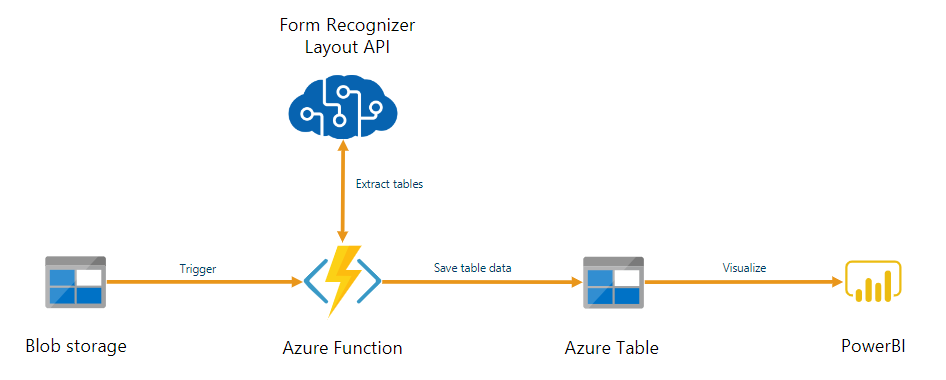
Document Intelligence は、Azure Functions で構築された自動データ処理パイプラインの一部として使用できます。 このガイドでは、Azure Functions を使用して、Azure BLOB ストレージ コンテナーにアップロードされたドキュメントを処理する方法について説明します。 このワークフローでは、Document Intelligence レイアウト モデルを使用して、格納済みドキュメントからテーブル データを抽出し、そのテーブル データを Azure で .csv ファイルに保存します。 その後、Microsoft Power BI (ここでは説明しません) を使用してデータを表示できます。
このチュートリアルでは、以下の内容を学習します。
- Azure ストレージ アカウントを作成します。
- Azure Functions プロジェクトを作成します。
- アップロードされたフォームからレイアウト データを抽出します。
- 抽出されたレイアウト データを Azure Storage にアップロードします。
前提条件
Azure サブスクリプション - 無料で作成できます
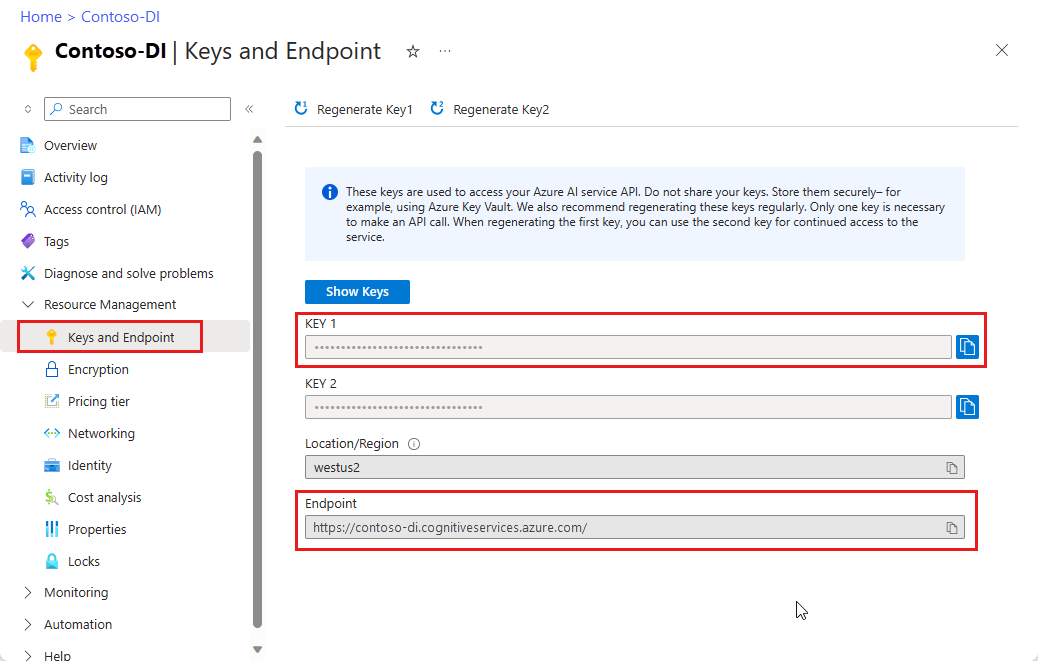
Document Intelligence リソース。 Azure サブスクリプションを入手したら、Azure portal で Document Intelligence リソースを作成して、キーとエンドポイントを取得します。 Free 価格レベル (
F0) を使用してサービスを試用し、後から運用環境用の有料レベルにアップグレードすることができます。リソースがデプロイされたら、 [リソースに移動] を選択します。 アプリケーションを Document Intelligence API に接続するには、作成したリソースのキーとエンドポイントが必要です。 このチュートリアルで後ほど下記に示すコードに、ご自分のキーとエンドポイントを貼り付けます。
Python 3.6.x、3.7.x、3.8.x、または 3.9.x (Python 3.10.x はこのプロジェクトでサポートされていません)。
次の拡張機能がインストールされている Visual Studio Code (VS Code) の最新バージョン。
Azure Functions 拡張機能。 インストールされると、左側のナビゲーション ウィンドウに Azure ロゴが表示されます。
Azure Functions Core Tools バージョン 3.x (バージョン 4.x はこのプロジェクトでサポートされていません)。
Visual Studio Code 用のPython 拡張機能。 詳細については、「VS Code でのはじめての Python」を "参照" してください
Azure Storage Explorer がインストールされていること。
分析対象のローカル PDF ドキュメント。 このプロジェクトのサンプル PDF ドキュメントを使用できます。
Azure Storage アカウントの作成
Azure portal で汎用 v2 Azure Storage アカウントを作成します。 ストレージコンテナーでAzureストレージアカウントを作成する方法がわからない場合は、以下のクイックスタートに従ってください:
- ストレージ アカウントの作成。 ストレージ アカウントを作成するときに、 [インスタンスの詳細]>[パフォーマンス] フィールドで [Standard] を選択してください。
- コンテナーを作成する。 コンテナーの作成時に、パブリック アクセス レベル を Container (コンテナとファイルの匿名読み取りアクセス) に設定し、[New Container] ウィンドウに表示します。
左側のペインで [リソースの共有 (CORS)] タブを選択し、既存の CORS ポリシーが存在する場合は削除します。
ストレージ アカウントがデプロイされたら、input と output という名前の 2 つの空の BLOB ストレージ コンテナーを作成します。
Azure Functions プロジェクトを作成する
プロジェクトを含む functions-app という名前の新しいフォルダーを作成し、[選択] を選択します。
Visual Studio Code を開き、コマンド パレットを開きます (Ctrl+Shift+P)。 [Python:Select Interpreter] (Python :インタープリターを選択) を検索して選択します。→ インストールされている Python インタープリター (バージョン 3.6.x、3.7.x、3.8.x、または 3.9.x) を選択します。 この選択により、選択した Python インタープリター パスがプロジェクトに追加されます。
左側のナビゲーション ウィンドウから Azure ロゴを選択します。
既存の Azure リソースが [リソース] ビューに表示されます。
このプロジェクトに使用している Azure サブスクリプションを選択すると、Azure Function App が下に表示されます。
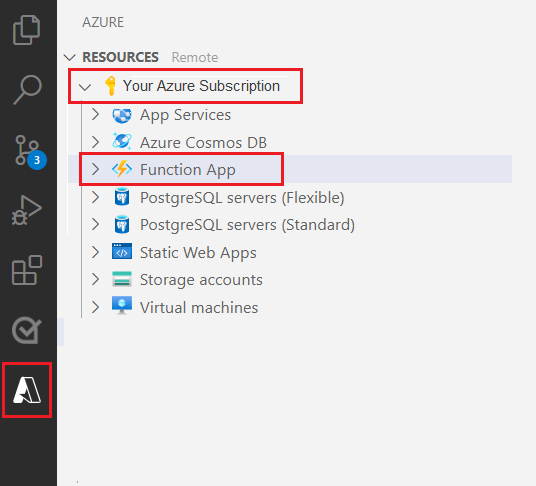
一覧のリソースの下にあるワークスペース (ローカル) セクションを選択します。 プラス記号を選択し、[関数の作成] ボタンを選択します。

メッセージが表示されたら、[新しいプロジェクトの作成] を選択し、 function-app ディレクトリに移動します。 [選択] を選択します。
いくつかの設定を構成するように求められます。
[言語を選択] → Python を選択します。
[Select a Python interpreter to create a virtual environment] (仮想環境を作成する Python インタープリターを選択) → 既定値として以前設定したインタープリターを選択します。
[テンプレートを選択する]→[Azure Blob Storage trigger] (Azure Blob Storage トリガー) を選択し、トリガーに名前を付けるか、既定の名前をそのまま使用します。 確認するには Enter キーを押します。
[設定の選択] →ドロップダウン メニューから [➕新しいローカル アプリ設定を作成する] を選択します。
サブスクリプションを選択 →作成したストレージ アカウントを使用して Azure サブスクリプションを選択→、ストレージ アカウントを選択→ストレージ入力コンテナーの名前を選択します (この場合は、
input/{name})。 確認するには Enter キーを押します。ドロップダウン メニューから [プロジェクトを開く方法を選択] → [現在のウィンドウでプロジェクトを開く] を選択します。
これらの手順を完了すると、VSCode によって、__init__.py Python スクリプトを持つ新しい Azure 関数プロジェクトが追加されます。 このスクリプトは、ファイルが input ストレージ コンテナーにアップロードされたときにトリガーされます。
import logging
import azure.functions as func
def main(myblob: func.InputStream):
logging.info(f"Python blob trigger function processed blob \n"
f"Name: {myblob.name}\n"
f"Blob Size: {myblob.length} bytes")
関数をテストする
F5 キーを押して、基本的な関数を実行します。 VS Code によって、インターフェイスとして使用するストレージ アカウントを選択するよう求められます。
作成したストレージ アカウントを選択し、続行します。
Azure Storage Explorer を開き、サンプル PDF ドキュメントを input コンテナーにアップロードします。 次に、VS Code ターミナルを確認します。 このスクリプトは、PDF のアップロードによってトリガーされたことをログしているはずです。
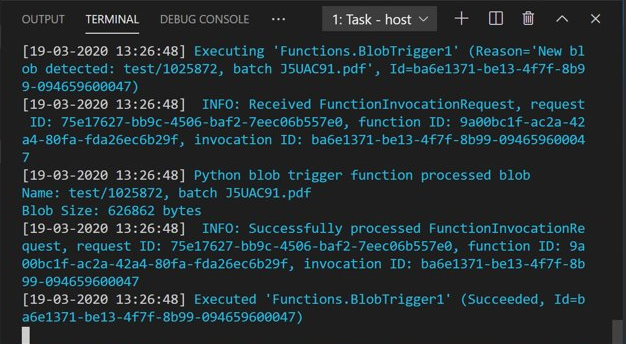
続行する前に、スクリプトを停止してください。
ドキュメント処理コードを追加する
次に、独自のコードを Python スクリプトに追加して Document Intelligence サービスを呼び出し、アップロードしたドキュメントを Document Intelligence レイアウト モデルを使用して解析します。
VS Code で、この関数の requirements.txt ファイルに移動します。 このファイルにより、お使いのスクリプトに対する依存関係が定義されます。 次の Python パッケージをこのファイルに追加します。
cryptography azure-functions azure-storage-blob azure-identity requests pandas numpy次に、__init__.py スクリプトを開きます。 次の
importステートメントを追加します。import logging from azure.storage.blob import BlobServiceClient import azure.functions as func import json import time from requests import get, post import os import requests from collections import OrderedDict import numpy as np import pandas as pd生成された
main関数はそのまま使用できます。 この関数内にカスタム コードを追加します。# This part is automatically generated def main(myblob: func.InputStream): logging.info(f"Python blob trigger function processed blob \n" f"Name: {myblob.name}\n" f"Blob Size: {myblob.length} bytes")次のコード ブロックは、アップロードされたドキュメントに対して Document Intelligence Analyze Layout API を呼び出します。 エンドポイントとキーの値を入力します。
# This is the call to the Document Intelligence endpoint endpoint = r"Your Document Intelligence Endpoint" apim_key = "Your Document Intelligence Key" post_url = endpoint + "/formrecognizer/v2.1/layout/analyze" source = myblob.read() headers = { # Request headers 'Content-Type': 'application/pdf', 'Ocp-Apim-Subscription-Key': apim_key, } text1=os.path.basename(myblob.name)重要
終わったらコードからキーを削除し、公開しないよう注意してください。 運用環境では、Azure Key Vault などの資格情報を格納してアクセスする安全な方法を使用します。 詳しくは、Azure AI サービスのセキュリティを "ご覧ください"。
次に、サービスに対してクエリを実行してから返されたデータを取得するコードを追加します。
resp = requests.post(url=post_url, data=source, headers=headers) if resp.status_code != 202: print("POST analyze failed:\n%s" % resp.text) quit() print("POST analyze succeeded:\n%s" % resp.headers) get_url = resp.headers["operation-location"] wait_sec = 25 time.sleep(wait_sec) # The layout API is async therefore the wait statement resp = requests.get(url=get_url, headers={"Ocp-Apim-Subscription-Key": apim_key}) resp_json = json.loads(resp.text) status = resp_json["status"] if status == "succeeded": print("POST Layout Analysis succeeded:\n%s") results = resp_json else: print("GET Layout results failed:\n%s") quit() results = resp_json次のコードを追加して、Azure Storage の output コンテナーに接続します。 ストレージ アカウントの名前とキーには、独自の値を入力します。 このキーは、Azure portal のストレージ リソースの [アクセス キー] タブで取得できます。
# This is the connection to the blob storage, with the Azure Python SDK blob_service_client = BlobServiceClient.from_connection_string("DefaultEndpointsProtocol=https;AccountName="Storage Account Name";AccountKey="storage account key";EndpointSuffix=core.windows.net") container_client=blob_service_client.get_container_client("output")次のコードは、返された Document Intelligence の応答を解析し、.csv ファイルを作成して output コンテナーにアップロードします。
重要
多くの場合、独自のドキュメントの構造に合わせて、このコードを編集する必要があります。
# The code below extracts the json format into tabular data. # Please note that you need to adjust the code below to your form structure. # It probably won't work out-of-the-box for your specific form. pages = results["analyzeResult"]["pageResults"] def make_page(p): res=[] res_table=[] y=0 page = pages[p] for tab in page["tables"]: for cell in tab["cells"]: res.append(cell) res_table.append(y) y=y+1 res_table=pd.DataFrame(res_table) res=pd.DataFrame(res) res["table_num"]=res_table[0] h=res.drop(columns=["boundingBox","elements"]) h.loc[:,"rownum"]=range(0,len(h)) num_table=max(h["table_num"]) return h, num_table, p h, num_table, p= make_page(0) for k in range(num_table+1): new_table=h[h.table_num==k] new_table.loc[:,"rownum"]=range(0,len(new_table)) row_table=pages[p]["tables"][k]["rows"] col_table=pages[p]["tables"][k]["columns"] b=np.zeros((row_table,col_table)) b=pd.DataFrame(b) s=0 for i,j in zip(new_table["rowIndex"],new_table["columnIndex"]): b.loc[i,j]=new_table.loc[new_table.loc[s,"rownum"],"text"] s=s+1最後に、コードの最後のブロックによって、抽出されたテーブルとテキスト データが BLOB ストレージ要素にアップロードされます。
# Here is the upload to the blob storage tab1_csv=b.to_csv(header=False,index=False,mode='w') name1=(os.path.splitext(text1)[0]) +'.csv' container_client.upload_blob(name=name1,data=tab1_csv)
関数を実行する
F5 キーを押して、関数を再度実行します。
Azure Storage Explorer を使用して、サンプルの PDF フォームを input ストレージ コンテナーにアップロードします。 この操作により、スクリプトの実行がトリガーされ、結果として得られる .csv ファイル (テーブルとして表示されます) が output コンテナーに表示されます。
このコンテナーを Power BI に接続すると、それに含まれるデータを詳細に視覚化できます。
次のステップ
このチュートリアルでは、Python で記述された Azure 関数を使用して、アップロードされた PDF ドキュメントを自動的に処理し、その内容をよりデータに適した形式で出力する方法について学習しました。 次に、Power BI を使用してデータを表示する方法について学習します。
- Document Intelligence とは
- レイアウト モデルに関する詳細情報
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示