Language Studio で発話にラベルを付ける
プロジェクトのスキーマを作成したら、プロジェクトにトレーニング発話を追加する必要があります。 発話は、ユーザーがプロジェクトと対話するときに使うものと似たものとする必要があります。 発話を追加するときは、それが属する意図を割り当てる必要があります。 発話が追加されたら、エンティティとして抽出する発話内の単語にラベルを付けます。
データのラベル付けは開発ライフサイクルにおける重要なステップです。このデータは、ラベル付きデータからモデルを学習できるようにモデルをトレーニングする、次の手順で使用されます。 発話が既にラベル付けされている場合は、プロジェクトに直接インポートできますが、データが、許容されるデータ形式に従っていることを確認する必要があります。 ラベル付けされたデータをプロジェクトにインポートする方法の詳細については、「プロジェクトの作成」を参照してください。 ラベル付けされたデータは、テキストの解釈方法をモデルに示し、トレーニングと評価に使用されます。
前提条件
データにラベルを付けるには、以下が必要です。
- 正常に作成されたプロジェクト。
詳細については、「プロジェクト開発サイクル」を参照してください。
データのラベル付けガイドライン
スキーマを構築し、プロジェクトを作成した後、データにラベルを付ける必要があります。 データのラベル付けは、プロジェクト内の意図やエンティティに関連付けられる単語と文をモデルが認識できるようにするために重要です。 発話のラベル付け (モデルのトレーニングに使用されるデータの導入と調整) に時間を費やす必要があります。
発話を追加してラベルを付ける際は、次の点に注意してください。
機械学習モデルは、提供したラベル付けされた例に基づいて一般化されます。提供する例が多いほど、より良い一般化を行うためにモデルで利用できるデータ ポイントが多くなります。
ラベル付けされたデータの正確性、一貫性、完全性が、モデルのパフォーマンスを決定する重要な要因です。
- 正確なラベル付け: 各意図とエンティティを常に適切な型にラベル付けします。 ラベルには、分類および抽出するデータのみを含め、不要なデータを入れないでください。
- 一貫したラベル付け: すべての発話で、同じエンティティに同じラベルが付いているようにします。
- 完全なラベル付け: 意図ごとにさまざまな発話を指定します。 すべての発話に含まれるエンティティのすべてのインスタンスにラベルを付けます。
発話に明確にラベルを付ける
エンティティが参照する概念が明確に定義され、分離可能であることを確かめます。 確実に違いを簡単に特定できるかどうかを確認します。 できない場合は、学習済みコンポーネントでも困難であることを示している可能性があります。
エンティティ間に類似点がある場合は、それらの違いのシグナルを提供するデータの一部の側面があることを確かめます。
たとえば、フライトを予約するモデルを構築した場合、ユーザーは "I want a flight from Boston to Seattle" のような発話を使用することがあります。このような発話の "出発地" と "目的地" は似ていることが予想されます。 "出発地" を区別するためのシグナルは、多くの場合、"from" という単語の前に置かれる可能性があります。
必ず、トレーニングとテスト データの両方で、各エンティティのすべてのインスタンスにラベルを付けてください。 1 つの方法は、検索機能を使用して、データ内の単語または語句のすべてのインスタンスを見つけ、正しいラベルが付けられているかどうかを確認することです。
学習済みコンポーネントがないエンティティと、あるエンティティのテスト データにラベルを付けます。 これは、評価メトリックが正確であることを確かめるのに役立ちます。
多言語プロジェクトの場合、他の言語に発話を追加すると、それらの言語でモデルのパフォーマンスが向上しますが、サポートするすべての言語でデータを複製しないようにしてください。 たとえば、ユーザーとのカレンダー ボットのパフォーマンスを向上させるために、開発者はほとんどの例を英語で追加し、いくつかの例をスペイン語やフランス語で追加することもできます。 次のような発話を追加できます。
- "Set a meeting with Matt and Kevintomorrow at 12 PM." (英語)
- "Reply as tentative to the weekly update meeting." (英語)
- "Cancelar mi próxima reunión." (スペイン語)
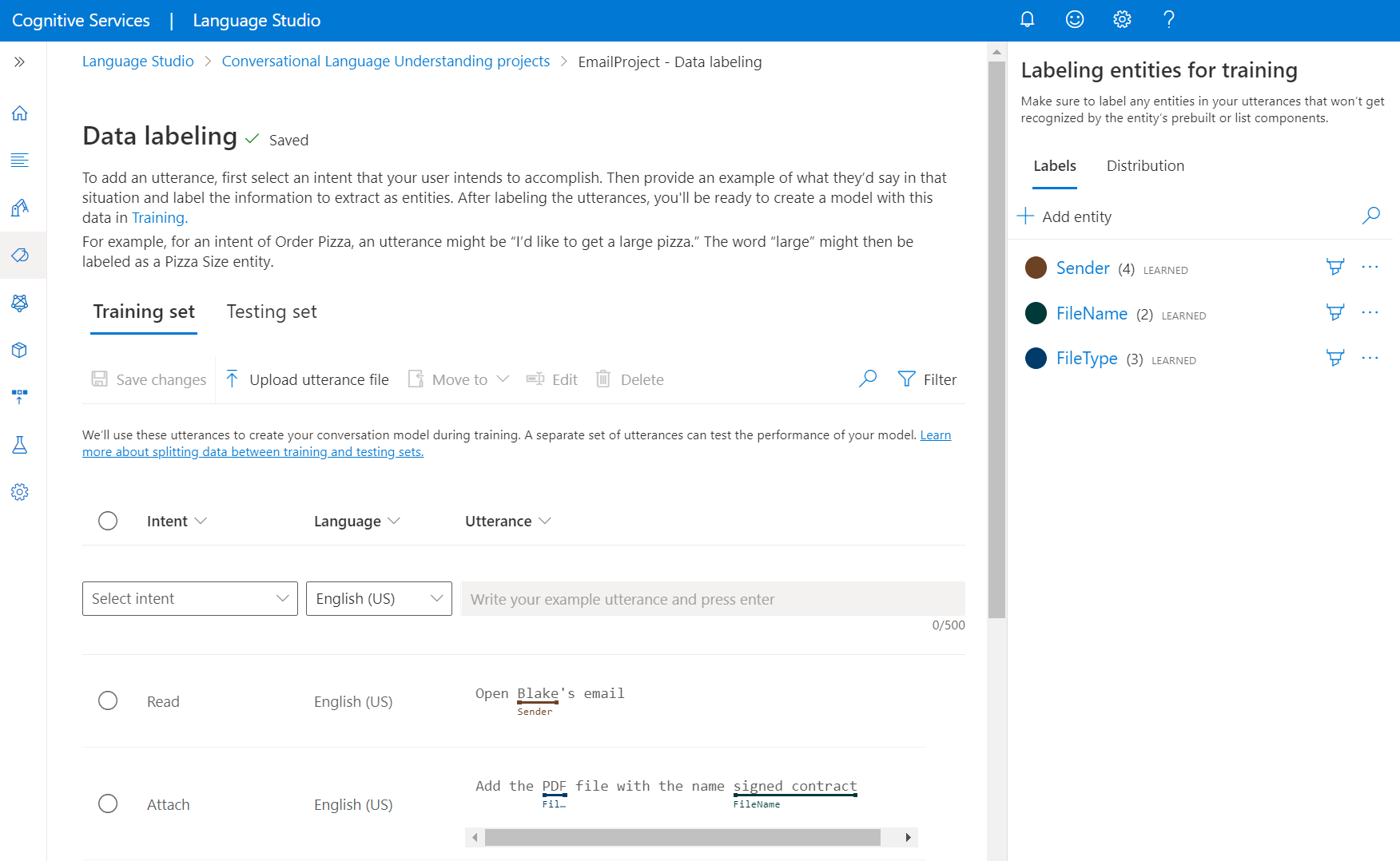
発話にラベルを付ける方法
次の手順に従って、発話にラベルを付けます。
Language Studio でプロジェクトのページに移動します。
左側のメニューから、[データのラベル付け] を選択します。 このページでは、発話の追加とラベル付けを開始できます。 上部のメニューから [Upload utterance file](発話ファイルのアップロード) をクリックして発話を直接アップロードすることもできます。これが受け入れ可能な形式に従っていることを確認します。
上部のピボットから、ビューをトレーニング セットまたはテスト セットに変更できます。 トレーニング用セットとテスト用セットの詳細と、モデルのトレーニングと評価に使用される方法について説明します。
ヒント
[トレーニング データからのテスト セットの自動分割] を使用する予定の場合は、すべての発話をトレーニング セットに追加します。
[Select Intent](意図の選択) ドロップダウン メニューから、いずれかの意図、発話の言語 (多言語プロジェクトの場合)、発話自体を選択します。 発話のテキスト ボックスで Enter キーを押して発話を追加します。
発話内のエンティティにラベルを付けるオプションは 2 つあります。
オプション 説明 ブラシを使ってラベルを付ける 右側のペインでエンティティの横にあるブラシ アイコンを選択し、ラベルを付ける発話のテキストを強調表示します。 インライン メニューを使ってラベルを付ける エンティティとしてラベルを付ける単語を強調表示すると、メニューが表示されます。 これらの単語にラベルを付けるエンティティを選択します。 右側のペインの [ラベル] ピボットで、プロジェクト内のすべてのエンティティ型と、それぞれのラベル付きインスタンスの数を確認できます。
[分布] ピボットの下で、トレーニング用セットとテスト用セット全体の分布を表示できます。 表示には、2 つのオプションがあります。
- "ラベル付けされたエンティティごとのインスタンスの合計数"。特定のエンティティのすべてのラベル付きインスタンスの数を表示できます。
- "ラベル付けされたエンティティごとの一意の発話" 。それぞれの発話に、このエンティティの少なくとも 1 つのラベル付きインスタンスが含まれている場合、発話がカウントされます。
- "意図ごとの発話"。意図ごとの発話の数を表示できます。


注意
リストと事前構築済みのコンポーネントはデータのラベル付けページには表示されず、ここでのすべてのラベルは学習したコンポーネントにのみ適用されます。
ユーザーを削除するには:
- 発話内から、ラベルを削除するエンティティを選択します。
- 表示されるメニューをスクロールして、[ラベルの削除] を選択します。
エンティティを削除するには:
- 右側のペインで、編集するエンティティを選びます。
- エンティティの横にある 3 つのドットを選択し、ドロップダウン メニューから目的のオプションを選びます。
Azure OpenAI を使用して発話を提案する
CLU では、Azure OpenAI を活用し、GPT モデルを使ってプロジェクトに追加する発話を提案します。 まず、Azure OpenAI にアクセスしてリソースを作成する必要があります。 次に、GPT モデルのデプロイを作成する必要があります。 こちらの前提条件の手順に従ってください。
開始する前に、発話の提案機能は、言語リソースが次のリージョンにある場合にのみ使用できます。
- 米国東部
- 米国中南部
- 西ヨーロッパ
[データのラベル付け] ページで、次の手順を実行します。
- [Suggest utterances] (発話の提案) ボタンを選択します。 右側にウィンドウが開き、Azure OpenAI リソースとデプロイを選択するように求められます。
- Azure OpenAI リソースを選択するときに、[接続] を選択すると、言語リソースが Azure OpenAI リソースに直接アクセスできるようになります。 Azure OpenAI リソースに対する
Cognitive Services Userのロールが言語リソースに割り当てられ、現在の言語リソースが Azure OpenAI のサービスにアクセスできるようになります。 接続に失敗した場合は、下に示す手順に従って、Azure OpenAI リソースに適切なロールを手動で追加します。 - リソースが接続されたら、デプロイを選択します。 Azure OpenAI デプロイに推奨されるモデルは
text-davinci-002です。 - 提案の取得対象の意図を選択します。 選択した意図に、発話の提案用に少なくとも 5 つの保存された発話が有効になっていることを確認します。 Azure OpenAI によって提供される提案は、その意図に対して追加した 最新の発話に基づいています。
- [Generate utterances] (発話の生成) を選択します。 完了すると、提案された発話が [Generated by AI] (AI によって生成) というメモと共に、点線で囲まれて表示されます。 これらの提案を受け入れるか拒否する必要があります。 提案を受け入れると、自分で追加したかのように、単にプロジェクトに追加されます。 拒否すると、提案が完全に削除されます。 受け入れられた発話のみがプロジェクトの一部となり、トレーニングまたはテストに使用されます。 各発話の横にある緑色のチェックまたは赤いキャンセル ボタンをクリックすると、承諾または拒否できます。 ツール バーの
Accept allボタンとReject allボタンを使用することもできます。

この機能を使用すると、生成された発話の提案と同様の数のトークンについて、Azure OpenAI リソースに対する料金が発生します。 Azure OpenAI の価格の詳細については、こちらを参照してください。
Azure OpenAI リソースに必要な構成を追加する
言語リソースを Azure OpenAI リソースに接続できない場合は、次の手順に従います。
次のオプションを使用して、言語リソースの ID 管理を有効にします。
Azure portal を使用して有効にするには、Language リソースに ID 管理が必要です。
- 言語リソースに移動します
- 左側のメニューの [リソース管理] セクションで、[ID] を選択します
- [システム割り当て済み] タブで、必ず [状態] を [オン] に設定します
マネージド ID を有効にした後、言語リソースのマネージド ID を使用して Azure OpenAI リソースにロール Cognitive Services User を割り当てます。
- Azure portal にサインインし、Azure OpenAI リソースに移動します。
- 左側の [アクセス制御 (IAM)] タブを選択します。
- [追加] > [ロールの割り当ての追加] の順に選択します。
- [Job function roles] (ジョブ関数のロール) を選択し、[次へ] をクリックします。
- ロールのリストから
Cognitive Services Userを選択し、[次へ] をクリックします。 - [アクセスの割り当て先] で [マネージド ID] を選択し、[メンバーを選択する] を選択します。
- [マネージド ID] で [言語] を選択します。
- リソースを検索して選択します。 その後、下の [選択] ボタンを選択し、次にプロセスを完了します。
- 詳細を確認し、[レビューと割り当て] を選択します。

数分後に Language Studio を更新すると、Azure OpenAI に正常に接続できるようになります。